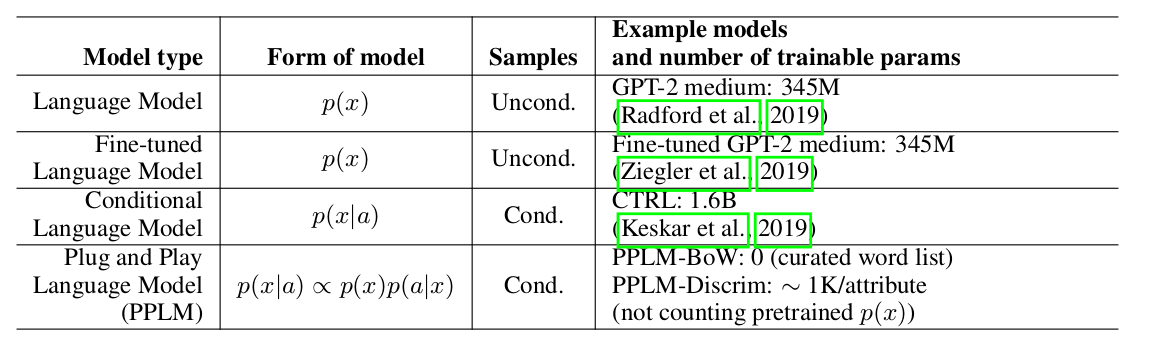
В предыдущей статье было очень подробно рассмотрено устройство аналоговой видеокамеры с целью создания собственной прошивки. Как уже было сказано, камера имеет микроконтроллер неизвестного происхождения. Он гораздо богаче, чем привычные мне AVR: у него два напряжения питания 3.3В и 1.8В, а также, у него есть функция DSP. К такому выводу я пришёл, когда задумался про реализацию алгоритма автофокусировки. Тем не менее, я не предпочитал сложные МК типа STM32 и прочие, хотя бы потому, что я с ними вообще никогда не работал. Мной однозначно было принято решение, что для реализации своей прошивки я буду применять один из МК AVR. Поэтому уже на этом этапе я начал осознавать, что с реализацией функции автофокусировки будет не очень легко справиться, а точнее – невозможно.
Мой выбор пал на МК ATmega128, так как именно он попался мне под руку. МК ATmega8 будет явно недостаточно по числу выводов, тем более что на всякий случай я решил зарезервировать целый порт МК для входа цифрового потока видео от видеопроцессора. Первым делом я прикинул, какие будут функции в собственной прошивке, в частности, функции, которые отсутствовали в оригинальной прошивке, и какими функциями придётся пренебречь.
Рассмотрим вариант алгоритма автофокусировки по анализу цифрового видеопотока. Мне удалось узнать, что данные видеопотока представляют собой чередование байтов, синхронизированные с импульсами «CK». Байты видеопотока кодируют уровни компонентов Y, Cr, Cb видеосигнала с 8-разрядной градацией (256 уровней). То есть, цифровой видеовыход с видеопроцессора данной камеры является компонентно-мультиплексированным. Информация о яркости (Y) содержится в каждом втором байте видеопотока, а информация о цветности – в два раза реже. То есть, информация о цветоразностном сигнале красного Cr содержится в каждом четвёртом байте, как и информация о цветоразностном сигнале синего. Таким образом, поток представляет такую последовательность: Cb0, Y0, Cr0, Y1, Cb2, Y2, Cr2, Y3, Cb4, Y4, Cr4, Y5,…. То есть, в то время как информация о яркости каждого пикселя приходит без пропусков, информация о цветности пикселей приходит покомпонентно по очереди. Данное прореживание обусловлено свойствами нечувствительности зрения к цвету мелких деталей и сокращением полосы цветности в видеосигнале. Эти свойства применяются в аналоговом телевидении и оцифровке видео. Представленная выше «компрессия» (цветовая субдискретизация) имеет компонентное соотношение 4:2:2.
Для работы алгоритма автофокусировки достаточно анализировать только составляющую яркости, чего также легко добиться, перехватывая видеопоток «байт через байт». Если частота CK составляет около 18 мГц, то CK/2 – 9 мГц, что, казалось бы, вполне достижимо для МК ATmega128. Импульсы синхронизации по горизонтали и вертикали дают возможность контроллеру «отсчитать» и анализировать любую область изображения. Возможно, для алгоритма автофокуса достаточно анализировать только центр растра. Очевидно, что чем лучше фокусировка, тем чётче изображение, а значит – тем шире частотная полоса видеосигнала (больше ВЧ составляющих). То есть, можно (даже нужно) применить алгоритм быстрого преобразования Фурье (БПФ) к фрагментам цифрового видеопотока и анализировать ВЧ составляющие. При этом нужно каждый раз подкручивать ШД фокуса, применяя метод «половинного деления», как математический метод оптимизации. Тем самым можно добиться оптимального результата.
Я не стал заморачиваться функцией автофокуса, посчитав, что это невозможно на МК с простой архитектурой, хотя, на всякой случай, порт для цифрового видео зарезервировал. Вместо автофокусировки я решил реализовать ряд других функций, которые отсутствовали в оригинальной прошивке. Но для этого видеокамеру придётся ограничить стационарными условиями, что и характерно для видеонаблюдения. Предполагается, что камера в дальнейшем будет способна поворачиваться в горизонтальной и вертикальной плоскости с помощью специальных механизмов, как автоматически, так и вручную. При автоматическом наведении камеры на определённый объект, сферические координаты которого будут заранее занесены в память устройства управления, также будут меняться «координаты» зума и фокуса, которые также будут заранее выбраны и занесены в память. Управление можно организовать по протоколу PELCO-D, тем более, в спецификации данного протокола есть специальная команда под это дело. Координаты зума и фокуса, естественно, будут «парные», для определённого конкретного расстояния. То есть, объект, который будет располагаться на данном расстоянии, будет в фокусе.
Прежде чем начать писать программу прошивки, нужно подумать, какая периферия МК и какие выводы будут задействованы. Затем надо подумать, как поместить и закрепить плату с собственным МК внутри камеры. И чтобы это всё было максимально удобно и ремонтопригодно. Я решил использовать плату с МК, выводы которой будут полностью разведены на левую и правую сторону. Плата будет располагаться на дне камеры, где есть немного места, и будет держаться на разъёмном соединении. При этом на самой плате будут «штырьки» разъёма, а на боковых сторонах камеры будут ответные гнёзда. Для ответных гнёзд я решил изготовить ещё две переходные платы, размером с боковую сторону камеры. Ламели данных плат выходят к верхней стороне камеры, прямо к основной плате. Предполагается, что каждая ламель будет проводком соединяться с нужной точкой основной платы камеры.
Во время разработки платы с МК у меня возникла идея дополнить видеокамеру часам (RTC), и я выделил линию I2C, разместил на плате RTC DS1307 (уже знаю, что хрень) с кварцем и батарейкой и, на всякий случай EEPROM 24AA512, что были под рукой. Также на плате у верхнего края разместились разъёмы для подключения SPI и JTAG программаторов. На оригинальной плате МК тактируется от кварца на 12 мГц. У меня – аналогично. Вообще, лучше туда поставить кварц на 11.0592 мГц для чёткой работы UART. Расстояния между «гребёнками» разъёмных соединений я предварительно тщательно рассчитал. Питать МК я решил от пятивольтовой «Кренки», что будет прикручена на каркас под основной платой (он заодно будет служить теплоотводом). Питание на неё будет браться от входного напряжения 12В сразу после предохранителя FB801, как показано на рисунке.
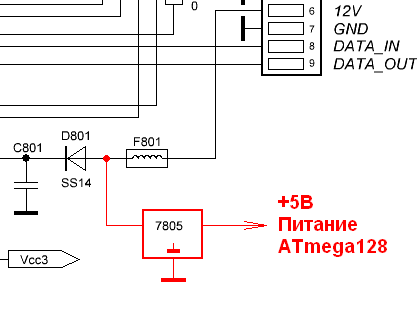
Рис. 1. Организация питания микроконтроллера.
Во время рисования плат в «SprintLayout» я прикидывал назначение каждого вывода МК, который выводится «наружу» на разъём. В результате получился вот такой рисунок.
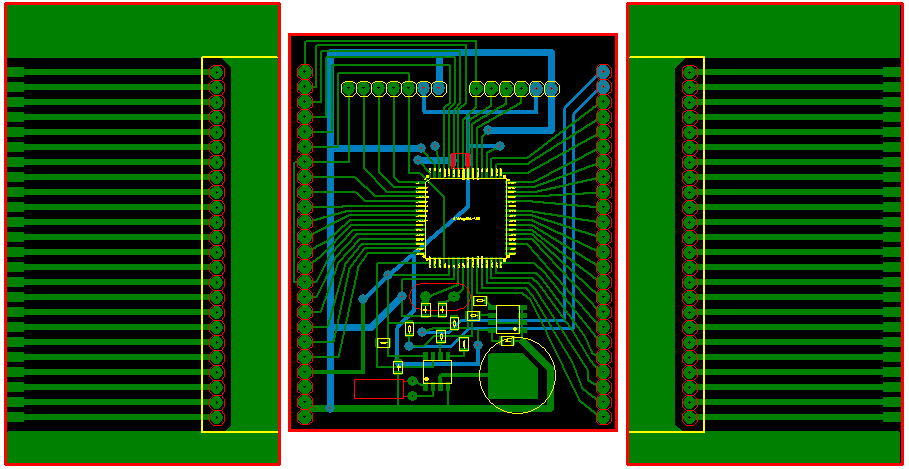
Рис. 2. Эскизы дополнительных печатных плат.
