1. Межсетевой экран уровня web-приложений Modsecurity
1.1 Проект ModSecurity
ModSecurity создан Иваном Ристиком (Ivan Ristic) в 2003 году и представляет собой firewall Web-приложений, который может использоваться как модуль Web-сервера Apache, либо работать в автономном режиме и позволяющий защитить Web-приложения как от известных, так и неизвестных атак. Его использование прозрачно, как установка, так и удаление не требует изменения настройки сервисов и сетевой топологии. Кроме того, при обнаружении уязвимого места теперь не обязательно впопыхах изменять исходный код, делая новые ошибки, достаточно на первых порах добавить новое правило, запрещающее вредную комбинацию. Modsecurity может защищать одновременно несколько Web-серверов, в том числе и отличных от Apache [1].
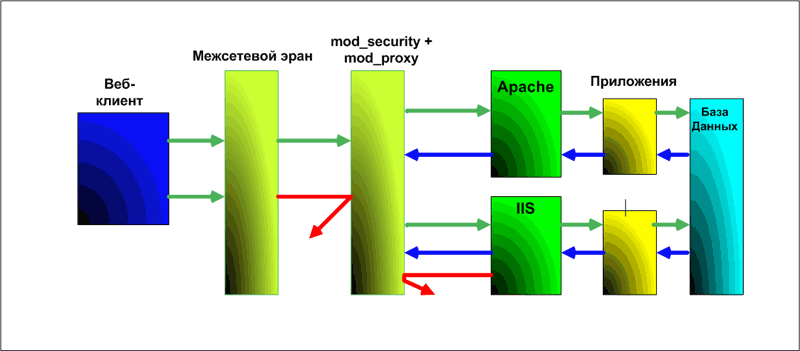
Кроме обычных соединений может контролировать и защищенный SSL-трафик. Гибкозадаваемые правила журналирования позволяют записать любые данные сеанса, позволяя в будущем полностью разобрать запросы, предшествующие взлому. Понимание протокола HTTP позволяет очень тонко выполнить фильтрацию, поддерживается как GET, так и POST-методы, запросы к динамическим ресурсам. Для борьбы с различными методами уклонения (ссылки на внешние сайты, закодированные URL, использование нескольких слэшей, нулевые байты и пр.) пути и параметры нормализуются. В новой версии, возможно наследование правил, используется новый формат контрольного журнала, позволяющий производить аудит в реальном времени. Кроме того, в этой версии введен новый механизм, названный guardian, задачей которого является контроль запросов, производимых с одного адреса, что позволяет защититься от DOS-атак, настраивая правила iptables. Интеграция с Open Source антивирусом ClamAV дает возможность сканировать загружаемые файлы на наличие вирусов. В версии добавлена поддержка PCRE, которую теперь можно использовать вместо библиотеки regex для Apache. Количество кода по сравнению с предыдущей версией выросло на 40%. Распространяется ModSecurity под двойной лицензией: GNU GPL, как свободное Open Source приложение, также доступно несколько вариантов end-user и OEM коммерческих лицензий [1].
1.2 Варианты установки ModSecurity
а) Установка непосредственно на Web-сервер.
б) Установка в качестве обратного прокси-сервера (Reverse Proxy).
Надо сказать, что ModSecurity используется только с Web-серверами Apache, желательно версий 2.x. Сервер Apache может работать как под Linux/UNIX, так и под Windows (http://httpd.apache.org). Mодуль ModSecurity изначально создавался под Linux/UNIX (http://www.modsecurity.org), но благодаря работе Стефана Лэнда был успешно портирован под Microsoft Windows (http://www.apachelounge.com). Сравним, чем отличается установка ModSecurity непосредственно на Web-сервер от установки в качестве обратного proxy [3].
В первом случае ModSecurity перехватывает все запросы к Web-серверу, на котором он установлен: запрос от клиента сначала сравнивается с правилами фильтрации модуля ModSecurity, а затем передается на дальнейшую обработку Web-серверу. ModSecurity также может контролировать ответы Web-сервера, т.е. после формирования страницы ответ обрабатывается модулем и в соответствии с правилами блокирует или разрешает прохождение ответа Web-сервера. Последний вариант можно использовать для замены страниц с ошибками Web-приложений, возникающими в результате обработки Web-сервером запросов от клиента, на стандартные страницы (например, страницы с ошибкой 404). Это позволит уменьшить объем передаваемой клиенту критичной информации о работе приложения и усложнит задачу потенциального злоумышленника [3].
