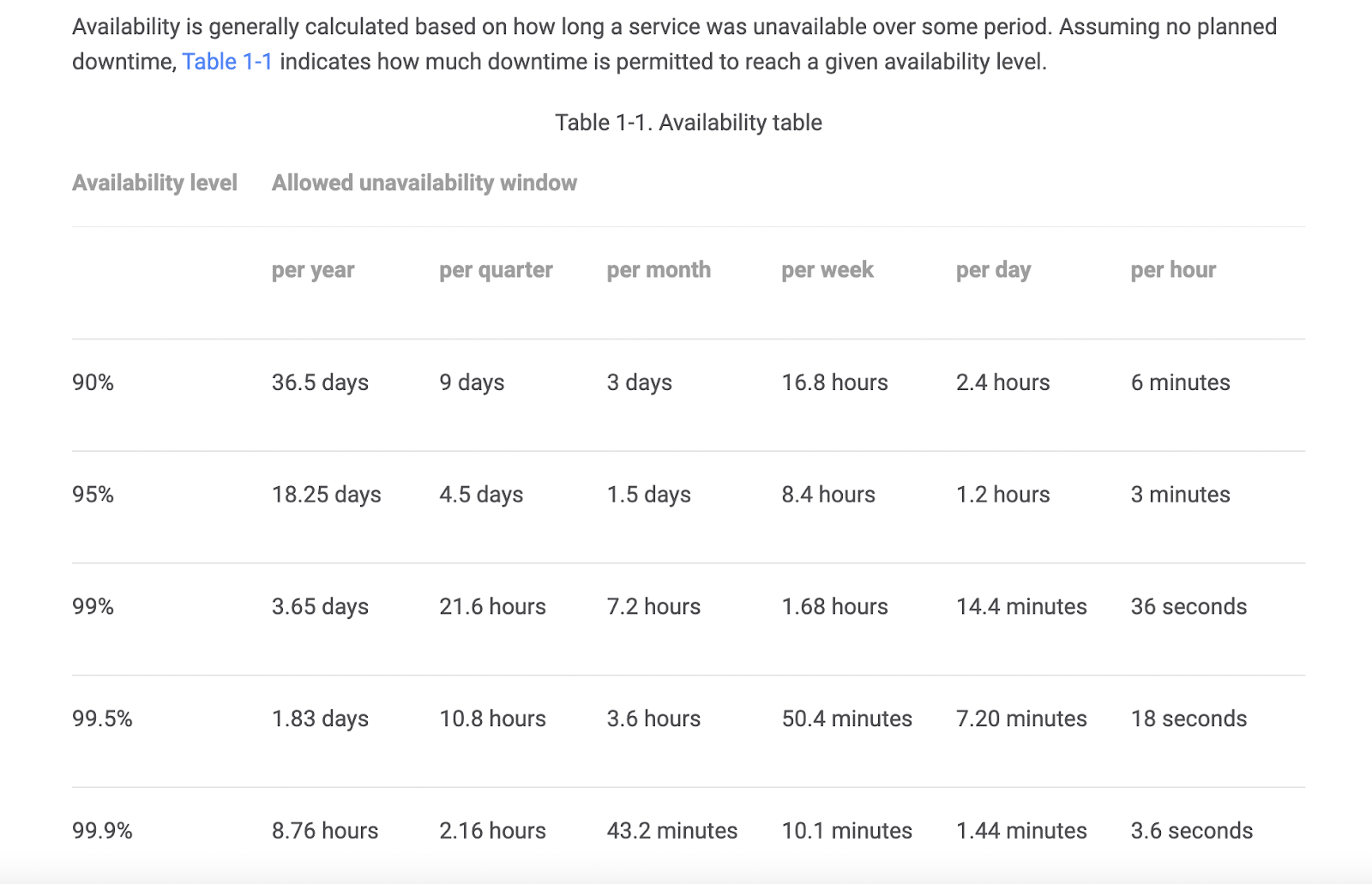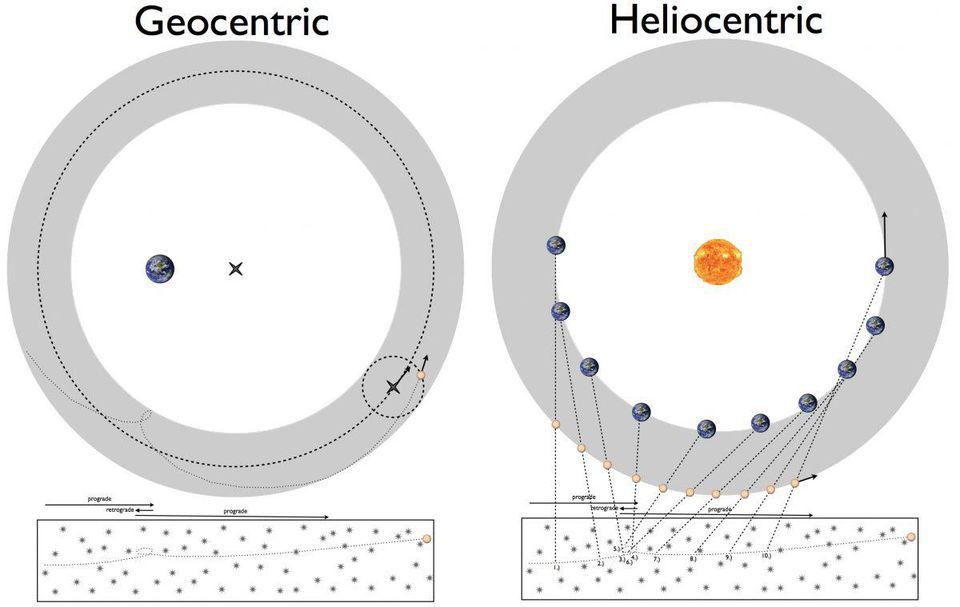
Одной из величайших загадок XVI века был вопрос с видимым ретроградным движением планет. Объяснения давали как геоцентрическая модель Птолемея (слева), так и гелиоцентрическая модель Коперника (справа). Однако для полного уточнения этого вопроса потребовались теоретические прорывы в понимании законов, лежащих в основе наблюдаемых явлений. В итоге Кеплер открыл свои законы, а Ньютон описал закон всемирного тяготения.
Меркурий становится ретроградным – то есть, меняет направление своего движения по небесной сфере – 3-4 раза в год. Последний раз он проделал это 9 сентября 2022 года. Такое его поведение известно с античных времён, и сначала его неправильно объясняли через теорию эпициклов от Птолемея. Сегодня же мы лучше понимаем гравитацию и то, как объекты двигаются в рамках Солнечной системы. Почему же именно Меркурий ведёт себя так?
Практически весь год наблюдатель на Земле может видеть движение планет по небу, и происходит оно довольно предсказуемо. Если звёзды для наблюдателя остаются неподвижными относительно друг друга, то планеты – будучи гораздо ближе к нам, чем звёзды – ночь от ночи сдвигаются на небе. Большую часть времени эти далёкие миры медленно двигаются в одну и ту же сторону – обычно с запада на восток, причём каждый день их восход и закат происходит всё позже и позже.
Но иногда, если вы будете отслеживать движение каждой из планет постоянно и долго, несколько недель или месяцев, вы заметите, что планета начнёт двигаться медленнее, а потом вообще остановится. После этого на несколько недель она поменяет направление своего движения – это будет т.н. ретроградный период. Наконец это движение вновь замедлится, его направление снова поменяется, и планета снова пойдёт в ту сторону, куда двигалась до этого. Ретроградные периоды обладают своими особенностями для каждой из планет, при этом у Меркурия они самые короткие и самые частые.
Когда большинство планет Солнечной системы входят в ретроградный период – включая Марс, Юпитер, Сатурн, Уран и Нептун – это происходит потому, что Земля «нагоняет» их на орбитах. У орбиты каждой из планет, движущихся вокруг Солнца, есть свои особенности – среднее расстояние до светила и средняя орбитальная скорость. Быстрее всего движутся самые близкие к Солнцу планеты, а медленнее – самые далёкие.