Говоря по правде, боковые платы (по краям) я нарисовал на этапе написания этой статьи. А на самом деле я их делал с помощью резака. Получился не самый удачный вариант. Да и сама плата с МК была изготовлена кривовато. Боковые вспомогательные платы я кое-как прикрутил к боковым сторонам каркаса камеры, припаяв флюсом гайки к медной поверхности текстолита. Дело в том, что места по бокам очень мало, и крышка камеры практически «натягивается» впритык.
На рисунках ниже приводится схема распределения выводов МК, а также их назначение.

Рис. 3. Назначения выводов микроконтроллера.
Следует прокомментировать множество моментов.
Для SPI программатора (STK200+) вывод «PEN» оказался ненужным. Активация происходит по «RESET», как обычно. Но вместо «MISO» и «MOSI» у МК выделен отдельный интерфейс (PDI/PDO), а линия «CLK» совмещена.
В качестве опорного напряжения для АЦП я выбрал те же 5В, от чего и питается сам МК. Пробовал завести отдельно 3.3В (как на оригинальной схеме), но при этом были свои подводные камни. А для того, чтобы перейти на опорное напряжение 5В, нужно немножко изменить схему, как показано на рисунке.
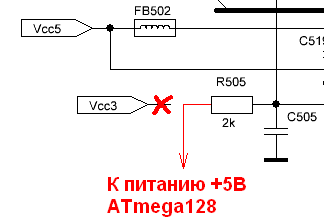
Рис. 4. Перевод кнопок на опорное напряжение 5В.
То есть, нужно отпаять одну сторону резистора R505 со стороны питания 3.3В, и вместо этого подать на него 5В от линии питания МК.
Из выводов МК, которые используются только внутри спроектированной платы, задействовано только три. На вход PB7 приходит сигнал импульсов 1 Гц с RTC для обновления времени. Выводы PD0 и PD1 отведены под шину I2C. Она будет реализовываться программно с помощью библиотеки CVAVR «i2c.h», несмотря на то, что к этим выводам привязан аппаратный i2c (TWI) интерфейс.
Вывод «RESET» МК выведен наружу, но сброс МК будет происходить самостоятельно без внешней цепочки сброса.
Подразумевалось, что синхроимпульсы HD и VD будут приходить на МК по портам внешнего прерывания для точности отсчёта поля видеоизображения. Однако, исключая функцию автофокусировки, в них уже нет потребности. На соседние порты внешних прерываний приходят сигналы с концевиков зума и фокуса.
Для цифрового видеопотока зарезервирован порт «A» МК. Порт «C» полностью отведён под ШД.
Вывод PD4 используется для коммутации TX/RX RS-485. В оригинальной схеме никакой коммутации не было: 2-ая и 3-я ноги микросхемы MAX485 сидели на «земле». Оригинальный МК умел только принимать данные для управления камерой по PELCO-D. Я же задумал сделать небольшую модернизацию. Идея была такова. В случае если видеокамера будет висеть высоко и в закрытом кожухе, будет просто невозможно оперативно обновить прошивку. А такая потребность обязательно возникнет: исключение различных багов и улучшение функционала станет на первое время регулярной практикой. Поэтому я придумал реализовать для МК загрузчик, и уже с помощью него удалённо обновлять прошивку по RS-485. А в таком случае двухсторонний обмен очень даже желателен. Про загрузчик будет отдельная часть данной статьи. А для того, чтобы подключить MAX485 (2 и 3 ноги) к данному выводу МК, нужно внести небольшое изменение в первую и вторую плату. Эти платы соединены шлейфом, на разъёмах которого имеется неиспользуемый контакт «IRL» управления подсветкой. На второй (основной) плате нужно отпаять резистор R520 и припаять вместо него на сторону разъёма провод, который пойдёт через переходную плату к МК ATmega128 на соответствующий вывод. А на первой плате нужно отпаять и отогнуть вверх 2 и 3 ножки U202, спаять их вместе и проводком от них дотянуть до свободного вывода 1 разъёма J302. Данные операции по изменению схемы показаны на рисунке.
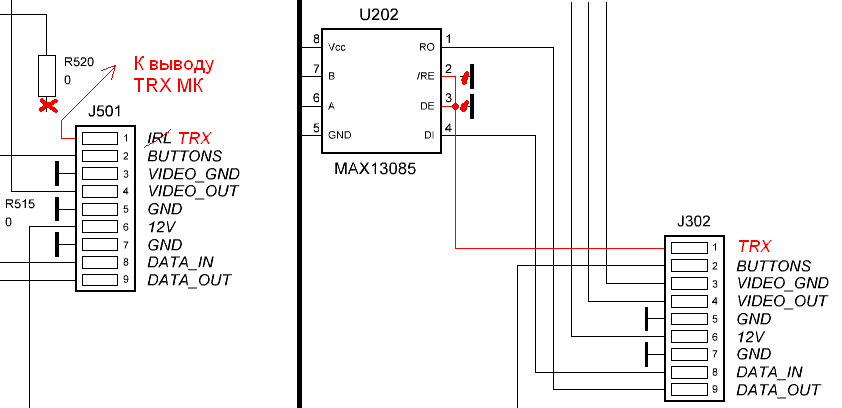
Рис. 5. Организация линии TRX для управления TX/RX MAX485.
На борту ATmega128 имеется два UART интерфейса. В данном случае приходится задействовать второй интерфейс (выводы 27, 28), так как первый интерфейс по выводам (выводы 2, 3) совмещён с интерфейсом для SPI программатора.
На плате задействованы почти все выводы МК. Незадействованными оказались выводы порта «G». Кстати, можно было реализовать часы программно на базе МК. Он предусматривает спящий экономичный режим с применением батарейки для отсчёта времени при отключенном основном питании. Имеются даже выводы для подключения отдельного НЧ кварца. Однако я не стал с этим заморачиваться, влепив DS1307.
На рисунке ниже представлено назначение каждого вывода платы с МК. Кроме этого, условно помечено, к чему и на какой стороне основной платы будет припаиваться проводок от каждого вывода. Здесь также необходимо дать несколько комментариев.
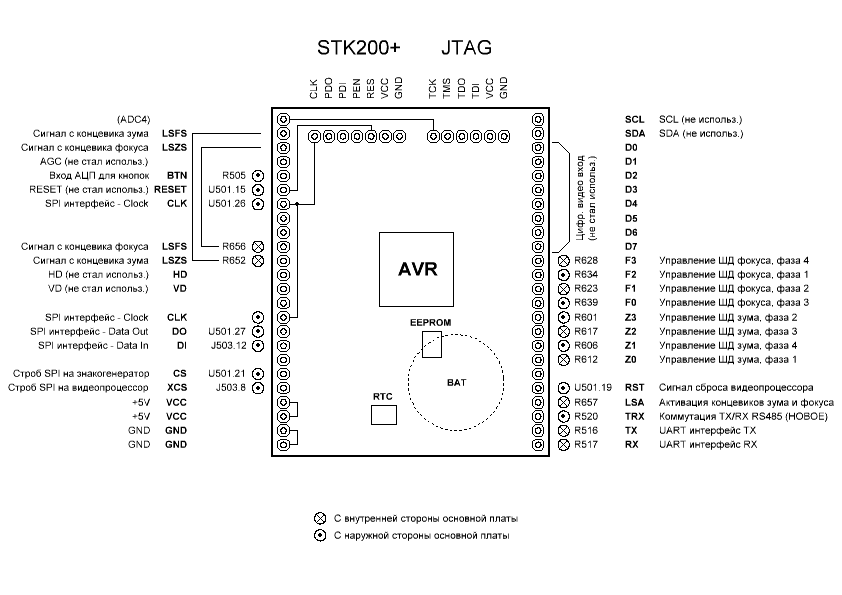
Рис. 6. Назначения выводов дополнительной платы с МК.
Сигналы с концевиков зума и фокуса поступают не только на порты прерываний, но и на входы АЦП. Дело в том, что ещё на этапе исследования ШД я заметил такую особенность. В случае если механизм зума или фокуса находится на «нуле», то выходной сигнал с концевика может принять «промежуточное» состояние. Для более чёткого улавливания таких редких случаев я решил использовать АЦП. Конечно, это не совсем грамотный подход, но тем самым я быстро выкрутился из проблемы, которая иногда возникала на этапе инициализации в моей тестовой прошивке. Тем самым я повысил устойчивость работы алгоритма.