Данный вариант установки ограничен применением Apache в качестве Web-сервера и не может использоваться для защиты других Web-серверов.
Установка Apache c модулем ModSecurity в качестве обратного proxy-сервера позволяет перехватывать запросы клиентов к Web-серверам, развернутым на любой платформе (IIS, Apache, WebSphere и т.д.). Принцип работы обратного proxy-сервера заключается в том, что сервер переадресует все запросы от клиентов Web-серверу и при получении ответа перенаправляет его клиенту. Клиенты «видят» только внешний интерфейс proxy-сервера и «не видят» расположенных за ним Web-серверов. В данном случае недостатками являются необходимость закупки дополнительного оборудования под proxy-сервер и наличие единой точки отказа для одного или нескольких Web-серверов. Однако сам proxy-сервер может выполнять и дополнительные полезные функции, например кэширование статических запросов и балансировку нагрузки на группу Web-серверов [3].
1.3 Функционал и преимущества ModSecurity
Вот несколько из основных возможностей, предоставляемых модулем ModSecurity.
а) Анализ запроса. Это основная функция данного модуля, особенно когда вы имеете дело с POST запросами, в которых получение тела запроса может быть затруднено [2].
б) Выполнение канонизации и функции антиуклонения. Выполнение ряда преобразований, для преобразования входных данных в форму, подходящую для анализа. Этот шаг применяется для борьбы с различными методами уклонения.
в) Выполнение специальных встроенных проверок. В этом месте выполняются более сложные проверки правильности, такие как проверка правильности URL кодирования и проверка правильности Unicode кодирования. Вы можете также контролировать некоторые значения байтов в запросе для борьбы с shellcode.
г) Запуск входных правил. В этом месте запускаются правила, созданные вами. Они позволяют вам анализировать каждый аспект запроса, используя регулярные выражения. Также здесь могут быть объединены несколько правил для более сложного анализа [2].
Затем запрос достигает обработчика. После запроса выполняются нижестоящие действия.
а) Запуск правил вывода. Правила вывода применяются к телу ответа. Они очень полезны для предотвращения утечек информации [2].
б) Регистрация запроса. Регистрируется окончательный запрос, состоящий из тела запроса и заголовков ввода и вывода. Чтобы предотвращать чрезмерную регистрацию, ModSecurity может регистрировать запросы по выбору, например запросы, которые получили ответ от ModSecurity [2].
Преимущества ModSecurity заключаются в следующем.
1) Бесплатный.
2) Открытые исходные коды.
3) Фильтрует как исходящие, так и входящие данные.
4) Удобный язык для написания правил фильтрации, базированный на проверке по регулярным выражениям.
5) Интеграция с прокси модулями Apache, что позволяет оптимально ускорить работу Web-сервера (loadbalancing).
6) Графическая оболочка для написания правил безопасности (REMO) [4].
ModSecurity на хабре:
1) Бета-версия modSecurity для Nginx
2) Защита веб-сервера Apache от атаки медленного чтения, а так же некоторых других направленных атак
2. Защита сервера с помощью WAF ModSecurity
На рисунке 1.1 изображена схема практической реализации атакующего воздействия на защищенный ModSecurity сервер с проектом Webgoat (подробнее данный проект рассмотрен в конце статьи). Атакующий с помощью специализированного ПО (браузер MS Internet Explorer, прокси-сервер WebScarab, сканер Acunetix WVS 6) будет атаковать Web-сервер с предустановленным проектом WebGoat. В последующем схема работы будет изменена – после соответствующей настройки Web-сервера c установленным межсетевым экраном прикладного уровня, настроенного в качестве обратного сервера-посредника по отношению к серверу с проектом WebGoat, будем атаковать данный сервер.
