В этом посте я хочу поделиться своим опытом общения с Nebius. Прежде всего, сразу же хочется отметить тот факт, что сами технические собеседования проводили классные разработчики, с которыми было приятно и интересно общаться. Все негативные моменты происходили вокруг этого.
Итак, история началась в апреле, когда ко мне в телеграм постучался рекрутер и предложил пообщаться по поводу вакансии golang разработчика. Я подумал, а почему бы и не сдуть с себя пыль, согласился. Далее были всем знакомые созвоны, сначала пол часа с рекрутером, где нужно рассказать про свои заслуги и послушать про прелести компании. После этого созвона, рекрутер скинул мне приблизительный список задач, которые будут ждать меня на технических этапах. Я не хотел ударить в грязь лицом, поэтому на выходных расчехлил книжку, ютуб и литкод, хорошенько позанимался и пошел на первый этап.
На первом этапе мне дали две алгоритмические задачи, с которыми я управился за полтора часа, на том созвон и закончился. Ни про опыт, ни про какие-то теоретические знания спрашивать не стали, ну на то он и первый этап, окей. С обраткой рекрутер вернулся быстро, на следующий день, сказал что я молодец и хорошо справился с обеими задачами, можно готовиться ко второму этапу. Так что еще одни выходные за книгой, ютубом и литкодом.
Второй этап оказался точно таким же как первый. Две алгоритмические задачи и два часа на их решение. Но в этот раз интервьюер попросил рассказать про мой технический бекграунд, а это я люблю и с удовольствием делаю. Опять же, рекрутер вернулся довольно быстро и сказал, что этот этап я тоже прошел хорошо, сделал обе задачи и перехожу на третий этап. Тут я уже осторожно спросил, а будет ли он как-то отличаться от первых двух? На что мне сказали — нет, тоже будут задачи на алгоритмы, но немного сложнее, а времени дадут меньше.
На этом моменте я уже подумал, что план минимум для себя выполнил, с алгоритмами особо не дружу, а тут прошел аж два этапа, круто! К тому же, произошла потеря мотивации от непонимания, зачем три раза спрашивать кандидата одно и тоже? В надежде на что? Выявить, а не «списал» ли он первые два раза? Четыре часа алгоритмических задач недостаточно, чтобы понять умеет кандидат писать код или нет? В итоге, к третьему этапу я не стал дотошно готовиться, покрутил еще немного литкод и на этом все.
Третий этап прошел как и первые два, получил две задачи, пописал код, в конце послушал интересные истории про то, чем занимаются ребята в Яндекс Клауде. На следующий день пришел рекрутер, торжественно объявил, что и третий этап пройден неплохо. Спросил про зарплатные ожидания. Я, как человек ютубы смотревший, знаю что конкретную цифру называть неправильно, поэтому кокетливо отвечаю, что меня устроит цифра из вилки вакансии. В ответ слышу окей и что ко мне скоро вернутся, после уточнения плана дальнейших действий…
И тут начинается самая интересная и чудная часть
Прохождение трех этапов заняло примерно две недели, с середины апреля и до начала мая. Крайний, третий этап был 2-го мая, это важная хронология. Далее, неделя тишины. В выходные рекрутер появляется и просит назвать более конкретную цифру, которую я бы хотел видеть в оффере, диапазон вилки вакансии не достаточно конкретен. Нууу, окей, пусть будет от А до Б. Понял, принял, ушел дальше уточнять план… и пропал еще на две недели. Причем не просто пропал, а прям пропал‑пропал, с полным игнорированием сообщений в телеграмм. Я себя чувствовал как в меме «Папа, где алименты?», а в ответ — тишина.
На тот момент, мне уже было жалко бросать все на пол пути, жалко потраченных усилий на подготовку и прохождение технических собесов, чтобы после этого меня просто бросили и игнорировали как назойливого одноклассника. Я пошел на линкедин, нашел другого рекрутера из компании, обратился к нему с просьбой пингануть первого. Это сработало, первый вернулся спустя две с лишним недели и сказал, что заболел и в командировке был, кошмар-ужас, даже сил телеграм открыть за две недели не нашлось. Окей, ладно, так что дальше? А дальше он снова спросил у меня ожидание по ЗП, причем нужно было назвать уже конкретную цифру. Ладно, если это поможет толкнуть процесс с места, то давай возьмем среднее между А и Б и сдвинемся наконец с мертвой точки. Понял, принял, ушел дальше уточнять план…
И так прошел месяц. Я, конечно же, уже забил на всю эту ситуацию, ни да, ни нет, какая-то ерунда. Тут мне пишут с вакансией от Яндекс Клауда, на что я отвечаю вопросом про Небиус, мол так и так. Добрая девушка уходит уточнить мой вопрос к коллегам и возвращается с ответом, что оказывается, мое резюме задублировалось в базе и поэтому возникли такие заминки, но ничего страшного, сейчас все решим. Как можно догадаться, никакого результата это не дало и никто со мной не связался и я продолжить спокойно жить свою жизнь.
Прошел еще месяц, пишет другая девушка и говорит, что у нее есть крутая вакансия, да не от кого‑то, а от самого Небиуса! «Как здорово!» — отвечаю я, и в который раз пересказываю историю своего весеннего приключения. На что она, уже по классике, уходит уточнить у коллег (я тем временем ожидаю ответ про дубликат в базе). Но нет! Оказывается, по новой версии, я плохо прошел интервью в начале лета, и теперь могу повторить попытку только через пол года. Вау! Вернемся к важной хронологии, последний этап был 2-го мая, далее два месяца никаких подвижек не происходило (кроме дотошных вопросов про ЗП). На просьбу дать контакт, с кем можно это обсудить, я получил вежливый отказ.
Теперь мне кажется, что я попал в чистилище Небиуса — на интервью пару раз в месяц зовут, но пройти его невозможно. Вот, как то так.
А что я хочу добиться этим постом? Ну, во-первых поделиться этой глупой историей с другими разработчиками, не держать в себе свое негодование от потраченных в пустую времени и усилий. Во-вторых, что супер мало вероятно, достучаться до Небиуса, с просьбой или крестик снять, или трусы одеть разобраться с бардаком в базах, рекрутинге и коммуникациях. Либо удалите меня из своей базы, либо отметьте как «провалившего интервью летом» и не пишите больше с предложениями, а то цирк какой-то.
Спасибо за внимание!
P.S. Люблю читать смешные и глупые истории с собесов, поэтому вэлком в комментарии!
Патент RU_2676949_C2 со скромным названием «Система и способ определения дохода пользователя мобильного устройства» компании ООО ЯНДЕКС (RU) действует с пятого апреля 2017 года. А вместе с патентом RU 2 637 431 C2 «Способ и система определения оптимального значения параметра аукциона для цифрового объекта» это дает возможность для персонального, ситуационного и точечного ценообразования, например на услуги такси. Не документальное ли это подтверждение возможности компании для топ-менеджера с последним iPhone ставить ценник дороже, чем для дизайнера с Xiaomi на идентичный по гео и времени заказ? «Вот тебе, бабушка, и Юзер и Экспирианс!»?
В дебри патента окунаться не будем, а поговорим об алгоритмах скрывающихся под обличием термина User Experience (ох, не тому ведь вас учили, юная леди, на на курсе Яндекс.Практике по UI/UX). Во-первых, это «душное» чтиво. Во-вторых они все одинаковые: одни знают сколько мы зарабатываем, другие (Tinder) — с кем мы спим, третьи увеличивают вовлеченность (EA), четвертые повышают микротранзакции (Ubisoft).
Я их все прочел и для простоты резюмирую: в основе всех патентов и технологий лежит теория множеств, мат. аппарат теории Графов, что то типа алгоритмов Elo для системы подбора и десяток серверов тензорными ядрами на 3958 терафлопс. Вы ведь не думали, что Хуанг их продает для генерации картинок или GPT?!)
Предлагаю читателю познакомится с тем, как нежно и волшебно пишет об этом зарубежная пресса и исследования, в моем «правильном» переводе лит.обзора на тему Algorithmic Experience (AX), за авторством Diem-Trang Vo и редакцией Duy Dang-Pham. Все нужные слова выделены жирным.
Введение
ИИ «бла-бла-бла» неотъемлемой «бла-бла-бла» повседневной жизни. Спектр реализаций: рекомендательные системы э-коммерции, рекомендации фильмов, специализированные службы агрегации контента или навигационные системы.
Да. Внедрение технологий может улучшить работу пользователей и спектр услуг, но, не очевидно, как пользователи воспринимают такие рекомендательные системы: какие факторы влияют на нашу удовлетворенность и принятие этих рекомендательных систем алгоритмов? И как мы можем улучшить алгоритмический опыт пользователей?
Проблема ИИ: с точки зрения пользователей
Проанализировав 35 448 отзывов пользователей Facebook, Netflix и Google Maps, Einband и др. (2019) выяснилось что не только точность, но и взаимодействие между пользователями и системами также влияет на опыт пользователей.