Сигналы SDA/SCL от I2C выведены на разъём просто так, на всякий случай, и они не используются за пределами данной платы.
Названия каждого вывода для управления ШД подписаны согласно фактическому подключению. Данные подключения, забегая вперёд, окончательно корректировались на этапе отладки. Было много путаницы, но ошибки были лишь только в чередовании фаз с точностью до реверса, а не в их упорядоченности. Чередования «4-1-2-3» (для зума) и «2-3-4-1» (для фокуса) – это одно и то же, равно, как и «1-2-3-4», что и бралось за основу.
В конце статьи (чтобы не позориться) представлены две фотографии. На первой — вид видеокамеры внутри снизу с видом на дополнительную печатную плату. На второй — вид внутри сверху на основную плату видеокамеры с отпаянным штатным МК (микропроцессором, если быть точнее), кучей проволочных перемычек и прочих соплей.
Написание программы (прошивки) я производил совместно с её предварительным тестированием в программе «ISIS 7 Professional» (Proteus).
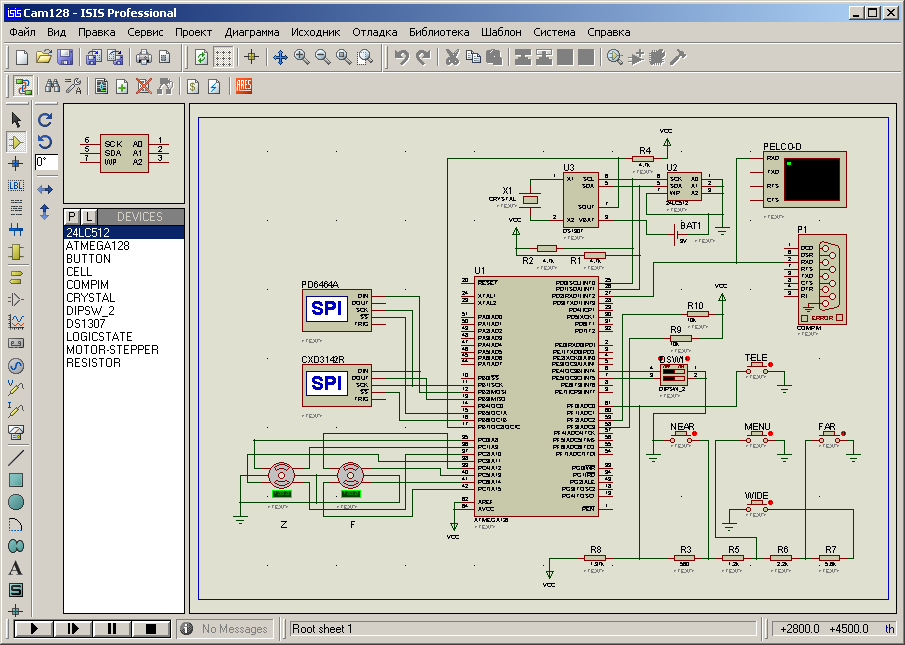
Рис. 7. Вид проекта в Proteus.
Вместо уникальных чипов знакогенератора и видеопроцессора (которых, разумеется, нет в Proteus) я поставил SPI отладчики. С помощью них удобно контролировать байты, которые отправляет МК по SPI. А вот реальная реакция на эти байты контролируется уже непосредственно на «железе». С помощью Proteus можно контролировать и отлаживать команды PELCO-D, приходящие с реального DVR. Для этого, как вариант, нужно через простейший односторонний переходник RS485->RS232 подключить DVR к COM порту компьютера.
Затем я приступил к разработке и моделированию. Очень сильно при этом помогала программа Excel.
Сначала необходимо определиться с таймерами и их конфигурацией. Один таймер – для реализации вращения ШД и реализации повторных срабатываний кнопок при их удерживании. При удерживании той или иной кнопки во время настроек через меню будет исключена работа ШД. А при удерживании одной из кнопок управления зумом или фокусом вне меню происходит вращение ШД с соответствующим временным параметром. Тем самым, какие-либо коллизии отсутствуют. Второй таймер я планировал использовать для реализации ШИМ для ШД, но со временем я решил от неё отказаться. Действительно, в моём случае, когда отсутствует автофокус, нет необходимости в ШИМ. Тем более, передаточный механизм имеет винтовую структуру, поэтому в состоянии покоя можно не «удерживать» ШД постоянным током, механизм никуда не уползёт.
Затем нужно произвести ревизию алфавита символов знакогенератора, согласно даташиту, и сопоставить его со стандартным алфавитом ASCII. Алфавит знакогенератора состоит из 128 символов, что вдвое меньше последнего. Например, символы кириллицы в знакогенераторе напрочь отсутствуют, но есть специальные символы, характерные области его применения (солнце, песочные часы, человечек, нота, телефон и т.д.). Я составил массив «smb[256]» из 256 элементов, поместив его в EEPROM МК. При этом запись smb[i]=adr обозначает, что по адресу adr в знакогенераторе находится символ с ASCII кодом i. А если символ i отсутствует в алфавите знакогенератора, то значение элемента массива ссылается на «пробел» с адресом 0x7E. То есть, почти половина элементов массива имеет значение «0x7E». Данный массив в табличном виде представлен на рисунке ниже.

Рис. 8. Массив сопоставления символов ASCII с кодами для PD6464A.
Далее, нужно продумать, как обрабатывать кнопки через АЦП. По закону Ома несложно рассчитать значения напряжений на входе АЦП при нажатии на ту или иную кнопку. После этого несложно рассчитать границы интервалов, серединами которых будут те самые значения напряжений. Всего получается шесть интервалов: пять из них соответствуют каждой кнопке и один – отсутствию нажатия (ни одна кнопка не нажата). АЦП МК на аппаратном уровне периодически анализирует значение напряжения с кнопок. Таймер для антидребезга можно реализовать на основе подсчёта тактов АЦП, что я и сделал. На этапе отладки этой части программы были свои подводные камни. Думаю, что подробности писать не стоит. Чтобы добиться чёткой работы этого функционала, пришлось долго повозиться. Функция распознавания кнопки помещена в секцию прерывания АЦП, а на её выходе – номер кнопки, флаг нажатия и флаг отпускания. Дальнейшая обработка кнопок происходит в основном цикле программы. Частота опроса кнопок (частота АЦП) получилась 12000/128=93.75 (кГц), где 128 – максимально возможный делитель.
Потом я составил массив значений регистра UBRR1 конфигурации UART в зависимости от того или иного значения бодрейта для PELCO-D, которое можно будет выбирать из списка в настройках через меню. Эти значения можно рассчитать по формуле из даташита на МК, а также можно получить с помощью автоконфигуратора «AVR Wizard».
Затем я приступил к моделированию меню. Это основной и трудоёмкий этап написания программы. Повторять меню штатной прошивки я в принципе не собирался, кроме этого, решил усложнить его до иерархической структуры (раздел в разделе). Ниже приведу описание модели и определений меню, которые я для себя составил.
Можно не читать
Меню состоит из нескольких отдельных страниц.
Каждая страница имеет имя и состоит из заголовка и списка элементов.
На каждой странице вверху отображается её заголовок.
Заголовок страницы совпадает с её именем и окружён определёнными своеобразными символами.
Корневая страница меню имеет имя и заголовок «MENU».
При нажатии на кнопку «М» вызывается корневая страница меню.
При нажатии на кнопки «ВВЕРХ» и «ВНИЗ» осуществляется выбор элемента из списка текущей страницы.
При нажатии «ВВЕРХ» на первом элементе будет выбран последний элемент.
При нажатии «ВНИЗ» на последнем элементе будет выбран первый элемент.
По умолчанию (при открытии новой страницы) выбран первый элемент, если эта страница была вызвана активацией соответствующей ей директории.
Символом выбора служит «стрелочка вправо», стоящий слева от имени элемента.
В роли элементов выступают:
— директории;
— радиокнопки;
— чекбоксы;
— числа.
Директории служат для группировки элементов, включая сами директории, в иерархическое дерево.
Имя директории окружено скобками <>.
Каждой директории соответствует определённая страница меню.
Первым элементом любой страницы всегда является директория с именем "<..>".
Активация выбранной директории осуществляется нажатием кнопки «М».
При активации директории отображается новая страница меню, соответствующая активированной директории.
Имя новой страницы меню совпадает с именем активированной (соответствующей ей) директории.
Активация директории с именем "<..>" приводит к отображению предыдущей страницы меню.
После выполнения вышесказанной операции выбранным элементом будет являться директория, которой соответствовала предыдущая страница.
Активация данной директории на корневой странице меню приводит к выходу из меню.
Радиокнопками называются элементы особого списка переключаемых параметров.
В данном списке отсутствуют иные элементы.
В данном списке может быть активирован только один элемент.
