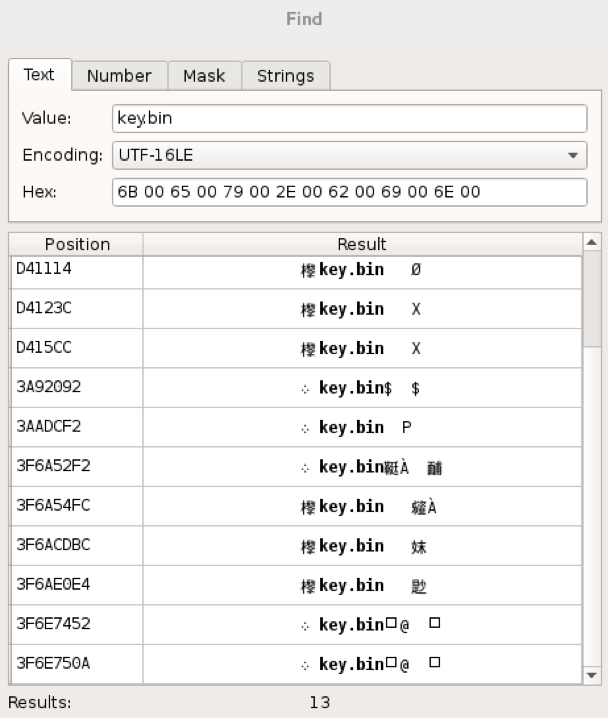
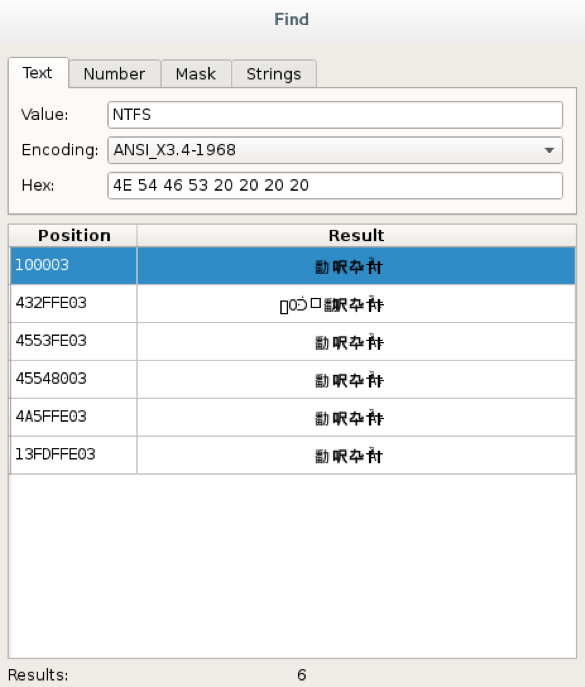
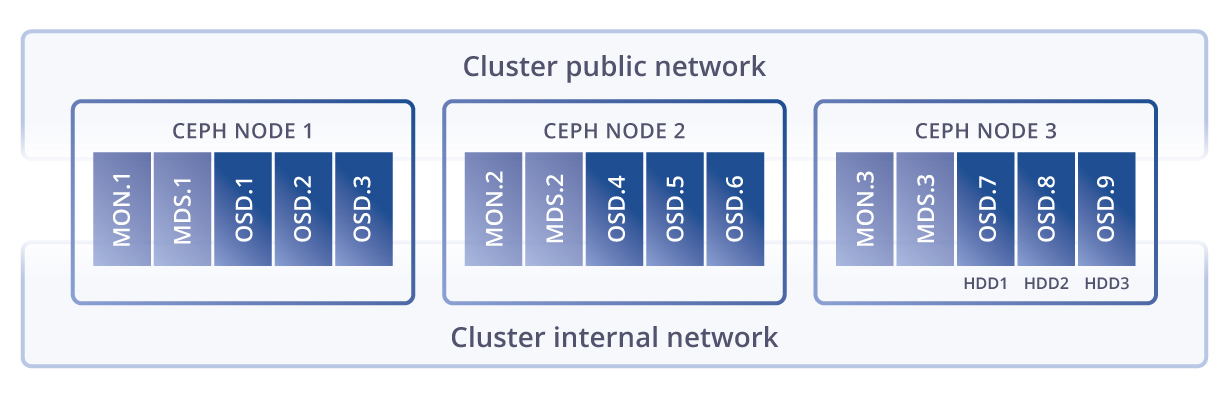
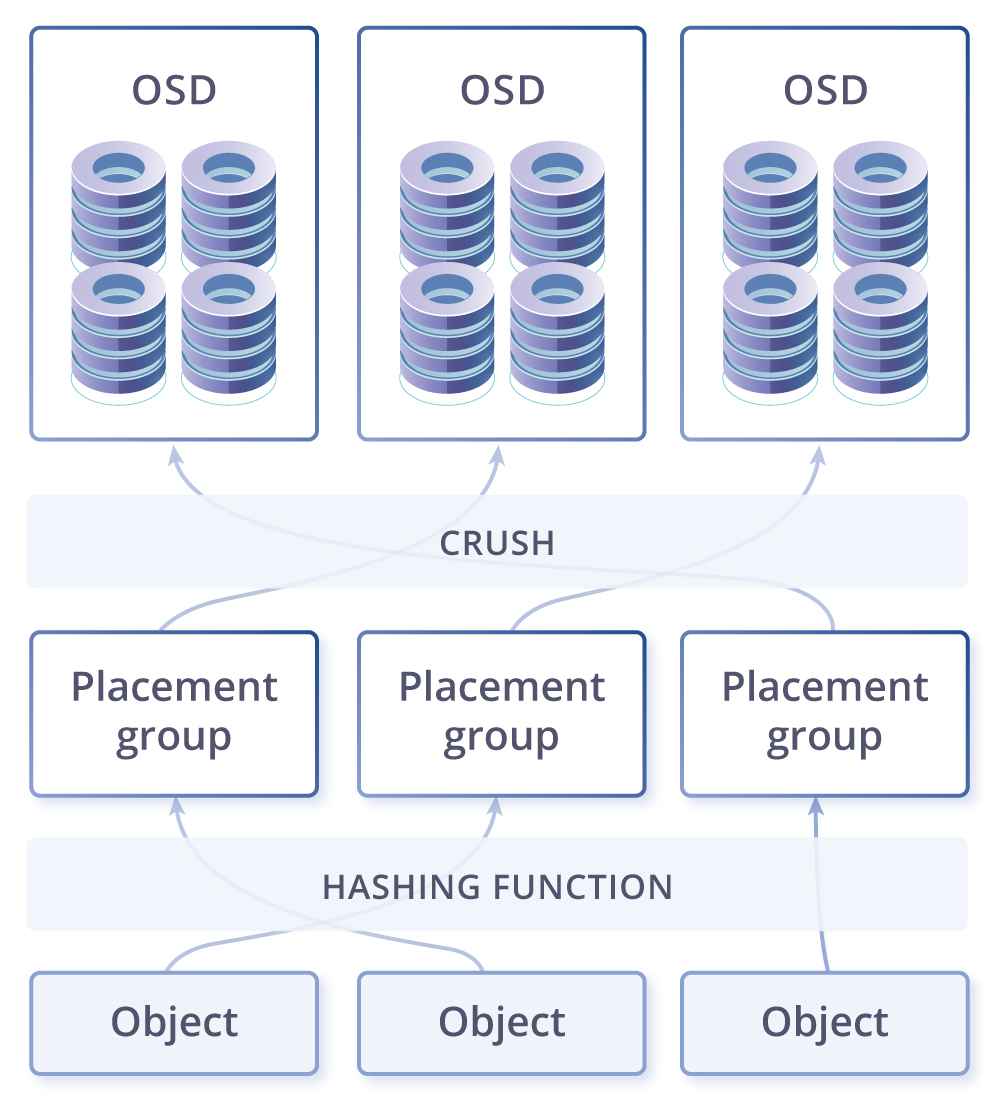
Мои последние исследования, результат которых описан в предыдущих статьях, привели меня к мысли: а что, если создать систему, противоположную Системе подавления — Систему Раскрытия Потенциала, применимую к планете Земля и человечеству? Данная система описывает правила такого устройства многомерной среды обитания существ, в которой энтропия сознания сведена к минимуму. Живущие/играющие в ней существа реализуют весь доступный им Потенциал — совокупность всех их интеллектуальных, физических и всех прочих ресурсов, данных им во всём пространстве и времени, в полном объёме. Иначе говоря, как сделать идеальную игру?