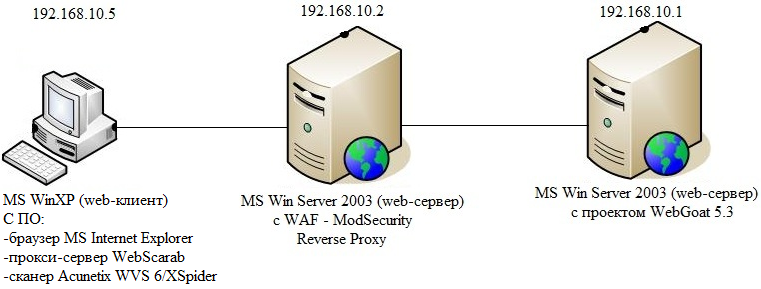
Рисунок 1.1
2.1 Руководство по настройке ОС Windows Server 2003 (ModSecurity)
Установим ModSecurity в качестве обратного прокси-сервера по отношению к серверу с проектом WebGoat, для этого:
1. Зайдем в «Пуск-Панель управления-Сетевые подключения». По подключению «Подключение по локальной сети» необходимо нажать правой кнопкой мыши, затем «Свойства». Выбрать «Протокол Интернета(TCP/IP)» и установить ip-адрес 192.168.10.2, маска 255.255.255.0.
2. Рассмотрим универсальный вариант использования ModSecurity в качестве обратного сервера-посредника (Reverse Proxy). Для работы сервера Apache в качестве обратного proxy-сервера необходимо включить поддержку следующих модулей:
1) mod_unique_id (входит в состав Apache);
2) mod_proxy (входит в состав Apache);
3) mod_proxy_http (входит в состав Apache);
4) mod_proxy_balancer (входит в состав Apache);
5) mod_proxy_html (не входит в состав Apache).
Устанавливаем Microsoft Visual C++ 2008 (x86). Для этого запускаем vcredist_x86(2008).exe и следуем указаниям мастера установки. Далее распаковываем файл httpd-2.2.21-win32-x86-ssl.zip в папку C:\Apache2. Данные дистрибутивы можно скачать с соответствующих источников [5, 6].
3. Устанавливаем сервер Apache в качестве службы операционной системы. Для этого в командной строке набираем: c:\Apache2\bin\httpd.exe -k install
4. Запускаем ApacheMonitor (С:\Apache2\bin\ApacheMonitor.exe).
Распакуем архивы с библиотекой libxml2.dll и модулем mod_proxy_html в папку c:\Apache2\modules\ (данные архивные файлы можно скачать с соответствующих источников [6])
5. Настроим Web-сервер Apache на работу в качестве обратного proxy-сервера. Для этого отредактируем файл конфигурации c:\Apache2\conf\httpd.conf в соответсвии с нижеприведенным листингом:
ThreadsPerChild 250
MaxRequestsPerChild 0
ServerRoot «c:/Apache2»
Listen 80
LoadFile C:\apache2\modules\libxml2.dll
LoadModule proxy_module modules/mod_proxy.so
LoadModule proxy_balancer_module modules/mod_proxy_balancer.so
LoadModule proxy_http_module modules/mod_proxy_http.so
LoadModule unique_id_module modules/mod_unique_id.so
LoadModule proxy_html_module modules/mod_proxy_html.so
ProxyRequests Off
ProxyPass / 192.168.10.1/
ProxyPassReverse / 192.168.10.1/
ServerName localhost:80
ErrorLog logs/error_log
LogLevel warn
6. В файле конфигурации нас интересует следующие параметры:
Listen 80 — порт, который будет использоваться Web-службой для приема HTTP-запросов от клиентов;
ProxyRequests Off — отключение режима обычного proxy;
ProxyPass и ProxyPassReverse, предназначенные для перенаправления запросов на другой Web-сервер.
В общем виде директивы ProxyPass и ProxyPassReverse имеют следующий синтаксис:
ProxyPass <относительный адрес на proxy-сервере> <адрес Web-сервера для перенаправления>.
7. Попробуем запустить наш proxy-сервер: открываем ApacheMonitor и нажимаем Start.
В случае если proxy-сервер был запущен успешно, то при обращении к нему по HTTP должна отобразиться Web-страница защищаемого Web-сервера.