Перед именем активной радиокнопки приписывается "<•>" (точка посередине).
Перед именем неактивной радиокнопки приписывается "< >" (пробел).
Активация выбранной директории осуществляется нажатием кнопки «М».
Чекбоксами называются элементы двоичных параметров.
Данные элементы могут также содержаться наравне с директориями в пределах одной страницы.
Перед именем активного чекбокса приписывается «l*l» (крестик, окружённый буквой «l»).
Перед именем неактивного чекбокса приписывается «l l» (пробел, окружённый буквой «l»).
Активация или деактивация выбранного чекбокса осуществляется нажатием кнопки «М».
Числами называются элементы, каждый из которых представляет собой числовой параметр.
Данный элемент не может быть активирован.
Данные элементы могут также содержаться наравне с директориями в пределах одной страницы.
В состав имени данного элемента входят название параметра и его целое числовое значение.
Формат целого числового значения может быть трёх видов: «000», «00», «0».
Формат выбирается в зависимости от параметра из соображения удобства.
Название и значение параметра отделены между собой двоеточием и пробелами: ": ".
Количество пробелов — от одного до максимально допустимого (до выравнивания по правому краю) в зависимости от ситуации из соображения удобства.
Значение параметра, соответствующее выбранному числу, можно изменить нажатием кнопок «ВЛЕВО» или «ВПРАВО».
При нажатии на кнопку «ВЛЕВО» значение параметра уменьшается на 1.
При нажатии на кнопку «ВПРАВО» значение параметра увеличивается на 1.
Значения всех элементов записываются в ПЗУ при выходе из меню.
Реакция на изменение значений элементов осуществляется непосредственно при их изменении.
Таким образом, навигация по меню чем-то напоминает навигацию по файлам и папкам через «Total Commander». Код реализации данной модели меню не совсем сложный, но очень громоздкий. Имеются две ключевые переменные: номер активной страницы и номер активной позиции на странице. По обеим переменным работают две вложенные друг в друга функции «switch-case». Данная пара функций участвует в обработках нажатий кнопок «Влево», «Вправо» и «Меню». В каждом месте (для каждой кнопки, страницы и текущего пункта) прописаны те или иные определённые действия. На каждую страницу меню отведена функция, которая реализует отображение страницы на экран со всеми надписями и параметрами. Прежде чем реализовывать функции вывода страниц, я предварительно смоделировал их в Excel, что называется, «по клеточкам». Так нагляднее представляются координаты ячеек каждого символа на экранном поле, а эта информация необходима на этапе программирования. На рисунке ниже в качестве примера я привёл вид страницы 9, на которой из списка выбирается бодрейт PELCO-D. Элемент интерфейса на странице – радиокнопка. Кроме неё, первый пункт <..> – для выхода из этого раздела.
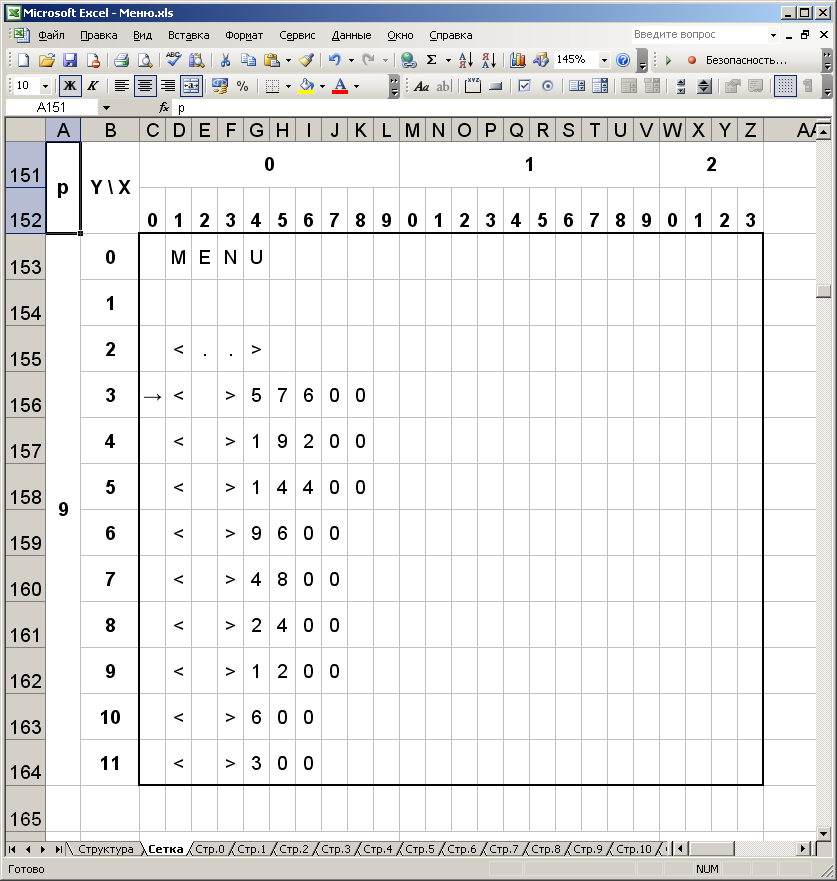
Рис. 9. Моделирование экранного меню в Excel.
Также я составил массив, который отражает количество пунктов на каждой странице. Он используется в обработке нажатия кнопок «Вверх» и «Вниз». Это сделано для сокращения кода и избегания использования функции «switch-case»
Повторные виртуальные нажатия при удерживании кнопок реализованы в теле прерывания таймера функцией «switch-case», работающей на целочисленную переменную, являющейся флагом. Значение флага уникально для каждого действия той или иной кнопки на определённой странице и определённого пункта меню. Оно присваивается флагу, как порядковый номер, только в тех местах, где нужны виртуальные нажатия. При этом внутри функции «switch-case» (в теле прерывания таймера) помещены копии функций, реализующие действия кнопок. Можно было для экономии памяти поместить «ярлыки» (ссылки) на очередные вызовы функции обработки кнопок. Так даже разумнее, но на тот момент у меня не хватило терпения подумать, как это лучше сделать, ибо желал поскорее закончить с проектом. Да и памяти в ATmega128 оказалось достаточно много.
Наконец, мной были реализованы «библиотеки» для работы с видеопроцессором, знакогенератором и RTC DS1307 с необходимыми функциями. После этого я определил адреса EEPROM МК для хранения той или иной информации. Первые 32 байта отведены для хранения информации настроек меню. Следующие 32 байта отведены под хранение текста, который можно будет выводить на экран или менять с помощью стандартной для PELCO-D команды «Write Char. To Screen». Следующие 256 байт области EEPROM отведены под алфавит (преобразование символа из ASCII в адрес для знакогенератора, о чём говорилось выше). Наконец, следующие 128 байт отведены под хранение «пресетов» (шаблонов) зума/фокуса. Эту функциональную возможность я ввёл ввиду отсутствия автофокусировки. Об этом я писал в начале статьи. Всего отведено 32 шаблона. Координаты зума или фокуса кодируются двумя байтами.
Отдельно стоит написать про реализацию управления ШД. Вращение ШД достигается путём вызова функций StepF() и StepZ() в блоке прерывания таймера. Скорость вращения определяется конфигурацией этого таймера. А выполнение вышесказанных функций реализуют продвижение фокуса или зума (соответственно) на минимальный шаг. При вращении ШД зума и фокуса контролируются их конечные положения. Положение максимума фокуса и положение минимума зума представлены в программе константами (280 и -600 соответственно). А вот положение минимума фокуса и положение максимума зума – в виде переменных F_min и Z_max (точнее, функций). Такому подходу поспособствовала непрямоугольная рабочая область со срезанным нижним правым углом. Для расчёта значений F_min и Z_max применяются кусочно-заданные функции F_min(Z) и Z_max(F). Кроме того, при вращении ШД зума в положительном направлении при Z (координата зума) >500 происходит одновременное вращение ШД фокуса в том же направлении, если последний имеет координаты <(-180). То есть, максимальное положение зума в принципе не ограничивается текущим положением фокуса, а ограничивается числом 600. Просто-напросто происходит вращение двух ШД одновременно при достижении соответствующей угловой границы пятиугольной области, и движение на этом этапе происходит вдоль «стороны среза» (если интерпретировать графически). С точки зрения механики это эквивалентно описанному в предыдущей статье процессу, когда при отсутствии ШД и при перемещении узлов зума и фокуса вручную, узел зума а конце траектории «тянет за собой» узел фокуса. Ввиду того, что координата зума доминирует над координатой фокуса (именно поэтому я рассматриваю зависимость F(Z), а не наоборот), я не стал реализовывать аналогичную процедуру «прокрутки» зума в функции Step_F().
В оригинальной прошивке скорости смены зума и фокуса имели фиксированные значения. Это не всегда удобно. В своей прошивке я предусмотрел четыре значения скоростей зума и фокуса (независимо), которые можно будет выбирать как через меню, так и с помощью отведённой под эту функцию команды PELCO-D. Эти четыре значения заранее подбираются на этапе отладки исходя из соображения удобства, затем заносятся в прошивку.