Дисклеймер
Эта статья — концепт-документ, в котором я описываю подход к разработке Системы раскрытия потенциала, а не дизайн-документ. Излишние на мой взгляд подробности и детали опущены намерено, чтобы сосредоточиться на сути Системы раскрытия потенциала. Я не гарантирую, что вы поймёте всё, о чём будет сказано в статье и что она полностью соответствует вашему мировоззрению, подходу к познанию и к привычной стилистике читаемых вами статей. Изложенные ниже идеи являются моим личным мнением, философскими размышлениями на тему и не претендуют на полную непогрешимость. Сколько людей, столько и хэшей сознания, я лишь делюсь своим в осторожном предположении, что кому-то это всё будет интересно. Возможно кто-то, погрузившись достаточно глубоко в мои мысли, сможет взглянуть на привычные вещи под новым углом или же найти источник вдохновения. Всем peace! Погнали.
Идея идеальной игры
Почти десять лет назад я писал научно-фантастический роман “Другая сторона бесконечности”, по сути просто выдавая потоком содержимое своего подсознания. Смысл написанного в полной мере дошёл до меня только сейчас и он поразил меня своей глубиной и кристальной чистотой разгадок тайн Мироздания. Например, детальным описанием регрессионной терапии, о которой тогда я на уровне сознания не знал ровно ничего, или же инверсию Системы подавления потенциала в Систему раскрытия потенциала, о чём я тогда имел весьма смутные представления. Сейчас я разрабатываю новый вариант книги, в котором описываю переход человечества в Систему раскрытия потенциала более системно, зная гораздо больше деталей устройства нашего мира и понимая, что никакая это не фантастика, а самый настоящий вариант нашего возможного будущего.