После настройки и проверки работоспособности proxy-сервера установим непосредственно ModSecurity. Сначала остановим запущенную службу Apache (через ApacheMonitor). Из архива mod_security-2.6.2-win32.zip распаковываем в папку c:\Apache2\modules\ файл mod_security2.so (данный архив можно скачать с соответствующих источников [6]).
8. Для работы с модулем ModSecurity в конфигурационный файл Apache необходимо внести некоторые изменения, а именно добавить следующую строку: LoadModule security2_module modules/mod_security2.so
9. Разархивируйте архив с последними версиями правил для ModSecurity modsecurity-crs_2.2.2.zip (данный архив можно скачать с соответствующего источника [7]) перепишите всю папку rules из архива в папку c:\Apache2\conf\rules
10. Добавьте конфигурационные файлы правил в конфигурационный файл httpd.conf с помощью следующих команд:
include c:\Apache2\conf\rules\base_rules\*.conf
include c:\Apache2\conf\rules\slr_rules\*.conf
include c:\Apache2\conf\rules\*.conf
11. В папке c:\Apache2\conf\rules\находится конфигурационный файл modsecurity_crs_10_config.conf с базовыми настройками модуля ModSecurity.
Удалите базовые настройки. Укажите список действий по умолчанию, при которых будет производится занесение в журналы аудита каждого правила, для которого выполнено соответствие, и запрос будет прерываться с кодом статуса 404 с помощью команды SecDefaultAction «phase:2,deny,log, status:404»
12. Включите фильтрацию с помощью команды SecRuleEngine On
13. Включите сканирование тела запроса и тела ответа с помощью команды SecRequestBodyAccess On и SecResponseBodyAccess On
14. Скройте идентификатор сервера с помощью команды SecServerSignature «Apache/2.2.4 (Fedora)»
15. Укажите папку для загрузки файлов tmp с помощью команды SecUploadDir /tmp
16. Включите поддержку cookie версии 1 с помощью команды SecCookieFormat 1
17. Укажите параметры типовой конфигурации протоколирования событий:
SecAuditEngine RelevantOnly
SecAuditLogRelevantStatus "^(?:5|4\d[^4])"
SecAuditLogType Concurrent
SecAuditLogParts ABCDEFHZ
SecAuditLogStorageDir logs/data/
SecAuditLog bin/mlogc.exe
SecAuditLog "|bin/mlogc.exe bin/mlogc.conf"
18. Добавьте в конфигурационный файл modsecurity_crs_10_config.conf команды, чтобы в итоге они соответствовали рисунку 1.2.
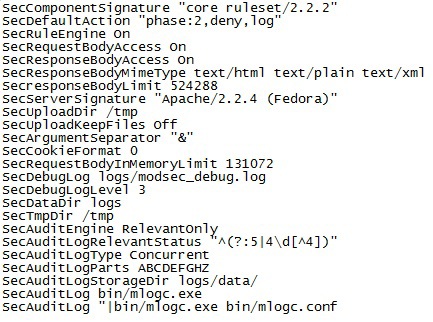
Рисунок 1.2 – Конфигурационный файл modsecurity_crs_10_config.conf
19. Запустите сервер Apache (с помощью ApacheMonitor). В итоге мы получили рабочий proxy-сервер, позволяющий защитить выбранный Web-сервер от ряда атак.
2.2 Руководство по настройке ОС Windows Server 2003 (WebGoat)
Развернем сервер с проектом WebGoat, для этого:
1. Зайдем в «Пуск-Панель уравления-Сетевые подключения». По подключению «Подключение по локальной сети» необходимо нажать правой кнопкой мыши, затем «Свойства». Выбрать «Протокол Интернета(TCP/IP)» и установить ip-адрес 192.168.10.1, маска 255.255.255.0.