Функция инициализации ШД init_MR() необходима для привязки механики зума и фокуса к системе координат. Она выполняется один раз при каждом включении видеокамеры. Алгоритм её работы примерно следующий. Первым делом предполагается, что зум или фокус находятся в нулевой точке, и происходит попытка поймать дребезг сигнала с концевиков функциями внешнего прерывания. Сразу отмечу, что, если зум или фокус находятся «в нуле» (на границе перегораживания оптического концевика), то сигнал на выходе концевика имеет «промежуточное» состояние между логическими «0» и «1». Такие случаи очень маловероятны, но исключать их нельзя. При этом функция прерывания не интерпретирует такой сигнал, как дребезг. Именно для этого я пришёл к использованию АЦП МК, заводя на два его свободных канала сигналы с концевиков зума и фокуса. И так, первым делом происходит «оцифровка» сигналов с концевиков с 8-битной точностью. Это осуществляется с помощью однократного аналогово-цифрового преобразования. Стоит помнить, что опорное напряжение в нашем случае составляет 5В, а уровень логической «1» с концевика – 3.3В. Для логического «0» значение АЦП будет нулевым, а для «1» – 3.3/5*255=168. Если значение сигнала с того или иного концевика попало в диапазон, скажем, от 2 до 165 (берётся нечёткий интервал), то это означает, что соответствующий узел уже находится «в нуле», и процедуру инициализации для этого узла можно прекратить. В противном случае по логическому значению сигнала концевика («0» или «1») нужно определить, в какой части (половине) находится узел. От этого будет зависеть направление вращения ШД. Так или иначе, ШД нужно вращать в таком направлении, чтобы соответствующий узел передвигался в сторону «нуля» (концевика). Таким образом, запускается вращение ШД с одновременным подсчётом числа шагов до тех пор, пока не будет достигнут концевик. Как только соответствующий концевик будет достигнут, что определит функция внешнего прерывания по перепаду логического уровня, произойдёт реверс вращения ШД. Он совершит вращение в обратную сторону на то же число шагов, тем самым, возвратившись в исходное положение. Значение числа шагов для каждого ШД с соответствующим знаком будет скопировано в соответствующие переменные перед выходом из функции инициализации. Описанная выше процедура происходит независимо для фокуса и зума в пределах одной функции (не по очереди). Скорость вращения ШД на этапе инициализации определена отдельной константой и соответствует максимальной скорости для уверенного корректного вращения ШД.
Рассмотрим пример, когда перед включением питания камеры зум находился в отрицательной области, а фокус – в положительной. На рисунке схематически показана траектория перемещения точки (Z;F) при процедуре инициализации ШД.
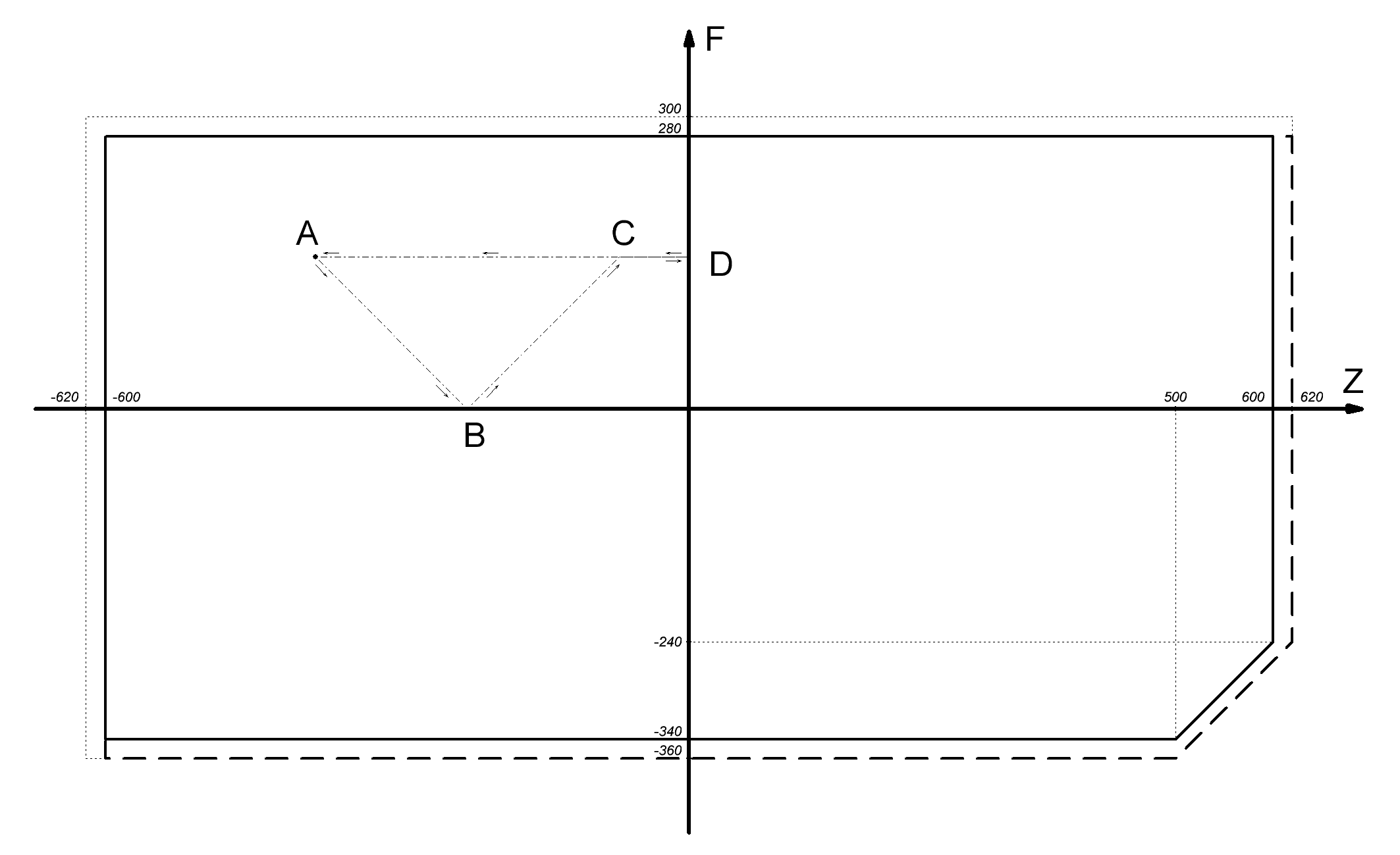
Рис. 10. Процесс инициализации зума и фокуса.
Точка A – начальное положение зума и фокуса. Движение обоих узлов происходит в сторону «нуля» с одинаковой скоростью (скоростью инициализации). В точке B происходит достижение «нуля» узлом фокуса, так как он находился ближе к нулю, чем зум. Затем происходит реверс фокуса. В точке C фокус завершает процесс инициализации, возвратившись на исходное положение. При этом зум всё ещё движется в сторону своего «нуля». В точке D он достигает свой «нуль» и возвращается на исходное положение (точка A).
Кроме функции инициализации init_MR() имеется функция goto_zf(z,f). Исходя из названия, она предназначена для перехода с одного пресета на другой, о чём я писал в начале статьи. Скорость вращения ШД при переходе такая же, как и при инициализации. Процесс перехода по зуму и фокусу осуществляется одновременно. То есть, если требуется из точки (z1;f1) перейти в точку (z2;f2), запускается одновременное вращение двух ШД. Если, например, |f2-f1|<|z2-z1|, то ШД фокуса остановится раньше. Это продемонстрировано на рисунке ниже.
