Ответить
Архив за месяц: Ноябрь 2014
Что такое утечки памяти в android, как проверить программу на их отсутствие и как предотвратить их появление
В этой статье для начинающих android-разработчиков я постараюсь рассказать о том, что такое «утечки памяти» в android, почему о них стоит думать на современных устройствах, выделяющих по 192МБ на приложение, как быстро найти и устранить эти утечки в малознакомом приложении и на что нужно обращать особое внимание при разработке любого приложения.


Конечная цель это статьи — ответ на простой вопрос:
Куда нажать, чтобы узнать, какую строчку в приложении поправить?
Что такое «утечка памяти»?
Начнем с того, что же называется «утечкой памяти». В строгом понимании объект можно назвать утечкой памяти, если он продолжает существовать в памяти даже после того, как на него потеряны все ссылки. С этим определением сразу же возникает проблема: память для всех объектов, которые вы создаете, выделяется при участии сборщика мусора, и все созданные объекты сборщик мусора помнит, независимо от того, есть у вас ссылка на объект, или нет.
На самом деле сборщик мусора устроен крайне примитивно (на самом деле нет — но принцип работы действительно простой): есть граф, в котором каждый существующий объект — это вершина, а ссылка от любого объекта на любой другой объект — ребро. Некоторые вершины на этом графе — особые. Это корни сборщика мусора (garbage collection roots) — те сущности, которые созданы системой и продолжают свое существование независимо от того, ссылаются на них другие объекты или нет. Если и только если на графе существует любой путь от данного объекта до любого корня, объект не будет уничтожен сборщиком мусора.
В этом и заключается проблема — если объект не уничтожен, значит существует цепочка ссылок от корня до данного объекта (либо, если такой цепочки не существует, объект будет уничтожен при следующей сборке мусора).А это значит, что ни один объект не может являться утечкой памяти в строгом понимании этого термина. Собственно даже того, что сам сборщик мусора хранит ссылку на каждый существующий объект в системе, уже достаточно.
Попытки получить в java «чистую» утечку памяти предпринимались неоднократно и, безусловно, продолжают предприниматься, однако ни один из способов не способен заставить сборщика мусора забыть ссылку на объект, не освободив память. Существуют утечки памяти, связанные с выделением памяти нативным кодом (JNI), однако в этой статье мы их не будем рассматривать.
Вывод: вы можете потерять все ссылки на интересующий вас объект, но сборщик мусора помнит.
Итак, определение «утечки памяти» в строгом смысле нам не подходит. Поэтому далее будем понимать утечку памяти как объект, который продолжает существовать после того, как он должен быть уничтожен.
Далее я покажу несколько наиболее распространенных случаев утечек памяти, покажу как их обнаруживать и как избегать. Если вы научитесь устранять эти типовые утечки памяти, то с вероятностью 99.9%, в вашем приложении не будет утечек памяти, о которых стоит волноваться.
Но, прежде чем перейти к описанию этих частых ошибок, нужно ответить на главный вопрос: а нужно ли вообще исправлять эти ошибки? Приложение-то работает…
Почему нужно тратить время на устранение утечек памяти?