С одной стороны, исследование предполагает, что есть общими проблемами этих систем — алгоритмические, такие как: предвзятая модерация контента Facebook, несоответствие между рекомендациями и интересами Netflix, неточный пункт назначения Google Maps, являются
С другой, пользователи могут чувствовать раздражение, когда они имеют ограниченный контроль над тем, как работают системы. Например, пользователи могут быть разочарованы, когда Google Maps продолжает перезаписывать выбранные вручную маршруты, не сообщая им об этом.
Кроме того, важно, как системы взаимодействуют с отзывами пользователей. С бинарной системой рейтинга (нравится/не нравится) пользователям может быть сложно предоставить значимую обратную связь для Netflix, что, в свою очередь, влияет на актуальность рекомендаций.
Учитывая эти проблемы, ориентированные на человека, все больше исследований начинают изучать «алгоритмический опыт» или «AX» (1) — всеобъемлющий взгляд на взаимодействие пользователя с интеллектуальными системами. Это понятие включает (но не определяется) действия по усилению пользовательского контроля над алгоритмами принятия решений, прозрачности в том, как работает система, и преднамеренной активации или деактивации алгоритмического влияния.
AX и нежные чувства пользователей
Человеческая деятельность и контроль за системой — одна из новых тем. Позволяя пользователям подтверждать, управлять и сохранять контроль над алгоритмом, система может дать пользователям возможность почувствовать себя способными управлять тем, что система думает о них (1) (5).
Согласно опросу, 56% пользователей хотели бы, чтобы у них была возможность управлять новостной лентой Facebook и самостоятельно фильтровать контент, включая, например, включение/выключение/настройку функции «Люди, которых вы можете знать» (1).
Исследователи предполагают участие людей в процессе разработки систем ИИ. Вовлечение конечных пользователей в процесс разработки может улучшить восприятие пользователями справедливости и доверия, повысить осведомленность об алгоритмах и понимание алгоритмов принятия решений, что приведет к более чуткой позиции (6).
AX и прозрачность
Исследования по внедрению алгоритмов и алгоритмическим бихевиористики опираются на воспринимаемую прозрачность и справедливость для объяснения отношения пользователей, фактического использования, уровня принятия, удовлетворенности и намерения продолжать (8) (9).
Прозрачность относится к тому, как система делает видимыми то, что алгоритм знает о пользователе, и объясняет, почему алгоритм представляет результаты на основе этого профилирования (1), что, в свою очередь, улучшает работу алгоритма.
Шин’овская «петля доверия и обратной связи» (9) также предполагает, что воспринимаемая прозрачность и точность гарантируют доверие, что, в свою очередь, способствует удовлетворению.
AX и осведомленность: польза объяснения
Другие работы направлены на то, чтобы помочь пользователям разобраться в интеллектуальных системах, например, посредством объяснений.
Некоторые авторы согласны с тем, что объяснение положительно влияет на восприятие прозрачности (3). Другие утверждают, что эффективность объяснения зависит от механизмов прозрачности (отчетность и интерпретируемость), а также от того, как система объясняет (7). Например, различия в стилях объяснения (влияние исходных данных, чувствительность, на основе конкретных случаев или демографические данные), методах и модальностях уведомлений по-разному влияют на восприятие справедливости пользователями (2).
В заключение…
Алгоритмы «бла-бла-бла» частью «бла-бла-бла» подход ориентированный на человека. Создание ИИ с точки зрения того, что удовлетворяет потребности человека и общества, гораздо важнее, чем продвижение того, что технически возможно.
В недавних исследованиях изучались различные способы повышения удовлетворенности пользователей и принятия ими ИИ, включая расширение участия пользователей, повышение прозрачности, справедливости или использование объяснений.
Однако все еще существует ограниченное понимание возможных решений, которые требуют дальнейшего изучения и внимания. Благодаря пониманию восприятия пользователя будущая работа может быть посвящена разработке инклюзивных алгоритмов, ориентированных на человека.
P.S.
Ага, прям таки вижу как Яндекс Такси, перед очередным заказом уведомляет: «Мы знаем, что вы зарабатываете 25к рублей, поэтому хотели сделать вам скидку в 3 процента, но вы получили материнский капитал, поэтому только 1%»
Список литературы
Alvarado, O & Waern, A 2018, ‘Towards algorithmic experience: Initial efforts for social media contexts’, in Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, pp. 1-12.
Binns, R, Van Kleek, M, Veale, M, Lyngs, U, Zhao, J & Shadbolt, N 2018, ‘‘It’s Reducing a Human Being to a Percentage’ Perceptions of Justice in Algorithmic Decisions’, in Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, pp. 1-14.
Brunk, J, Mattern, J & Riehle, DM 2019, ‘Effect of Transparency and Trust on Acceptance of Automatic Online Comment Moderation Systems’, in 2019 IEEE 21st Conference on Business Informatics (CBI), vol. 1, pp. 429-35.
Eiband, M, Völkel, ST, Buschek, D, Cook, S & Hussmann, H 2019, ‘When people and algorithms meet: user-reported problems in intelligent everyday applications’, in Proceedings of the 24th International Conference on Intelligent User Interfaces, pp. 96-106.
Kumar, A, Braud, T, Tarkoma, S & Hui, P 2020, ‘Trustworthy AI in the Age of Pervasive Computing and Big Data’, arXiv preprint arXiv:2002.05657.
Lee, MK, Kusbit, D, Kahng, A, Kim, JT, Yuan, X, Chan, A, See, D, Noothigattu, R, Lee, S & Psomas, A 2019, ‘WeBuildAI: Participatory framework for algorithmic governance’, Proceedings of the ACM on Human-Computer Interaction, vol. 3, no. CSCW, pp. 1-35.
Rader, E, Cotter, K & Cho, J 2018, ‘Explanations as mechanisms for supporting algorithmic transparency’, in Proceedings of the 2018 CHI conference on human factors in computing systems, pp. 1-13.
Shin, D 2020, ‘How do users interact with algorithm recommender systems? The interaction of users, algorithms, and performance’, Computers in Human Behavior, p. 106344.
Shin, D, Zhong, B & Biocca, FA 2020, ‘Beyond user experience: What constitutes algorithmic experiences?’, International Journal of Information Management, vol. 52, p. 102061.
Статья-туториал для тех, кто хочет узнать, как из заголовка получается «6» методом рекурсивного спуска. Начнём с самого простого и дойдём до вычисления -1.82 или около того из строки -2.1+ .355 / (cos(pi % 3) + sin(0.311)).
Конечно, этот метод неоднократно описан на Хабре и зачитан каждому айтишному первокурснику. В своей версии я хочу изложить его очень просто и подробно, с позиции элементарной практики на JavaScript. Ссылки на рабочий код — в самом низу.
«2»
Разберём невыносимо простой пример: на входе у нас строка с двойкой, а на выходе должно быть число 2. Разумеется, тут достаточно вызова функции parseInt, но давайте напишем так, чтобы было от чего отталкиваться на следующих уровнях.
function calc(tokens) { // ['2'] let result = parseInt(tokens.shift()); // ['2'] → '2' → 2 if (tokens.length) throw new Error('expected eof'); // [empty array] return result; // 2 } console.log(calc('2'.split('')) === 2); // true
Зачем мы делим строку на символы, да ещё когда она состоит из всего одного? На самом деле нам нужны не отдельные символы, а элементы выражения, которые называются токенами. Числа — это один вид токенов, операторы +, -, *, / — другой (причём каждый оператор может быть отдельным видом), скобки — третий и т.д. Но для начала пускай каждый токен будет символом, ведь так выражение гораздо проще разрезать на токены (токенизировать): достаточно вызвать .split('').
Кроме того, тут появляется понятие EOF (end of file) и вводится правило, по которому после выражения сразу должен идти конец файла/ввода. Представьте, что на вход подаётся строка 2#. Без проверки EOF мы бы так и вывели двойку, проигнорировав #, а такие вольности недопустимы. Выражение 2+2 точно так же должно сбить с толку наш парсер на этом этапе.
Кстати, в JavaScript метод shift() выдаёт первый элемент и удаляет его из массива. Этим будем пользоваться, чтобы идти по токенам. Иногда будем проверять токен, прежде чем удалить его, типа if (tokens[0] === '+') { tokens.shift(); ... }.
«2+2»
Пойдём дальше по выражению дальше и, встречая + либо - , будем решать, что делать со следующей за ними цифрой — добавить или вычесть из накопленного результата.
function expr(tokens) { // ['2', '+', '3', '-', '4'] let result = parseInt(tokens.shift()); // NEW while (true) { if (tokens[0] === '+') { tokens.shift(); // throw away the '+' result += parseInt(tokens.shift()); } else if (tokens[0] === '-') { tokens.shift(); // throw away the '-' result -= parseInt(tokens.shift()); } else break; } return result; } function calc(tokens) { // ['2', '+', '3', '-', '4'] let result = expr(tokens); if (tokens.length) throw new Error('expected eof'); return result; } console.log(calc('2+2'.split('')) === 4); // true console.log(calc('2+3-4'.split('')) === 1); // true
Кроме того, мы вынесли часть алгоритма в отдельную функцию expr, хоть и можно было продолжать писать всё в calc. Такое разделение пригодится нам позже.