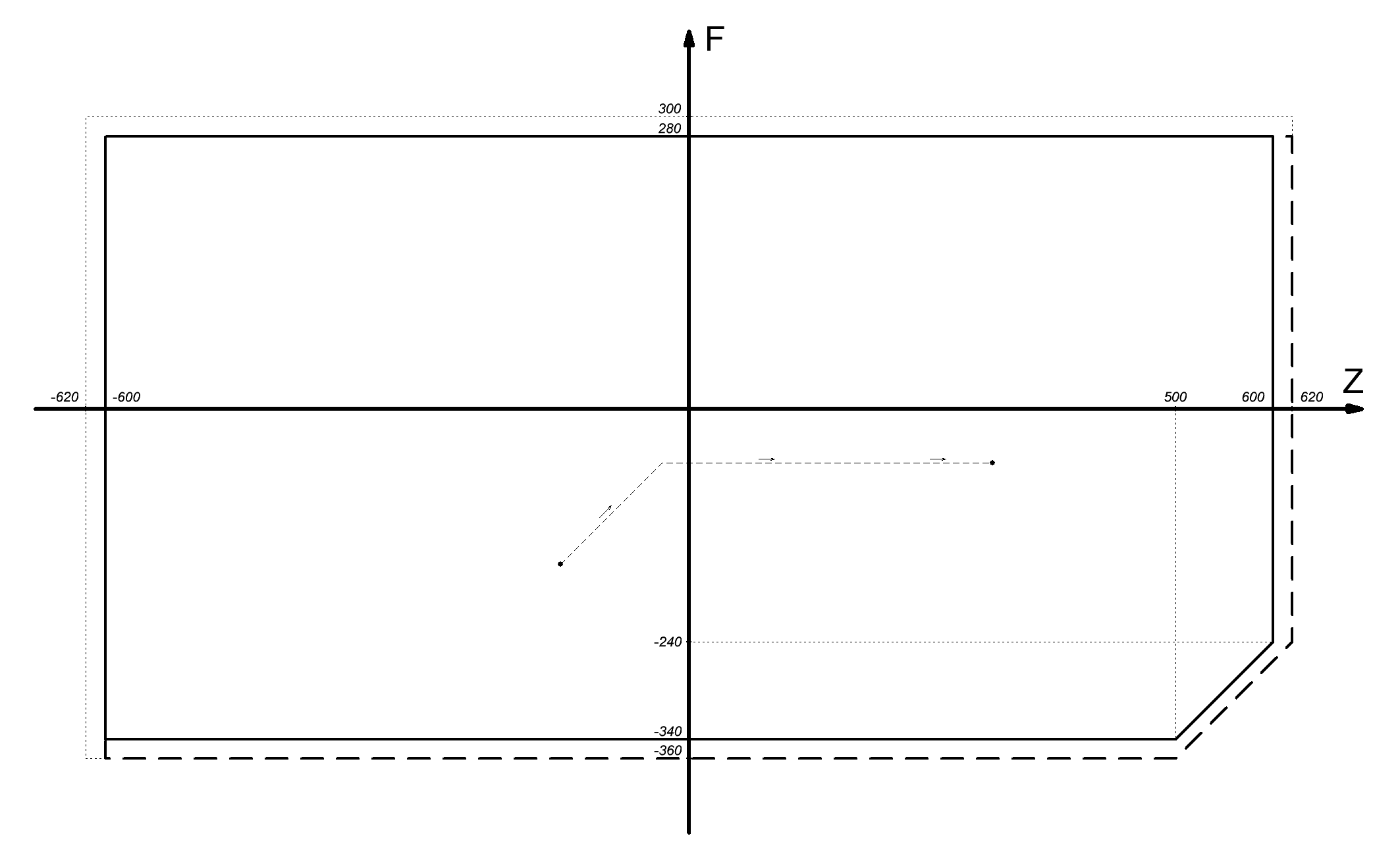
Рис. 11. Процесс смены зума и фокуса при выборе пресета.
На протяжении всего времени работы ШД при прохождении концевика нулевой метки происходит обнуление соответствующей координаты. И это несмотря на то, что теоретически этого можно не делать. Однако на практике всё же существует погрешность в 1-2 шага ШД.
Стоит дополнить, что, в отличие от оригинальной прошивки, в своём случае при управлении зумом и фокусом (как с кнопок, так и через PELCO-D) я предусмотрел возможность пошагового передвижения. Это работает следующим образом. При нажатии на какую-либо одну из 4-х кнопок управления зумом или фокусом соответствующий ШД проворачивается на один шаг, тем самым происходит минимальное передвижение узла зума или фокуса. Если при этом не отпускать кнопку, то обычное вращение ШД начнётся спустя небольшой промежуток времени. Данная задержка подбирается опытным путём заранее. Эта особенность аналогична виртуальным повторным нажатиям при удержании кнопки. Благодаря этой особенности устраняется проблема «залипания» кнопки при управлении зумом или фокусом по PELCO-D удалённым устройством через плохое Интернет соединение. Точнее, появляется возможность как грубой, так и точной подстройки зума или фокуса.
Интерпретатор PELCO-D команд выполнен по той же аналогии, что и в устройстве для коммутации нагрузок через PTZ. Этому простому устройству я ранее посвятил отдельную небольшую статью на Хабре. В отличие от оригинальной прошивки, команды управления зумом и фокусом полностью ссылаются на нажатия соответствующих кнопок. То есть, имеется возможность с помощью кнопок зума и фокуса PELCO-D «лазить» по меню. А для того, чтобы удалённо через PELCO-D вызывать меню, точнее, нажимать кнопку «MENU», я сопоставил с ней кнопку открытия диафрагмы, ибо данная функция не применяется в данной модели камеры. Таким образом, действуют пять базовых команд PELCO-D для нажатия, а также пять базовых команд – для отпускания кнопок. Кроме этого, как я уже писал вскользь на протяжении всей статьи, обрабатываются дополнительные команды: «Set Preset», «Clear Preset», «Go To Preset», «Write Char. To Screen», «Clear Screen», «Set Zoom Speed», «Set Focus Speed».
Дата и время с RTC выводятся в нижнем левом углу изображения по аналогии со старыми VHS камерами, если данная опция активирована в меню. Кроме того, в меню можно выбрать формат вывода, что я также заранее предусмотрел. Также на экран рядом с датой и временем имеется возможность выводить день недели. Кроме часов, в качестве дополнительной информации на экран выводятся текущие координаты зума и фокуса. Эту опция нужна, прежде всего, на этапе отладки.
Расскажу про функции меню, которое я реализовал. Со временем, по необходимости, меню будет подвергнуто редакции: какие-то функции можно будет убрать, а какие-то добавить. Структура меню, которую я нарисовал в SPlan, с видами страниц представлена на рисунке ниже. Красные стрелки – вход в раздел. Синие стрелки – выход из раздела. Я не стал рисовать синие стрелки на каждую страницу меню, нарисовал всего две для примера.
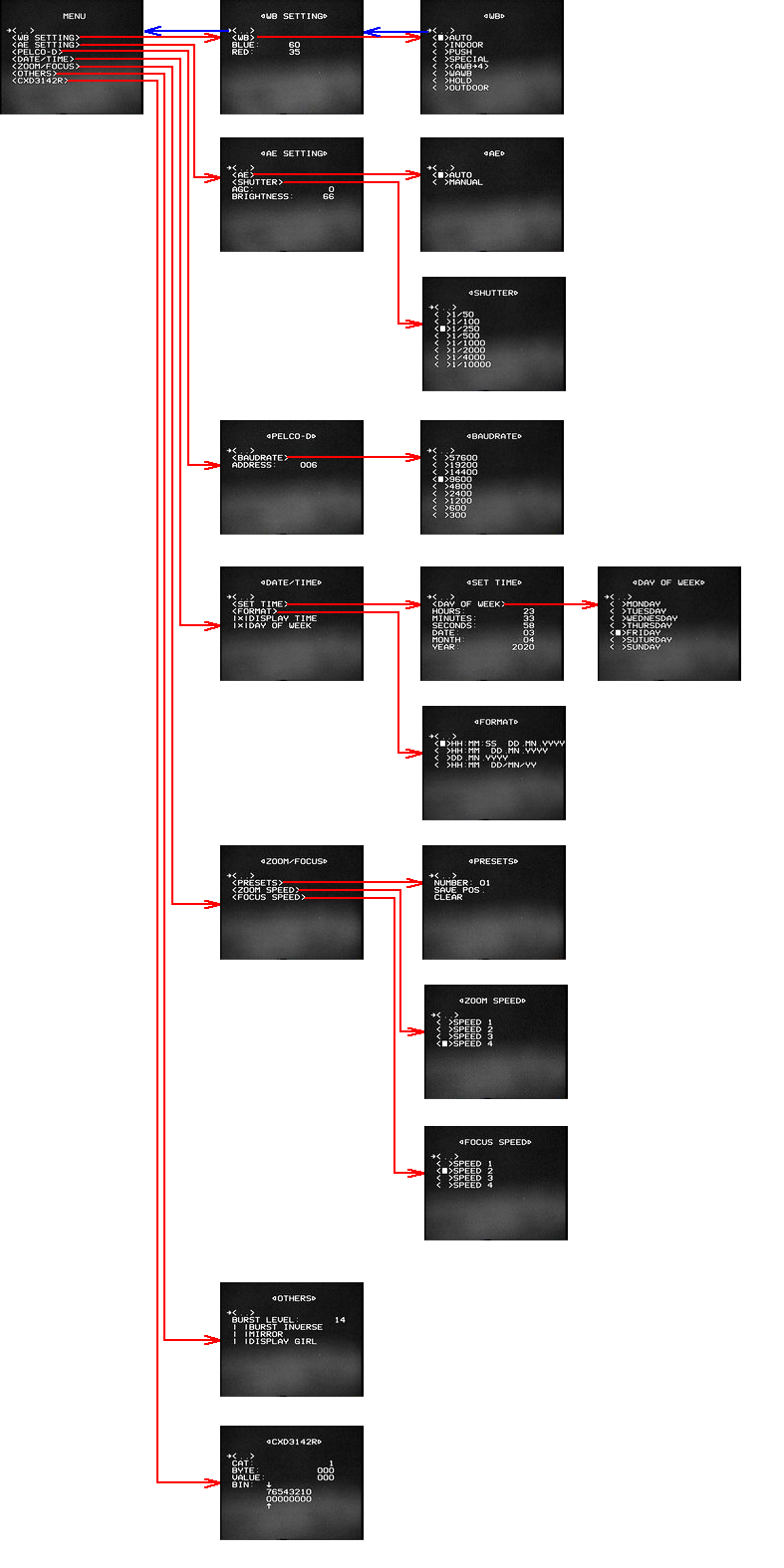
Рис. 12. Структура экранного меню.