Приложения уже давно не падают из-за того, что вы забыли пережать ресурсы в папку drawable-ldpi. Готовясь к написанию этой статьи, я провел простой эксперимент: я взял одно из работающих приложений, и добавил в него утечку памяти таким образом, что ни одно создаваемое activity никогда не выгружалось из памяти (стал добавлять их в статический список). Я открыл приложение и начал прокликивать экраны, ожидая, когда же приложение наконец упадет на моем Nexus 5. Наконец, через 5 минут и 55 экранов, приложение упало. Ирония в том, что, по данным Google Analytics, обычно пользователь за сессию посещает 3 экрана.
Так нужно ли волноваться по поводу утечек памяти, если пользователь может их просто не заметить? Да, и есть три причины почему.
Во-первых, если в вашем приложении работает что-то, что работать не должно, это может привести к очень серьёзным и трудно отлаживаемым проблемам.
Например, вы разработали приложение для социальной сети. В этом приложении можно обмениваться сообщениями между пользователями, где на экране обмена сообщениями есть таймер, который делает запрос на сервер каждые 10 секунд с целью получения новых сообщений, но вы забыли этот таймер выключить при выходе с экрана. К чему это приведет визуально? Да ни к чему. Вы не заметите, что приложение делает что-то не то. Но при этом приложение продолжит каждые 10 секунд посылать запрос на сервер. Даже после того, как вы выйдете из приложения. Даже после того, как вы выключите экран (поведение может варьироваться от телефона). Если пользователь зайдет на экраны общения с тремя разными друзьями, в течение часа вы получите 1000 лишних запросов на сервер и одного пользователя, очень рассерженного на ваше приложение, которое усиленно потребляет батарею. Именно такие результаты я получил с тестовым приложением на телефоне с выключенным экраном.
Вы можете возразить, что это не утечка памяти, а всего лишь не выключенный таймер и это совсем другая ошибка. Это неважно. Важно, что проверив свое приложение на наличие утечек памяти, вы найдете и другие ошибки. Когда мы проверяем приложение на наличие утечек памяти, мы хотим найти все объекты, которые существуют, но существовать не должны. Находя такие объекты, мы сразу понимаем, какие лишние операции продолжают выполняться.
Во-вторых, не все приложения потребляют мало памяти, и не все телефоны выделяют много памяти.
Помните про приложение, которое упало только после 5 минут и 55 не выгруженных экранов? Так вот для этого же приложения мне каждую неделю приходит 1-2 отчета о падении с OutOfMemoryException (в основном с устройств до 4.0; у приложения 50.000 установок). И это при том, что утечек памяти в приложении нет. Поэтому даже сейчас вы можете изрядно подпортить себе карму, выложив приложение с утечками памяти, особенно если ваше приложение потребляет много памяти. Как обычно в мире android, от блестящего будущего нас отделяет суровое настоящее.
В-третьих, мужик должен всё уметь! (я же обещал, что все 3 причины будут серьёзные)
Теперь, когда я, надеюсь, убедил вас в необходимости отлавливать утечки памяти, давайте рассмотрим основные причины их появления.
Никогда не сохраняйте ссылки на activity (view, fragment, service) в статических переменных
Один из первых вопросов, с которым сталкивается каждый начинающий разработчик, это как передать объект из одного activity в следующий. Самое простое и самое неправильное решение, которое мне периодически приходится видеть, это запись первого activity в статическую переменную и обращение к этой переменной из второго activity. Это крайне неудачный подход. Не только потому, что он моментально приводит к утечке памяти (статическая переменная продолжит существовать пока существует приложение, и activity, на который она ссылается, никогда не будет выгружен). Этот подход также может привести к ситуации, когда вы будете обмениваться информацией не с тем экраном, ведь экран, невидимый пользователю, может в любой момент быть уничтожен и пересоздан лишь когда пользователь к нему вернется.
Почему же утечка activity — такая большая проблема? Дело в том, что если сборщик мусора не соберет activity, то он не соберет и все view и fragment, а вместе с ними и все прочие объекты, расположенные на activity. В том числе не будут высвобождены картинки. Поэтому утечка любого activity — это, как правило, самая большая утечка памяти, которая может быть в вашем приложении.
Никогда не записывайте ссылки на activity в статические переменные. Используйте передачу объектов через Intent, либо вообще передавайте не объект, а id объекта (если у вас есть база данных, из которой этот id потом можно достать).
Этот пункт также относится к любым объектам, временем жизни которых напрямую или косвенно управляет android. Т.е. к view, fragment, service и т.д..
View и fragment объекты содержат ссылку на activity, в котором они расположены, поэтому, если утечет один единственный view, утечет сразу всё — activity и все view в нём, а, вместе с ними, и все drawable и всё, на что у любого элемента из экрана есть ссылка!
Будьте аккуратны при передаче ссылки на activity (view, fragment, service) в другие объекты
Рассмотрим простой пример: ваше приложение для социальной сети отображает фамилию, имя и рейтинг текущего пользователя на каждом экране приложения. Объект с профилем текущего пользователя существует с момента входа в аккаунт до момента выхода из него, и все экраны вашего приложения обращаются за информацией к одному и тому же объекту. Этот объект также периодически обновляет данные с сервера, так как рейтинг может часто меняться. Необходимо, чтобы объект с профилем уведомлял текущее activity об обновлении рейтинга. Как этого добиться? Очень просто:
@Override protected void onResume() { super.onResume(); currentUser.addOnUserUpdateListener(this); } Как добиться в этой ситуации утечки памяти? Тоже очень несложно! Просто забудьте отписаться от уведомлений в методе onPause:
@Override protected void onPause() { super.onPause(); /* Забудьте про следующую строчку и вы получите серьёзную утечку памяти */ currentUser.removeOnUserUpdateListener(this); } Из-за такой утечки памяти activity будет продолжать обновлять интерфейс каждый раз, когда профиль будет обновляться даже после того, как экран перестанет быть видим пользователю. Хуже того, таким образом экран может подписать 2, 3 или больше раза на одно и то же уведомление. Это может привести к видимым тормозам интерфейса в момент обновления профиля — и не только на этом экране.
Что делать, чтобы избежать этой ошибки?
Во-первых, конечно нужно всегда внимательно следить за тем, что вы отписались от всех уведомлений в момент ухода activity в фон.
Во-вторых, вы должны периодически проверять своё приложение на наличие утечек памяти.
В-третьих, есть и альтернативный подход к проблеме: вы можете сохранять не ссылки на объекты, а слабые ссылки. Это особенно полезно для наследников класса View — ведь у них нет метода onPause и не совсем понятно, в какой момент они должны отписываться от уведомления. Слабые ссылки не считаются сборщиком мусора как связи между объектами, поэтому объект, на который существуют только слабые ссылки, будет уничтожен, а ссылка перестанет ссылаться на объект и примет значение null. Чтобы не возиться каждый раз с не очень удобными в использовании слабыми ссылками, вы можете воспользоваться примерно следующим шаблонным классом:
public class Observer<I> { private ArrayList<I> strongListeners = new ArrayList<I>(); private ArrayList<WeakReference<I>> weakListeners = new ArrayList<WeakReference<I>>(); public void addStrongListener(I listener) { strongListeners.add(listener); } public void addWeakListener(I listener) { weakListeners.add(new WeakReference<I>(listener)); } public void removeListener(I listener) { strongListeners.remove(listener); for (int i = 0; i < weakListeners.size(); ++i) { WeakReference<I> ref = weakListeners.get(i); if (ref.get() == null || ref.get() == listener) { weakListeners.remove(i--); } } } public List<I> getListeners() { ArrayList<I> activeListeners = new ArrayList<I>(); activeListeners.addAll(strongListeners); for (int i = 0; i < weakListeners.size(); ++i) { WeakReference<I> ref = weakListeners.get(i); I listener = ref.get(); if (listener == null) { weakListeners.remove(i--); continue; } activeListeners.add(listener); } return activeListeners; } } Который будет работать примерно вот так:
public class User { ... public interface OnUserUpdateListener { public void onUserUpdate(); } private Observer<OnUserUpdateListener> updateObserver = new Observer<OnUserUpdateListener>(); public Observer<OnUserUpdateListener> getUpdateObserver() { return updateObserver; } } ... @Override protected void onFinishInflate() { super.onFinishInflate(); /* Мы подписываемся на уведомления при создании объекта */ currentUser.getUpdateObserver().addWeakListener(this); } /* ... и никогда от этих уведомлений не отписываемся */ ... Да, вы можете получить лишние обновления этого view. Но часто это — меньшее из зол. И, при любом раскладе, утечку памяти вы уже не получите.
Есть только одна тонкость при использовании метода addWeakListener: на объект, который вы добавляете, должен кто-то ссылаться. Иначе сборщик мусора уничтожит этот объект до того, как он получит свое первое уведомление:
/* Не делайте так! */ currentUser.getUpdateObserver().addWeakListener(new OnUserUpdateListener() { @Override public void onUserUpdate() { /* Этот код не будет вызван */ } });
Таймеры и потоки, которые не отменяются при выходе с экрана
Про эту проблему я уже рассказывал выше: итак, вы разработали приложение для социальной сети. В этом приложении можно обмениваться сообщениями между пользователями, и вы добавляете на экран обмена сообщениями таймер, который делает запрос на сервер каждые 10 секунд с целью получения новых сообщений, но вы забыли этот таймер выключить при выходе с экрана:
public class HandlerActivity extends Activity { private Handler mainLoopHandler = new Handler(Looper.getMainLooper()); private Runnable queryServerRunnable = new Runnable() { @Override public void run() { new QueryServerTask().execute(); mainLoopHandler.postDelayed(queryServerRunnable, 10000); } }; @Override protected void onResume() { super.onResume(); mainLoopHandler.post(queryServerRunnable); } @Override protected void onPause() { super.onPause(); /* Вы забыли написать строчку ниже и в вашем приложении появилась утечка памяти */ /* mainLoopHandler.removeCallbacks(queryServerRunnable); */ } ... } К сожалению, эту проблему сложно избежать. Единственные два совета, которые можно дать, будут такими же, как и в предыдущем пункте: будьте внимательны и периодически проверяйте приложение на утечки памяти. Вы также можете использовать аналогичный предыдущему пункту подход с использованием слабых ссылок.
Никогда не сохраняйте ссылки на fragment в activity или другом fragment
Я очень много раз видел эту ошибку. Activity хранит ссылки на 5-6 запущенных фрагментов даже не смотря на то, что на экране всегда виден только 1. Один фрагмент хранит ссылку на другой фрагмент. Фрагменты, видимые на экране в разное время, общаются друг с другом по прямым закешированным ссылкам. FragmentManager в таких приложениях выполняет чаще всего рудиментарную роль — в нужный момент он подменяет содержимое контейнера нужным фрагментом, а сами фрагменты в back stack не добавляются (добавление фрагмента, на который у вас есть прямая ссылка, в back stack рано или поздно приведет к тому, что фрагмент будет выгружен из памяти; после возврата к этому фрагменту будет создан новый, а ваша ссылка продолжит ссылаться на существующий, но невидимый пользователю фрагмент).
Это очень плохой подход по целому ряду причин.
Во-первых, если вы храните в acitvity прямые ссылки на 5-6 фрагментов, то это тоже самое, как если бы вы хранили ссылки на 5-6 activity. Весь интерфейс, все картинки и вся логика 5 неиспользуемых фрагментов не могут быть выгружены из памяти, пока запущено activity.
Во-вторых, эти фрагменты становится крайне сложно переиспользовать. Попробуйте перенести фрагмент в другое место программы при условии, что он должен быть обязательно запущен в одном activity с фрагментами, x, y и z, которые переносить не надо.
Относитесь к фрагментам как к activity. Делайте их максимально модульными, общайтесь между фрагментами только через activity и fragmentManager. Это может казаться излишне сложной системой: зачем так стараться, когда можно просто передать ссылку? Но, на самом деле, такой подход сделает вашу программу лучше и проще.
По этой теме есть отличная официальная статья от Google: «Communicating with Other Fragments». Перечитайте эту статью и никогда больше не сохраняйте указатели на фрагменты.
Обобщённое правило
После прочтения четырех предыдущих пунктов вы могли заметить, что они практически ничем не отличаются. Все это — частные случаи одного общего правила.
Все утечки памяти появляются тогда и только тогда, когда вы сохраняете ссылку на объект с коротким жизненным циклом (short-lived object) в объекте с длинным жизненным циклом (long-lived object).
Помните об этом и всегда внимательно относитесь к таким ситуациям.
У этого правила нет красивого короткого названия, такого как KISS, YAGNI или RTFM, но оно применимо ко всем языкам со сборщиком мусора и ко всем объектам, а не только к activity в android.
Теперь, когда я, надеюсь, показал основные источники утечек памяти, давайте наконец перейдём к их выявлению в рабочем приложении.
Куда нажать, чтобы узнать, какую строчку в приложении поправить?
Итак, вы знаете как избежать утечек памяти, но это не ограждает вас от опечаток, багов и проектов, которые вы написали до того, как узнали, как избежать утечек памяти.
Для того, чтобы определить наличие и источник утечек памяти в приложении вам потребуется немного времени и MAT. Если вы никогда раньше не пользовались MAT, установите его как plugin к eclipse, откройте DDMS perspective и найдите кнопку «Dump HPROF file». Нажатие на эту кнопку откроет дамп памяти выбранного приложения. Если вы используете Android Studio, то процесс будет немного сложнее, так как на данный момент MAT все ещё не существует как плагин к Android Studio. Поставьте MAT как отдельную программу и воспользуйтесь инструкцией со stackoverflow.
Выполните следующие шаги:
- Установите приложение на устройство, подключенное к компьютеру и попользуйтесь им таким образом, чтобы оказаться на каждом экране как минимум однажды. Если один экран может быть открыт с разными параметрами, постарайтесь открыть его со всеми возможными комбинациями параметров. Вообщем — пройдитесь по всему приложению, как если бы вы проверяли его перед релизом. После того как вы прошли все экраны, нажимайте кнопку «назад» до тех пор, пока не выйдите из приложения. Не нажимайте кнопку home — ваша задача завершить все запущенные activity, а не просто скрыть их.
- Нажмите на кнопку Cause GC несколько раз. Если вы этого не сделаете, в дампе будут видны объекты, которые подлежат уничтожению сборщиком мусора, но ещё не были уничтожены.
- Сделайте дамп памяти приложения нажав на кнопку «Dump HPROF file».
- В открывшемся окне сделайте OQL запрос: «SELECT * FROM instanceof android.app.Activity»