Давайте подсунем нашему калькулярсеру какую-нибудь ерунду, убедимся, что он не выводит случайный числовой результат, и двинемся дальше.
console.log(calc('+'.split(''))); // NaN console.log(calc('+1'.split(''))); // Error: expected eof
Пока сойдёт. Одинокий плюс никакого числа не представляет, а поддержку +1 (унарный плюс) мы добавим позже вместе с унарным минусом.
«2+2×2»
Естественно, тут подвох в приоритете операций умножения/деления над операциями сложения/вычитания, поэтому нельзя просто добавить блок else if (tokens[0] === '*') {...} вслед за плюсом и минусом, ведь тогда получится 8. Здесь-то на помощь и приходит рекурсия языка программирования, на котором мы пишем этот калькулятор. В JavaScript рекурсия есть, и потому этот метод легко реализуется. Но есть условно современные языки без поддержки рекурсии — например, structured text в IEC 61 131–3, на котором программируются контроллеры в среде промышленной автоматики.
Оставим двойки для красивого заголовка, и, чтобы проще было следить за руками, возьмём пример 3+4×5. Да, говоря обывательским языком, нам нужно сначала посчитать 4×5 и уже потом складывать это с тройкой. Но можно переформулировать и более удобным для программирования образом: сложить тройку с тем, что главнее сложения. А значит, можно как обычно начать считывать тройку, потом + за ней, а потом «отвлечься» на вычисление 4×5, результат которого и сложить с ранее замеченной тройкой. Вот на этом «отвлечься» и строится принцип рекурсивного спуска. Давайте оформим «отвлечься» новой функцией term, которую реализуем точно так же, как сделана expr выше. Ну а в expr будем вызывать term там, где прежде считывали цифры.
function term(tokens) { // like old `expr` but * and / let result = parseInt(tokens.shift()); while (true) { if (tokens[0] === '*') { tokens.shift(); // throw away the '*' result *= parseInt(tokens.shift()); } else if (tokens[0] === '/') { tokens.shift(); // throw away the '/' result /= parseInt(tokens.shift()); } else break; } return result; } function expr(tokens) { let result = term(tokens); // was `parseInt(tokens.shift())` while (true) { if (tokens[0] === '+') { tokens.shift(); // throw away the '+' result += term(tokens); // was `parseInt(tokens.shift())` } else if (tokens[0] === '-') { tokens.shift(); // throw away the '-' result -= term(tokens); // was `parseInt(tokens.shift())` } else break; } return result; } function calc(tokens) { let result = expr(tokens); if (tokens.length) throw new Error('expected eof'); return result; } console.log(calc('2+2'.split('')) === 4); // true console.log(calc('2+3-4'.split('')) === 1); // true console.log(calc('2+2*2'.split('')) === 6); // true console.log(calc('3+4*5'.split('')) === 23); // true console.log(calc('3/2+4*5'.split('')) === 21.5); // true
Как видите, мы сразу заумели делать даже 3/2+4*5.
«(2+2)×2»
Что если всё-таки нужна восьмёрка при помощи скобок? Значит, нужно в termотвлечься на то, что заключено в скобки. А в скобках может быть то, что должно обрабатываться функцией expr , для чего мы её и выделили некоторое время назад. Очередное отвлечение назовём factor, из которой либо вызовем expr между скобками (круг замкнулся), либо считаем число.
function factor(tokens) { if (tokens[0] === '(') { tokens.shift(); let result = expr(tokens); if (tokens[0] !== ')') { throw new Error('missing closing parenthesis'); } else { tokens.shift(); } return result; } else return parseInt(tokens.shift()); } function term(tokens) { let result = factor(tokens); while (true) { if (tokens[0] === '*') { tokens.shift(); // throw away the '*' result *= factor(tokens); } else if (tokens[0] === '/') { tokens.shift(); // throw away the '/' result /= factor(tokens); } else break; } return result; } function expr(tokens) { /* omitted for clarity */ } function calc(tokens) { /* omitted for clarity */ } console.log(calc('2+2'.split('')) === 4); // true console.log(calc('2+3-4'.split('')) === 1); // true console.log(calc('2+2*2'.split('')) === 6); // true console.log(calc('3+4*5'.split('')) === 23); // true console.log(calc('3/2+4*5'.split('')) === 21.5); // true console.log(calc('(2+2)*2'.split('')) === 8); // true
В принципе, на этом заканчивается основа рекурсивного спуска. Дальше будем прокачивать эту структуру.
«(02. + 0002.) × 002.000»
До сих пор мы парсили массив символов, состоящий из цифр, бинарных операторов и круглых скобок. Каждый символ был токеном, и это очень упрощало нам жизнь. Но дальше развивать это будет сложно. Давайте теперь посимвольный split('') заменим чуть более взрослым лексическим разбором (по большому счёту это синоним токенизации).
У нас будет несколько регулярных выражений по всем типам токенов, и мы будем пытаться отрезать от входной строки по кусочку, который соответствует хоть одной регулярке. Сначала упрощённый пример, напрямую не связанный с нашей задачей:
Тут важно отметить ^ в начале каждого регулярного выражения, означающее поиск соответствия строго с начала строки. Вместе со slice() это даёт тот самый проход по строке «кусочками».
Такой лексер на регулярках очень компактен и читабелен, но его гибкость и производительность весьма ограничены для по-настоящему взрослого лексического разбора; имейте это в виду, когда пойдёте делать свой язык программирования. Тем не менее, современные рантаймы JS оптимизируют разрезание строк через slice, по сути сводя его к манипуляциям с указателями. В сумме с простыми регулярками, прибитыми к началу строки, это должно давать неплохую производительность.
Давайте теперь растянем такой лексер на лексику наших выражений. Вместо строк для обозначения типов возьмём JS-овский Symbol и упакуем матчинг внутрь функции-генератора (это такие функции, которые могут выдавать по несколько значений за один вызов; в JavaScript они обозначаются звёздочкой и «выплёвывают» значения через yield).
Не знаю, заметили вы сами или нет, но здесь мы впервые разобрали выражение (2+2)×2 — обратите внимание на знак умножения, это не звёздочка, причём воспринимается наравне со звёздочкой. Там есть ещё один вариант умножения, а также «типографский» минус. Пускай это будет фишкой нашего языка для упоротых по типографике эстетов.
В сущности, это то же самое, что split(''), только кусочки покрупнее. Среди прочего у нас теперь есть явное обозначение пробелов (whitespace), которые мы легко можем пропустить, и end-of-file в виде отдельного токена.
Но дело не ограничивалось одним лишь split(''), правда? Мы подглядывали следующий токен через if (tokens[0] === '*'), а также «проглатывали» токены через shift(). Кое-где мы даже убеждались, что токен именно такой, а не другой, выбрасывая ошибку ‘missing closing parenthesis’. Воспроизведём эти удобства в классе:
class ExpressionCalc { #stream; #token; constructor(input) { this.#stream = tokenize(input); this.#next(); } #error(err) { throw new Error(`${err}, pos=${this.#token?.pos}, token=${this.#token.match}, type=${this.#token.type.description}`); } #next() { do { this.#token = this.#stream.next()?.value; } while (this.#token?.type === WS); } #accept(type) { let match; if (this.#token?.type === type) { match = this.#token.match; this.#next(); return match || true; } return false; } #expect(type) { return this.#accept(type) || this.error(`expected ${type.description}`); } }
Это джентельменский набор для простейшего парсинга:
метод next() — эквивалент shift() из массива с автоматическим пропуском пробелов;
метод accept(type) — эквивалент проверки с последующим удалением из массива; заодно возвращает текст совпадения;
метод expect(type) — эквивалент проверки с выбрасыванием ошибки при несовпадении;
метод error(err) — выбрасывание ошибки с индикацией текущей позиции.
То есть всё это у нас было, но прямо по месту парсинга, «inline». Давайте теперь адаптируем функции парсинга/вычисления как методы того класса:
class ExpressionCalc { ...constructor, #error, #next, #accept, #expect #factor() { let result; let text; if (this.#accept(LEFT_PAR)) { // parenthesis (but not function calls) result = this.#expression(); this.#expect(RIGHT_PAR); } else if (text = this.#accept(NUMBER)) { // numeric literals result = parseFloat(text); } else { this.#error('unexpected input'); } return result } #term() { let result = this.#factor(); while (true) { if (this.#accept(MULTIPLY)) result *= this.#term(); else if (this.#accept(DIVIDE)) result /= this.#term(); else if (this.#accept(MOD)) result %= this.#term(); else break; } return result; } #expression() { let result = this.#term(); while (true) { if (this.#accept(PLUS)) result += this.#term(); else if (this.#accept(MINUS)) result -= this.#term(); else break; } return result; } }
Ещё у нас появилась операция получения остатка от деления (оператор %) и числа дробные поддерживаются, т.к. вместо parseInt делаем parseFloat.
«+1»
Как бы нам добавить сюда унарный плюс и унарный минус? По первой интуиции это знак рядом с числовым литералом, который можно учесть подобно скобкам в factor. Но это обманчивая интуиция. Возможны такие выражения: -(2+3), -sin(0.33). Стало быть, это отдельная вещь c отдельной рекурсией.
