Последняя статья Олега Гельбуха дала обзор различных аспектов бесперебойности в OpenStack. Все компоненты OpenStack разработаны с учетом бесперебойности, но платформа использует и внешние ресурсы, как, например, базу данных и систему обмена сообщениями. И это забота пользователя — развернуть эти внешние ресурсы для безотказной работы.
Очень важно помнить, что все ресурсы с фиксацией состояния в OpenStack используют систему обмена сообщениями и базу данных, а все остальные компоненты не хранят информацию о состоянии (за исключением Glance). База данных и система обмена сообщениями являются ключевыми для платформы OpenStack. В то время как система управления очередью позволяет нескольким компонентам обмениваться сообщениями, база данных хранит состояние кластера. Обе эти системы принимают участие в каждом запросе пользователя, как при отображении списка виртуальных объектов, так и при создании новой виртуальной машины.
По умолчанию для обмена сообщениями используется RabbitMQ, а база данных по умолчанию — MySQL. В отрасли известны надежные решения и по нашему опыту их достаточно для масштабирования даже в крупных установках. В теории подойдет любая база данных, поддерживающая SQLAlchemy, но большинство пользователей пользуются базой данных по умолчанию. Для обмена сообщениями трудно найти альтернативу RabbitMQ, хотя некоторые пользуются драйвером ZeroMQ для OpenStack.
Как в OpenStack работают сообщения и база данных
Давайте для начала рассмотрим, как база данных и система обмена сообщениями вместе работают в OpenStack. Для начала я опишу поток данных при наиболее популярном запросе пользователя: создание экземпляра виртуальной машины.
Пользователь отправляет свой запрос в OpenStack, взаимодействуя с компонентом nova-api. Nova-api обрабатывает запрос на создание экземпляра, вызывая функцию create_instance из API-интерфейса nova-compute. Функция делает следующее:
— Проверяет данные, введенные пользователями: (например, проверяет, что существует запрошенный образ ВМ, разновидность, сети). Если они не определены, она пытается получить значения по умолчанию (например, разновидность, сеть по умолчанию).
— Проверяет запрос на предмет соответствия ограничениям пользователя.
— После того, так описанная выше проверка дала положительные результаты, создает запись об экземпляре в БД (функция create_db_entry_for_new_instance).
— Вызывает функцию _schedule_run_instance, которая передает запрос пользователя компоненту nova-scheduler через очередь сообщений с помощью протокола AMQP. Тело запроса содержит параметры экземпляра:
request_spec = {
‘image’: jsonutils.to_primitive(image),
‘instance_properties’: base_options,
‘instance_type’: instance_type,
‘num_instances’: num_instances,
‘block_device_mapping’: block_device_mapping,
‘security_group’: security_group,
}
Функция _schedule_run_instance завершается отправкой сообщения AMQP с вызововм функции scheduler_rpcapi.run_instance.
Теперь в работу вступает планировщик. Он получает сообщение со спецификацией узла и на основе него и своих политик планирования пытается найти подходящий узел для создания экземпляра. Это выдержка из файлов журнала nova-scheduler в процессе выполнения этой операции (здесь используетя FilterScheduler):
Host filter passes for ubuntu from (pid=15493) passes_filters /opt/stack/nova/nova/scheduler/host_manager.py:163
Filtered [host ‘ubuntu’: free_ram_mb:1501 free_disk_mb:5120] from (pid=15493) _schedule /opt/stack/nova/nova/scheduler/filter_scheduler.py:199
Он выбирает узел с наименьшими затратами, применяя функцию взвешивания (здесь только один узел, поэтому в данном случае операция взвешивания ничего не меняет):
Weighted WeightedHost host: ubuntu from (pid=15493) _schedule /opt/stack/nova/nova/scheduler/filter_scheduler.py:209
После того, как бы определен вычислительный узел, на котором необходимо запустить экземпляр, планировщик вызывает функцию cast_to_compute_host, которая:
— Обновляет запись об узле для экземпляра в базе данных nova (узел = вычислительный узел, на котором будет создан экземпляр) и
— Отправляет сообщение по протоколу AMQP сервису nova-compute на этом конкретном узле, чтобы запустить экземпляр. Сообщение включает UUID экземпляра для запуска и следующее действие, которое необходимо предпринять, то есть:run_instance.
В ответ сервис nova-compute на выбранном узле вызывает метод _run_instance, который получает параметры экземпляра из базы данных (на основе UUID, который был передан) и запускает экземпляр с соответствующими параметрами. Во время настройки экземпляра nova-compute также взаимодействует по протоколу AMQP с сервисом nova-network для настройки сетевого взаимодействия (в том числе назначения IP-адреса и настройки DHCP-сервера). Состояние виртуальной машины на разных этапах процесса создания фиксируется в базе данных nova с помощью функции _instance_update.