Список результатов должен быть пустым. Если в списке есть хотя бы один элемент, значит этот элемент — это и есть ваша утечка памяти. На скриншоте вы видите именно такой элемент — HandlerActivity: это и есть утечка памяти. Выполните пункты 8-10 для каждого элемента из списка.
- Выполните аналогичные запросы для наследников Fragment: «SELECT * FROM instanceof android.app.Fragment». Как и в предыдущем случае, все, что попало в список результатов — это утечки памяти. Выполните для каждой из них пункты 8-10.
- Откройте histogram. Результаты, отображаемые в histogram, отличаются от результатов, отображаемых в OQL тем, что в histogram отображаются классы, а не объекты. В поле фильтра введите используемый для ваших классов package name (на скриншоте это com.examples.typicalleaks) и отсортируйте результаты по колонке objects (сколько объектов данного класса сейчас существует в системе). Обратите внимание, что в результатах отображаются в том числе и классы, 0 экземпляров которых существовало на момент получения дампа. Эти классы нас не интересуют. Если объектов действительно много — выделите всю таблицу, нажмите правой кнопкой и выберите пункт Calculate Precise Retained Size. Отсортируйте таблицу по полю Retained Heap и рассматривайте только объекты с большими значениями Retained Heap, например больше 10000.

На этот раз далеко не все объекты классов, которые вы видите в списке, являются утечками памяти. Однако все эти классы — это классы вашего приложения, и вы должны примерно понимать, сколько объектов каждого из этих классов должно существовать в данный момент. Например, на скриншоте мы видим 6 объектов класса Example и один массив Example[]. Это нормально — класс Example это enum, его объекты были созданы при первом обращении и будут существовать пока существует приложение. А вот HandlerActivity и HandlerActivity$1 (первый анонимный класс, объявленный внутри файла HandlerActivity.java) — это уже знакомые нам утечки памяти. Нажимаем правой кнопкой на подозрительный класс, выбираем пункт list objects, выполняем пункты 8-10 для одного из объектов из полученного списка.
- Если к этому шагу у вас не набралось ни одного подозрительного объекта — поздравляю! В вашем приложении нет значимых утечек памяти.
- Нажмите правой кнопкой на подозрительный объект и выберите пункт Merge Shortest Paths to GC Roots — exclude all phantom/weak/soft etc. references.
- Раскройте дерево. У вас должна получится примерно следующая картина:

В самом низу вы должны увидеть ваш подозрительный объект. В самом верху — корень сборщика мусора. Все, что посередине — это объекты, соединяющие ваш подозрительный объект с корнем сборщика мусора. Именно эта цепочка и не позволяет сборщику мусора уничтожить подозрительный объект. Читать эту цепочку следует следующим образом: жирным написана переменная объекта выше по списку, в которой содержится ссылка на объект справа от названия переменной. Т.е. на скриншоте мы видим, что переменная mMessages объекта MessageQueue содержит ссылку на объект Message, который содержит переменную callback, ссылающуюся на объект HandlerActivity$1, который содержит ссылку на объект HandlerActivity в переменной this$0. Иными словами, наш подозрительный объект HandlerActivity удерживает первый Runnable, объявленный в файле HandlerActivity.java, так как он добавлен в Handler с помощью метода post или postDelayed. Найдите последний снизу списка класс, который являются частью вашего приложения, нажмите на него правой кнопкой и выберите пункт Open Source File.
- Исправьте код приложения таким образом, чтобы разрушить цепочку между подозрительным объектом и корнем сборщика мусора в тот момент, когда подозрительный объект перестанет быть нужен. В нашем примере нам достаточно вызвать метод Handler.removeCallbacks(Runnable r) в методе onPause HandlerActivity.
- После того, как вы разобрались со всеми подозрительными объектами, повторите алгоритм с шага 1, чтобы проверить, что теперь все работает нормально.



