 Многие разработчики нередко встают перед дилеммой – получать данные только из базы или же держать кэш для ряда таблиц. В основном, это некоторые справочники, которые содержат мало записей и постоянно нужны под рукой. Вопрос этот холиварный и затрагиваться в данной статье не будет.
Многие разработчики нередко встают перед дилеммой – получать данные только из базы или же держать кэш для ряда таблиц. В основном, это некоторые справочники, которые содержат мало записей и постоянно нужны под рукой. Вопрос этот холиварный и затрагиваться в данной статье не будет.
Такая же проблема встала и передо мной при проектировании высоконагруженного сервера системы мониторинга транспорта на .NET. В итоге, было принято решение, что кэшам – быть. Кэши словарей стали храниться в обёртках над ConcurrentDictionary. Этот вариант был взят без особых исследований, поскольку является стандартным средством .NET для потокобезопасных словарей. Теперь настало время проверить производительность данного решения. Об этом, собственно, статья. Также в конце статьи будет небольшое исследование того, как устроен внутри ConcurrentDictionary.
Постановка задачи
Требуется потокобезопасная коллекция пар ключ-значение, которая умеет следующее:
- Запрос объекта по ключу-идентификатору – естественно, используется чаще всего;
- Изменение, удаление и добавление новых элементов – редко, но нужно обеспечить потокобезопасность;
- Работа со значениями — запрос всех значений, поиск по свойствам объекта-значения.
Пункт 3 нетипичен для коллекций-словарей и потому является главным тормозом данной конструкции. Однако, если используется кэширование справочных таблиц, подобные ситуации неизбежны (например, банально потребуется вывести весь словарь в админке для редактирования).
Попробуем рассмотреть разные системы, в которых будет использоваться кэш. Отличаться они будут частотой операций со словарём. Формализуем типы этих операций:
- GET — запрос объекта по ключу,
- ADD — добавление нового объекта по новому ключу (если такой ключ уже есть — перезаписываем),
- UPDATE — новое значение по существующему ключу (если ключа нет — ничего не делаем)
- SEARCH — работа с итератором, в данном случае — поиск первого подходящего значения
Список участников тестирования
- ConcurrentDictionary . Это готовое решение от Microsoft со встроенной потокобезопасностью. Реализует удобные методы TryGetValue, TryAdd, TryUpdate, AddOrUpdate, TryDelete, которые позволяют удобно установить политику разрешения конфликтов. Особенности реализации будут рассмотрены в конце статьи.
- Dictionary с блокировкой через Monitor. Самое что ни на есть решение в лоб — все непотокобезопасные операции оборачиваются конструкцией lock.
- Dictionary c блокировкой через ReaderWriterLock. Оптимизация предыдущего решения — операции делятся на операции чтения и операции записи. Соответственно читать могут несколько потоков одновременно, а для записи требуется монопольный доступ.
- Dictionary с блокировкой через ReaderWriterLockSlim. По сути, то же самое, но с использованием более нового класса (добавлены настройки управления рекурсией). В контексте данной задачи вряд ли должен показать что-то отличное от ReaderWriterLock.
- Dictionary с блокировкой через OneManyResourceLocker из библиотеки PowerThreading от Wintellect — хитрая реализация ReaderWriterLock от Джефри Рихтера. Уточню, что использовалась версия с официального сайта, а не пакет NuGet — там версия другая и она мне не понравилась.
- Hashtable.Synchronized. Тоже готовое решение от Microsoft — предоставляет потокобезопасный индексатор. Неудобно использовать по причине того, что это не-generic коллекция (boxing, хуже читабельность), а также нет методов с префиксом Try (невозможно установить политику одновременного добавления/обновления).
Кратко расскажу, как именно реализованы обработчики.
- Операция GET: все участники используют потокобезопасный метод TryGetValue из интерфейса IDictionary. Для Hashtable используется индексатор с приведением типа.
- Операция ADD: для ConcurrentDictionary – AddOrUpdate, для Dictionary – блокировка на запись и добавление через индексатор, для Hashtable — добавление через индексатор без блокировки.
- Операция UPDATE: для ConcurrentDictionary – сначала TryGetValue, затем TryUpdate.
Данный метод интересен тем, что между этими двумя методами может пройти параллельное обновление (что при тестировании и проявлялось). Именно для этого случая в TryUpdate передаётся oldValue, чтобы в этом редком случае перезапись не удалась. Для Dictionary — проверяем на наличие через ContainsKey и в случае успеха ставим блокировку на запись и перезаписываем значение. Для Hashtable нет удобного TryUpdate, поэтому не стал заморачиваться с проверкой наличия ключа и, как и в случае добавления, значение перезаписывается через индексатор (для данной коллекции это не принципиально – всё равно всё было довольно плохо). - Операция SEARCH: для ConcurrentDictionary используется LINQ-овский FirstOrDefault, для остальных — блокировка на чтение и тот же FirstOrDefault.
Тестовый стенд
Для тестирования создано консольное приложение (ссылка).