Некоторые разделы моего меню немножко похожи на разделы оригинала. Прежде всего, это первые два раздела: баланс белого и экспозиция. В третьем разделе можно указать адрес камеры PELCO-D и выбрать скорость обмена данными (бодрейт) из списка. Четвёртый раздел посвящён дате и времени. Можно настроить дату, время, день недели, выбрать один из четырёх форматов отображения, выбрать способ отображения. Пятый раздел – работа с пресетами (шаблонами) зума и фокуса, где можно вызвать его по номеру, а также стереть или перезаписать. Также в данном разделе меню можно выбрать один из четырёх скоростей смены фокуса или зума. Пятый раздел позволяет редактировать параметры видеопроцессора, находящиеся в байте 9 категории 3. Это уровень и инверсия составляющей «burst» видеосигнала, и зеркальное отображение видео. Последний раздел меню предназначен для отладки. С помощью него можно записывать в видеопроцессор любое значение любого байта в любой категории. Значение можно задавать как в десятичном, так и в бинарном виде.
Теперь скажу несколько слов по поводу загрузчика. Как я уже писал, загрузчик нужен для удалённой перепрошивки видеокамеры по RS-485. Изначально я думал полностью реализовать загрузчик самостоятельно. Однако в целях экономии времени я решил обойтись одним из уже реализованных готовых загрузчиков, которые можно найти в Интернете. Тем более, я ни разу ими не пользовался, имея представление о них только на теоретическом уровне. Одним из важных критериев выбора загрузчика – поддержка RS-485. Обычно AVR загрузчики работают по UART RS-232. А загрузчик с поддержкой RS-485 отличается лишь тем, что на стороне МК выделяется дополнительный вывод для коммутации приёмо-передатчика RS-485 (например, MAX485) во время передачи данных от МК к ПК. При прошивке МК загрузчик передаёт компьютеру информацию об успешной или неуспешной записи. Первый загрузчик, который я нашёл, позволяет записывать не только FLASH память МК с прошивкой, но и EEPROM. Кроме записи, можно ещё и считывать данные. Но данный проект с исходным кодом на ассемблере был довольно запутанный и я в нём не разбирался. Тем более, основной акцент данного загрузчика был направлен на возможность прошивать множество устройств по отдельности, не отключая их от сети RS-485, обращаясь к каждому устройству по заранее зашитому в него адресу. В таких функциональных особенностях я не нуждаюсь, так как применяю иную топологию сети RS-485, и есть возможность быстро переключить видеокамеру с DVR на ПК. Второй загрузчик – немецкий «Chip45». Исходный код находится не в свободном доступе, его можно купить у автора. Вместо этого имеется несколько сотен HEX-файлов под разные AVR МК, разные интерфейсы UART (если их несколько, как в моём случае), RS-485 или RS-232 на выбор. Короче, на все случаи жизни. При этом автор отмечает, что в случае с RS-485 вывод для коммутации TX/RX фиксированный и соответствует пину XCK UART интерфейса контроллера, который практически в UART не применяется. В моём случае на 30-ый вывод XCK второго UART интерфейса МК Atmega128 приходится PORTD.5 и используется для активации концевиков зума и фокуса. В принципе, эта функция не нужна, ибо, как показали исследования, концевики всегда активны, о чём я уже писал. Да и при необходимости можно перебросить эту функцию на любой другой свободный вывод МК. Но, всё равно, данный загрузчик меня также не впечатлил, тем более, мне попался более интересный загрузчик под названием «AVR Universal Bootloader» китайской разработки. Как и Chip45, он умеет только записывать и только во FLASH память МК. Но у него большое количество возможностей, и поэтому я твёрдо решил остановиться на нём. Поставляется он как проект AVR Studio с исходным кодом на языке Си. В связи с тем, что я работаю в CodeVisionAVR, мне пришлось установить AVR Studio совместно с WinAVR. Для того чтобы получить HEX-файл прошивки загрузчика, нужно откомпилировать проект, сделав предварительные изменения в исходном коде под собственную конфигурацию устройства и собственные нужны. Компиляция проекта заключается в запуске bat-файла (батника), в котором прописаны команды компиляции. Таким образом, проект в AVR Studio открывать не требуется. Изменения в исходном коде можно делать как вручную (на уровне программиста), так и с помощью конфигуратора. В роли последнего выступает дополнительное окно утилиты, работающей с загрузчиком, которая также прилагается. В конфигураторе можно указать вывод МК для коммутации TX/RX RS-485, вывод МК для контрольного мигающего светодиода, вывод МК для входа в загрузчик, способ входа в загрузчик, название и частоту МК и т.д., всё не перечислить. Кроме того, в роли утилиты для загрузки пользовательской программы в МК, т.е., для работы с загрузчиком, может выступать стандартная известная программа «HyperTerminal» Для загрузки прошивки она использует протокол «Xmodem». А для того, чтобы через текстовый терминал было удобно и наглядно работать с загрузчиком, в конфигураторе предусмотрена специальная функция «Verbose mode». Но я, несмотря на привлекательность гипертерминала, решил пользоваться утилитой, прилагающейся к загрузчику. Дело в том, что с активированной в конфигураторе удобной функцией Verbose, работая через терминал, я столкнулся со следующей ситуацией. Иногда приходилось, когда трафик данных в линии «сталкивался» (оба устройства в режиме TX), вследствие чего MAX485 в видеокамере сильно нагревалась и выходила из строя, точнее, не полностью, а только секция RX (передача данных по RS-485 в камеру). Из-за этого я отказался от HyperTerminal. И есть ещё одно неудобство. HyperTerminal не работает с текстовыми HEX-файлами и принимает только бинарный файл. Поэтому пришлось бы применять дополнительное преобразование из hex в bin. После того, как HEX-файл загрузчика был мной сформирован, я его зашил в МК с помощью программы «PonyProg» и обычного SPI программатора. В результате, загрузчик работает следующим образом. При включении видеокамеры сразу же активируется загрузчик. Он ждёт подключения от утилиты одну секунду, затем начинает работать основная прошивка. Если подключение успешно установлено, то начинается процесс перепрошивки. При этом другой конец линии RS-485 нужно заранее отключить от DVR и подключить к ПК через переходник RS485<->RS232 или RS485<->USB. Кстати, насчёт переходников. Возник вопрос, как сделать такой переходник самостоятельно, ибо покупные переходники дороговато стоят. Ковыряясь в Интернете, нашёл простую схему переходника RS485<->RS232. Она приведена на рисунке ниже. Он в основном состоит из известных микросхем MAX232 и MAX485, а TX/RX коммутация последней производится сигналом с 3-го вывода разъёма COM-порта компьютера через цепочку со стабилитроном. То есть, MAX485 коммутируется самим трафиком данных, который передаёт ПК. Всё просто и гениально.

Рис. 13. Схема переходника RS-232 <-> RS-485.
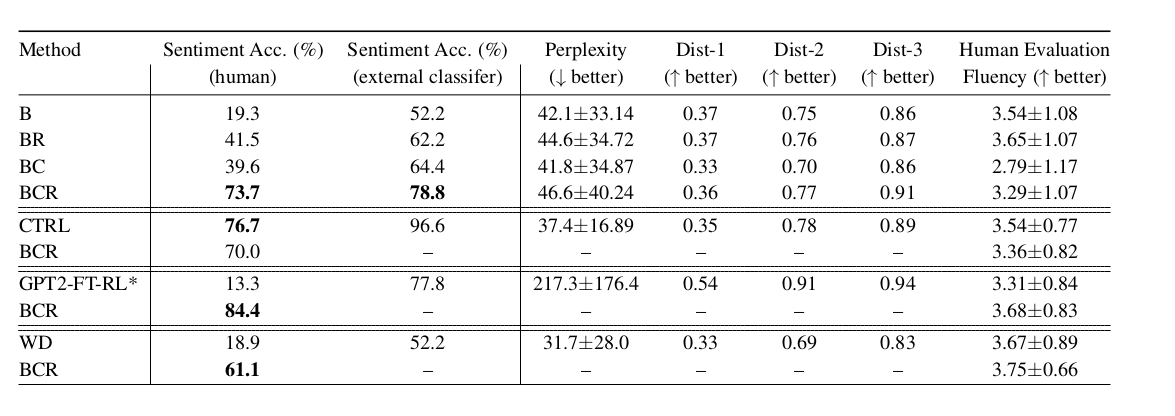
После освоения загрузчика, на досуге, я решил исследовать оптику видеокамеры. Точнее говоря, мне стало интересно, какие комбинации значений зума и фокуса будут давать сфокусированные изображения на различных дистанциях от объектива до предмета. Напомню, что область всевозможных взаимных значений зума и фокуса описывается пятиугольной областью (почти прямоугольной). Для примера возьмём расстояние от объектива до предмета 10 см. Аргумент (по оси абсцисс) зум имеет диапазон значений от -600 до 600. Нужно на каждом значении зума подобрать значение фокуса, при котором предмет перед объективом на видеоизображении будет в фокусе. Затем нужно составить таблицу. Разумеется, нет смысла перебирать все 1200 значений зума, достаточно взять несколько десятков значений с определённым равным шагом. В качестве такого шага я выбрал значение 50. На каждом значении зума с данным шагом (-600, -550, -500, …) я подобрал значение фокуса, и результаты измерений зафиксировал. Аналогичную процедуру я проделал с другими расстояниями от объектива до предмета: 50 см, 1 м, 10м, 100 м. В результате получилось семейство кривых, которые я отобразил в Excel.