Заключение
Если вы прокликали все экраны в своем приложении и не нашли ни одного подозрительного объекта, то, с вероятностью 99.9%, в вашем приложении нет серьёзных утечек памяти.
Этих проверок действительно достаточно практически для любого приложения. Вас должны интересовать только утечки памяти, действительно способные повлиять на работу приложения. Утечка объекта, содержащего строковый uuid и пару коротких строк — это ошибка, на исправление которой просто не стоит тратить свое время.
Список литературы
- Investigating Your RAM Usage
https://developer.android.com/tools/debugging/debugging-memory.html - Java Performance blog
http://kohlerm.blogspot.ru/2009/07/eclipse-memory-analyzer-10-useful.html - Avoiding memory leaks
http://android-developers.blogspot.co.uk/2009/01/avoiding-memory-leaks.html - Memory Analysis for Android Applications
http://android-developers.blogspot.ru/2011/03/memory-analysis-for-android.html - Detecting a Memory Leak
http://blog.crowdint.com/2013/10/02/fixing-memory-leaks-in-android-applications.html - DEBUGGING MEMORY LEAKS ON ANDROID FOR BEGINNERS: PROGRAMMATIC HEAP DUMPING
http://novoda.com/blog/memory-debugging-on-android-part-1 - How To Identify If Your App is Leaking Memory
http://www.littleeye.co/blog/2013/04/24/identify-memory-leaks-android-apps/ - Fixing an Android Memory Leak
http://therockncoder.blogspot.ru/2012/09/fixing-android-memory-leak.html - Managing Your App’s Memory
https://developer.android.com/training/articles/memory.html - HUNTING YOUR LEAKS: MEMORY MANAGEMENT IN ANDROID
http://www.raizlabs.com/dev/2014/03/wrangling-dalvik-memory-management-in-android-part-1-of-2/
http://www.raizlabs.com/dev/2014/04/hunting-your-leaks-memory-management-in-android-part-2-of-2/ - How to discover memory usage of my application in Android
http://stackoverflow.com/questions/2298208/how-to-discover-memory-usage-of-my-application-in-android/2299813#2299813
ссылка на оригинал статьи http://habrahabr.ru/company/sebbia/blog/243537/
Восстановление PDP 11/04
Перевод статьи по восстановлению одной старой интересной машинки. Много тяжелых картинок. Курсивом мои комментарии.
Этот PDP 11/04 изначально принадлежал Ericsson. Мы получили его в конце восьмидесятых от EDKX — компьютерного клуба Ericsson. Компьютер был передан по частям, но всё было на месте за исключением пары винтиков. Вместе с самим PDP-11 шла ленточная станция TU60.

Панель операторской консоли
PDP-11/04 появился в середине семидесятых как удешевленный преемник PDP-11/05. В этой новой версии DEC смогла уместить всю процессорную логику на одной шестиконтактной плате (в PDP применялось несколько видов плат с различными форм-факторами — шестиконтактные, четырёхконтактные, двухконтактные. На фото чуть-чуть ниже видно 6 групп пинов. Кроме того платы разделялись по тому, на какую шину они рассчитаны.) вместо двух в предшественнике. Модули подключались к общей кросс-плате (backplate) с девятью слотами, выполненной монтажем накруткой. Обычно с PDP 11 шла программерская консоль (отдельная панель. PDP собиралась из нескольких блоков. что-то типа стойки с набором оборудования), через которую оператор мог вводить несложные загрузочные программы и проводить техобслуживание системы. Однако, именно этот экземпляр имел только обычную ограниченную операторскую консоль.

Кросс-плата
В книге Computer Engineering: A DEC view of hardware design семейство машин PDP-11 описывается очень подробно. Книга отсканирована и находится в публичном доступе. Очень увлекательное чтиво!

Плата CPU
Процессорный модуль состоит из 138 микросхем. Небольшое упрощение операционного автомата (datapath, часть процессора, которая выполняет операции над любыми данными. К примеру, это АЛУ, мультиплексоры, регистровые файлы, декодеры. В общем, практически это самая главная часть процессора.) и использование программируемой памяти позволило уменьшить число используемых чипов. На плате есть пять 256×8 биполярных программируемых микросхем ПЗУ, выделенных под хранение микрокода, который упакован в 40-битные структуры. Первые восемь бит отведены под адрес следующей микроинструкции. Интересной особенностью является то, что линия, по которой передаются эти адреса, реализована по схеме с открытым коллектором, что позволяет делать условные ветвления микрокода просто используя проводные OR-соединения прямо на шине. В качестве главного АЛУ, DEC взяли широко известные 74181, а микросхемы Intel 3101 16×4 RAM использовались в качестве сверхоперативной памяти (scratchpad memory) под основные регистры. Для тактирования нет отдельного кристалла, но вместо него присутствует линия задержки в цепи обратной связи.

Плата памяти
Нам достался PDP-11/04 с модулем памяти на 16 килобайт. Он содержит 32 MK4096, MOS-чипов динамической памяти, произведенных MOSTEK. Занятная ремарка — это была первая память с мультплесированной адресацией по колонке/строке, похожая схема используется и в современном DDR. Благодаря этому новшеству, инженеры MOSTEK’a смогли уместить 4 килобита памяти в 16-пиновый корпус.

Это карта M7800, модуль асинхронных коммуникаций DL11. (В PDP-11 применялась своя классификация модулей. К примеру, в схеме указано MS11-JP, что значит модуль памяти, но конкретные платы могли различаться — M7867-XJ, M7847-DJ или какая еще карта, соответствующая стандарту модуля. В данном случае DL11 это классификатор, а M7800 — конкретная плата.)

