Сразу писать ИИ для настоящих сёги на поле 9 на 9 я не рискнул и решил начать с упрощённой версии игры на поле 5 на 5 (такое поле часто используется новичками). Если вы прочитали полные правила игры на википедии, то нижеследующий раздел вам будет понять гораздо проще.
Правила игры
Давайте договоримся, что начиная с этого момента и далее я буду писать «сёги», но подразумевать упрощенную версию игры на поле 5 на 5.
Фигуры
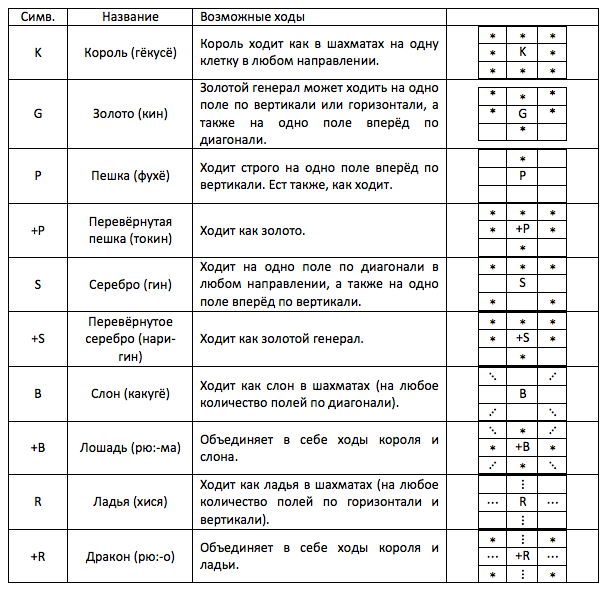
Первое с чем надо разобраться при изучении новой игры — это ходы. В сёги есть 10 различных фигур. Обозначения фигур, их названия и возможные ходы представлены в таблице ниже:
Перевороты
Наверняка вы заметили, что среди есть фигур есть «перевёрнутые дубли», которые чаще всего сильнее оригинала. Принцип усиления в сёги похож на шахматный, но, если в шахматах, превращается только пешка, и превращается она в произвольную фигуру, то в сёги переворачиваются все фигуры, кроме золота и короля. Чтобы добиться переворота необходимо начать или закончить ход на последней горизонтали противника. В общем случае переворот является произвольным: т.е. вы можете дойти ладьёй до последней горизонтали, но не перевернуть её, а следующим ходом вернуться в свой лагерь уже с переворотом (т.к. ход вы начали на последней диагонали). Естественно, пешка обязана перевернуться, если она достигла зоны переворота.
Сбросы
Если вы дочитали до этого момента, вам, возможно, кажется, что сёги — это какое-то подобие шахмат или шашек, но уверяю вас это не так. В сёги есть один нюанс, который сразу же делают эту игры на несколько порядков сложнее.
Любую съеденную у противника фигуру вы можете выставить на любое свободное поле как свою. Такое действие называется сбросом (хотя лично мне больше нравится слово «космодесант», которое впервые в данном контексте применил Андрей Васнецов).
Правда при сбросе есть несколько ограничений, но они довольно просты:
- Все фигуры сбрасываются неперевёрнутыми;
- Если вы сбрасываете фигуру в зону переворота, то перевернуться она сможет только после того, как сделает ход;
- Нельзя сбрасывать пешку на вертикаль, где уже есть твоя пешка (токин при этом пешкой не считается);
- Нельзя сбрасывать пешку на последнюю горизонталь;
- Нельзя сбрасывать пешку с матом.
Может правило сброса и кажется вам незначительным, но оно кардинальным образом меняет всю стратегию игры. Если в шахматах или шашках достаточно получить небольшое материальное преимущество, а потом постоянно идти на размены и выиграть в эндшпиле, то в сёгах размены приводят к более напряжённой позиции и усложнению просчёта.
Очерёдность ходов и начальная расстановка
Игра проходит на квадратном поле со стороной в 5 клеток. В начале игры на поле выглядит следующим образом:

По неизвестным мне причинам, в сёги первыми начинают чёрные, а белые защищаются. Чтобы не путаться с терминами, давайте договоримся, что сторона, начинающая партию называется сенте, а защищающаяся сторона готэ.