#factor() { let result; ... } else if (this.#accept(PLUS)) { // unary plus result = +this.#factor(); } else if (this.#accept(MINUS)) { // unary minus result = -this.#factor(); } ... return result } console.log(new ExpressionCalc('+1').calc() === 1); // true console.log(new ExpressionCalc('-(2+3)').calc() === -5); // true
«cos(2*pi)»
Именованные операнды типа «pi» чем-то напоминают числовые литералы, не правда ли? По крайней мере они стоят там же относительно операторов. Ну, например, 2 + -(5 * 3) vs 2 + -(pi * 3). Похоже? И несложно представить себе какие-нибудь римские числа, которые вообще не отличаются от переменных: 10 + 21 = 10 + XXI. Только с функциями какая-то фигня: у них свои скобки. Значит, и будем обрабатывать всё там же, где числа — в factor.
#factor() { let result; let text; ... } else if (text = this.#accept(IDENTIFIER)) { // identifiers (named constants and function calls) text = text.toLowerCase(); let func; if (text === 'pi') result = Math.PI; else if (text === 'e') result = Math.E; else if (Math[text] && typeof (func = Math[text]) === 'function') { this.#expect(LEFT_PAR); result = func(this.#expression()); this.#expect(RIGHT_PAR); } else this.#error(`unknown id ${text}`); } ... return result } console.log(new ExpressionCalc('cos(2*pi)').calc() === 1); // true
На что тут можно обратить внимание? Во-первых, мы не пытаемся как-либо реюзать обработку приоритезирующих скобок; здесь скобки — это отдельная синтаксическая конструкция. Если бы мы поддерживали несколько аргументов, то прошлись бы здесь по ним через запятую. Во-вторых, что мы реюзаем, так это функции Math из JavaScript.
Можно сказать, что переменные, которые вы определяете в этом блоке, образуют окружение, в котором вычисляется введённая вами формула (ну или «исполняется ваш скрипт» если бы мы писали интерпретатор какого‑нибудь языка).
В текущем виде лексер вообще не способен его обрабатывать. Чтобы избежать падения на каком-нибудь там }@5+1, можно пропускать по одному символу, пока совпадения вновь не появятся, и что с ними дальше делать, уже зависит от применения; в общем случае надо показать ошибку и прекратить вычисление. Хорошим тоном будет накопить неизвестные символы и выдать их одной ошибкой.
const ... UNKNOWN = Symbol('unknown'), ...; function* tokenize(input) { const matchers = [ ... ]; let pos = 0; let unknownFrom = -1; while (input) { const posBefore = pos; for (const { type, re } of matchers) { const match = re.exec(input.slice(pos))?.[0]; if (typeof(match) === 'string') { if (unknownFrom >= 0) { // flush the unknown input as one token yield { type: UNKNOWN, pos: unknownFrom, match: input.slice(unknownFrom, pos), }; unknownFrom = -1; } yield { type, pos, match }; if (type === END_OF_FILE) input = null; // breaks outer loop pos += match.length; break; } } if (input && posBefore === pos) { // nothing matched, track unknown input if (unknownFrom < 0) unknownFrom = pos; pos++; } } } [...tokenize('}@5+1')].forEach(t => console.log(t)); // {type: Symbol(unknown), pos: 0, match: '}@'} // {type: Symbol(num), pos: 2, match: '5'} // {type: Symbol(plus), pos: 3, match: '+'} // {type: Symbol(num), pos: 4, match: '1'} // {type: Symbol(eof), pos: 5, match: ''}
Подытоживая
Целью заметки было показать «на пальцах», как работает и из чего строится простейший рекурсивный парсер-калькулятор арифметических выражений, не погружаясь в термины грамматик языков программирования. Подобные парсеры можно встретить под капотом софта, который на уровне пользователя позволяет вводить формулы/выражения, например для срабатывания алертов или для формирования графиков. Встречаются и другие подходы к обработке выражений: перевод в постфиксную форму с последующим вычислением, применение генераторов парсеров вместо ручного их написания. Многие языки и среды исполнения предлагают готовые решения, чтобы вычислять пользовательские выражения.
Так уж вышло, что в течение своей деятельности мне немало доводилось работать с публичными API, причем как в со стороны, которая их предоставляет, так и со стороны, которая интегрируется. И здесь я хочу рассказать не только про один из кейсов, который решал ранее, но и поделиться результатами проводимого анализа, полученным опытом, а также набитыми шишками.
Материала вышло многовато, поэтому разбил его на 2 части. В части 1 (этой статье) рассмотрим, почему и зачем вообще публичным API нужна документация, есть ли у нее какие-то отличия от документации внутренних API, а также проанализируем и детально разберем различные подходы к ведению такой документации, попутно познакомившись поближе с полезными инструментами.
В следующей части затронем уже непосредственно написание документации, подумаем, кто же должен ее писать, какие инструменты могут в этом помочь, как это встроить в реальный процесс разработки и что во всем этом может пойти не так.
Часть 1 – текущая статья
Часть 2 – TBD
Статьями надеюсь помочь созданию удобных и полезных документаций публичных API продуктов упростив всем нам возможные будущие интеграции с ними.
Сразу скажу, что оставляю за рамками темы:
Чем именно наполнять документацию публичных API и что в ней должно быть.
AsyncAPI, GraphQL и прочие стандарты и протоколы, имеющие свои особенности. В статье речь пойдет про REST-подобные API преимущественно.
Кому может быть интересен материал? Тем, кто страдает от плохой документации публичных API в своем продукте, хочет улучшить онбординг клиентов или сделать процесс документирования API удобнее, а также всем, кого так или иначе касается тема документирования API, ведь многие вещи на самом деле применимы и по-отдельности, причем не только к публичным API.
И, перед тем как начать, определимся с одним понятием:
Публичный API (Public, External API) – это API-интерфейс, предназначенный для использования сторонними сервисами, с помощью которого осуществляется доступ к ресурсам вашего продукта. Иными словами API, с помощью которого выполняют интеграции с вашим приложением.
Вводная часть
Почему про это важно поговорить? Вижу несколько причин.
Вспомните свой опыт интеграции со сторонними продуктами: каково это было? По каким документациям вам приходилось разбираться с чьми-то API? Насколько часто вы получали актуальную и подробную документацию API продукта? По своему опыту скажу, что далеко не вся документация API, в том числе и крупных сервисов, является таковой, а порой документация представляет вообще Word`овский файл, который писали 5 лет назад (и это не шутка).
Также посмотрим на ситуацию со стороны самих продуктов. Здесь определить актуальность проще, потому что ее можно измерить. Измерить деньгами. Так вот, сколько продуктов сейчас теряют деньги из-за отсутствия адекватной документации публичных API? Это может быть упущенная выгода от клиентов, которые отказались от использования продукта, потому что не смогли понять ваши реальные возможности для интеграции, или человеко-часы вашей команды, которые вы тратите, отвечая на вопросы по работе ваших же методов API: как от клиентов, так и от своих же коллег.
Также часто видим использование для отображения документации одного только бедного Swagger UI. Причем, это касается продуктов самого разного размера. Swagger UI остается самым распространенным инструментом для отображения документации, однако он далеко не единственный в своем роде. И существуют качественные альтернативы, которые так же просты в использовании, но в то же время делают документацию удобнее, и про которые хочется упомянуть и напомнить, что это всего лишь инструменты и, как и для любого инструмента, здесь есть выбор.
Картинка, знакомая, наверняка, многим
Почему важна документация для публичных API
Не стоит говорить о том, что продукт создается для пользователей. И часто мы думаем о том, как сделать так, чтобы продукт решал задачу пользователей, делал их работу (привет, Jobs to Be Done).
Но важно не забывать, какие категории пользователей у вашего продукта есть. И часто это могут быть не только пользователи-пользователи, но пользователи-разработчики. А в чем между ними разница? На самом деле, она не такая принципиальная. И те и те взаимодействуют с продуктом через какие-то интерфейсы. И если для первых это пользовательские интерфейсы, которые вы развиваете и стараетесь делать более дружественными, то для вторых – это скорее программные интерфейсы, ваши API и SDK. Именно поэтому, как есть термин UX, так есть и термин
И логично, что здесь важно, как выглядит ваше публичное API, насколько качественно и успешно оно может решить задачу приходящего к нему пользователя. А пользователь обычно приходит с простой задачей — для обретения некоей своей бизнес-ценности выполнить интеграцию с продуктом.
И первое, что он встречает на своем клиентском пути — наша документация API. А теперь сравните, какое впечатление произведет неполное или неоднозначное описание API, которое ему после запроса вышлют в файле или читабельная и структурированная документация, по которой можно вести разработку, не прибегая к необходимости задавать вопросы. Это, конечно, две крайности, однако они наглядно демонстрируют разницу.
Удобство работы с вашими публичными API напрямую зависит в том числе и от качества их документации. Публичные API — такое же лицо нашего продукта, просто повернутое к другой категории пользователей.
Да, можно говорить про то, что идеальное API не нуждается в документации и должно быть самоописывающим, есть даже целые книги, где продвигается такая идея, однако в реальности документация все же помогает разработчикам узнать нюансы и детали, которые влияют тем больше, чем больше требования к надежности данной интеграции.