Земля находится на среднем расстоянии в 150 млн км от Солнца и большую часть года движется по орбите со скоростью 30 км/с. Меркурий и Венера расположены ближе и двигаются быстрее. Среднее расстояние от Меркурия до Солнца – 58 млн км, скорость – 47 км/с. Все внешние планеты расположены дальше и двигаются медленнее. Нептун расположен на расстоянии в 4,5 млрд км и движется со скоростью в 5 км/с. На полный оборот по орбите у Нептуна уходит более 160 земных лет. Меркурий же успевает более четырёх раз пробежать вокруг Солнца, пока Земля делает один оборот.
Одной из наиболее гениальных геометрических идей истории было осознание того, что для возникновения ретроградного движения, наблюдаемого с Земли, планете вовсе не нужно физически менять траекторию движения, его скорость или направление. Всё это можно объяснить при помощи простой гелиоцентрической модели. Возьмём для примера Землю и Марс. Марс находится дальше от Солнца и медленнее движется по орбите. Соответственно, Земля совершает один оборот за меньшее время. В итоге, когда Земля проходит между Солнцем и Марсом, она его «обгоняет».
Обгон планеты для нас будет выглядеть так же, как обгон на шоссе автомобиля – с нашей точки зрения планета будет двигаться «назад», хотя на самом деле все мы движемся вперёд, просто другая планета делает это медленнее. Поскольку Земля двигается по космосу быстрее Марса и примерно в том же направлении, кажется, что Марс