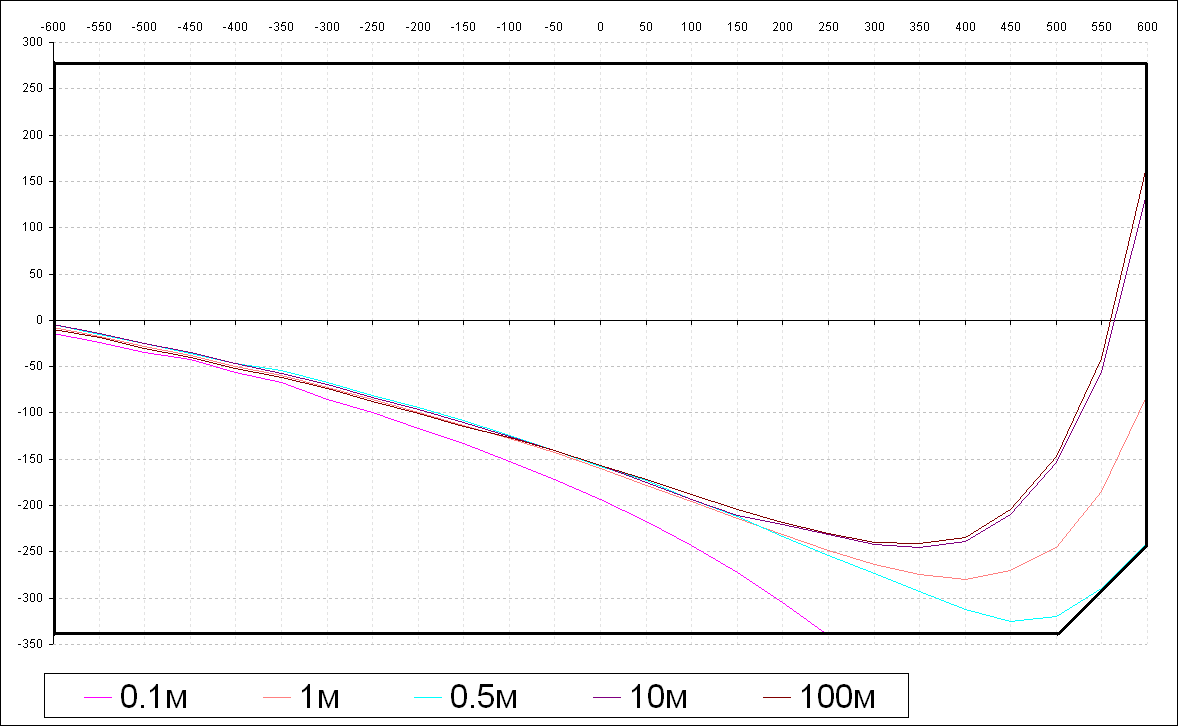
Рис. 14. Кривые Z-F для сфокуссированных изображений.
Глядя на графики, хочется дать множество комментариев. На минимальном зуме значения фокуса чуть меньше «середины» (нуля) практически для любой дистанции. Розовая кривая для дистанции 10 см заканчивается на значении зума около 250, которому соответствует минимальное значение фокуса. Данная кривая имеет убывающий характер и выпукла вверх. Красная кривая для дистанции в 1 м имеет совершенно другую форму. Во-первых, она не монотонна, а во-вторых, что касается свойства выпуклости, – есть точка перегиба. Аналогичный характер имеют кривые для дистанций 10 м и 100 м. Последние, кстати говоря, практически совпадают, о чём я уже заранее догадывался. Поэтому измеряемые дистанции 10 и 100 метров я, разумеется, брал приблизительно. Что качается кривой голубого цвета для полуметрового расстояния – изначально я не собирался делать на нём измерения. Данное расстояние я подобрал приблизительно исходя из того принципа, чтобы как можно ближе фрагментом соответствующей кривой приблизиться к угловой границе области (срезу). Так и получилось: данная граница практически касается фрагменту кривой. В общем, стоит отметить, что верхняя половина области (положительные значения фокуса) практически не используется. Исключение – на большой дистанции от предмета до объектива и на самом большом зуме. И ещё, для практически всех дистанций (кроме самой близкой, менее полуметра), на малом зуме (150 и менее) значения фокусов практически одинаковые. Вообще говоря, все изложенные факты измерений должны иметь теоретическую трактовку, опираясь на законы оптики. Но на текущий момент времени я не имею представления об устройствах объективов подобного рода. Максимум, с чем я сталкивался в области оптики – построение простейшего телескопа-рефрактора из двух линз. А в случае с данной видеокамерой – я не разбирался с устройством механики оптики. На выходе не доступны только два подвижных узла: узел фокуса (отвечающий за фокус) и узел зума. А сколько всего линз внутри – не знаю. Предполагаю, что две, которые, как раз, связаны с этими подвижными узлами. Стоит также заметить, что при подстройке фокуса также визуально немножко изменяется зум, даже если соответствующий ему узел фиксирован.
В завершении статьи перейдём к практическому тестированию видеокамеры. Я решил не делать множество стоп-кадров, а сразу выложить видео целиком. Записывал через устройство видео захвата, звук писал отдельно на аудио рекордер. Исходное разрешение – 720 на 576. После загрузки видео на ютуб его качество заметно изменилось.
При включении камеры первым делом происходит инициализация шаговых двигателей зума и фокуса на фоне видеоизображения. Данное изображение чёрно-белое и без АРУ, так как процедура инициализации видеопроцессора ещё не прошла. Внизу слева на месте отображения текущей даты и времени будет отображаться дата и время компиляции текущей прошивки камеры. В исходном коде прошивки я создал соответствующие переменные, которые расположены по фиксированным адресам в HEX-коде. Предполагается, что на этапе компиляции, точнее после неё, автоматически будет выполняться программа, которая возьмёт значения переменных из системного времени и вставит их в HEX-файл по нужным адресам. Кроме этого там ещё нужно пересчитать контрольные суммы. Возможно, есть способ проще. В примере на видео эти переменные равны нулю, так как данную функцию я пока не реализовывал.
После инициализации ШД происходит инициализация видеопроцессора и тут же высвечивается приветствие на фоне видеоизображения. При регулировке зума и фокуса внизу справа высвечиваются их координаты. На видео я демонстрирую использование функции сохранения и вызова шаблонов (пресетов) зума и фокуса на различных участках изображения. При очистке пресета соответствующие переменные приобретают значения 0xFFFF, что соответствует значению -1. Данная функция, в принципе, лишняя, её можно исключить.
В последнем разделе меню, который служит для отладки, я демонстрирую запись байта 9 категории 3. Функции, соответствующие этому байту, есть в предыдущем разделе меню, о них я уже неоднократно писал. В связи с тем, что текущее состояние байта из видеопроцессора не считывается, я вручную задаю ему значение «48», как одно из приемлемых. После этого я изменяю отдельные биты данного байта, показывая тем самым функции «Mirror» и «Inverse Burst».
При регулировке уровня «Burst» в предпоследнем разделе меню можно заметить небольшой баг прошивки, который легко устранить. Из других недочётов – иногда при обновлении времени происходят пропуски символов. Думаю, это связано с «кривым» монтажом электроники внутри видеокамеры.
В целом при эксплуатации камеры обнаружились мелкие неудобства, связанные с навигацией по меню. Поэтому, вполне возможно, со временем будет произведена необходимая доработка.
Да, чуть не забыл. Как обещал, привожу две фотографии, во что превратилась начинка видеокамеры после доработки.

Рис. 15. Обновлённый вид видеокамеры внутри снизу.

Рис. 16. Обновлённый вид видеокамеры внутри сверху.