Как можно видеть, для коммуникации между различными компонентами OpenStack используется протокол AMQP. Кроме того, база данных обновляется несколько раз, чтобы отображать состояние инициализации виртуальной машины (ВМ). Таким образом, если мы потеряем какой-либо из следующих компонентов, мы значительно нарушим основные функции кластера OpenStack:
— Потеря RabbitMQ приведет к невозможности выполнять любые задачи пользователя. Также некоторые ресурсы (как, например, развертываемая ВМ) останется в разобранном состоянии.
— Потеря базы данных приведет к ещё более разрушительным последствиям: все экземпляры будут работать, но не смогут определить, кому они принадлежат, на какой узел они попали или какой у них IP-адрес. Принимая во внимание, какое число ВМ может быть запущено у вас в облаке (возможно несколько тысяч), эту ситуацию невозможно исправить.
Решения HA для базы данных
Вы можете предотвратить сбой базы данных с помощью тщательного резервирования и репликации данных. В случае с MySQL существует много решений с подробным описанием, в том числе MySQL Cluster (“официальный” набор для кластеризации MySQL), MMM (инструмент управления тиражированием с несколькими основными репликами) и XtraDB из Percona.
Кластер MySQL
Кластер MySQL работает на основе специального движка для хранения под названием NDB (Network DataBase). Движок представляет собой кластер серверов под названием “узлы данных”, который управляется “узлом управления”. Данные сегментируются и реплицируются между узлами данных и для каждой единицы данных существует как минимум две реплики. Все реплики обязательно располагаются на разных узлах данных. Поверх узлов данных запущена ферма серверов MySQL с хранилищем NDB в серверной части. Каждый из процессов mysqld обладает возможностью чтения/записи и позволяет распределять нагрузку для обеспечения эффективности и бесперебойности.
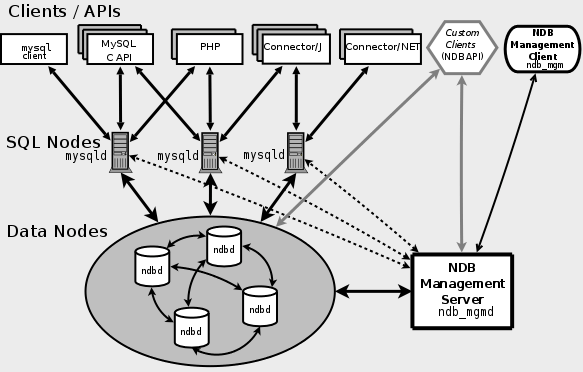
Кластер MySQL гарантирует синхронную репликацию , что является явным недостатком традиционного механизма репликации. У него есть некоторые ограничения по сравнению с другими движками хранения (хороший обзор расположен по этой ссылке).
Кластер XtraDB
Это решение признанной в отрасли компании Percona. XtraDB Cluster состоит из набора узлов, на каждом из которых запущен экземпляр Percona XtraDB с набором дополнений для поддержки репликации. Дополнения содержат набор процедур для обмена данными с движком хранения InnoDB и позволяют ему создать на нижнем уровне систему репликации, соответствующую спецификации WSREP.
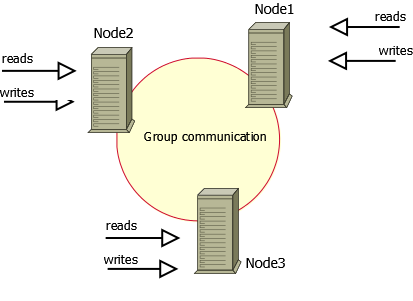
На каждом кластерном узле запущена версия mysqld с дополнениями от Percona. Также на каждом из них располагается полная копия данных. Каждый узел позволяет выполнять операции чтения и записи. Как и MySQL Cluster, XtraDB Cluster имеет некоторые ограничения, описанные здесь.
MMM
Инструмент управления тиражированием с несколькими основными репликами (MultiMaster replication Manager) использует для репликации традиционный механизм “master-slave”. Он работает на основе набора серверов MySQL с как минимум двумя основными репликами с набором подчиненных реплик, а также с выделенным узлом мониторинга. Поверх этого набора узлов настраивается пул IP-адресов, который MMM может динамически перемещать от узла к узлу, в зависимости от их доступности. У нас есть два типа этих адресов:
— “Записывающий”: клиент может записывать в базу данных, подключаясь к этому IP-адресу (во всем кластере может быть только один адрес записывающего узла).
— “Читающий ”: клиент может читать в базе данных, подключаясь к этому IP-адресу (может быть несколько читающих узлов для масштабирования чтения).