Прежде чем переходить к собственно программированию, необходимо отметить ещё одну важную вещь. В сёги нет понятия шаха, т.е. вашему королю угрожают, вы не обязаны защищаться или убегать. Вы вполне можете начать свою атаку. Правда следующим ходом скорее всего съедят вашего короля, и игра закончится.
Программирование игры
Вступление получилось довольно длинным, но поверьте, без него никак нельзя было обойтись. Когда-то давно я уже писал пост на хабре об игровых деревьях. Основное преимущество игровых деревьев в том, что они могу применяться к любой игре: и к крестикам-ноликам, и к шашкам, и к шахматам и даже к сёги. Давайте попытаемся вспомнить основные идеи.
Перебор игровых деревьев
Полный перебор игровых деревьев
Пусть мы играем в сёги и в какой-то момент на доске возникла интересная позиция, в которой нам необходимо найти лучший ход за сенте. Т.к. компьютер по сути своей — глупый исполнитель, мы можем приказать ему перебрать все возможные ходы и оценить их. Тогда лучшим ходом будет ход с наибольшей оценкой. Но нам по-прежнему неизвестно, как оценивать ходы.
Тут можно сделать небольшое отступление и заметить, что если в какой-то позиции у сенте есть преимущество в условных единиц, то готе в этой же позиции проигрывают условных единиц. Получается, что функция оценки позиции как со стороны сенте, так и со стороны готе даст одинаковый по модулю результат, а разница будет только в знаке.
Тогда оценка каждого хода для сенте может быть получена инвертированием оценки лучшего ответного хода для готе. А оценка лучшего хода для готе получается путём оценки лучшего ответного хода для сенте и т.д. Т.е. получается, что функция оценки хода по сути своей рекурсивна. Эти рекурсивные оценки позиции в идеале должны продолжаться до тех пор, пока в каждой ветви дерева игра не завершится матом. На рисунке ниже показана малая часть игрового дерева, возникающего при игре в сёги:
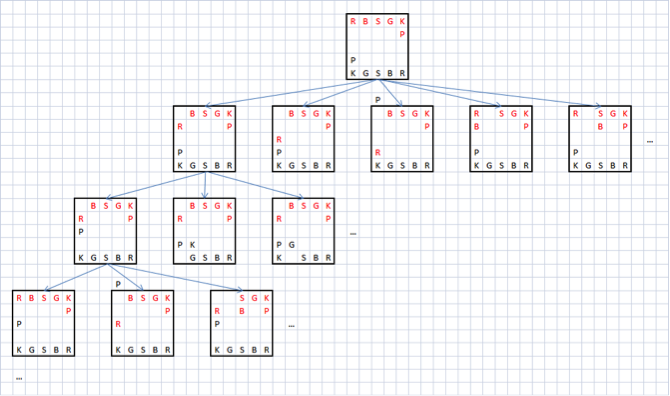
Перебор игровых деревьев с ограничением глубины рекурсии
Очевидно, что это дерево растёт чрезвычайно быстро. Даже для крестиков-ноликов, полное дерево будет содержать более четверти миллиона узлов, что уж говорить о шахматах и сёги. В реальных алгоритмах глубину рекурсии искусственно ограничивают, и если достигнута максимальная глубина рекурсии, то вызывается функция статической оценки позиции, которая, например, просто подсчитывает материальный перевес. Таким образом функция поиска лучшего хода может быть записана следующим образом:
function SearchBestMove(Depth: byte; color: TColor): real;
var
r,tmpr: real;
i, N: word;
Moves: TAMoves;
begin
if Depth=0 then
r:=EstimatePos
else
begin
real:=-100000;
N:=GenerateAllMoves(Moves);
for i:=1 to N do
begin
Делаем ход Moves[i];
tmpr:=-SearchBestMove(Depth—1,opcolor(color));
Отменяем ход Moves[i];
if tmpr>r then
r:=tmpr;
end;
end;
SearchBestMove:=r;
end;
Понятно, что данный алгоритм выдаёт не полную оценку позиции, а только оценку той позиции, которая возникнет через Depth ходов. Поэтому, если необходимо усилить игру программы, в первую очередь надо увеличивать глубину рекурсии, а это в свою очередь приводит к увеличению дерева, а значит и увеличению времени счёта.