- Создаётся набор обработчиков, которые умеют обрабатывать операции всех определённых типов;
- Создаётся словарь из N элементов (по умолчанию — 10 000);
- Создаётся коллекция задач разных типов в количестве M (по умолчанию — 10 000);
- Каждым обработчиком проводится параллельная обработка всех задач по сгенерированному словарю (общему для всех обработчиков);
- Опыт (пункты 2-4) проводится заданное число раз (по умолчанию — 10) и полученное время усредняется. Измерения производились на машине с Core 2 Quad 2.66Ггц и 8Гб памяти.
Значения по умолчанию достаточно маленькие, однако, если их увеличивать, принципиально ничего не меняется.
Результаты тестирования
Тестирование производилось с различными вариантами распределения по типам операций и таблица получилась слишком большой, посмотреть её целиком можно здесь (ссылка). Для наглядности приведу график времени выполнения теста в микросекундах в зависимости от процента чтения по значению от общего числа операций (операций записи при этом фиксировано 20%, остальные – чтение по ключу).
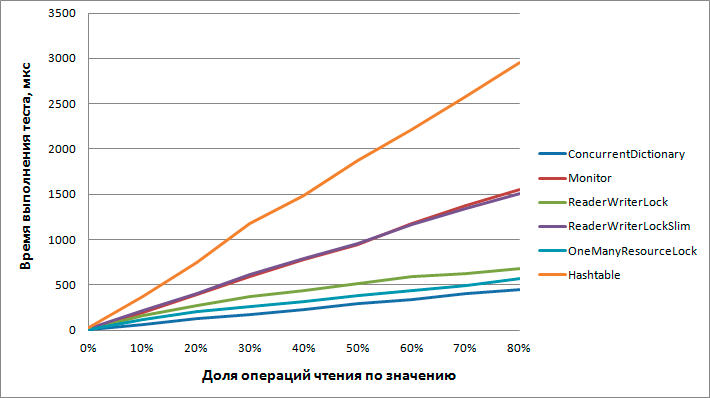
Выводы
Производительность всех участников падает линейно от количества чтений по значению не зависимо от количества операций записи.
- ConcurrentDictionary. Опыты показали, что этот инструмент лучше остальных подходит для данной задачи. Чтение по значению ощутимо бьёт по производительности, но он всё равно остаётся быстрее остальных участников.
- Dictionary + Monitor. Значительно медленнее, результаты ожидаемые.
- Dictionary + ReaderWriterLock. Оптимизация предыдущего варианта, также всё ожидаемо.
Стоит отметить, что чем больше преобладают операции записи – тем меньше разница. С определённого момента Monitor становится даже более предпочтительным за счёт меньших накладных расходов на сам процесс блокировки. - Dictionary + ReaderWriterLockSlim. Почему-то умудрился проиграть даже простому монитору. Либо расширенная функциональность (по сравнению с предыдущим вариантом) повлияла на производительность, то ли я не умею его готовить.
- Dictionary + OneManyResourceLock. Рихтер, похоже, выжал всё возможное из блокировки чтения/записи. По результатам тестов это самое быстрое использование Dictionary. Но ConcurrentDictionary всё равно быстрее.
- Hashtable. Ожидаемый провал. Возможно, я неправильно его использовал, но не думаю, что можно было получить результат сравнимый с другими участниками. Да и вообще как-то уныло работать с не-generic коллекциями.
Внутреннее устройство ConcurrentDictionary
Присмотримся к победителю поподробнее, а именно: посмотрим исходники ConcurrentDictionary.
При создании этого класса задаются 2 параметра: Capacity и ConcurrencyLevel. Первый (Capacity) является привычным для коллекций и задаёт количество элементов, которые могут быть записаны без расширения внутренних коллекций. В данном случае создаются связанные списки (m_buckets, поэтому далее будем называть их корзинами (ну не вёдрами же, да?)) в количестве Capacity, а затем элементы относительно равномерно в них добавляются. Значение по умолчанию — 31.
Второй параметр (ConсurrencyLevel) определяет количество потоков, которые могут одновременно писать в наш словарь. Реализуется это с помощью создания коллекции объектов для блокировки мониторами. Каждый такой объект блокировки отвечает за приблизительно одинаковое количество корзин. Значение по умолчанию — Environment.ProcessorCount * 4.
Таким образом, каждому объекту в словаре однозначно сопоставляется корзина, где он лежит, и объект блокировки для записи. Делается это следующим методом:
/// <summary> /// Computes the bucket and lock number for a particular key. /// </summary> private void GetBucketAndLockNo( int hashcode, out int bucketNo, out int lockNo, int bucketCount, int lockCount) { bucketNo = (hashcode & 0x7fffffff) % bucketCount; lockNo = bucketNo % lockCount; Assert(bucketNo >= 0 && bucketNo < bucketCount); Assert(lockNo >= 0 && lockNo < lockCount); } Любопытно, что даже при ConcurrencyLevel = 1 ConcurrentDictionary всё равно работает быстрее, чем обычный словарь с локом. Также стоит отметить, что класс оптимизирован под использование через итератор (что и показали тесты). В частности, при вызове метода ToArray() осуществляется блокировка по всем корзинам, а итератор используется относительно дёшево.
Для примера: лучше использовать dictionary.Select(x => x.Value).ToArray(), чем dictionary.Values.ToArray().
Статья написана ведущим разработчиком компании.
Спасибо за внимание!
ссылка на оригинал статьи http://habrahabr.ru/company/scout/blog/156125/
Добавить комментарий