Узел мониторинга проверяет доступность серверов MySQL и включает перенос “записывающих” и “читающих” IP-адресов в случае отказа сервера. Набор проверок относительно прост: он включает проверку доступности сети, проверку присутствия mysqld на узле, присутствия ветки репликации и размера журнала репликации. Распределение нагрузки по чтению между “читающими” IP-адресами выполняется пользователем (его можно сделать с помощью HAProxy или циклического перебора DNS и т.п.).
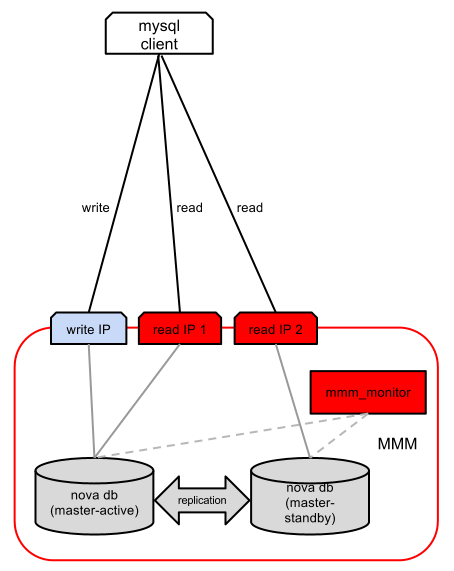
MMM использует традиционную асинхронную репликацию. Это значит, что всегда есть шанс, что в момент сбоя мастера реплики отстают от мастера. Сейчас используется одна ветка репликации, чего часто недостаточно в многоядерном мире с большим объемом транзакций, особенно когда выполняются долгие запросы на запись. Эти соображения устраняются в будущей версии MySQL, которая реализует набор функций для оптимизации бинарного лога (binlog) и бесперебойности HA.
Что касается обучающих материалов OpenStack в отношении бесперебойности MySQL, Алессандро Тальяпьетра (Alessandro Tagliapietra) представляет интересный подход (статья описывает только OpenStack) к обеспечению доступности MySQL с помощью репликации “master-slave", а также Pacemaker с агентом Percona’s Pacemaker.
Обеспечение бесперебойности (HA) для очереди сообщений
По своей природе данные RabbitMQ очень часто меняются. Так как для обмена сообщениями важны скорость и объем данных, все сообщения хранятся в RAM, если вы не определили очереди как “устойчивые” – в этом случае RabbitMQ записывает сообщения на диск. Эта возможность поддерживается OpenStack с помощью параметра rabbit_durable_queues=True в nova.conf. Хотя сообщения записываются на диск и таким образом не пропадут при сбое или перезагрузке сервера RabbitMQ, это не является настоящим решением для обеспечения бесперебойности, так как:
— RabbitMQ не выполняет fsync н а диск при получении каждого сообщения, поэтому при сбое сервера в буфере файловой системы могут быть сообщения, не записанные на диск. После перезагрузки они будут потеряны.
— RabbitMQ все ещё располагается только на одном узле.
Можно выполнить кластеризацию RabbitMQ и кластеризованный RabbitMQ называется “посредником”. Кластеризация сама по себе больше предназначена для масштабирования, чем для обеспечения бесперебойности. Тем не менее, у неё есть большой недостаток— выполняется репликация всех виртуальных узлов, коммутирующих элементов, пользователей, за исключением самих очередей сообщений. Для того чтобы исправить этот недостаток, была реализована функция зеркалирования очередей. Создание посредника, а также зеркалирование очереди, необходимо сочетать для полной отказоустойчивости RabbitMQ.
Также существует решение на основе Pacemaker, но оно считается устаревшим по сравнению с описанным выше.
Следует заметить, что ни один из описанных выше режимов кластеризации не поддерживается напрямую в OpenStack; тем не менее, Mirantis имеет достаточно богатый опыт в этой области (об этом ниже).
Опыт развертывания в Mirantis
Компания Mirantis выполняла установки высокодоступного MySQL с помощью MMM (инструмент управления тиражированием с несколькими основными репликами) для нескольких клиентов. Хотя некоторые разработчики выражали озабоченность ошибками в MMM в сетевых дискуссиях, в нашем опыте мы не встретили значительных сбоев этого инструмента. Мы считаем его достаточным и приемлемым решением. Тем не менее, мы знаем, что есть люди, у которых много проблем с этим решением и поэтому сейчас рассматриваем архитектуры на основе подхода синхронной репликации WSREP, так как он по определению обеспечивает большую целостность данных и управляемость ими, а также более простую настройку (например, Galera Cluster, XtraDB Cluster).