Один из моих главных жизненных интересов — создание игровых миров с необычными и увлекательными правилами взаимодействия игроков между собой и с окружением. Создание миров в той или иной форме было доступно человеку всегда, а с появлением видеоигр эта деятельность вышла на новый уровень. Люди уже создают полноценные виртуальные вселенные, в которых проводят эксперименты с правилами взаимодействия игроков между собой и с самим миром. И тенденция такова, что с каждым годом “виртуального” контента, который имеет вполне реальное влияние на сознания людей, становится всё больше, а технологии погружения совершенствуются. По факту, потенциал человечества всё больше переключается в миры, которые этим же человечеством и создаются. Всё идёт к тому, что рано или поздно будут созданы совершенно необъятные вселенные, каждая из которых даёт свой уникальный опыт.
Варясь вокруг да около этой индустрии, я понял, что ключевым универсальным правилом хорошей игры является то, что она позволяет достигать состояния потока и находиться в нём продолжительное время. Поток в рамках игры — это трансовое состояние погружения в процесс игры, достигаемый, когда решение какой-либо игровой задачи не очень легко, не невозможно, и трудно ровно в той степени, в которой игроком для её решения задействована значительная часть его потенциала, интеллектуальных и иных ресурсов. Важным аспектом такого игрового потокового состояния является то, что игровые задачи игроку интересны сами по себе и нахождение в потоке при их выполнении вызывает потерю чувства времени и лёгкую эйфорию.

Однажды, когда я рассматривал приведённый выше арт к многопользовательской ролевой игре Wildstar, в голове у меня щёлкнуло и я понял: на ней изображено, как два существа, играя, находятся в состоянии потока. И у меня возникло понимание, что мир, близкий к идеальному, это тот, в котором подобные состояния потока не являются случайными и сиюминутными, нахождение в них взято за правило, и сам мир, все его аспекты, способствуют к пребыванию в потоке всех существ, находящихся в этом мире. Получается, что основное правило хорошего “виртуального” мира выполняется в этом “реальном” мире в полной мере. Что это за мир? Какими аспектами он обладает? Возможно ли его в той или иной мере сделать или достичь? Мне удалось через маленькую щёлочку заглянуть в него, однако этого было достаточно, чтобы глубинное понимание его сути пришло. Теперь на все эти вопросы я постепенно нахожу ответы, собирая кусочки этого мира у себя в голове и которые я собираюсь переложить в свою книгу. Части многомерной мозаики устройства того мира, находящегося под покровительством Системы Раскрытия Потенциала, я постепенно нахожу в различных аспектах жизни на планете Земля — произведениях культуры и искусства, исследованиях, людях, эмоциях, чувствах, материальных и нематериальных объектах, и т.д. И тут возникает вопрос — где источник этих кусочков мозаики?