Поэтому в ряде случаев имеет смысл учитывать и такую категорию ваших пользователей. Про это, к слову, говорит концепция API as Product.
Документация публичных и внутренних API: есть отличия?
Про подходы к документированию API в интернете написано много. Но часто в сообществах разработки явно не разделяется документация внутренних и внешних API. Чтобы понять, есть ли между ним разница, рассмотрим три примера.
Кто есть пользователь, что он знает и умеет?
Если говорить про внутренние API, то это обычно наш коллега, и он скорее всего будет хоть как-то знаком с предметной областью и хоть что-то будет знать про сам продукт (но все равно сильно надеяться на это не стоит).
В случае внешних API пользователь — довольно абстрактное лицо, и он вполне может не знать ничего про особенности нашей предметной области и специфику работы продукта, для него информация должна быть понятна практически без контекста.
Получение ответа на свой вопрос
Когда у нас возникает вопрос по работе внутреннего API и мы не можем сами найти на него ответ, какое будет наше самое первое действие? Вероятно, пойти и написать в чат тому, кто это API делал, либо посмотреть самостоятельно его реализацию в коде.
В случае внешних API таких опций мы зачастую лишены. И вопрос нам придется задавать в поддержку или в клиентского менеджера при его наличии. Если в самой документации ответа на вопрос нет, первые линии поддержки помочь нам вряд ли смогут, и получение ответа легко может растянуться на несколько дней.
Цена имиджа
Когда мы говорим про внутреннюю документацию, то даже если разработчик допустит в описании какие-то ошибки естественного языка (грамматические, орфографические, синтаксические и пр.), при этом сохранив однозначность трактовки, это не буде являться большой проблемой, и от этого в большинстве случаев никто не помрет.
Публичная документация же – лицо нашего продукта, и здесь имидж нам важен. Никакому продукту не хочется предоставлять клиентам описания, в которых есть явные ошибки или несоответствия стилю продукта, например.
Кроме того, для внутренней документации как хорошую практику имеет смысл рассмотреть генерацию документации из кода, потому что здесь банально важнее именно актуальность документации и схемы, чем ее грамотные и выверенные описания. Причем это можно спокойно совмещать с Design-first подходом: сначала upfront накидывается спецификация, по ней ведется разработка, а в результате в документацию уходит уже железно та реализация, которая была выполнена, с ее деталями.
Пару слов про Code-first и Design-first подходы
Также чтобы дальше нам правильно понимать некоторые вещи, вкратце упомяну про два известных подхода.
Code-first подход предполагает, что разработчики сперва делают имплементацию API, а затем на ее основе создают документацию. Часто это делается автоматизировано с использованием комментариев или аннотаций.
Примеры аннотаций и комментариев для различных языков программирования
Design-first, иногда называемый API-first полагается на то, что сначала мы планируем и описываем контракт API таким, каким он должен быть, и уже затем, когда он определен, делаем имплементацию на его основе (иногда также автоматизируя этот процесс).
Справедливо заметить, что оба этих подхода в общем случае — крайности, и часто в реальности мы видим нечто между ними, смещенное в ту или иную сторону.
Design-first и аналитики, а еще причем тут Style Guide
При всем этом, если у вас есть аналитики, бизнес- или системные, то при Design-first подходе совершенно не обязательно они должны проектировать API самостоятельно. Наоборот, вполне хорошей практикой считаю проектировать их вместе с разработчиками на основе выявленных аналитиками требований к API. Или, по крайней мере, валидировать свои предложения.
Ведь никто не говорит, что разработчик может и должен подключаться только на некоем волшебном этапе «разработки». Напротив, при ранней совместной работе и коллаборации шансы на успех куда выше. И куда лучше будет результат, нежели чем если спецификацию сам написал какой-то аналитик, чего-то не учел, и потом эту задачу молча “распределили” на какого-то разработчика.
Также есть простой вариант, когда аналитик приносит именно требования, а не полный дизайн API. При наличии Style Guide для вашего API не обязательно сразу упираться в имплементацию, а вполне достаточно сперва ограничиться требованиями. Если разработчики следуют Style Guide, то результат будет вполне предсказуемый и обладающий необходимыми атрибутами качества. На мой взгляд, польза от того, чтобы задизайнить API аналитиками сразу вместо требований к нему, обычно сводится к двум вещам:
получить заранее до начала разработки контракт, чтобы другие стороны могли начать по нему вести разработку;
обеспечить нужное качество методов API, если разработчики об этом не думают и пишут каждый по своему.
Кажется, и первое и второе решается далеко не только перекладыванием вопроса проектирования контракта на аналитиков полностью.
Какие проблемы хотим решить и какие есть?
Здесь начать хочу с того, что нет смысла делать документацию “просто так” или “потому что у всех есть”. Как и везде, документация публичного API должна решать какие-то конкретные задачи и давать определенную пользу. Поэтому перед тем как думать, а какой она должна быть и как ее делать, стоит понять, а какие наши проблемы она должна решать, причем полезно бывает их также проскорить и приоритизировать, чтобы понять их важность.
Вот примеры типовых проблем, которые встречал чаще всего:
Актуальность документации плохо поддерживается, описания устаревают и не обновляются;
Клиенты не могут самостоятельно выполнить интеграцию с продуктом, задают схожие вопросы, ответы на которые тратят время сотрудников;
Затрудняются типовые клиентские интеграции, для них требуется участие аналитиков (или других сотрудников), которые описывают одни и те же API в разных местах;
Новым сотрудникам трудно и долго изучать текущие возможности, потому что информация не консолидирована;
Нет единого источника правды, информация может разниться между ресурсами и людьми;
За информацией люди ходят не в документацию, а к «Developer portal и улучшением онбординга ваших клиентов в целом, но здесь пока это не будем останавливаться на этом подробно.
Обзор подходов к ведению документации API
Итак, давайте наконец попробуем рассмотреть различные подходы к документированию API. Чтобы это было проще понять, разобьём их по категориям — примерно такими же уровнями я двигался сам, когда анализировал тему.
Далее пройдемся по всем уровням, рассмотрим широкую картину, а затем поделюсь для примера мотивами выбора для решения моего кейса.
Первый уровень: по подходу к описанию
Здесь классификацию ведем на основе того, в каком виде вообще будем подходить к документированию. Рассмотрим 3 основные группы:
1. IDL — Interface Definition (Description) Language
IDL в данном случае является разновидностью DSL — Domain Specific Language. Тема использования IDL не нова и вполне успешно применяется для формализации контрактов различных интерфейсов в разработке. Применительно к веб-API подход предполагает использование IDL как дополнительного уровня абстракции над конечной спецификацией. То есть сначала мы описываем наш API с использованием IDL, а затем на основе него при необходимости генерируем, например, OpenAPI-спецификацию. Примерами известных IDL можно называть Smithy от Amazon и TypeSpec (бывший Cadl) от Microsoft.
Если вы захотите копнуть глубже в эту тему, вероятно, рано или поздно наткнетесь на книжку «The Language-Oriented Approach to API Development» by Stephen Mizell. При том, что новое из нее узнать можно, хочу предупредить, что подача автора там сильно однобокая в сторону преимуществ IDL, поэтому не забывайте держать ваше критическое мышление включенным.
2. Стандартизированные спецификации
Здесь немного хитрим: фактически указанные здесь «стандарты» by definition являются теми же IDL. Однако ввиду факта, что IDL мы назвали еще одним дополнительным уровнем абстракции, а также широкой распространенности этих стандартов, их мы вынесем в отдельную группу.
Для RESTful и не только API существуют различные стандарты спецификаций, которые имеют свою четкую структуру и формат и за счет этого дают возможность работать со спецификацией на различных стадиях различными инструментами, такими как редакторы, валидаторы и линтеры, mock-серверы, средства для просмотра и прочие. Наиболее известными стандартами можно назвать OpenAPI, Blueprint и RAML.
А как же JSON Schema?
Очень часто можно услышать, что «мы описываем API в JSON Schema». И на самом деле, здесь нет никакого противоречия: JSON Schema хорошо ложится на описание данных (например, запроса и ответа метода).
В то же самое время OpenAPI позволяет описать API целиком, который представляет из себя больше, чем просто описание данных для методов. Более того, начиная с версии 3.1 OpenAPI Specification является совместимой с JSON Schema. Поэтому предлагаю разделять эти два понятия не как нечто противоположное, а скорее как идущие рядом вещи, которые вполне могут использоваться сообща, беря лучшее от обоих форматов.
3. Произвольные текстовые форматы
Под произвольными текстовыми форматами будем понимать любые сколь-нибудь rich text-подобные редакторы, которые позволяют записывать форматированный текст и имеют встроенные средства его отображения. В данном случае мы создаем «условный» шаблон для нашей спецификации и визуально проверяем описание на соответствие ему. Это можно делать, например, с использованием публичного раздела в Confluence, на основе Google Docs, используя Github wiki или же просто Github-репозиторий с markdown-файлами. Также можно использовать static site generators на основе markdown-файлов, такие как MkDocs или Docusaurus. Главное отличие в том, что наше описание не имеет под собой «жесткой» структуры, формат будет достаточно произвольным и непростым для автоматизированной обработки, но зато начать писать документацию можно гораздо быстрее. В качестве примеров можно посмотреть на документацию gRPC Tinkoff Invest API (использующих как раз MkDocs) или на документацию HeadHunter API на основе markdown-файлов на GitHub.