меняет нормальное направление движения с запада на восток на противоположное, и начинает двигаться с востока на запад относительно неподвижных звёзд. И только после пары месяцев ретроградного движения Марс возобновляет привычное перемещение, когда Земля движется по примерно перпендикулярному вектору.
Подобная схема работает для всех внешних планет. Чем дальше планета, тем сильнее эффект. Если скорость движения Марса сравнима с Земной, то Сатурн, Уран и Нептун движутся гораздо медленнее, поэтому их движение по нашей небесной сфере почти полностью определяется тем, как Земля движется по Солнечной системе. Каждый раз, когда Земля проходит между более удалённой планетой и Солнцем, видимое движение этой планеты по нашему небосводу меняется с обычного (с запада на восток) на ретроградное (с востока на запад). Потом в какой-то момент, когда Земля, пройдя по орбите, начинает двигаться в другом направлении, внешняя планета вновь начинает обычное движение по небу.
Со внутренними планетами, Венерой и Меркурием, всё происходит наоборот. Они двигаются по орбитам быстрее Земли, а их орбиты меньше нашей. Большую часть времени Меркурий и Венера двигаются с востока на запад, постепенно превращаясь из утренних звёзд (видимых в небе до рассвета) в вечерние (видимые после заката).
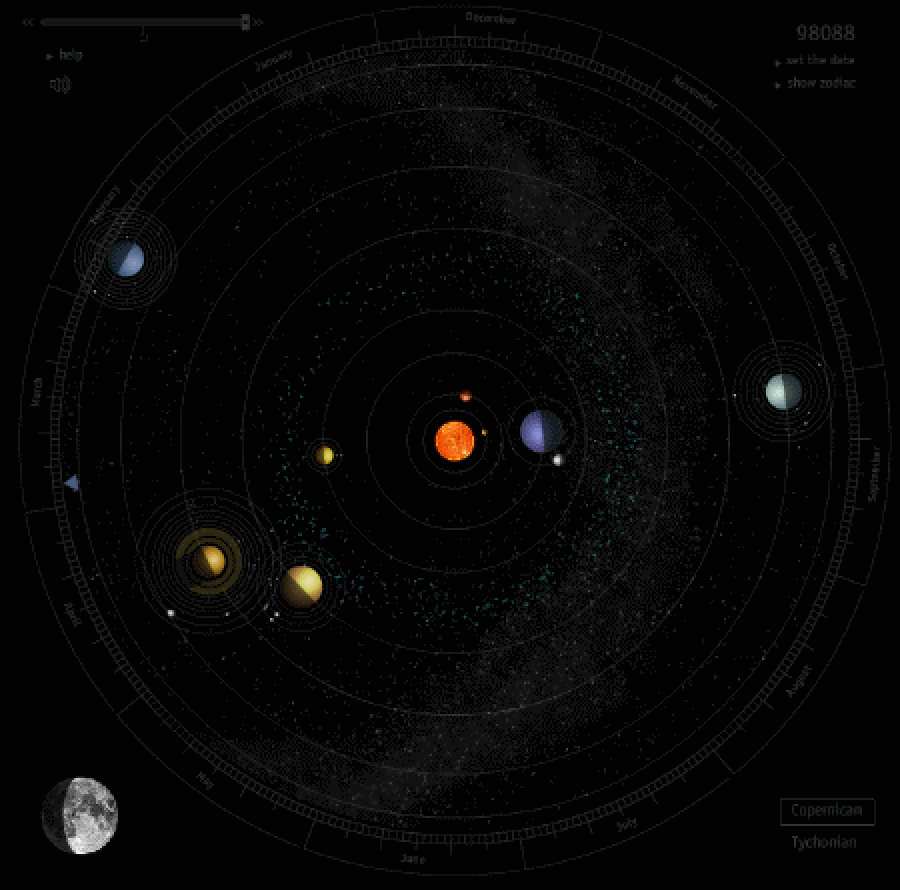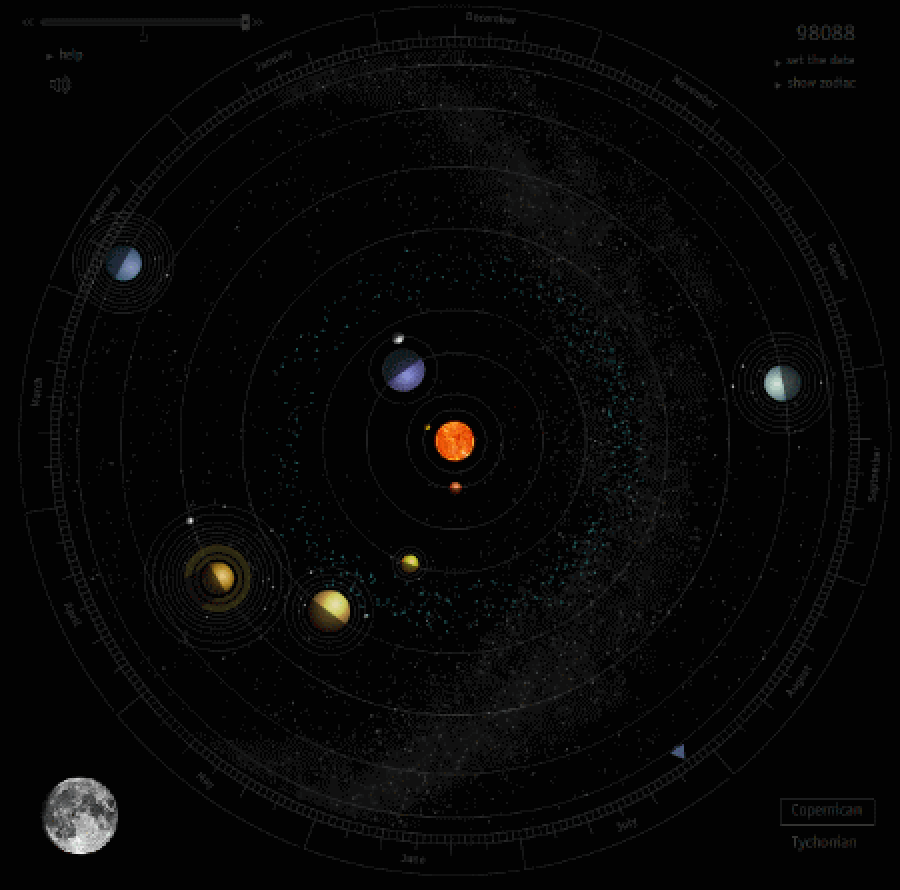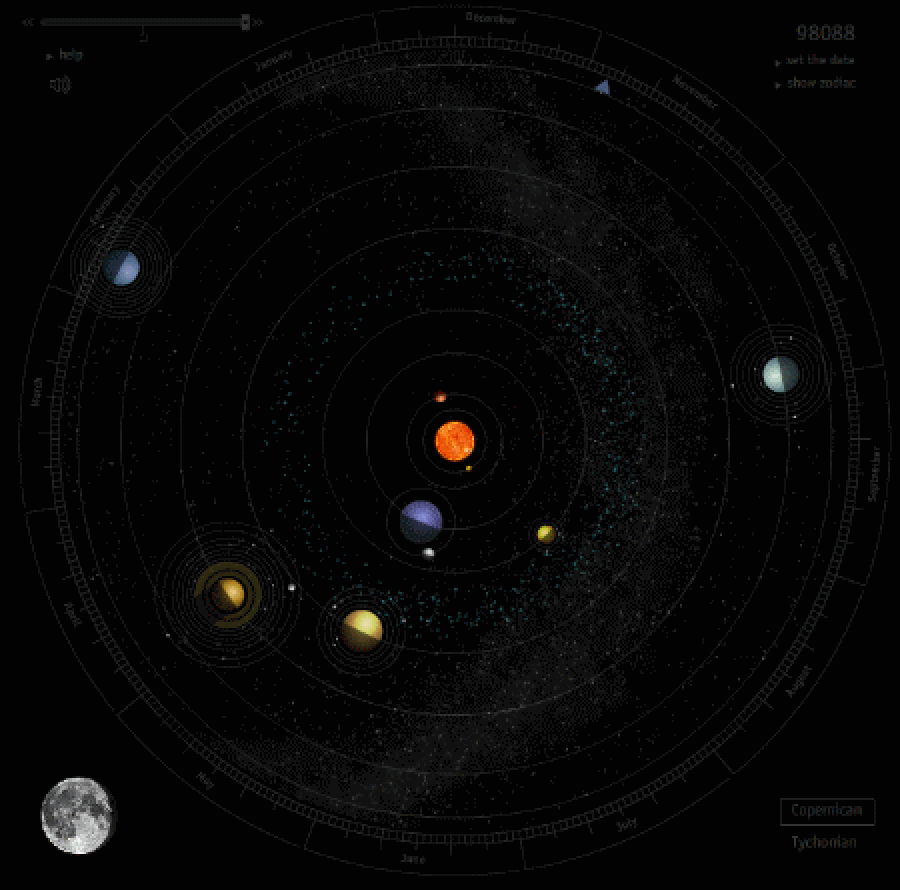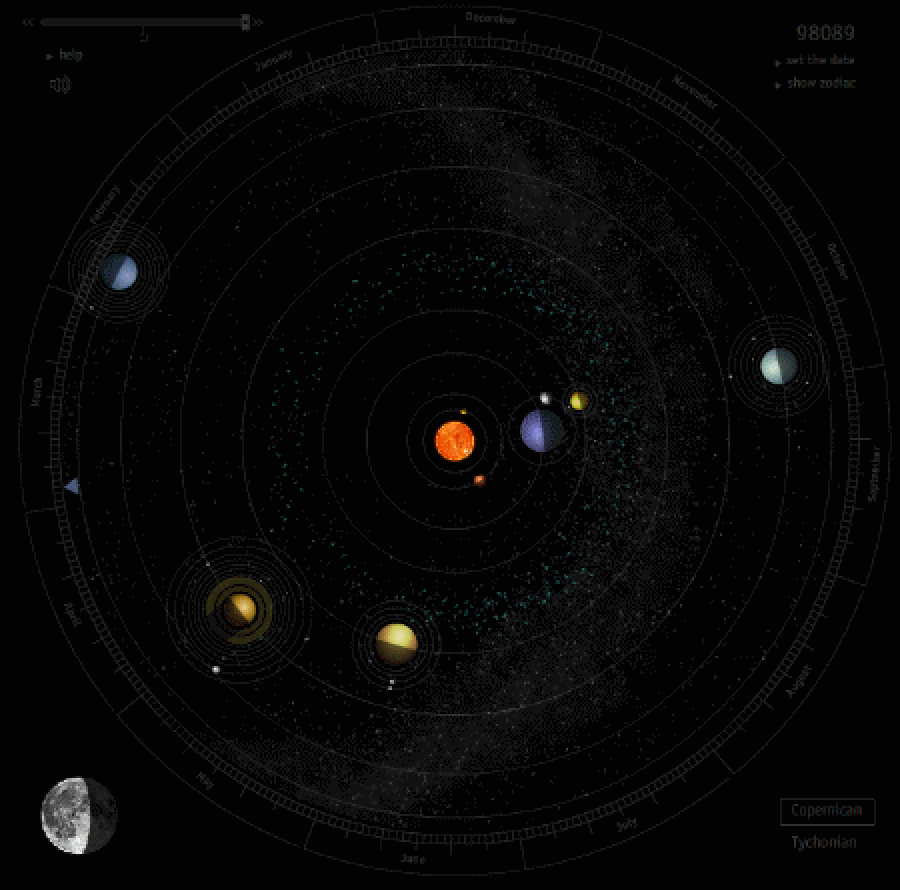
