
В данной статье рассматривается краткое описание того, как функционируют активные модели внешнего вида и связанного с этим математического аппарата, а также приводится пример их реализации.
Общие сведения об активных моделях внешнего вида
На протяжении последних лет математический аппарат активных моделей внешнего вида активно развивался и на данный момент можно выделить 2 подхода к построению подобных моделей: классический (тот, что был предложен Кутесом изначально) и на основе так называемой обратной композиции (предложен Мэтьюсом и Бейкером в 2003 году [2]).
Рассмотрим сначала общие части двух подходов. В активных моделях внешнего вида моделируются два типа параметров: параметры, связанные с формой (параметры формы), и параметры, связанные со статистической моделью изображения или текстурой (параметры внешнего вида). Перед использованием модель должна быть обучена на множестве заранее размеченных изображений. Разметка изображений производится вручную или в полуавтоматическом режиме, когда с помощью какого-либо алгоритма находятся приближенные расположения меток, а затем они уточняются экспертом. Каждая метка имеет свой номер и определяет характерную точку, которую должна будет находить модель во время адаптации к новому изображению. Пример подобной разметки (база лиц XM2VTS) показан на рисунке ниже.
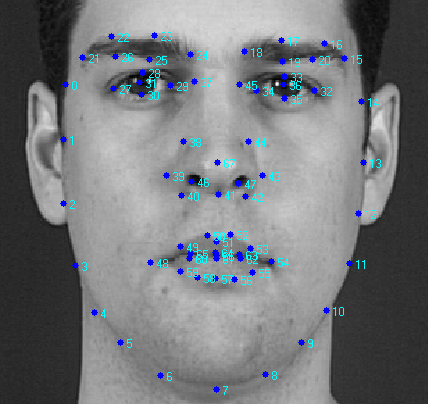
В представленном примере на изображении отмечены 68 меток, образующих форму модели активного внешнего вида. Эта форма обозначает внешний контур лица, контуры рта, глаз, носа, бровей. Данный характер разметки позволяет в дальнейшем определить различные параметры лица по его изображению, которые могут быть использованы для дальнейшей обработки другими алгоритмами. Например, это могут быть алгоритмы идентификации личности, аудио-визуального распознавания речи, определения эмоционального состояния субъекта.
Процедура обучения активных моделей внешнего вида начинается с нормализации положения всех форм для того, чтобы компенсировать различия в масштабе, наклоне и смещении. Для этого используется так называемый обобщенный Прокрустов анализ. Здесь мы не будем приводить его подробное описание, а интересующийся читатель может ознакомиться с соответствующей статьей в Википедии. Вот как выглядит множество меток до и после нормализации (согласно [3]).
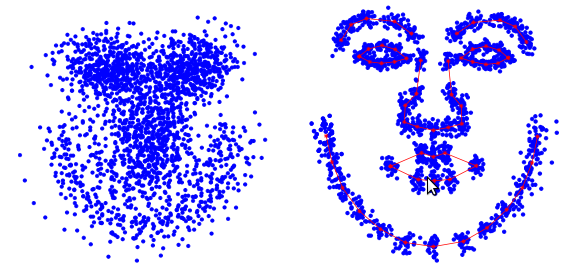
После того, как все формы нормированы, из составляющих их точек формируется матрица 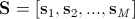 , где
, где 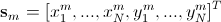 . После выделения главных компонент указанной матрицы получаем следующее выражение для синтезированной формы:
. После выделения главных компонент указанной матрицы получаем следующее выражение для синтезированной формы:
 .
.
Здесь 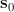 — форма, усредненная по всем реализациям обучающей выборки (базовая форма),
— форма, усредненная по всем реализациям обучающей выборки (базовая форма), 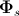 — матрица главных векторов,
— матрица главных векторов,  — параметры формы. Приведенное выражение означает, что форма
— параметры формы. Приведенное выражение означает, что форма  может быть выражена как сумма базовой формы и линейной комбинации собственных форм, содержащихся в матрице . Изменяя вектор параметров мы можем получать разного рода деформации формы для подгонки ее под реальное изображение. Ниже показан пример такой формы [7]. Синими и красными стрелками показаны направления главных компонент.
может быть выражена как сумма базовой формы и линейной комбинации собственных форм, содержащихся в матрице . Изменяя вектор параметров мы можем получать разного рода деформации формы для подгонки ее под реальное изображение. Ниже показан пример такой формы [7]. Синими и красными стрелками показаны направления главных компонент.