Последняя плата, M9312, используется для начальной загрузки системы, и, кроме того, выполняет роль терминатора шины. Вообще, в системе должно быть два терминатора, поскольку процессорный модуль сам по себе не выполняет данную функцию. Поэтому другой терминатор должен быть установлен на противоположном краю шины, в данном случае как можно ближе к процессорному модулю. На M9312 есть четыре разъема под биполярные программируемые ПЗУ, позволяющие обеспечить поддержку загрузки с разных устройств. Кроме этого на плате есть ППЗУ, которое содержит код эмулятора консоли для коммуникации с оператором через последовательный порт.
Компьютер разобран по винтикам в этом документе.
Проверяем блок питания H777
Первое, с чего нужно начать, это проверить, что с блоком питания всё в порядке. В частности, важно убедиться в том, что конденсаторы в хорошем состоянии. H777 является импульсным блоком питания с ключевым элементом во вторичной цепи, из чего следует, что он содержит огромный трансформатор (по сравнению со схемой с ключем в первичной цепи, он действительно большой), который понижает амплитуду входного переменного напряжения до куда более приятных в работе 38 VAC. Не очень здорово возиться с блоками питания, в которых почти на всех участках цепи напряжение в районе 400 VDC. H777 состоит из двух регуляторов: 5 вольтового, генерирующего 25 ампер, и MOS-регулятора, отдающего +15V, -15V, +5V (в других версиях H777 есть еще и третий регулятор на +20V, -5V).
Какая-то добрая душа отсканировала необходимый мануал, в котором в деталях описана вся внутренняя кухня этого БП.
Большие конденсаторы 50В x 22000мФ, фильтрующие нерегулируемый постоянный ток, смогли полностью зарядиться через 10кОм сопротивление, а ток утечки был крайне мал. Выходной конденсатор на 5В был в куда худшей форме. Конденсатор 6В x 3900мФ от Sprague, на впечатляющих ножках, ни разу не достигал номинального напряжения, даже при долгом использовании с 560 Ом резистором.

Слева — подпорченный временем элемент, справа — его замена
В настоящее время таких конденсаторов 6В x 3900мФ с креплением болтами не найти, поэтому я заменил его на 40В x 6800мФ от RIFA.
С новым конденсатором БП смог выдать 3 ампера на мою тестовую плату, от которой вскорости потянулся приятный аромат разогретого гетинакса (макетки часто из этого материала делают).

Процесс проверки БП. Кстати, виден здоровый трансформатор первичной цепи
Но заработает ли всё это, если подключить БП к кросс-плате? К сожалению, не заработало. Выяснилось, что два сигнальных контакта БП находятся в перманентно низком состоянии: BUS DC LO L и BUS AC LO L. Эти сигналы с активным низким уровнем, и в активном состоянии подавляют тактовый генератор главного процессора.
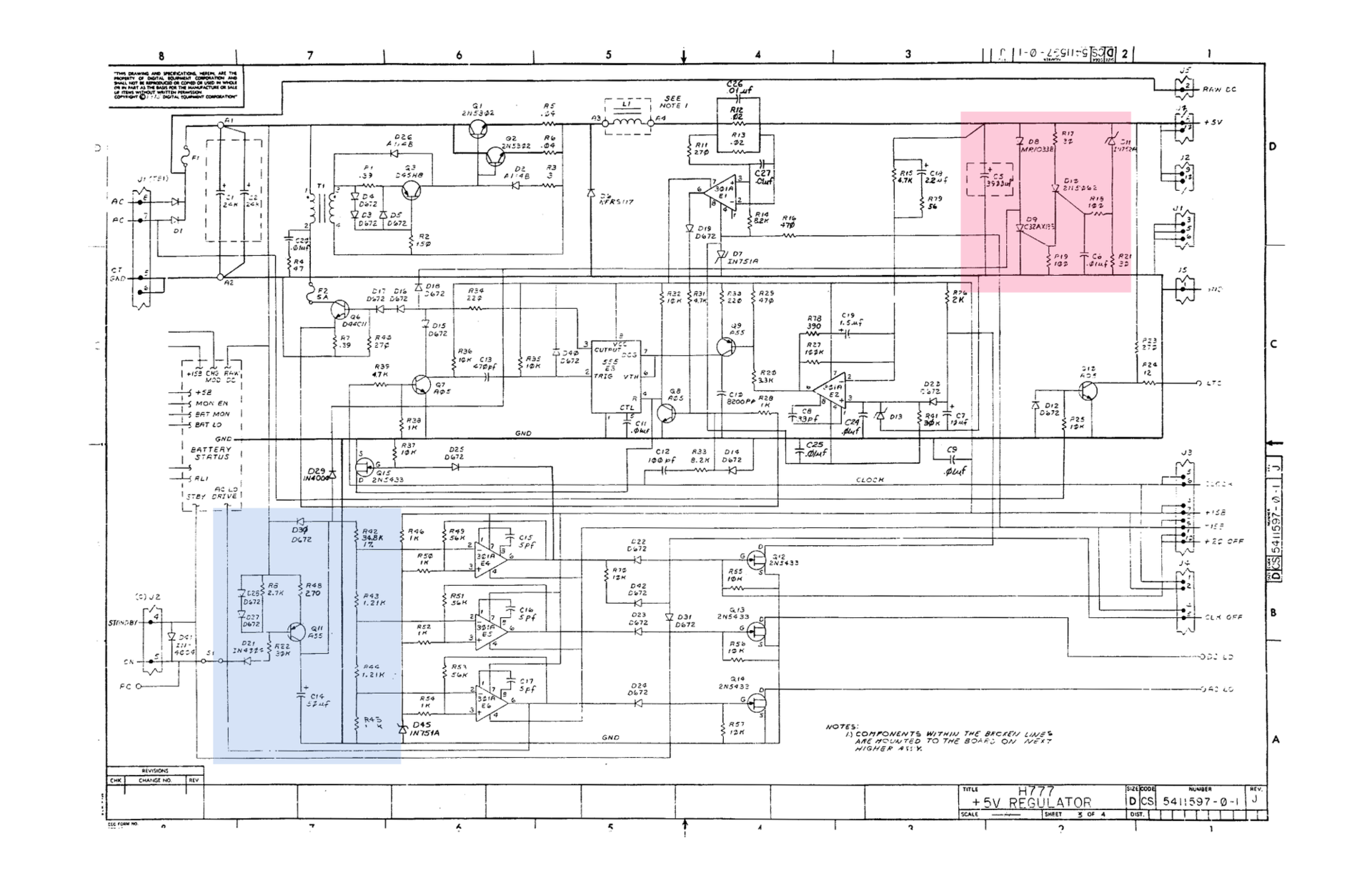
Схема выше описывает 5-вольтовый регулятор. Выделенная голубым область это цепь источника тока, которая на вход получает нерегулируемый постоянный ток, заряжая 50мФ конденсатор, который затем выдаёт красивый пилообразный сигнал. Резисторная матрица и набор компараторов (операционные усилители, которые выступают здесь в роли компараторов напряжения) генерируют BUS DC LO L, BUS AC LO L и внутренний сигнал, на котором основывается тактирование главного ШИМ-ключа. Напряжение на конденсаторе не превосходило 20.4 вольта, что недостаточно для смены полярности двух компараторов. Это выглядело так, как будто слишком много тока поглощается с этого источника. Замена конденсатора ничего не изменила. Но, кроме источника тока, к конденсатору подключена красная область схемы — цепь защиты от перегрузок. Если какой-нибудь из транзисторных ключей сбойнёт, то на выход пойдёт 38 вольт нерегулируемого постоянного тока. Что, само-собой, не очень хорошо. Поэтому здесь используется стабилитрон и пара тиристоров, которые срабатывают при выходном напряжении больше 5.4 VDC, что приводит к короткому замыканию в источнике тока, и, в свою очередь, крайне эффективно останавливает любую активность в блоке питания. Проблема, видимо, была в том, что даже при нормальных условиях защитной цепью поглощалось 1.5 мА из-за утечки тиристора, причём в зактрытом состоянии. Конечно же, любой тиристор течёт, но не настолько сильно как этот.