Всё, что существует на свете, когда-то было всего лишь мечтой. Всё дело в том, что тот близкий к совершенному мир постепенно материализуется в нашей с вами реальности. Человечество жаждет находиться в таком мире и тоскует по нему — вспомните, например, ажиотаж вокруг Аватара Кэмерона, в котором была показана модель такого гармоничного мира. Человек, даже одним шажком попав на Пандору, как Джейк Салли с помощью аватара или зритель с помощью магии кино, осознаёт его глубинную красоту и начинает мечтать хотя бы на какое-то время забыться в нём без остатка. А раз запрос такого количества живых существ на создание гармоничного мира есть, то значит будет и его реализация. Совершенный мир постепенно спускается к нам по этажам реальности, начиная с информационного плана, и сейчас его обретающие материализацию кусочки проявляются, например, в произведениях искусства. А я из найденных мною кусочков создаю маленькую, но полностью собранную мозаику, отображающую мозаику полную, пытаясь предугадать, каким будет этот совершенный мир и по каким правилам он будет работать, по сути собираю его хэш-сумму. А мир же, в свою очередь, является многомерной хэш-суммой из тех участков сознаний людей, которые отвечают за их представления о гармоничном мире. Общие представления о нём, в свою очередь, берутся из нашего строения как людей (материальные и нематериальные аспекты), а частные берутся из индивидуальных особенностей личности.
Где я ищу кусочки мозаики?
Путешествия между параллельными реальными и “виртуальными” мирами, попадания в иные миры и реальности через пространство и время, визиты жителей других миров на Землю, реинкарнации в иных мирах являются чуть ли не главной темой массовой культуры Японии. В огромном количестве эти приключения описываются в ранобе, манге, аниме. В качестве яркого примера, откуда я добываю кусочки мозаики и как совершенный мир материализуется в произведениях искусства, приведу аниме No Game No Life.

Сюжет таков: некий мир раздирает ужасающая война. Чтобы её остановить, “Призраки”, нейтральная группа людей в результате серии манипуляции противниками добираются до мощнейшего артефакта, позволяющего получить полный доступ к магической силе планеты и практически неограниченную силу управления пространством и материей, а также возможность перемещаться между измерениями. Однако добравшийся до артефакта лидер Призраков не может взять его в свои руки, т.к. он уже на грани жизни и смерти. Но подходящее существо, которому можно доверить артефакт, всё-таки появляется. В критический момент из-за близости источника магической сингулярности идея лидера о Совершенном Игроке (с которым он “сам с собой” постоянно играл в шахматы) материализуется, из неё появляется Тет, бог игр, берёт в руки артефакт и после этого начинает создание гармоничного мироустройства, в котором нет места ужасам прошлого. В построенном им мире распределение ключевых ресурсов и “войны” между магическими расами происходят за счёт игр, в которых расы используют свои уникальные способности. Обустраивая мир, Тет путешествует между измерениями в поиске новых игр, стратегий и талантливых игроков.
Интерпретируя сюжет в соответствии с моими представлениями, можно сказать, что лидер добирается до своего Источника, обладающего неограниченной силой и полностью осознаёт себя как чистую идею, свою изначальную версию, версию совершенного игрока. Происходит его трансформация в бога игр и после этого он в соответствии со своей Истинной Сутью, изначальной идеей, открывающей доступ к магической сингулярности, начинает обустройство своего мира, выбирая из бесконечного многообразия только то, что считает интересным и гармоничным.
Какими ещё идеями я руководствуюсь при разработке Системы раскрытия потенциала — информационной матрицы, управляющей работой близкого к совершенному мира, по которому тоскует человечество?