2. Установить Java Runtime Environment (JRE) дистрибутив. В процессе установке оставить все настройки по умолчанию
3. Разархивировать архив WebGoat-OWASP_Standard-5.3_RC1.7z в папку «C:\ WebGoat-5.3_RC1»
4. Открываем конфигурационный файл, находящийся по адресу «С:\WebGoat-5.3_RC1\tomcat\conf\server_80.xml» и редактируем настройки подключения внешних ip-адресов следующим образом (см. рисунок 1.3):
Connector address=«127.0.0.1,192.168.10.1,192.168.10.2, 192.168.10.5»
5. Открыть каталог «С:\WebGoat-5.3_RC1» и запустить файл «webgoat.bat»
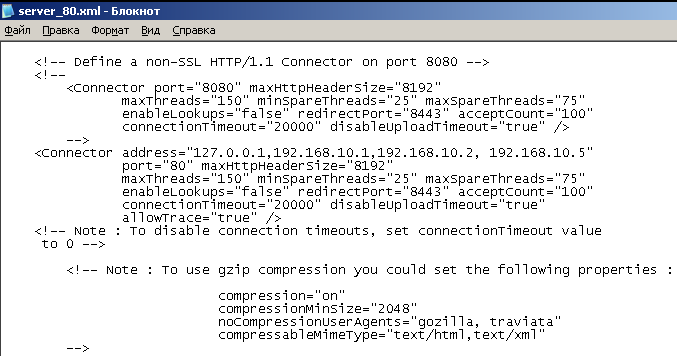
Рисунок 1.3 — Редактирование конфигруационного файла server_80.xml
2.3 Генерация атакующего воздействия
Для тестирования работы ModSecurity можно использовать любой из сканеров безопасности, умеющий проверять уязвимости веб-сервисов. Воспользуемся Acunetix Web Vulnerability Scanner.
Acunetix Web Vulnerability Scanner автоматизирует задачу контроля безопасности Web приложений и позволяет выявить уязвимые места в защите Web-сайта до того, как их обнаружит и использует злоумышленник.
Acunetix Web Vulnerability Scanner (WVS) работает следующим образом:
1) Acunetix WVS исследует и формирует структуру сайта, обрабатывая все найденные ссылки и собирая информация обо всех обнаруженных файлах;
2) затем программа тестирует все Web-страницы с элементами для ввода данных, моделируя ввод данных с использованием всех возможных комбинаций и анализируя полученные результаты;
3) обнаружив уязвимость, Acunetix WVS выдает соответствующее предупреждение, которое содержит описание уязвимости и рекомендации по ее устранению;
4) итоговый отчет WVS может быть записан в файл для дальнейшего анализа и сравнения с результатами предыдущих проверок.
Acunetix Web Vulnerability Scanner автоматически обнаруживает следующие уязвимости:
1) Cross site scripting (выполнение вредоносного сценария в браузере пользователя при обращении и в контексте безопасности доверенного сайта);
2) SQL injection (выполнение SQL-запросов из браузера для получения несанкционированного доступа к данным);
3) база данных GHDB (Google hacking database) – перечень типовых запросов, используемых хакерами для получения несанкционированного доступа к Web-приложения и сайтам.
4) выполнение кода;
5) обход каталога;
6) вставка файлов (File inclusion);
7) раскрытие исходного текста сценария;
8) CRLF injection
9) Cross frame scripting;
10) общедоступные резервные копии файлов и папок;
11) файлы и папки, содержащие важную информацию;
12) файлы, которые могут содержать информацию, необходимую для проведения атак (системные логи, журналы трассировки приложений и т.д.);
13) файлы, содержащие списки папок;
14) папка с низким уровнем защиты, позволяющие создавать, модифицировать или удалять файлы.
А также идентифицирует задействованные серверные технологии (WebDAV, FrontPage и т.д.) и разрешение на использование потенциально опасных http-методов (PUT, TRACE, DELETE).
На основной машине, выступающей в роли сканирующей станции, установлен Acunetix Web Vulnerability Scanner. Для тестирования работы межсетевого экрана прикладного уровня вначале протестируем на наличие Web-уязвимостей Web-сервер с установленным проектом WebGoat (с ip-адресом 192.168.10.1), а затем просканируем сервер (с ip-адресом 192.168.10.2), с установленным Apache и ModSecurity, работающим в качестве обратного сервера-посредника по отношению к серверу WebGoat.