Симуляция движения планет Солнечной системы за один земной год. Видно, как Меркурий перегоняет Землю на орбите три раза за год. Период обращения Меркурия составляет всего 88 дней, поэтому у него бывает 3-4 ретроградных периода за год – это единственная планета, у которой таких периодов в год больше одного. Другие планеты начинают ретроградное движение только когда их обгоняет Земля – примерно раз в год для всех планет, кроме Марса, у которого это бывает реже.
Однако в какой-то определённый момент – в последний раз с Меркурием такое случилось 9 сентября 2022 года – внутренняя планета входит в период максимальной элонгации в небе после заката, когда она находится в дальней от Солнца точке, к западу от него. Через непродолжительное время, в данном случае – пару недель, внутренняя планета переходит на ретроградное движение, с запада на восток. Только у Венеры и Меркурия ретроградное движение связано с перемещением по небу с запада на восток.
Эти ретроградные периоды соответствуют той части орбит Венеры и Меркурия, где эти внутренние планеты движутся между Солнцем и Землёй, и обгоняют нас. Случается это тогда, когда у внутренней планеты компонент скорости, направленной в ту же сторону, что и наша скорость, оказывается выше, чем у Земли, и длится это всего несколько недель. Меркурий начал свой ретроградный период 9 сентября и закончил 1 октября.