Следует отметить, что различают модели активного внешнего вида с жесткой и не жесткой деформацией. Модели с жесткой деформацией могут подвергаться только аффинным преобразованиям (поворот, сдвиг, масштабирование), в то время как модели с не жесткой деформацией могут подвергаться и другим видам деформаций. На практике используется комбинация обоих видов деформаций. В этом случае к параметрам формы добавляются еще и параметры расположения (угол поворота, масштаб, смещение или коэффициенты аффинного преобразования).
Процедура обучения для компонентов внешнего вида выполняется после того, как вычислены компоненты формы (базовая форма и матрица главных компонент). Процесс обучения здесь состоит из трех шагов. На первом шаге выполняется извлечение из обучающих изображений текстур, которые наилучшим образом соответствуют базовой форме. Для этого выполняется триангуляция меток базовой формы и формы, состоящей из меток обучающего изображения. Затем с помощью кусочной интерполяции выполняется отображение полученных в результате триангуляции регионов обучающего изображения в соответствующие регионы формируемой текстуры. В качестве примера на рисунке ниже показан результат такого преобразования для одного из изображений базы IMM.

После того, как все текстуры сформированы, на втором шаге производится их фотометрическая нормализация для того, чтобы компенсировать различные условия освещения. В настоящее время разработано большое число методов, позволяющих это сделать. Самый простой из них — вычитание среднего значения и нормализация дисперсии яркости пикселей.
Наконец на третьем шаге, из текстур формируется матрица, такая что, каждый ее столбец содержит значения пикселей соответствующей текстуры (аналогично матрице 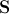 ). Стоит отметить, что используемые для обучения текстуры могут быть как одноканальными (градации серого), так и многоканальными (например, пространство цветов RGB или другое). В случае многоканальных текстур векторы пикселов формируются отдельно по каждому из каналов, а потом выполняется их конкатенация. После нахождения главных компонент матрицы текстур получаем выражение для синтезированной текстуры:
). Стоит отметить, что используемые для обучения текстуры могут быть как одноканальными (градации серого), так и многоканальными (например, пространство цветов RGB или другое). В случае многоканальных текстур векторы пикселов формируются отдельно по каждому из каналов, а потом выполняется их конкатенация. После нахождения главных компонент матрицы текстур получаем выражение для синтезированной текстуры:
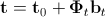 .
.
Здесь 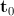 — базовая текстура, полученная усреднением по всем текстурам обучающей выборки,
— базовая текстура, полученная усреднением по всем текстурам обучающей выборки, 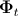 — матрица собственных текстур,
— матрица собственных текстур, 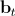 — вектор параметров активного внешнего вида. Ниже показан пример синтезированной текстуры [7].
— вектор параметров активного внешнего вида. Ниже показан пример синтезированной текстуры [7].

На практике для уменьшения эффекта переобучения модели в матрицах главных компонент оставляют только 95-98% наиболее значимых векторов. Причем это число может быть различным для главных компонент формы и главных компонент внешнего вида. Уточненные цифры могут быть выбраны уже в процессе экспериментальных исследований или при тестировании модели с помощью процедуры кросс-валидации.
На этом общая часть у разных видов активных моделей внешнего вида заканчивается и теперь мы рассмотрим различия двух подходов.
Классическая активная модель внешнего вида
В модели этого типа нам необходимо также вычислить вектор комбинированных параметров, который задается следующей формулой:
 .
.
Здесь 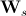 — диагональная матрица весовых значений, которая позволяет уравновесить вклад расстояний между пикселами и интенсивностей пикселов. По каждому элементу обучающей выборки (паре текстура-форма) вычисляется свой вектор
— диагональная матрица весовых значений, которая позволяет уравновесить вклад расстояний между пикселами и интенсивностей пикселов. По каждому элементу обучающей выборки (паре текстура-форма) вычисляется свой вектор 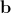 . Затем полученный набор векторов объединяется в матрицу и находятся ее главные компоненты. В этом случае синтезированный вектор объединенных параметров формы и текстуры определяется следующим выражением:
. Затем полученный набор векторов объединяется в матрицу и находятся ее главные компоненты. В этом случае синтезированный вектор объединенных параметров формы и текстуры определяется следующим выражением:
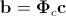 .
.