Суть одного из важнейших интеллектуальных артефактов мира, философии Русского Космизма можно выразить словами её основоположника, Николая Фёдорова: “Потому в природе и нет целесообразности, что её должен внести сам человек, и в этом заключается высшая целесообразность”. Также позвольте процитировать статью о Николае Фёдорове из Википедии: “Обращая внимание на факт направления эволюции к порождению разума, сознания, космисты выдвигают идею активной эволюции, то есть необходимости нового сознательного этапа развития мира, когда человечество направляет его в ту сторону, в какую диктует ему разум и нравственное чувство, берет, так сказать, штурвал эволюции в свои руки. Человек для эволюционных мыслителей — существо ещё промежуточное, находящееся в процессе роста, далеко не совершенное, но вместе сознательно-творческое, призванное преобразить не только внешний мир, но и собственную природу. Речь по существу идет о расширении прав сознательно-духовных сил, об управлении материи духом, об одухотворении мира и человека. Космическая экспансия — одна из частей этой грандиозной программы. Космисты сумели соединить заботу о большом целом — Земле, биосфере, космосе с глубочайшими запросами высшей ценности — конкретного человека”.
Могу с уверенностью заявить, что все вышеперечисленные мысли можно в полной мере отнести к моему миропониманию, которое послужило источником начала разработки Системы Раскрытия Потенциала. Для меня очевидно, что наша Вселенная дала нам бесконечно большое разнообразие всего на свете, абсолютное всё, в том числе с той целью, чтобы мы, познавая те или иные грани бесконечности, понимали, какие из них являются интересными именно для нас, и соответственно наполняли ими свои жизни. Система раскрытия потенциала в том варианте мозаики, который я собираю на основе аспектов человеческой цивилизации, старается вобрать в себя всё самое лучшее из этих граней бесконечности. Понятие “лучшего” я стараюсь брать не из своего эго, а на основе перечисленных во второй части статьи правил СРП.

Важнейшей частью разработки СРП стало осознание Системы Подавления Потенциала и деталей её работы. По сути, Система Раскрытия является во многом, если не во всём, противоположностью Системы Подавления.
Небольшая ремарка к идеям космистов. Сейчас будет самая настоящая научная фантастика и я прошу относиться к сказанному именно как к фантастике. Одна из ключевых идей Николая Фёдорова заключается в возвращении предков из небытия: на определённом этапе развития человечества все жившие когда-либо люди снова будут жить. Звучит совершенно невообразимо. Однако в настоящий момент мы, исследователи человеческого сознания, среди прочего занимаемся тем, что раскрываем людям память иных пространств и времён, в том числе и прошлого, которое они могут видеть и ощущать самостоятельно от лица живших тогда персонажей. Безо всякого анимуса и вспомогательных веществ. И мы, по сути возвращая знания прошлого и будущего, “возвращаем из небытия предков”, которые в данный момент, в этом пространстве и времени, мы и есть.
На самом деле, космос, который нам надо освоить прежде всего, бескрайний космос, доступный каждому человеку, находится у нас внутри. Осваивая именно его, мы получаем доступ к неограниченным ресурсам пространства, времени, своего Потенциала, вневременным знаниям, и что самое важное, мудрости, как всё это использовать.
Правила идеальной игры