Ниже приведена иллюстрация настройки, которую мы выполнили для крупномасштабной установки OpenStack:
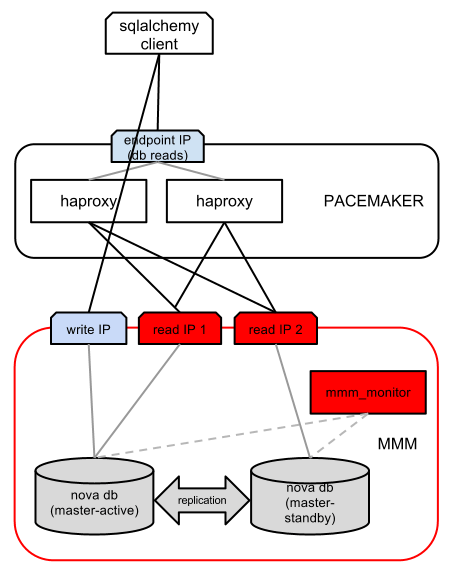
Бесперебойность базы данных обеспечивается MMM: репликация master-master с одной основной репликой в режиме ожидания (только активная реплика поддерживает запись, а оба мастера поддерживают чтение, таким образом, у нас один “записывающий” IP-адрес и два “читающих”). Модуль mmm_monitor проверяет доступность обоих мастеров и соответственно перемешивает “читающие” и “записывающие” IP-адреса.
Поверх MMM HAproxy обеспечивает улучшение производительности за счет распределения нагрузки при чтении между обоими IP-адресами. Конечно, для большей масштабируемости можно добавить несколько подчиненных узлов с дополнительными IP-адресами для чтения. В то время как HAproxy хорошо распределяет трафик, он не обеспечивает бесперебойность саму по себе, поэтому создается ещё один экземпляр HAproxy и для обоих экземпляров создается ресурс в Pacemaker. Поэтому, если один из прокси-серверов HAproxy дает сбой, Pacemaker переводит IP-адрес с неработающего “записывающего сервера” на другой.
Так как у нас есть только один “записывающий” IP-адрес, нам не нужно распределять нагрузку и запросы на запись попадают сразу на него.
С таким подходом мы можем обеспечить масштабируемость запросов на запись за счет добавления большего числа подчиненных узлов в ферму БД, а также балансировки нагрузки с помощью HAproxy. Кроме того, мы поддерживаем высокую доступность, используя Pacemaker (для определения сбоев HAproxy) плюс MMM (для определения сбоев узла базы данных).
Если сравнивать RabbitMQ HA и OpenStack, Mirantis предложила дополнение для nova с поддержкой зеркалирования очередей. С точки зрения пользователя дополнение добавляет две новых опции в nova.conf:
-rabbit_ha_queues=True/False – для включения зеркалирования очереди.
-rabbit_hosts=[«rabbit_host1»,«rabbit_host2»] – чтобы пользователи могли определить кластеризованную пару узлов RabbitMQ HA.
Технически происходит следующее: в каждый вызов queue.declare внутри nova добавляется x-ha-policy:all и подключается логика кластера roundrobin. Саму настройку кластера RabbitMQ выполняет пользователь.
Дополнительные сведения
Я представил несколько вариантов обеспечения высокой доступности для базы данных и системы обмена сообщениями. Ниже список ссылок для дополнительного исследования предмета.
http://wiki.openstack.org/HAforNovaDB/: Бесперебойность для БД OpenStack
http://wiki.openstack.org/RabbitmqHA: Бесперебойность системы очередей
http://www.hastexo.com/blogs/florian/2012/03/21/high-availability-openstack: статья о различных аспектах бесперебойности в OpenStack
http://docs.openstack.org/developer/nova/devref/rpc.html: принцип работы обмена сообщениями в OpenStack
http://www.laurentluce.com/posts/openstack-nova-internals-of-instance-launching/: интересное описание последовательности шагов при запуске экземпляра
https://lists.launchpad.net/openstack/pdfGiNwMEtUBJ.pdf: презентация о бесперебойности в nova
http://openlife.cc/blogs/2011/may/different-ways-doing-ha-mysql/: заголовок все объясняет
http://www.linuxjournal.com/article/10718: статья о репликации MySQL
http://www.mysqlperformanceblog.com/2010/10/20/mysql-limitations-part-1-single-threaded-replication/: о проблемах производительности репликации
https://github.com/jayjanssen/Percona-Pacemaker-Resource-Agents/blob/master/doc/PRM-setup-guide.rst: статья о репликации MySQL: статья о Percona Replication Manager
http://www.rabbitmq.com/clustering.html: кластеризация RabbitMQ
http://www.rabbitmq.com/ha.html: зеркалированные запросы RabbitMQ
Оригинал статьи на английском языке
ссылка на оригинал статьи http://habrahabr.ru/company/mirantis_openstack/blog/177357/