Когда внутренняя планета обгоняет Землю, она начинает «заворачивать», обходя Солнце вокруг, и ретроградный период заканчивается, когда её компонента скорости по направлению движения Земли становится меньше, чем у Земли. При этом элонгация планеты будет ещё какое-то время увеличиваться. Хотя ретроградный период Меркурия начался 9 сентября, максимальной элонгации он достиг 27 августа. И наоборот, хотя его ретроградный период закончился 1 октября, максимальной восточной элонгации, видимой в утреннем небе, он достиг 8 октября.
У Меркурия, который завершает полный оборот вокруг Солнца всего за 88 дней (примерно за четверть земного года), часто и регулярно случаются другие ретроградные периоды. Следующий ретроградный период Меркурия начнётся в январе 2023 года, потом в мае, потом в сентябре и потом в декабре 2023. В любой год обычно укладываются 3-4 ретроградных периода Меркурия – у других планет такое случается обычно только по разу в год, а у Марса иногда и реже.
Для любой планеты, движущейся ретроградно, наступает момент, когда Солнце, Земля и эта планета находятся на одной прямой. Этот момент называется нижним соединением – когда внутренняя планета проходит ровно через линию, соединяющую Землю и Солнце. Поскольку плоскости орбит разных планет немного различаются, идеальные соединения происходят довольно редко. Однако такое бывает, мы можем наблюдать такое замечательное явление, как транзит планеты по диску Солнца с точки зрения Земли.