сломанный тиристор, возможно C32AX135
После замены тиристора на современный BT145, блок питания заработал как надо.
Проверка процессора
Подключаем все кабели и включаем питание. Дыма не видно, что является хорошим знаком. Но лампочка «RUN» часто мерцает, а, после переключения соответствующего тумблера на консоли в значение «INIT», и, вовсе, только раз коротко мигнула. Ситуация не обнадеживающая.
Подключенный к главному тактовому сигналу процессорного модуля осциллограф показывает, что в начале идут 8 тактов, затем пауза на пару микросекунд, 3 такта, еще одна пауза и опять 3 такта, но за ними уже ничего не следует.

На этом фото можно заметить, что период синхросигнала ближе к 250нс чем к 260нс, про которые написано в «Computer Engineering». Однако, использование линии задержки в цепи обратной связи и не сможет дать такую точность. Тем не менее, 4 МГц очень впечатляющий результат для середины семидесятых.
Скорее всего, в дальнейшем выяснении причин неполадки осциллограф помочь не смог бы. Для такого рода задач я держу этот маленький USB-анализатор.

Но для того чтобы охватить весь компьютер с его шинами адреса и данных, мне нужно четыре таких. К счастью, мне в тот момент предложили купить логический анализатор HP1664A по доступной цене.
Поиск ошибок с использованием логического анализатора
После некоторых проблем в начале, когда я перепутал некоторые сигналы и забыл про то, что плата использует активно-низкие уровни, я получил несколько занимательных логов трассировки:

Здесь отображены значение шины, по которой передаются адреса микро-инструкций на выполнение. На самом деле, здесь показывается адрес следующей микро-инструкции, во время выполнения текущей. Однако, судя по мануалу, это вполне корректная последовательность микро-операций (если действительно интересно, то глава 6.3.3 Restarts from power failure).

Интересно в логе сверху то, что, при выставлении на шине адреса значения 026, мы получаем 0165020, являющееся значением счетчика команд, содержащего адрес, с которого мы должны начать исполнение после сбоя питания. Данный адрес принадлежит M9312 и указывает на программу диагностики. Но следующий адрес инструкции, выставленный на шине, — 0167020. По какой-то причине 10-ый бит оказался единицей! Исследуя более подробно чип-приёмник шины DS8641, заметил, что даже при входном токе в 3.31В, на выходе получаем 3.78В! Выглядит странновато.
Оно живое!
Вот, эта маленькая злостная штуковина:

К сожалению, DS8641 не особо распространенная микросхема. К тому же, она была специально адаптирована к шинам с открытым коллектором для DEC’a. Я заказал несколько на Ebay у продавца из Китая, но, так как идёт посылка довольно долго, я решил выпаять такой же чип с другой платы, и заменить им сбоящую микросхему в процессорном модуле.
На этот раз результат был лучше:
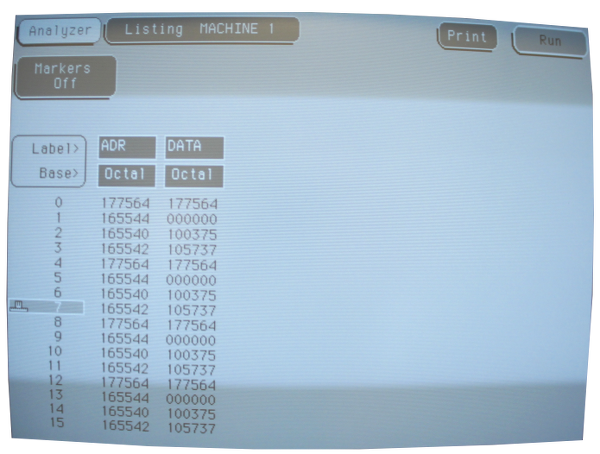
Тем не менее, всё заканчивается зацикленным ожиданием бита готовности TX консольного последовательного порта. Странно. Может дело в ошибке M7800?
Еще одна плата M7800
Другой модуль M7800 был подключен к кросс-плате. Последовательный порт подключил к ноутбуку.
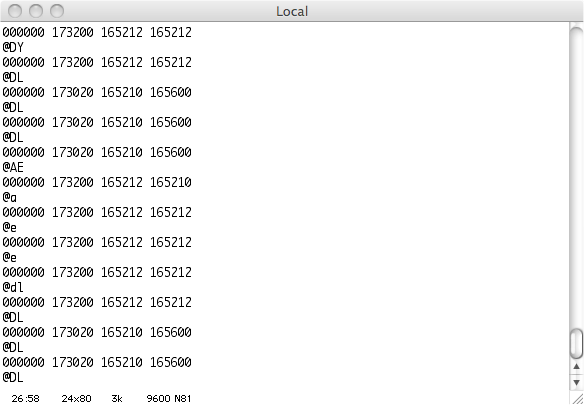
Отлично. Теперь система проходит все диагностические шаги с первого по четвёртый. Но ввод «DL» в консоли для того, чтобы попытаться загрузиться с несуществующего RL-устройства (RL01/RL02 — что-то типа жестких дисков, но со сменными картриджами с данными.), приводит к остановке машины.

Похоже на то, что при попытке протестировать оперативную память, происходит сбой, и затем, сразу же, получаем двойную ошибку во время обработки первой. Такое поведение характерно для обработки исключения (точнее ловушки, trap) процессором.
Корявый DIP-переключатель!
Во время исследования модуля памяти и проверки джамперов и позиций переключателей, я обнаружил, что при щелкании туда и обратно DIP-переключателем, игнорируется положение 6-ого ключа из 8ми, и цепь остаётся замкнутой. Проблемка.