12) Запустите Acunetix Web Vulnerability Scanner. Выполните сканирование, для этого нажмите «File->New->Web Site Scan», в появившемся диалоговом окне укажите «Scan Single Website» и адрес сервера (WebSite URL) «http://192.168.10.1/webgoat/attack». Оставляем все настройки по умолчанию, кроме пункта «Login» (указать в параметре «HTTP аутентификация» логин и пароль guest) После завершения всех настроек сканер автоматически начнет тестирование указанного узла.
13) Аналогичным образом просканируйте Web-сервер с установленным ModSecurity.
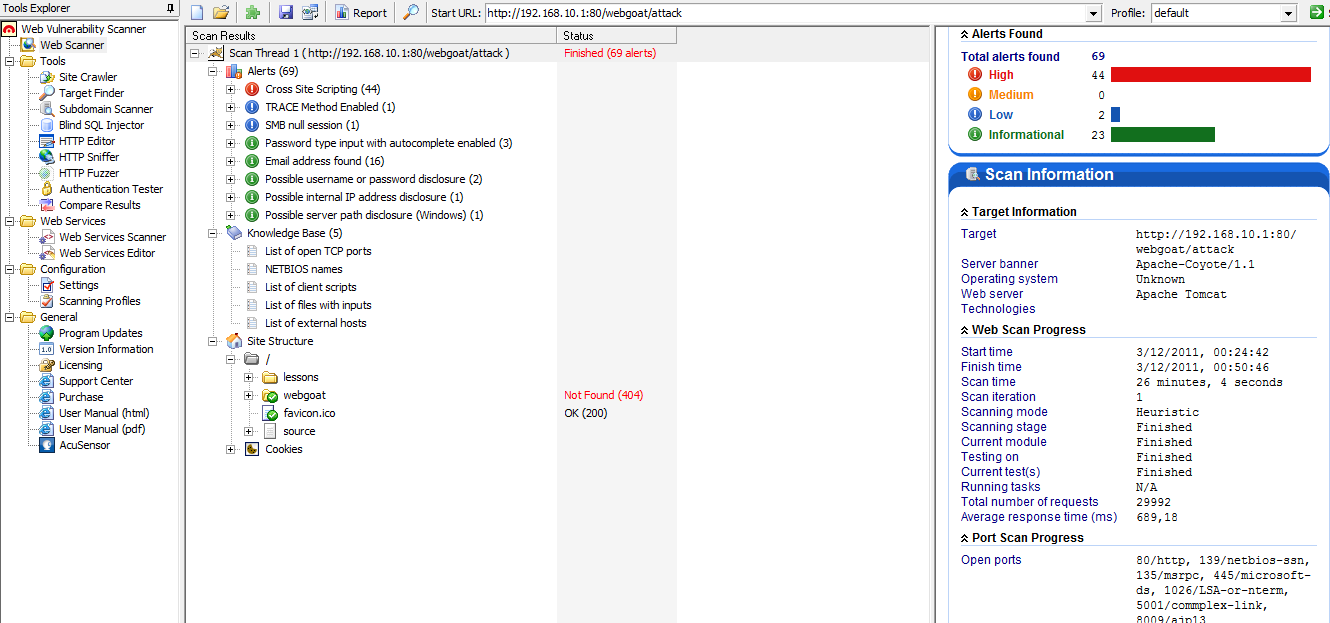
Рисунок 1.4 – Результаты сканирования сервера c установленным проектом WebGoat
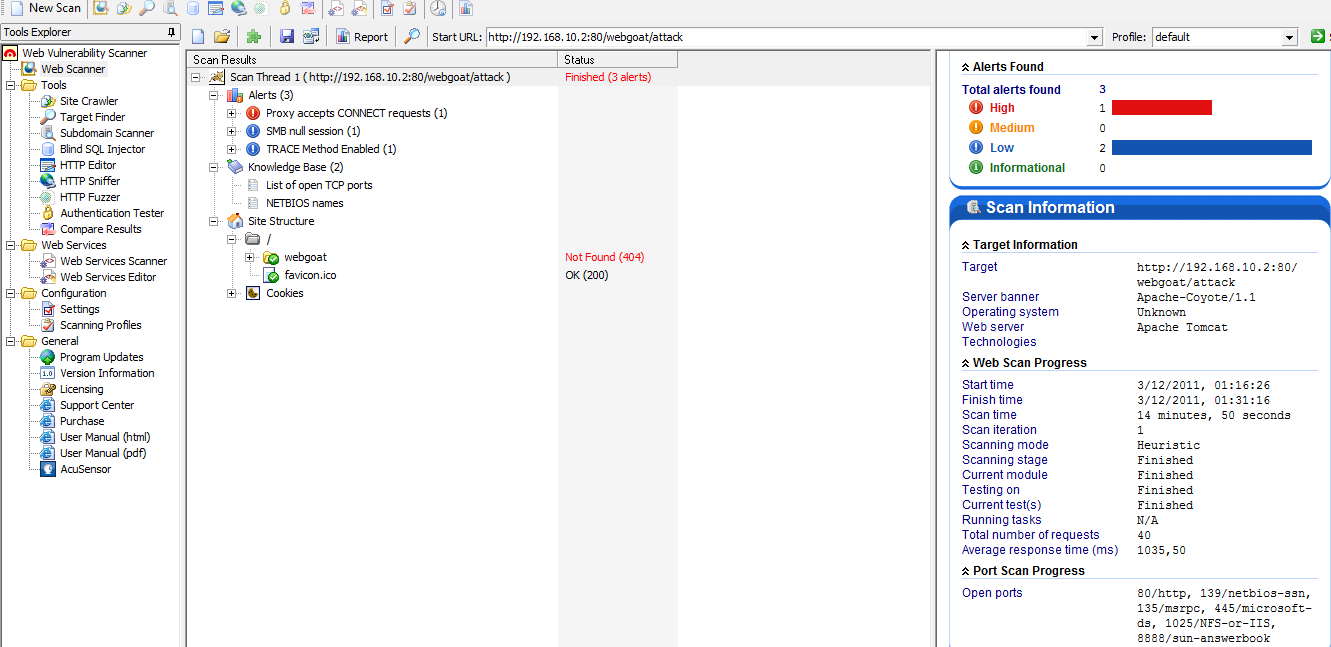
Рисунок 1.5 – Результаты сканирования сервера c установленным проектом ModSecurity, работающим в качестве обратного прокси-сервера по отношению к серверу с проектом WebGoat.
Проект OWASP WebGoat
Проект предназначенный для изучения web-уязвимостей (т.е. в нем изначально заложены типичные web-уязвимости). Примечателен тем, что развивается в рамках проекта OWASP (Open Web Application Security Project), под эгидой которого выпускается большое количество security-утилит. Данный код написан на Java. Для хостинга J2EE-приложений используется стандартный TomCat-сервер — к счастью, он уже включен в сборку WebGoat и настроен так, чтобы запустить его можно было максимально просто.