Будущие нижние соединения Меркурия ожидаются 7 января, 1 мая, 6 сентября и 22 декабря 2023 года. Но транзитов по диску Солнца там не будет. Последний транзит Меркурия был 11 ноября 2019 года, а следующий будет только в 2032 году. Из-за того, что Меркурий расположен близко к Солнцу, быстро движется по орбите, а плоскость его орбиты не сильно отличается от нашей, транзиты Меркурия случаются чаще, чем транзиты Венеры.
Венера находится почти в два раза дальше от Солнца, чем Меркурий, плоскость её орбиты наклонена сильнее, а нижнее соединение с Землёй у неё происходит раз в 19 месяцев — а не раз в 3-4 месяца, как у Меркурия.
Одно из прохождений Венеры случилось 6 июня 1761 года, и поскольку оно было вычислено заранее, за ним наблюдали десятки учёных XVIII века, среди которых был и Михаил Васильевич Ломоносов. Наблюдая за эффектами, видимыми во время прохождения, Ломоносов увидел некое размытие контуров планеты и верно истолковал его, как следствие преломления солнечного света в атмосфере Венеры, не уступающей по величине атмосфере Земли. Впоследствии эффект был назван «явлением Ломоносова».
В наше время последний транзит Венеры по диску Солнца случился с 5 на 6 июня 2012 года, а следующий ожидается лишь с 10 на 11 декабря 2117! Средний человек может увидеть лишь два транзита Венеры за всю жизнь, и если вы пропустили транзиты 2004 и 2012 года, вам придётся очень хорошо следить за своим здоровьем, чтобы дожить до следующего.
Во время своих ретроградных периодов Меркурий подходит к Земле ближе всего, и соответственно гравитационно воздействует на неё сильнее, чем в другие периоды. Во время следующего нижнего соединения Меркурий подойдёт на 96 млн км к Земле, однако некоторые соединения могут сокращать это расстояние до минимальных 82 млн км – последний раз такое было в 2015-м. Кроме того, хотя Меркурий и является самой малой планетой Солнечной системы, он может иметь видимый размер в 10 угловых секунд, т.е. в 1/6 угловой минуты (угловая минута составляет 1/60 градуса).
Это всё очень интересно, однако влияние Меркурия на Землю во время ретроградного движения и даже во время нижнего соединения практически невозможно засечь. Как Земля вызывает прецессию орбиты Меркурия, так и Меркурий вызывает прецессию орбиты Земли. К сожалению (или к счастью) эта прецессия меняет орбиту меньше, чем на одну угловую секунду в год, что практически невозможно заметить. Засветки неба Меркурий тоже никакой не даёт, а приливное действие Меркурия меньше, чем у Луны в миллион раз. Так что Меркурий, будь он ретроградным или каким-либо ещё, практически никак не может повлиять на жизнь на Земле – по крайней мере, так, как мы можем измерить.
Однако явление это интересное и абсолютно реальное. Из всех планет Солнечной системы лишь Меркурий становится ретроградным по нескольку раз в год, и обычно это бывает 3-4 раза. Внутренние планеты обычно движутся в небе Земли с востока на запад, а внешние – с запада на восток. В ретроградные периоды всё наоборот – Марс, Юпитер, Сатурн, Уран и Нептун движутся с востока на запад, а Меркурий с запада на восток.
Большинство людей, говоря о ретроградном Меркурии, подразумевают астрологию – они интересуются и беспокоятся о том, как это может повлиять на их жизнь на Земле. Неизвестно, является ли подобное воспринимаемое людьми влияние чем-то большим, чем просто склонностью наблюдателя к подтверждению своей точки зрения, однако астрофизика позволяет нам чётко описать влияние планеты на нашу жизнь – визуально, гравитационно и в связи с приливами. И это влияние практически неразличимо. Но по крайней мере, если теперь вы увидите ретроградное движение Меркурия в ночном небе, вы будете точно знать, отчего это происходит.
ссылка на оригинал статьи https://habr.com/ru/post/708508/