Слева — новый переключатель, справа — старый.
Наконец-то, компьютер запустился!
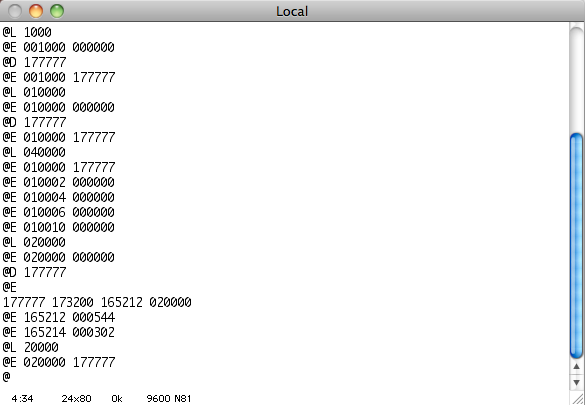
Понять, что он работает, можно по тому, что автор вводит консольные команды в терминале: @L — загрузить адрес, @E — проверить данные по адресу, @D — записать данные по загруженному адресу.
PDP11GUI
PDP11GUI — отличная утилита под Windows для управления вашим PDP-11. Она умеет загружать файлы в память PDP-11, просматривать слепок памяти и запускать процессор.
Перфоленты с BASIC’ом могут быть найдены на просторах интернета. Но, к сожалению, они в формате Absolute Binary Loader, который PDP11GUI не понимает. Однако, можно написать простенькую программу на Си для конвертирования. Полученный файл можно уже скармливать мини-ЭВМ, но это всё очень медленно на линии 9600bps.
Скрытый текст
#include <stdio.h> #include <stdlib.h> int main (int argc, char ** argv) { FILE * input, * output; int ch, state = 0, count, size, sum = 0, address, data=0, start=0; if (argc==3) { input = fopen (argv[1], "rb"); if (input == NULL) { fprintf(stderr, "cannot open file %s for reading\n", argv[1]); exit(1); } output = fopen (argv[2], "w+"); if (output == NULL) { fprintf(stderr, "cannot open file %s for reading\n", argv[2]); exit(1); } } else { fprintf(stderr, "Usage conver <input> <output>"); exit(1); } while(!feof(input)) { ch = fgetc (input); //fprintf (stderr, "state=%d ch=%02x sum=%02x count=%d start=%d\n", state, ch, sum, count, start); switch (state) { case 0: if (ch != 1) state = 0; else { state = 1; count = 1; sum += ch; sum &= 0xff; } break; case 1: if (ch != 0) state = 0; else { state = 2; count ++; sum += ch; sum &= 0xff; } break; case 2: // read low count byte size = ch; state = 3; sum += ch; sum &= 0xff; count ++; break; case 3: // read count size = size | (ch << 8); state = 4; sum += ch; sum &= 0xff; if (size==6) { start = 1; } count ++; break; case 4: // read address low address = ch; sum += ch; sum &= 0xff; state = 5; count ++; break; case 5: address = address | (ch << 8); state = 6; sum += ch; sum &= 0xff; count ++; if (count == size) { state =0; } if (start==1) { fprintf (stderr, "Start at %06o\n", address); fclose (input); fclose (output); exit(0); } break; case 6: data = ch; sum += ch; sum &= 0xff; count ++; if (count == size) { state = 7; } else { state = 8; } break; case 8: sum += ch; sum &= 0xff; data = data | (ch <<8); fprintf (output, "%06o %06o\n",address, data); address +=2; count++; if (count == size) { state = 7; } else { state = 6; } break; case 7: // checksum sum += ch; sum &= 0xff; if (sum!=0) { fprintf (stderr, "Checksum error chsum = %02X\n", sum); exit(1); } sum = 0; state = 0; } } }
UPDATE: В версии 1.38 PDP11GUI уже не нуждается во внешней программе, так как код конвертации был включен в PDP11GUI. (Да-да, в оригинале 5 одинаковых ссылок на PDP11GUI).
Запустив PDP с начальным адресом 016104, получим приглашение BASIC’a (очевидно, что запуск проходил через ту тулзу, в коей есть соответствующая настройка «initial PC»).