Задания, как правило, привязаны к реальной проблеме. Например, в одном из квестов предлагается провести SQL-injection с целью украсть список поддельных кредитных номеров. Некоторые задания сопровождаются учебной составляющей, показывающей пользователю полезные подсказки и уязвимый код.
Данный проект доступен по данному адресу.
Список использованных источников
1. Яремчук С. Как повысить безопасность веб-приложений // Системный администратор. 2006. №2.
2. Ристик И. Защита Web приложений с помощью Apache и ModSecurity // www.securitylab.ru/analytics/216322.php.
3. Юдин А. Защита приложений с помощью ModSecurity // Windows IT Pro. 2007. № 05.
4. Горячие идеи: Фильтрующий прокси // jthotblog.blogspot.com/2009/07/blog-post.html .2009.
5. По данным сайта Microsoft www.microsoft.com
6. По данным сайта Стефана Лэнда www.apachelounge.com
7. По материалам сайта организация The Open Web Application Security Project (OWASP) www.owasp.org/
P.S.: Настройки и синтаксис команд ModSecurity детально описаны в книге Magnus Mischel «ModSecurity 2.5.Securing your Apache installation and web applications»( England: Published by Packt Publishing, 2009. 280 c).
ссылка на оригинал статьи http://habrahabr.ru/post/228103/