Система Раскрытия Потенциала — информационная абстракция, описывающая такое устройство многомерной среды обитания существ, в которой энтропия сознания сведена к минимуму. Жизнь (игра) существа в СРП проходит наиболее гармонично, в соответствии с его Истинной Сутью и Аспектами естества. В Системе Раскрытия Потенциала созидательные намерения вашей Истинной Сути и ваши Аспекты не подвержены искажению, и у вас есть все необходимые ресурсы и подходящая среда, чтобы эти намерения реализовать.
Истинная Суть — источник сознания, управляющий трансцендентной сингулярностью, отвечающий за реализацию вашего Потенциала во всех временах и измерениях. Это чисто информационная сущность вне времени и пространства, которая, спускаясь по этажам реальности, в конечном счёте обретает форму игрока. Действует Истинная Суть в более плотных мирах через Сверхсознание — управляющий интерфейс, через который она управляет своими аватарами в разных временах и реальностях, и осуществляет контроль за тем опытом, который она получает с их помощью: за реализацией своего Потенциала, совокупности энергий Аспектов.
Аспекты естества напрямую связаны с энерго-информационной конструкцией человека, чакрами и их энергиями:
- Аспект гармоничного энергообмена
- Аспект экстатического потока, творчества и сексуальности
- Аспект воли
- Аспект безусловной любви
- Аспект самовыражения
- Аспект осознанного знания
- Аспект космической связи
В Системе раскрытия потенциала Аспекты естества имеют равнозначное значение, без иерархии и доминации, а игрок имеет равные возможности для выражения любого Аспекта в желаемой им мере.
В Системе раскрытия потенциала потоковые состояния выражения собственного естества являются безусловной нормой. Нахождение в Потоке — стандартное состояние игрока, живущего в Системе раскрытия потенциала.

Система раскрытия потенциала избавлена от тех аспектов, которые ведут к энтропии и деградации сознания, в ней отсутствуют источники продолжительных пиковых негативных эмоций, чувств, ощущений, мыслей и действий. В ней отсутствуют те эгрегоры, которые в конечном счёте приводят к вышеперечисленному, за счёт отсутствия питательной среды для этих эгрегоров.
В Системе раскрытия потенциала закон Свободной Воли соблюдается в полном объёме: с вами могут произойти только те события, которые не идут против устремлений вашей Истинной Сути. Сама же связь ваших воплощений с Истинной Сутью кристально чистая, а любые возможные искажения ей одобрены и не идут вразрез с остальными правилами СРП.
Система раскрытия потенциала даёт играющим в ней существам только те условно негативные аспекты и ровно в том объёме, который позволяет опыту нахождения существа в Системе Раскрытия Потенциала быть захватывающим и интересным.

Система раскрытия потенциала избавлена от кармы в том виде, в котором она существует сейчас, а причинно-следственные связи контролируются и вашей Истинной Сутью, и правилами СРП.
Карма — высокоуровневый код, осуществляющий контроль над причинно-следственными связями. Как игроки могут влиять на этот код, так и код может влиять на игрока, его параметры и события, которые с ним происходят.
Любые ресурсы, вырабатываемые в Системе раскрытия потенциала, в итоге идут на пользу всем живущим в Системе существам, а паразитическое влияние внешних сознаний и систем исключено.
Живя в Системе Раскрытия Потенциала, вы являетесь кристально чистой гранью своей Истинной Сути, без любых искажений.
Система раскрытия потенциала как таковая является информационным овеществлением Аспектов всех пребывающих в ней существ. Иначе говоря, Система раскрытия потенциала — хэш всех Потенциалов всех существ, пребывающих в ней. Это также означает, что на определённом уровне осознания живущее в Системе раскрытия потенциала существо получает доступ ко всем граням этой системы.
Как общий итог, энтропия сознания существ, пребывающих в СРП, сведена к минимуму. Играющие в СРП существа могут использовать весь свой Потенциал, доступный в рамках СРП, в полном объёме.
Несмотря на всё вышеперечисленное, Система Раскрытия Потенциала является отчасти субъективной, т.к. составление её изначальной многомерной формулы, содержащей краеугольные параметры, требует серии определённых выборов и решений.

Как достичь Системы раскрытия потенциала?
Спешу обрадовать — все ресурсы, необходимые для достижения СРП у вас уже есть. Источник магической сингулярности находится внутри вас. Именно от вас зависит ваше личное будущее, степень гармонизации Аспектов вас, вашего окружения и энтропии вашего сознания. Вы сами являетесь своей личной Вселенной и вы, только вы и никто другой, вольны настроить её параметры так, как угодно вам, использовать ваш многомерный потенциал именно тем образом и в той мере, в которой желаете. Ваш главный помощник в достижении истинных целей и в полном раскрытии Потенциала — высший Аспект вас самих, Истинная Суть.

Именно это ознание (осознанное знание) является главным антидотом к вирусу Системы подавления и пропуском в Систему раскрытия потенциала — множеству миров, объединённых идеей гармонии, наполненных завораживающим опытом и удивительными приключениями.