Заметно, что я уже очень давно не писал ничего на BASIC’e.
Запуск диагностик
Для настоящей проверки того, что процессор работает так как надо, существует две диагностических программы — GKAA и GKAB. Есть два способа запустить их: загрузить в PDP11GUI образ перфоленты или использовать XXDP. Я испробовал оба метода.
Точно известно, что эти программы хранились на перфоленте, но, увы, я не смог найти образы этих перфолент. Но я нашёл образ для XXDP, который содержал GKAAA0.BIC и GKABC0.BIC. Оказывается, что бинарники имеют тот же формат что и перфоленты. Я использовал PUTR для извлечения их из образа. Не забудьте, что файлы нужно копировать как бинарные, а не то, так же как и я, будете ломать голову несколько часов (PUTR предоставляет некий DOS-подобный интерфейс, и нужно делать «copy /b» вместо просто «copy»).
После извлечения, я просто загрузил образы в PDP11GUI и запустил с адреса 0200.
Загрузка XXDP
XXDP должен запускаться с какого-нибудь запоминающего устройства. Мне подходит только одна опция, которая была бы достаточно простой для использования на моём PDP-11 в тот момент, — TU58 (ленточная система), так как она использует последовательный порт для подключения, и поэтому может быть сэмулирована на ПК. Я скачал tu58em и скомпилировал на своём Маке. Нужно было сделать всего несколько правок в коде работы с последовательным портом для того, чтобы программа успешно скомпилировалась.
После этого я начал работать над созданием загрузочного образа с XXDP. Такого рода работа может быть выполнена значительно быстрее с использованием эмулятора PDP-11. Я использовал E11. Сначала я попробовал XXDP 2.6, найденный в виде образа на bitsavers:
Скрытый текст
Ersatz-11 V7.0 Demo version, COMMERCIAL USE LIMITED TO 30-DAY EVALUATION Copyright (C) 1993-2013 by Digby's Bitpile, Inc. All rights reserved. See www.dbit.com for more information. E11>assign tt1: dda: E11>mount dda0: dddp.dsk E11>set cpu 04 E11>set mem 16 E11>boot tt1: %HALT ?Bad kernel stack R0/000000 R1/176506 R2/000000 R3/000066 CM=K PM=K PRIO=0 R4/100020 R5/000000 SP/057774 PC/000006 N=0 Z=0 V=0 C=0 000006 halt E11>set mem 24 E11>boot tt1: CPU NOT SUPPORTED BY XXDP-XM BOOTING UP XXDP-SM SMALL MONITOR XXDP-SM SMALL MONITOR - XXDP V2.6 REVISION: E0 BOOTED FROM DD0 12KW OF MEMORY UNIBUS SYSTEM RESTART ADDRESS: 052010 TYPE "H" FOR HELP .R GKABC0 GKABC0.BIC %HALT R0/000357 R1/000000 R2/000300 R3/054426 CM=K PM=K PRIO=0 R4/000001 R5/000776 SP/000500 PC/012006 N=0 Z=0 V=0 C=0 012006 cmp 177776,#000000 E11>
Но он требовал больше памяти, чем было на моей машине, поэтому использовать эту версию никак не получилось бы. Кроме того, GKAB совсем не хотел запускаться на эмулируемом PDP-11/04 по неизвестной причине.
После этого я потратил время на то, чтобы сделать TU58-образ для XXDP+, более ранней версии пакета XXDP. Вот как это у меня получилось в E11:
Скрытый текст
.R UPD2 CHUP2A2 XXDP+ UPD2 UTILITY RESTART: 002432 *ZERO DD0: *DRIVER DD0: *LOAD DY0:HMDDA1.SYS XFR:005034 CORE:000000,017774 *SAVM DD0: *PIP DD0:HMDDA1.SYS=DY0:HMDDA1.SYS *PIP DD0:HDDDA1.SYS=DY0:HDDDA1.SYS *PIP DD0:GKA???.BIC=DY0:GKA???.BIC GKAAA0.BIC GKABC0.BIC *PIP DD0:HELP.TXT=DY0:HELP.TXT *PIP DD0:HUDIA0.SYS=DY0:HUDIA0.SYS *PIP DD0:HSAAA0.SYS=DY0:HSAAA0.SYS *PIP DD0:UPD?.BIN=DY0:UPD?.BIN UPD1 .BIN UPD2 .BIN *PIP DD0:SETUP.BIN=DY0:SETUP.BIN E11>set cpu 04 E11>set mem 16 E11>boot tt1: CLEARING MEMORY CHMDDA0 XXDP+ DD MONITOR 8K BOOTED VIA UNIT 0 ENTER DATE (DD-MMM-YY): RESTART ADDR:033726 50 HZ? N Y LSI? N THIS IS XXDP+. TYPE "H" OR "H/L" FOR DETAILS .DIR ENTRY# FILNAM.EXT DATE LENGTH START 000001 HMDDA1.SYS 22-MAR-80 17 000050 000002 HDDDA1.SYS 22-MAR-80 3 000071 000003 GKAAA0.BIC 11-AUG-76 15 000074 000004 GKABC0.BIC 29-JAN-77 16 000113 000005 HELP .TXT 22-MAR-80 26 000133 000006 HUDIA0.SYS 22-MAR-80 6 000165 000007 HSAAA0.SYS 22-MAR-80 24 000173 000010 UPD1 .BIN 22-MAR-80 12 000223 000011 UPD2 .BIN 22-MAR-80 16 000237 000012 SETUP .BIN 22-MAR-80 26 000257 .R GKABC0 %HALT R0/000357 R1/000000 R2/000300 R3/032240 CM=K PM=K PRIO=0 R4/000001 R5/000776 SP/000500 PC/012006 N=0 Z=0 V=0 C=0 012006 cmp 177776,#000000
GKAAA0.BIC под XXDP+ на настоящей машине запустился успешно. Большая часть системы в отличном состоянии! Вот ссылка на образ, который я сделал.
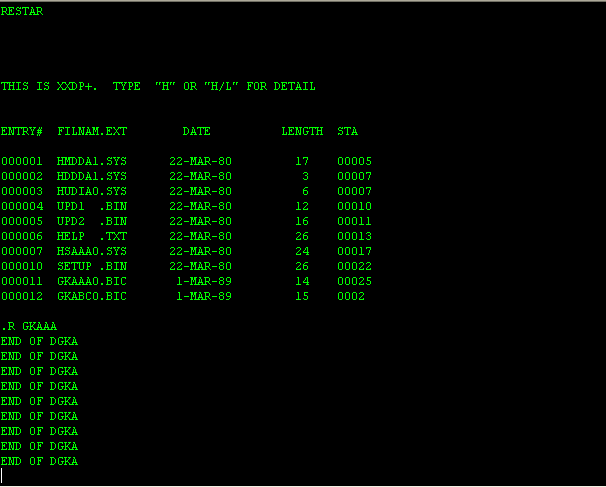
Но запуск GKABC0 закончился остановкой системы. Невозможно найти исходники для конкретной версии утилиты, но версия под PDP-11/34 должна подойти. Просматривая код, можно заметить, что участок, в котором происходит остановка системы, это проверка логики обработки переполнения стека. Устанавливается указатель стека в значение 0400, а затем дергается консольное TX-прерывание (видимо имеется в виду инструкция IOT, вызывающее прерывание 020, на которое OS обычно вешает I/O обработчик). При этом указатель стека становится меньше 0400, что ведёт к генерации исключения, номер вектора обработки которого 4 или 6. На моей машине поведение было иное — генерировались всё новые и новые консольные прерывания до тех пор, пока стек не достигал 0177774 (физической памяти по этому адресу нет), а затем останавливался с двойной ошибкой шины.
Глючный DL11-W!
Меняя платы, я заметил, что использование другой DL11-W, устраняет проблему. Похоже, что в DL11-W логика обработки прерываний сломана. Прерывание должно быть очищено, как только процессор отвечает SSYN (сигнал шины Unibus, своего рода handshake). Этого не происходило на сломанной карте. Только процессор начинал обработку прерывания, как получал его снова и снова. Процесс работы с прерываниями на шине Unibus не очень сложен. Устройство устанавливает сигнал BRn, а процессор отвечает установкой BGn, когда он готов к обслуживанию прерывания. После этого устройство, в свою очередь, отвечает SACK, устанавливает номер вектора прерывания и подтягивает INTR. Трассировка ниже взята с работающей карты:
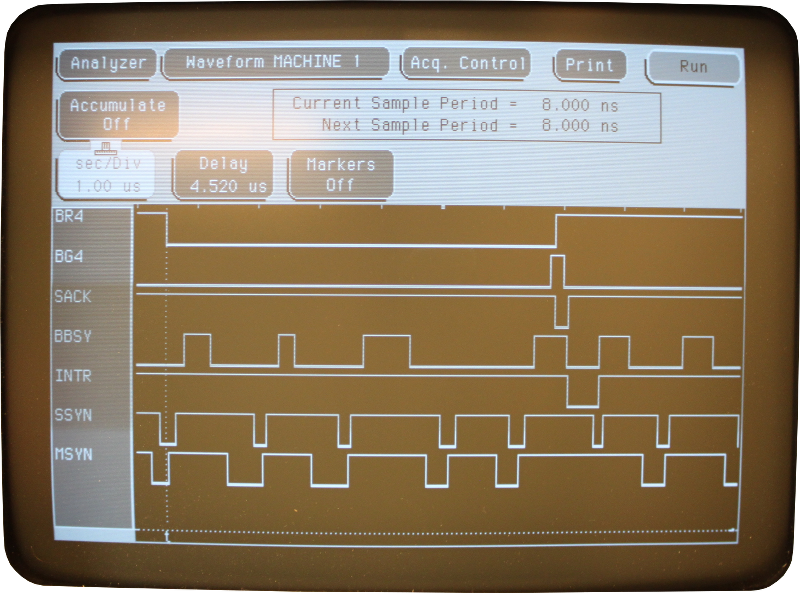
Не забываем, что в PDP-11 активный уровень сигнала — низкий
Схема показывает триггер прерывания и вентиль, который должен очищать сигнал прерывания, когда оно уже обслужено.
Данная нечеткая фотография ясно показывает сбоящий 7408 AND-вентиль на сломанной плате.

7408 здесь обозначен как E4, 12 и 13 — входные сигналы, 11 — выходной, который должен, по идее, очищать прерывание, когда находится в низком состоянии. Этого не происходит, и прерывания всё идут и идут.
На этом починка основного блока плат окончена, во второй части статьи чиним ленточную станцию TU60, а в третьей — терминал LA30 Decwriter.
ссылка на оригинал статьи http://habrahabr.ru/post/243551/