Здесь  — матрица главных компонент объединенных параметров,
— матрица главных компонент объединенных параметров,  — вектор комбинированных параметров внешнего вида. Отсюда мы можем получить новые выражения для синтезированной формы и текстуры:
— вектор комбинированных параметров внешнего вида. Отсюда мы можем получить новые выражения для синтезированной формы и текстуры:
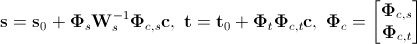 .
.
На практике матрица также подвергается удалению шумовых компонент для снижения эффекта переобучения и уменьшения количества производимых вычислений.
После того, как вычислены параметры формы, внешнего вида и комбинированные параметры нам необходимо найти так называемую матрицу предсказания 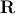 , которая в смысле минимума среднеквадратичной ошибки удовлетворяла бы следующему линейному уравнению:
, которая в смысле минимума среднеквадратичной ошибки удовлетворяла бы следующему линейному уравнению:
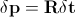 .
.
Здесь 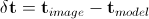 , а
, а 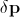 — возмущение вектора положения и комбинированных параметров внешнего вида. Разработаны различные методы для решения указанного выше уравнения. Подробное их рассмотрение проведено в работах [3 — 6].
— возмущение вектора положения и комбинированных параметров внешнего вида. Разработаны различные методы для решения указанного выше уравнения. Подробное их рассмотрение проведено в работах [3 — 6].
Адаптация рассматриваемой активной модели внешнего вида к анализируемому изображению происходит, в общем случае, следующим образом.
- На основе начального приближения вычисляются все параметры модели и аффинные преобразования формы;
- Вычисляется вектор ошибки
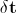 . Извлечение текстуры из анализируемого изображения происходит с помощью его кусочной деформации;
. Извлечение текстуры из анализируемого изображения происходит с помощью его кусочной деформации; - Вычисляется вектор возмущений ;
- Проводится обновление вектора комбинированных параметров и аффинных преобразований путем суммирования текущих их значений с соответствующими компонентами вектора возмущений;
- Проводится обновление формы и текстуры;
- Переходим к выполнению пункта 2 до тех пор, пока не достигнем сходимости.
Были предложены различные модификации и улучшения этого алгоритма, но его общая структура и суть остаются прежними.
Приведенный выше алгоритм достаточно эффективен, однако он имеет достаточно серьезный недостаток, который ограничивает его применение в приложениях реального времени: он медленно сходится и требует большого объема вычислений. Для преодоления указанных недостатках в [2, 7] был предложен новый тип активных моделей внешнего вида о которых пойдет речь в следующем разделе.
Активная модель внешнего вида обратной композиции
Мэтьюс и Бейкер предложили эффективный в вычислительном плане алгоритм адаптации активной модели внешнего вида, который зависит только от параметров формы (так называемая «project-out» модель). За счет этого удалось существенно повысить его быстродействие. Алгоритм адаптации, в основу которого был положен подход Лукаса-Канаде, использует метод Ньютона для поиска минимума функции ошибки.
Алгоритм Лукаса-Канаде пытается найти локально наилучшее соответствие в смысле минимум среднеквадратичной ошибки между шаблоном и реальным изображением. При этом шаблон подвергается деформации (аффинной и/или кусочной) задаваемой вектором параметров 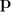 , которая отображает его пикселы на пикселы реального изображения.
, которая отображает его пикселы на пикселы реального изображения.
Непосредственное нахождение параметров является задачей нелинейной оптимизации. Для ее решения линейными методами алгоритм Лукаса-Канаде предполагает, что начальное значение параметров деформации известно и затем итеративно находит приращения параметров , обновляя на каждой итерации вектор .
Активная модель внешнего вида обратной композиции использует аналогичный подход для обновления собственных параметров во время процесса адаптации за исключением того, что деформации подвергается не базовая текстура , а анализируемое изображение.
На этапе обучения активной модели внешнего вида обратной композиции вычисляются так называемые изображения наискорейшего спуска и их гессиан. Адаптация модели происходит сходным с классической моделью внешнего вида образом за исключением того, что в данном случае происходит только обновление параметров формы и (опционально) параметров расположения.
Стоит отметить, что Мэтьюс и Бейкер предложили большое количество возможных вариаций, обладающих различными свойствами разработанных ими моделей. Заинтересованный читатель может обратиться к работам [2, 7 — 9] для более подробного ознакомления.