Второй уровень: по стандарту описания
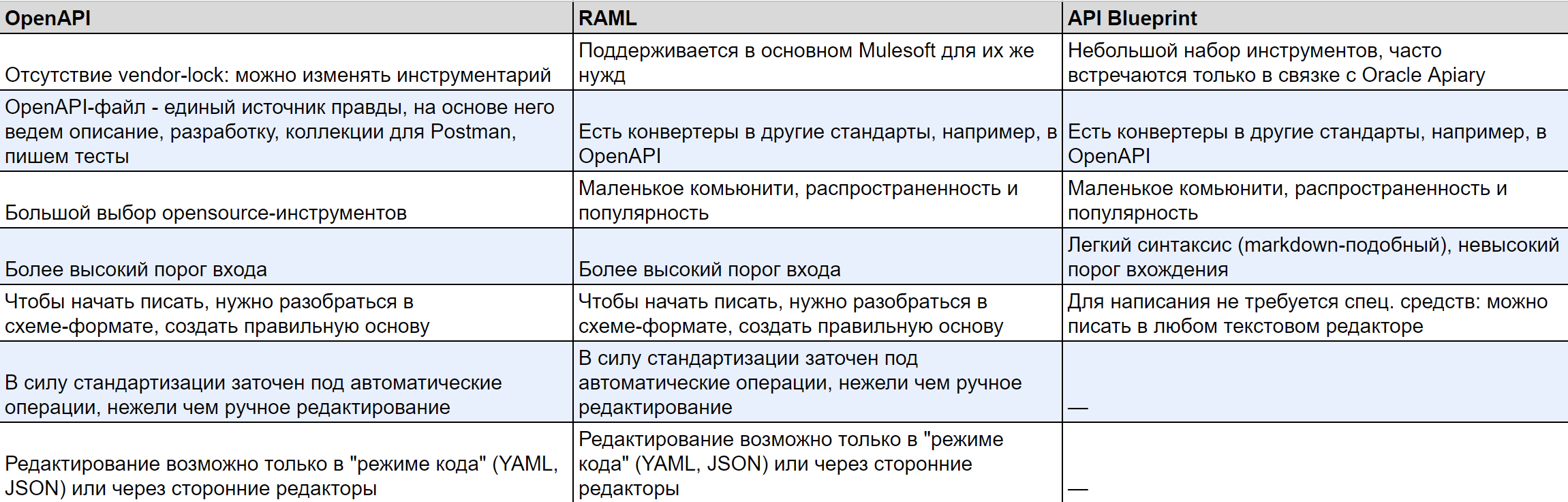
Здесь выделим трех основных кандидатов: OpenAPI, RAML и API Blueprint. Сравнительно их особенности можно представить так:
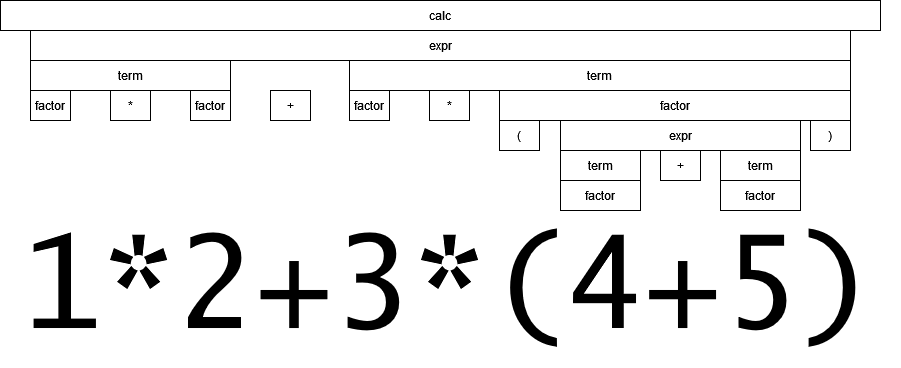
Для лучшего понимания можно посмотреть на примеры их синтаксиса, слева-направо: OpenAPI, RAML, API Blueprint
В первых двух видим привычный YAML (RAML основан на нем же), а у API Blueprint уже заметно отличие
Еще важно упомянуть про распространенность данных форматов и тенденцию их развития – ведь нам дальше еще жить с нашим решением. Здесь можно посмотреть статью от Postman RAML and API Blueprint: where are they now?, а также результаты проведенного ими же исследования за 2022 год:
Здесь можно отметить, что по популярности и своему развитию OpenAPI действительно опережает соседей и, кажется, что такой тренд будет только продолжаться.
Третий уровень: в каком виде отображаем (предоставляем)
Использование Static site generators для отображения документации API – довольно популярный подход. Здесь мы имеем наибольшую гибкость и ограничены только нашими возможностями и воображением, но в то же время создание подобных вещей – не самая дешевая процедура и часто на старте бывает логичнее посмотреть на более простые варианты.
Open Source инструменты здесь как раз могут быть помощниками в таком подходе. Подобрав верный под свои нужды, мы можем иметь достаточную функциональность «из коробки», потратив сначала минимальные усилия на тюнинг, и уже затем по появлении потребностей дорабатывать инструмент под себя.
Использование Software as a Service в своих продуктах является достаточно холиварной темой. С одной стороны, есть мнения про наличие тренда в корпоративном управлении финансами по переводу
Как мы отмечали выше, популярность инструмента Swagger UI превосходит все ожидания, и большинство OpenAPI-спецификаций, которые вы видите, отображаются в нем. Однако является ли это следствием того, что он лучший и самый удобный? По моему опыту взаимодействия с этим инструментом с разных сторон я так сказать не могу.
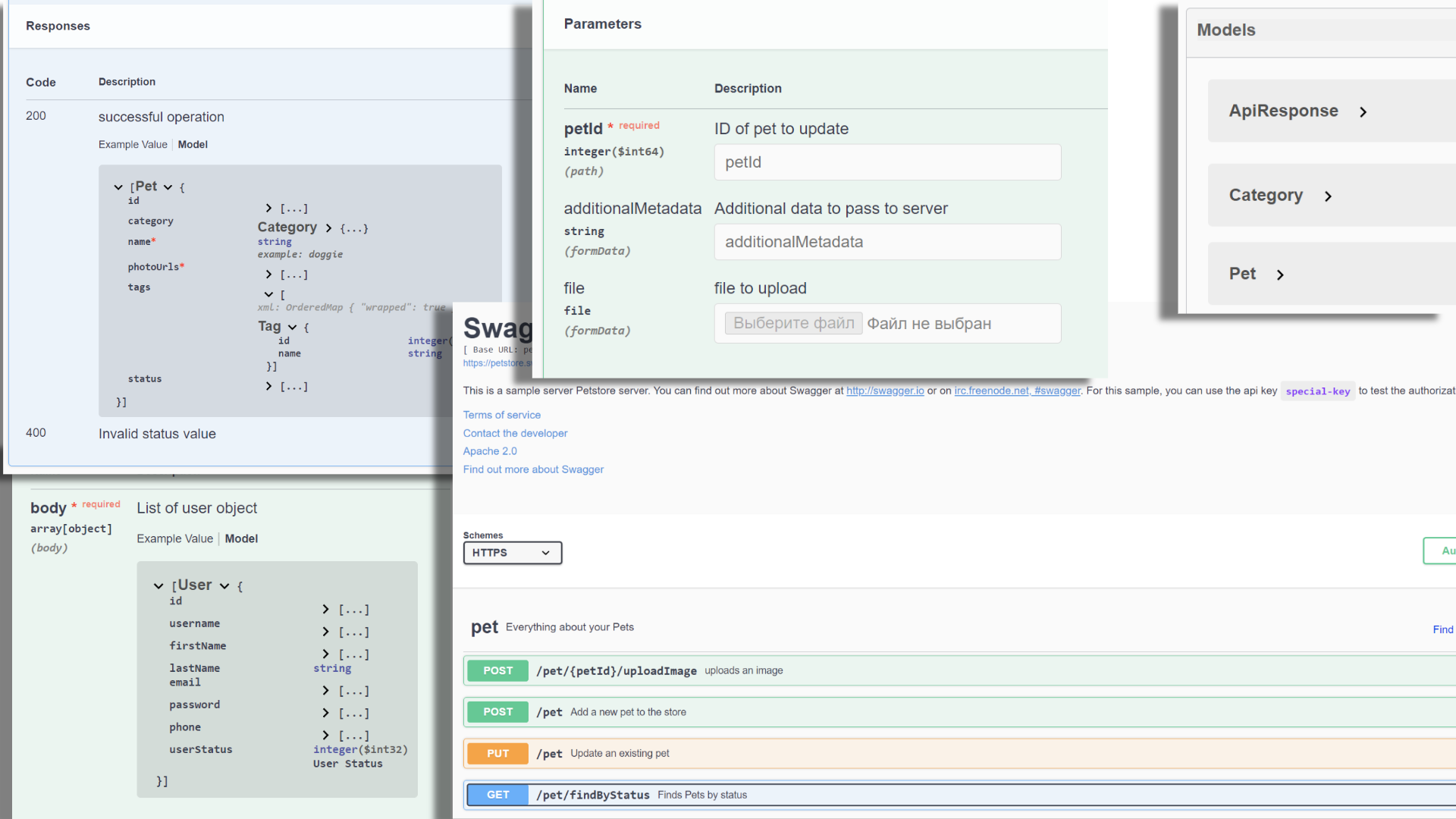
Для тех, кто имел счастье забыть, как же это выглядит, напомним:
Из особенностей Swagger UI могу выделить следующее:
Сфокусирован на отображении описания методов, а не API в целом
Используется one-panel компоновка, на странице только один блок со всей информацией
Не так удобно отображать дополнительную информацию, страница становится длинной
Методы идут списком, поиск не предусмотрен
«Своеобразное» представление описания параметров тела методов
Кастомизация не самая простая и часто вызывает боль
Какие есть альтернативы? Рассмотрев различные Open Source варианты, я могу выделить RapiDoc и Redoc, из достойных это, увы, все. Есть еще, конечно, форки или менее используемые инструменты, однако все они проигрывают или в использовании, или в функциональности.
