Терминология
Для начала определимся с терминологией.
Sku (Stock-keeping unit) — это номер, код или какой-либо другой идентификатор уникального товарного продукта в розничных сетях/магазинах. На постсоветском пространстве это понятие немного адаптировалось и под ним начали понимать уже не сам идентификатор, а описание этой товарной позиции (Например типичным Sku наших розничных сетей является: «Батончик шоколадный 50г Марс»). А для каждого такого Sku ставят в соответствие артикул.
Проблемы
В чем собственно проблема?
Проблемы возникают когда необходимо получить информацию не по конкретным розничным сетям или магазинам, а по регионам, странам или в целом продажи этого продукта.
Проблемы:
- Каждая розничная сеть использует свои уникальные Sku и артикулы;
- Sku некоторых сетей достаточно сильно сжимаются для экономии места на чеках, что затрудняет идентификацию товарной позиции (Пример: «К.КгВафВеселЖуравРош»);
- Периодически возникает необходимость получить продажи не по конкретным товарным позициям, а по товарным группам (Например: «Шоколадные батончики»), тогда даже полноценные красивые Sku нам ничем не помогут.
Если вам интересно как мы пытались автоматизировать процесс свода товарных справочников разных розничных сетей — добро пожаловать под кат.
Поскольку товарные справочники сетей оставляют желать лучшего, очевидным было решение создавать свой. Но его надо наполнять товарными позициями, которые были представлены в продажи, а для этого необходимо приводить все Sku к единому стандартизированному виду. Например, для упомянутых выше примеров (кондитерские изделия) необходимо «разложить» каждое Sku на несколько составляющих: Производитель, Торговая марка, Название, Группа товаров, Категория, Вес, Упаковка, Акция(при ее наличии). Первоначально разбор осуществлялся в рукопашную группой людей, но его результативность была крайне низка (порядка 5-10 мин. на одну запись одним человеком). Поэтому было принято решение о попытке автоматизации этого процесса.
Создание алгоритма
Задача: есть история всех заполнений (какое Sku соответствовало каким значением каких полей), необходимо для текущего Sku подобрать наиболее вероятные значения параметров.
Решение:
В первую очередь, как легко заметить, каждое Sku с легкостью можно разбить на составляющие (токены) каждый из которых несет в себе какой-то логический смысл. После разбивки каждого Sku на токены, необходимо привести табличку истории к удобному для дальнейшей работы виду:
- Токен (Например: Рош);
- Поле (Например: Торговая марка);
- Значение (Например: Roshen);
- Количество записей с таким токеном (Например: 100);
- Процент (вероятность) среди них, который соответствует данному значению (Например: 0,9).
И после каждого добавления нового Sku будем актуализировать содержимое этой таблички.
На основе этой истории потом достаточно просто рассчитать вероятность для каждого значения, каждого поля. Так например вероятность того, что Торговая марка продукции Roshen, будет равна:
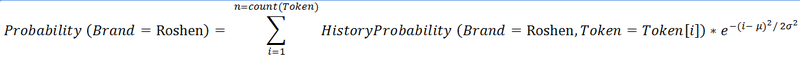
где HistoryProbability — вероятность вытянутая из таблички истории (Поле: Торговая марка, Значение: Roshen, Токен: пробегает значение всех токенов Sku);
экспонента ответственна за то, что каждая логическая единица пишется в большей части Sku на определенной позиции (для каждой розничной сети, и каждой группы товара эти позиции разные). Так с помощью параметров этой экспоненты мы можем устанавливать, на каких позициях вероятнее всего встретиться та или иная логическая единица, а где вероятность ее встретить значительно меньше. Пример: 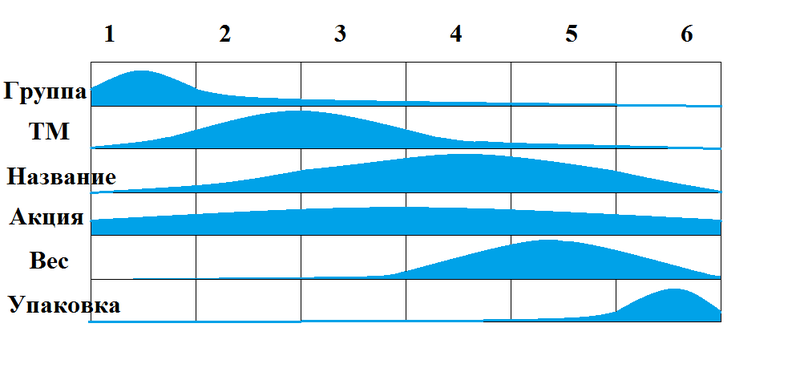
Просчитав такие вероятности для каждого возможного варианта просто выбираем максимум по каждому полю. Также были дополнительные попытки ввести анализ «похожести» токенов, их переводов, транслитерации, etc. Однако результаты экспериментов показали, что при достаточно большой истории описанный метод дает наиболее приятные результаты.
Вывод
К сожалению, полностью отказаться от человеческого труда не удалось, поскольку это всего лишь машина, и у нее бывают ляпы, а в данной задачи нам очень важна точность. Однако нам удалось простым алгоритмом оптимизировать человеческую работу, ускорив от 5-10 до 0,25-0,75 мин. на запись (при «богатой» истории и этот показатель все ближе устремляется к 15 секундам с наращиванием истории).
ссылка на оригинал статьи http://habrahabr.ru/post/163965/