Программная реализация
Для практической реализации и исследования указанных выше алгоритмов обучения и адаптации активных моделей внешнего вида автором была разработана специализированная программная библиотека под названием AAMToolbox. Библиотека распространяется под лицензией GPLv3 и предназначена для использования исключительно в некоммерческих и исследовательских целях. Исходные коды доступны по данной ссылке.
Для сборки AAMToolbox требуется библиотеки OpenCV 2.4, boost 1.42 или выше, IDE NetBeans 6.9. На данный момент поддерживаются ОС Ubuntu Linux версий 10.04 и 10.10. Работоспособность и собираемость на других платформах не проверялась.
В AAMToolbox реализованы алгоритмы работы как с классической активной моделью внешнего вида, так и с активной моделью внешнего вида обратной композиции. Доступ к обоим типам алгоритмов осуществляется через единый интерфейс, который обеспечивает тренировку модели на заданной обучающей выборке, сохранение и восстановление из файла обученной модели, адаптацию модели к реальному изображению. Поддерживаются как цветные изображения (в трехканальном цвете), так и изображения в градациях серого.
Для того, чтобы обучить модель необходимо вначале подготовить обучающую выборку. Выборка должна состоять из двух типов файлов. Первый тип — это собственно изображения, по которым будет обучаться модель. Файлы второго типа являются текстовыми файлами разметки и содержат метки форм обозначенных на соответствующих изображениях обучающей выборки. Ниже приведен фрагмент такого файла.
1 228 307 2 232 327 3 239 350 5 270 392 6 294 406 7 314 410 8 343 403 9 361 388 10 372 370 11 382 349 12 388 331 13 393 312 14 374 243 Здесь первый столбец — номер метки, второй столбец X-координата метки, третий столбец Y-координата метки. Каждому изображению должен соответствовать свой файл разметки.
Код обучения активной модели внешнего вида довольно прост.
#include "aam/AAMEstimator.h" void trainAAM() { // Создаем объект оценивателя параметров модели aam::AAMEstimator estimator; // Здесь будет хранится список файлов, которые // составят обучающую выборку // aam::ModelPathType является алиасом для пары // std::pair<std::string, std::string>, первый компонент // которой должен содержать путь к файлу меток, а // второй - путь к обучающему изображению. std::vector<aam::ModelPathType> modelPaths; // Заполняем каким-либо образом наш список файлов ...................................................... // // Теперь устанавливаем параметры обучения в опциях aam::TrainOptions options; // Порог отсечения шумовых главных компонент. Принимает значения от 0 до 1. options.setPCACutThreshold(0.95); // Выбираем, по каким изображениям производить обучение: // true - градации серого, false - цветные трехканальные options.setGrayScale(true); // Проводить ли обучение в несколько параллельных потоков. // Актуально при выборе классической активной модели // внешнего вида. options.setMultithreading(true); // Выбираем алгоритм обучения модели: // aam::algorithm::conventional - классическая модель, // aam::algorithm::inverseComposition - модель обратной композиции options.setAAMAlgorithm(aam::algorithm::conventional); // Устанавливаем результат триангуляции. Необходимо не во всех случаях. // Если не устанавливать, то в процессе обучения триангуляция будет // проведена автоматически. В противном случае переменная triangles должна // иметь тип std::vector<cv::Vec3i> и содержать список номеров вершин // треугольников (нумерация вершин начинается с 0. options.setTriangles(triangles); // Устанавливаем количество уровней гауссовой пирамиды изображений. // Ее использование предполагает обучение модели на нескольких масштабах, // что позволяет снизить риск попадания в локальный минимум. options.setScales(4); estimator.setTrainOptions(options); // Собственно процедура обучения estimator.train(modelPaths); // Сохраняем обученную модель в файл estimator.save("data/aam_test.xml"); } В результате выполнения представленного фрагмента кода позволяет обучить активную модель внешнего вида заданного типа и сохранить ее в файл. Стоит отметить, что во время обучения все данные, в том числе и изображения, находятся в оперативной памяти, поэтому при загрузке большого числа изображений (несколько сотен) следует позаботиться о том, чтобы было доступно достаточное ее количество (2 — 3 Гб). В качестве примера кода, который проводит процедуру обучения для разных типов активных моделей внешнего вида можно посмотреть юнит-тест «AAM Estimator test» проекта библиотеки. Если его запустить на выполнение, то он обучит и сохранит в соответствующие файлы модели каждого из поддерживаемых типов в варианте для цветных изображений и градаций серого (всего 4 различных модели).