Пример того, что RapiDoc и Redoc из себя представляют:
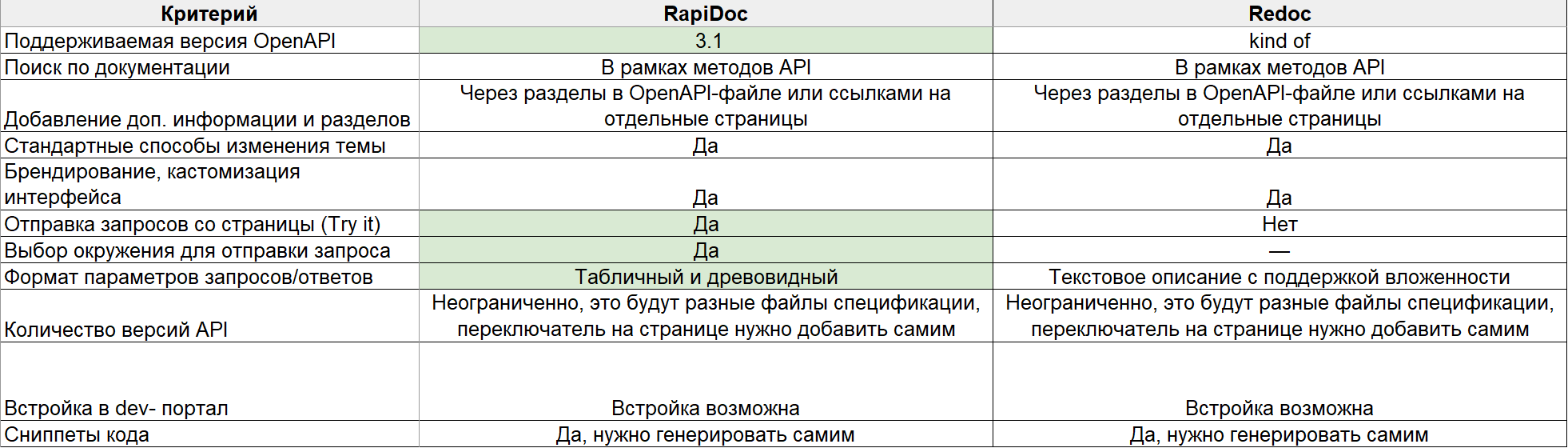
Кратко посмотрим на основные сравнительные характеристики:
И добавлю свое резюме по обоим инструментам,
RapiDoc. Хороший вариант, удобное представление формата тела запроса/ответа, очень богатая кастомизация, можно вызывать запросы со страницы. Можно обновлять спецификацию и страницу отдельно (может быть и плюсом, и минусом). Репозиторий живой, обновления есть, на issues отвечают, есть даже чат в Discord (после спонсирования от Zuplo).
Redoc. Неплохой вариант для быстрого старта, если не критично отсутствие «Try it» функциональности, можно сочетать с их CLI‑утилитой для проверки и быстро сделать свой воркфлоу. Из коробки есть Server‑side rendering (SSR), что может быть полезно для больших спецификаций. Поговаривают, что поддержка и развитие не очень, авторы сосредоточились на платной версии (Redocly).
Здесь для себя сделал выбор в пользу RapiDoc, из‑за его «true Open Source» натуры и уж совсем богатого набора фичей, включая встроенные API (не http-API, а свои программные интерфейсы) для еще большей кастомизации.
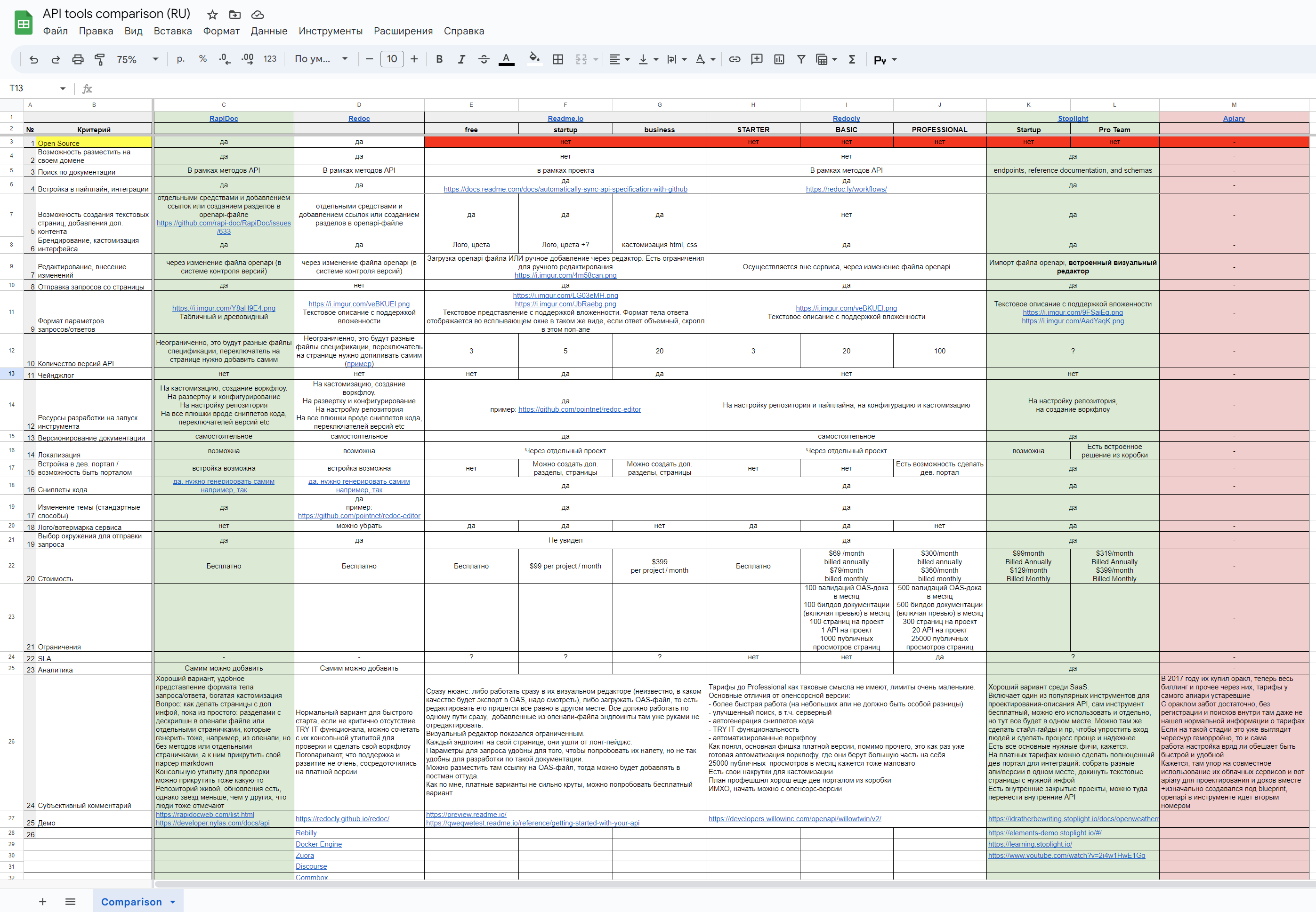
Также прилагаю ссылку на полную таблицу-сравнение инструментов, где присутствуют и SaaS-варианты, которые сравнивал для себя. Сравнение делал еще в 2021 году, но постарался актуализировать для текущего дня.
Таким образом мы разобрались с тем, зачем нам в принципе может быть нужна документация, чем она может отличаться для внутренних и публичных API, посмотрели на примеры типовых проблем и обратили внимание, что проблемы у каждого бывают свои. А также разобрали некоторую классификацию подходов к созданию документации API на трех уровнях: по подходу к описанию, по стандарту и по способу отображения.
Далее — сам процесс написания документации
Эту тему продолжим разбирать уже во 2 части статьи.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Мы живем в эпоху, сущность которой определяют цифровые технологии и электроника. И краеугольный камень этого мира — миниатюрная микросхема, состоящая из кремниевых транзисторов. А они, в свою очередь, были бы невозможны без полупроводников.