Альфа-бета отсечение
На самом деле существует алгоритм, который позволяет перебирать далеко не всё дерево, а лишь малую его часть, и при этом выдавать оценки такой же точности, что и при полном переборе. Это алгоритм называется альфа-бета отсечением.
В основе алгоритма лежит идея, что некоторые ветви дерева могут быть признаны неэффективными ещё до того, как они будут полностью рассмотрены. Например, если оценивающая функция в каком-то узле будет гарантировано хуже чем в ранее рассмотренных ветвях, то рассмотрение этого узла можно прекратить досрочно.
Такая ситуация возникает в следующих случаях: пусть мы рассматриваем позицию за сенте, и, рассмотрев, какую-то ветвь получили оценку позиции. Потом в глубине дерева при рассмотрении другого возможного хода мы заметили, что оценка для белых стала больше или равна ранее полученному максимуму. Очевидно, что дальше рассматривать этот узел нет никакого смысла, и все ветви, выходящие из него не принесут никакого улучшения позиции.
Вы, возможно, уже заметили, что этот алгоритм позволяет отсекать ветви только в том случае, если ранее был рассмотрен более хороший ход. Если предположить, что при просмотре все ходы проверялись в последовательности от худшего к лучшему, то альфа-бета алгоритм не даст никакого выигрыша по сравнению с полным перебором. Если же в начале были рассмотрены самые хорошие ходы, то альфа-бета алгоритм вместо полного дерева из N узлов рассмотрит всего лишь корень из N узлов, при той же точности оценки.
Сортировка ходов
Основная проблема в том, что заранее невозможно определить, какие ходы на самом деле хорошими, а какие окажутся плохими. В этом случае приходится прибегать к эвристикам. Если при оценки позиции в расчёт берётся только материальный перевес, то имеет смысл первыми рассматривать ходы-взятия. Причём, есть смысл в первую очередь рассматривать те ходы, где лёгкой фигурой берётся тяжёлая. Кроме того в сёги огромную роль играют перевёрнутые фигуры, поэтому для ходов-переворотов тоже можно увеличивать предварительную эвристическую оценку.
Кстати, о переворотах. Важно понимать, что если переворот возможен, его не всегда надо делать. Например в конце игры серебро, умеющее отступать вбок, иногда оказывается эффективнее золота, которое гораздо менее манёвренно при отступлении. Но для пешек, ладей и слонов переворот выполняется всегда, т.к. переворот оставляет все исходные ходы и добавляет новые.
В итоге после того, как все ходы были сгенерированы и проведена их эвристическая оценка, необходимо их отсортировать по этой оценке, и подать на вход альфа-бета алгоритма, который выглядит примерно так:
function AB(POS: TRPosition; color: TColor; Depth: byte; A,B: real): real;
var
Moves: TAMoves;
i,MovesCount: byte;
OLDPos: TRPosition;
begin
MovesCount:=0;
if (Depth=0) or Mate(POS.HandSente,POS.HandGote,color) then
A:= EstimatePos
else
begin
if color=sente then
MovesCount:=GenerateMoves(POS.Board,color,POS.HandSente,Moves)
else
MovesCount:=GenerateMoves(POS.Board,color,POS.HandGote,Moves);
for i:=1 to MovesCount do
begin
if A>=B then
Break;
OLDPOS:=POS;
MakeMove(POS,Color,Moves[i]);
Moves[i].r:=-AB(POS,opcolor(color),Depth—1,—B,—A);
POS:=OLDPos;
if Moves[i].r>A then
A:=Moves[i].r;
end;
end;
AB:=A;
end;
Итоговая реализация
В результате я написал небольшую программу (скачать), которая на мой взгляд, весьма неплохо играет в сёги. Конечно, она далека от совершенства, и в ней есть много вещей, требующих исправления и доработки. Неплохо было бы добавить ходы — угрозы королю в эвристическую оценку, совсем здорово было бы доработать программу и научить её играть в полноценные сёги, но всё это планы на будущее, а пока вы можете попробовать свои силы в этой интереснейшей игре.
ссылка на оригинал статьи http://habrahabr.ru/post/156233/
Добавить комментарий