Код адаптации активной модели внешнего вида к изображению будет выглядеть следующим образом:
#include "aam/AAMEstimator.h" void aplyAAM() { // Загружаем модель. // Ее тип и алгоритм работы будет определен автоматически aam::AAMEstimator estimator; estimator.load("<путь_к_файлу_модели>"); // Загружаем картинку cv::Mat im = cv::imread("<путь_к_файлу_изображения>"); // Определяем положение лица на изображении std::vector<cv::Rect> faces; cv::cvtColor(im, im, CV_BGR2GRAY); cascadeFace.detectMultiScale(im, faces, 1.1, 2, 0 |CV_HAAR_FIND_BIGGEST_OBJECT //|CV_HAAR_DO_ROUGH_SEARCH |CV_HAAR_SCALE_IMAGE , cv::Size(30, 30) ); if (faces.empty()) { return; } cv::Rect r = faces[0]; aam::Point2D startPoint(r.x + r.width * 0.5 + 20, r.y + r.height * 0.5 + 40); // Массив, куда будут помещены координаты точек найденной формы aam::Vertices2DList foundPoints; // Производим адаптацию модели. Последний параметр verbose определяет // выводить диагностическую информацию процесса адаптации или нет. estimator.estimateAAM(im, startPoint, foundPoints, true); } Для того, чтобы посмотреть демонстрацию работы алгоритмов адаптации активных моделей внешнего вида, необходимо запустить юнит-тесты «Aply model test» и «Aply model IC test», которые проводят адаптацию к изображению моделей поддерживаемых типов. На рисунке ниже показан пример одного из получаемых результатов.

Указанные тесты наглядно демонстрируют различие в скорости сходимости классической активной модели внешнего вида и активной модели внешнего вида обратной композиции. Однако к недостатку последней можно отнести расходимость алгоритма ее адаптации в некоторых случаях. Для его устранения предложено несколько подходов, но в рассматриваемой библиотеке AAMToolbox (по крайней мере на данный момент) они не реализованы.
Заключение
В статье были кратко рассмотрены активные модели внешнего вида и связанные с ними основные понятия и математический аппарат. Также рассмотрена разработанная автором программная библиотека AAMToolbox, реализующая изложенные в статье алгоритмы. Приведены примеры ее использования.
За кадром остались трехмерные модели активного внешнего вида и связанные с ними алгоритмы. Возможно они будут рассмотрены в следующих статьях.
Список литературы
- T. Cootes, G. Edwards, and C. Taylor. Active appearance models. In Proceedings of the European Conference on Computer Vision, volume 2, pages 484–498, 1998.
- S. Baker, R. Gross, and I. Matthews. Lucas-Kanade 20 years on: A unifying framework: Part 3. Technical Report CMU-RI-TR-03-35, Carnegie Mellon University Robotics Institute, 2003.
- M. B. Stegmann Analysis and Segmentation of Face Images using Point Annotations and Linear Subspace Techniques. Technical report IMM-REP-2002-22, Informatics and Mathematical Modelling, Technical University of Denmark, 2002
- T. F. Cootes, G. J. Edwards, and C. J. Taylor. Active appearance models. IEEE Trans. on Pattern Recognition and Machine Intelligence, 23(6):681–685, 2001.
- T. F. Cootes and C. J. Taylor. Statistical models of appearance for medical image analysis and computer vision. In Proc. SPIE Medical Imaging 2001, volume 1, pages 236–248. SPIE, 2001.
- T.F. Cootes and C.J. Taylor. Constrained active appearance models. Computer Vision, 2001. ICCV 2001. Proceedings. Eighth IEEE International Conference on, 1:748–754 vol.1, 2001.
- Iain Matthews and Simon Baker Active Appearance Models Revisited. International Journal of Computer Vision, Vol. 60, No. 2, November, 2004, pp. 135 — 164.
- S. Baker, R. Gross, and I. Matthews. Lucas-Kanade 20 years on: A unifying framework: Part 1. Technical Report CMU-RI-TR-02-16, Carnegie Mellon University Robotics Institute, 2002.
- S. Baker, R. Gross, and I. Matthews. Lucas-Kanade 20 years on: A unifying framework: Part 2. Technical Report CMU-RI-TR-03-01, Carnegie Mellon University Robotics Institute, 2003.
ссылка на оригинал статьи http://habrahabr.ru/post/155759/
Добавить комментарий