Микросхемы, транзисторы и полупроводники можно найти почти в любом устройстве сложнее вентилятора, начиная со стиральных машин и заканчивая космическими спутниками и аппаратами ИВЛ. Поэтому освоение полупроводников можно без сомнений назвать главным изобретением XX века. Рассказываем историю рождения технологии, сформировавшей нашу реальность.
Что такое полупроводники и почему они наше всё
Для начала немного физики. Полупроводники — это вещества с особыми свойствами проводимости электричества. На этих свойствах основана вся современная электроника — именно они позволяют модулировать, усиливать и направлять ток и обмениваться электросигналами.
Но сам по себе полупроводник — это всего лишь материал. Для того, чтобы использовать его особенности, инженеры разработали транзисторы — сложные миниатюрные устройства, управляющие током и преобразующие его. Главный элемент транзистора — p-n-переход (positive-negative), в котором соприкасаются два полупроводника. А из комбинаций транзисторов состоят микросхемы, которые используют обмен сигналами между ними для вычислений.
Чаще всего в качестве полупроводников для транзисторов используют кремний — это самый удобный, дешевый и универсальный материал. Кремний для изготовления полупроводника должен быть очень чистым и состоять из одного кристалла. Поэтому материал для полупроводников выращивают в лабораториях, «вытягивая» расплавленное вещество.
Свойствами полупроводников обладают многие другие элементы и вещества, например германий или сапфир, но в подавляющем большинстве случаев сегодня используется кремний. Для того, чтобы усилить особые свойства полупроводников, они обогащаются добавками — например, мышьяком. Добавление примесей — отдельная непростая задача, которую можно решить множеством способов.
Первые догадки
История покорения полупроводников началась в 1833 году, когда физик Майкл Фарадей заметил, что электропроводность сульфида серебра повышается при нагревании. Другие металлы реагируют обратным образом — чем выше температура, тем хуже через них проходит ток. Через пять лет Антуан Анри Беккерель заметил, что некоторые материалы меняют электропроводность под воздействием света.
В 1874 году Карл Фердинанд Браун обнаружил, что некоторые вещества изменяют электрическое сопротивление в зависимости от направления, величины и продолжительности тока. Это открытие привело к разработке технологии «выпрямления», то есть преобразования переменного тока в постоянный — именно такой механизм лежит в основании радиотехники. Примерно в то же время Артур Шустер сообщил о схожих результатах исследований контакта между проводами из чистой и окисленной меди — последняя здесь действует как полупроводник.
По сути, четыре эти открытия описывают основные свойства полупроводников. Но сущность этих свойств осталась для физиков XIX века загадкой — тогдашняя наука была не способна объяснить их. Исследовать полупроводники удалось лишь в 1920-1940-х годах, когда ученые смогли объяснить их устройство материалов на атомарном уровне.
Германий меняет мир
Электроника, то есть совокупность технологий, позволяющих использовать электрический ток для вычислений и обработки информации, появилась еще в 1930-х годах. До середины 1950-х основным компонентом электронного оборудования были вакуумные лампы. Именно их использовали первые компьютеры, созданные в годы Второй Мировой войны для военных целей.
Главным недостатком вакуумных ламп была чрезвычайная громоздкость. Вакуумная лампа примерно такого же размера, как лампочка накаливания. А транзистор, который выполняет ту же роль, крошечный: первая в истории серийная интегральная микросхема Intel 4004, выпущенная в 1971 году, была 5 сантиметров в длину и вмещала 2300 транзисторов. Поэтому ламповые компьютеры занимали по несколько комнат, но действовали очень медленно.
Кроме того, лампы потребляли гигантские объемы энергии и выделяли огромное количество тепла. Для того, чтобы электроника развивалась дальше, нужно было создать гораздо более экономичный электронный компонент — то есть транзистор.
Первый патент на концепцию полупроводникового транзистора, в котором использовался сульфид меди, еще в 1926 году подал польско-американский изобретатель Юлиус Лилиенфельд. Однако ему так и не удалось воплотить свое гипотетическое изобретение в жизнь — идея была реализована лишь 20 лет спустя.
Транзистор создали ученые из лабораторий корпорации Bell. Они начали изучать потенциал p-n перехода полупроводников еще в середине 1930-х. Однако из-за Второй Мировой войны почти всем передовым американским физикам пришлось пойти работать на армейские проекты, где разрабатывали радары и ядерное оружие. Исследования остановились на несколько лет, и возобновились после разгрома стран Оси.
Первый рабочий транзистор был создан в конце 1947 года. В качестве полупроводника в нем был использован германий — его научились очищать и выращивать раньше, чем кремний. Транзистор разработала группа инженеров во главе с Уильямом Шокли, Уолтером Браттейном и Джоном Бардином. В 1950 году Шокли получил патент на оригинальный транзистор, а Браттейн и Бардин — на его трехэлектродную версию. В 1956 году все трое были награждены Нобелевской премией по физике. Бардин стал единственным человеком, получившим эту премию дважды — в 1972 году он вместе с двумя другими физиками был награжден ей за разработку теории сверхпроводимости.
Открытие транзисторов породило совершенно новую индустрию, причем главным их покупателем стали военные, а чуть позже и НАСА. Лидером отрасли, помимо Bell, стала компания Philco, транзисторы которой первые годы были даже быстрее. Но уже в 1955 году группа ученых из Bell совершила еще одну мини-революцию, создав диффузионный транзистор — он отличался особым способом добавления усиливающих примесей а вещество-полупроводник.
Военные требуют кремния
Германиевые транзисторы стали огромным прорывом. Тем не менее, у них было как минимум два существенных недостатка — они сильно нагревались и не могли работать на высоких температурах. Забегая вперед, отметим, что и для современных интегральных микросхем германий не подходит. Физики знали, что гораздо более удобным полупроводником является кремний. Об этом было известно и военным, которые требовали разработать универсальные и жаропрочные кремниевые транзисторы.
Квалифицированных ученых в США в те годы было очень мало — с 1946 по 1948 год американские университеты выпустили всего 416 физиков и 378 математиков. Фундаментальная наука в стране как отрасль только зарождалась — до Второй Мировой государство почти не финансировало ученых, и им приходилось заниматься сугубо практическими и быстро коммерциализируемыми исследованиями для нужд промышленности, а почти все прорывные теоретические открытия совершались в Европе. Именно Вторая Мировая война, в начале которой Америка заметно отставала в технологиях от Германии, побудила Вашингтон создать первые федеральные программы поддержки фундаментальных исследований.
Количество ученых в США вскоре возросло во много раз, что быстро сделало их мировым лидером во многих отраслях науки. Однако этот эффект проявился лишь через десятилетие. А в 1950-х инновационными исследованиями могли заниматься всего несколько сотен человек на всю огромную страну. Потеряв группу специалистов, компания могла утратить инновацию Поэтому главным механизмом конкуренции стало переманивание ученых.
В 1952 году компания Texas Instruments «схантила» у Bell химика Гордона Тила. В 1954 году он помог техасским инженерам создать первый кремниевый транзистор. Это открытие стало большим сюрпризом. Тил произвел огромный фурор на одной из научных конференций по радиоэлектронике сухой репликой: «несмотря на то, что коллеги рассказывали вам о безрадостных перспективах кремниевых транзисторов, у меня в кармане лежит несколько таких». А затем показал преимущества своего изобретения, сунув усилитель работающего музыкального проигрывателя в кипящее масло — при этом музыка не остановилась. Именно этот транзистор можно считать прямым предком подавляющего большинства микросхем, окружающих нас.
Эти новые кремниевые транзисторы от Texas Instruments были адаптированы для использования в военной аппаратуре: бортовых радарах, средствах связи и навигационном оборудовании. К концу 1950-х они сделали Texas Instruments лидером отрасли и главным получателем военных госзаказов в сфере электроники. Очень вовремя — из-за Холодной войны в ВПК потекли огромные деньги. Их продажи выросли с нескольких сотен тысяч долларов в 1954 году до более чем 80 миллионов долларов в 1960 году.
В следующей статье мы расскажем о создании микрочипа, рождении современной Кремниевой долины, а также о состоянии полупроводниковой индустрии сегодня.
О сервисе Онлайн Патент
Онлайн Патент — цифровая система № 1 в рейтинге Роспатента. С 2013 года мы создаем уникальные LegalTech‑решения для защиты и управления интеллектуальной собственностью. Зарегистрируйтесь в сервисе Онлайн‑Патент и получите доступ к следующим услугам:
Онлайн‑регистрация программ, патентов на изобретение, товарных знаков, промышленного дизайна;
Подача заявки на внесение в реестр отечественного ПО;
Опции ускоренного оформления услуг;
Бесплатный поиск по базам патентов, программ, товарных знаков;
Мониторинги новых заявок по критериям;
Онлайн‑поддержку специалистов.
Больше статей, аналитики от экспертов и полезной информации о интеллектуальной собственности в России и мире ищите в нашем Телеграм‑канале.








, а у API Blueprint уже заметно отличие")