
Тестирование и поиск ошибок – неотъемлемая и не самая интересная часть процесса разработки ПО. Для избавления себя от рутины этот процесс все стараются автоматизировать. И если для проверки функционала приложения создаются специализированные самодельные тесты, то поиск ошибок общего типа далеко не всегда ими покрывается. Проверяется ли, например, ваше приложение на наличие утечек памяти или гонок данных? В этой статье рассмотрим, как использовать обновлённый Inspector XE 2013 в двух ипостасях:
- Для регулярного автоматического тестирования (regression testing)
- Для ручного поиска причин проблемы в паре с отладчиком
Зачем нужен Inspector XE?
Inspector XE – инструмент анализа корректности кода из состава Intel Parallel Studio XE, но поставляется и как отдельный продукт. Его назначение – поиск ошибок памяти (утечки, доступ к неинициализированной памяти и т.д.) и проблем, вызванных взаимодействием потоков (гонки данных, deadlock-и и т.д.). При этом проблема не обязательно должна себя проявить – если есть потенциальный deadlock (взаимная блокировка), Inspector XE его найдёт, даже если программа не «повисла» (но ветки кода, в которых он может возникнуть, исполнились).

Инспектор использует динамический анализ, т.е. анализируется не исходный код, а исполняемый процесс. Во время исполнения инспектор анализирует, что происходит в приложении, как оно выделяет и освобождает память, создаёт потоки, использует объекты синхронизации и т.д., после чего выдаёт программисту список найденных проблем:

Отдельную проблему можно более детально изучить в source view:

Статический анализ исходников тоже есть, но он выполняется компилятором Intel. А Inspector XE отображает, визуализирует результаты анализа, позволяет их фильтровать, управлять состоянием проблем и т.д. В этом посте этой темы касаться не будем.
Кстати, работает Inspector XE с кодом на C/C++, C# и Fortran. Выпускается для двух ОС: Windows* и Linux*. В обоих есть два интерфейса: GUI и командная строка. Кроме того, в Windows он ещё и интегрируется в Microsoft Visual Studio*.
Инспектировать, в принципе, можно любой исполняемый файл. Однако есть несколько рекомендаций для того, чтобы повысить вероятность обнаружения проблем, увидеть их в исходном коде и потратить на это не слишком много времени:
- Компилировать с ключами /MDd, /ZI, /Od и линковать с /DEBUG и /FIXED:NO (на примере компилятора и линкера Microsoft). Для связки бинарников и исходников нужна символьная информация, а оптимизацию стоит выключить, чтобы Inspector XE не был запутан компилятором.
- Для поиска ошибок многопоточности, по возможности снизьте нагрузку на приложение. Например, минимизируйте размер входных данных. Это позволит сэкономить время, т.к. Inspector XE замедляет работу программы – издержки динамического анализа и бинарной инструментации. Снижение нагрузки не скажется на результате, потому что инспектор ищет потенциальные проблемы взаимодействия потоков.
- Для поиска ошибок памяти наоборот, лучше использовать полный набор данных, т.к. для этого типа ошибок детектируются реально возникшие проблемы.
- Подбирайте тесты, активизирующие разные ветки кода. Если ветка кода не исполнялась, она не будет проанализирована.
Автоматизированное тестирование
Inspector XE – инструмент верификации. А для того, чтобы поддерживать качество и стабильность ПО на высоком уровне, верификацию стоит проводить регулярно. Можно, например, прогонять проверку инспектором во время ночного регрессионного тестирования. Для этого воспользуемся командным интерфейсом инструмента. Синтаксис команд Inspector XE для Linux* и Windows* одинаков. Пример запуска анализа тестового приложения в Windows:
inspxe-cl -collect mi3 -knob resources=true -knob still-allocated-memory=true -knob stack-depth=16 -knob analyze-stack=true -- D:\tests\testapps\mem_error.exeКомандная строка всегда начинается с запуска самого инспектора – “inspxe-cl”. Ключ “-collect” говорит о том, что надо запустить анализ, “-mi3” – тип анализа (поиск ошибок памяти, или “Locate memory problems”). Дальше идут прочие параметры анализа и путь к анализируемому приложению. Полную справку по синтаксису и параметрам можно распечатать командой “inspxe-cl -help”. Кроме того, если вы уже работаете в GUI и хотите запустить такой же анализ в командной строке, там есть кнопка “Command line”, которая сформирует готовую командную строку для сконфигурированного в GUI анализа.
После окончания анализа Inspector XE создаст папку с файлами результатов. Их можно просматривать в GUI, причём результаты, собранные на Linux можно просматривать на другой Windows машине (и наоборот). Однако простой запуск анализа из скрипта с последующим ручным просмотром результатов не есть полная автоматизация. Поэтому в инспекторе есть возможность распечатки информации о найденных проблемах и в CLI:
inspxe-cl -report problems -r D:\tests\testapps\r002mi3
P1: Error: Mismatched allocation/deallocation New Problem P1.1: Mismatched allocation/deallocation D:\tests\testapps\mem_error.cpp(48): Error X10: Allocation site: Function start: Module D:\tests\testapps\mem_error.exe D:\tests\testapps\mem_error.cpp(49): Error X9: Mismatched deallocation site: Function start: Module D:\tests\testapps\mem_error.exe P3: Error: Invalid memory access New Problem P3.1: Invalid memory access D:\tests\testapps\mem_error.cpp (40): Error X4: Allocation site: Function start: Module D:\tests\testapps\mem_error.exe D:\tests\testapps\mem_error.cpp (42): Error X5: Deallocation site: Function start: Module D:\tests\testapps\mem_error.exe D:\tests\testapps\mem_error.cpp (44): Error X3: Read: Function start: Module D:\tests\testapps\mem_error.exe Если простой текст не годится, можно экспортировать в csv, или распечатать в XML формате, чтобы парсить потом всевозможными Perl-ами и Python-ами:
inspxe-cl -report problems –format=xml -r D:\tests\r002mi3\
<?xml version="1.0" encoding="UTF-8"?> <pset id="P1" type="Mismatched allocation/deallocation" state="New" severity="Error"> <obs id="X1" type="Allocation site" state="New" severity="Error"> <stack id="10"> <frame id="" module=" D:\tests\testapps\mem_error.exe" file="D:\tests\testapps\mem_error.cpp“ func="start" line="48"/> <frame id="" module=" D:\tests\testapps\mem_error.exe " file="D:\tests\testapps\mem_error.cpp“ func="start1" line="84"/> <frame id="" module="C:\Windows\syswow64\kernel32.dll“ func="BaseThreadInitThunk" line="78792"/> </stack> </obs> <obs id="X2" type="Mismatched deallocation site" state="New" severity="Error"> <stack id="9"> <frame id="" module=" D:\tests\testapps\mem_error.exe " file="D:\tests\testapps\mem_error.cpp“ func="start" line="49"/> <frame id="" module=" D:\tests\testapps\mem_error.exe " file="D:\tests\testapps\mem_error.cpp“ func="start1" line="84"/> </stack> </obs> </pset> Из всего многообразия проблем, коих на большом проекте может быть найдено довольно много, нужно ещё отфильтровать новые и заслуживающие внимания. В Inspector XE есть возможность назначать проблемам состояния (New, Confirmed, Fixed и т.д.). Если проект инспектируется регулярно, то интересна в первую очередь динамика – не появилось ли что-то новое после недавних изменений? Для такого случая Inspector XE может объединять информацию о проблемах с разных запусков, выдавая резюме об изменениях:
inspxe-cl –merge-states D:\tests\r000mi3\ -r D:\tests\r001mi3\
inspxe-cl -report status -r D:\tests\r001mi3\
9 problem(s) found 3 Investigated 6 Not investigated Breakdown by state: 2 Confirmed 1 Not a problem 4 Not fixed 2 Regression Inspector XE может оказаться весьма полезным для поиска потенциальных «ошибок многопоточности». Рассмотрим простой пример на С++ с гонкой данных. Цикл распараллелен с использованием OpenMP. Пространство итераций разбивается на мелкие порции и может исполняться параллельно:
#pragma omp parallel for shared(j) for(i=0; i<MAX; i++) { printf("j=%d ", j++); } if(j != MAX) printf(“error\n”); Чтобы эта гонка иногда проявляла себя, нам потребовалось использовать MAX > 100000000, тест работал больше 10 минут. Inspector XE находит такую проблему с MAX = 10 и за 10 секунд, т.к. ищет потенциальные гонки данных. Пример, конечно, весьма рафинированный, но может использоваться для иллюстрации. В подобных случаях инспектор увеличит эффективность тестового прогона – больше найденных проблем в единицу времени.
Для сужения области поиска можно проводить анализ лишь некоторых модулей приложения:
inspxe-cl -collect mi1 -module-filter module1.dll,module2.dll -module-filter-mode exclude -- D:\tests\testapps\mem_error.exe Параметр “-module-filter-mode” определяет, хотим мы исключить указанные модули из анализа (exclude) или наоборот, анализировать только их (include).
Если нужно проанализировать дочерний процесс – например, если приложение запускается из скрипта, используйте опцию “-executable-of-interest”:
inspxe-cl -collect mi1 -executable-of-interest mem_error.exe -- D:\tests\testapps\startup_script.bat Результаты, полученные от инспектора, могут использовать разные члены команды. Для транспортировки результата используйте опцию “export”. Она упаковывает результат в один архив, вместе с некоторыми исходниками, для того, чтобы на другой машине не пришлось настраивать проект, пути к файлам и т.п.:
inspxe-cl -export -archive-name my-new-archived_result.inspxez -include-sources -result-dir myRes Для командной работы могут также пригодиться:
- Возможность делать текстовые отчёты и комментарии о проблемах
- Защита от одновременного редактирования результатов разными пользователями
- Общие правила подавления. Если, например, инспектор нашёл проблему в чужом модуле (системной библиотеке), исправлять которую вы не собираетесь, её можно специально пометить – подавить, чтобы не засоряла результат. Правила подавления хранятся в специальном файле, который может быть общим для всей команды.
Всё. Теперь осталось проинтегрировать запуск Inspector XE и парсинг результатов анализа в скрипты, выполняющие ночное тестирование, но это уже индивидуально и в этом посте не покрывается.
Инспектор + отладчик = два сапога пара
Другая модель использования Inspector XE – поиск проблем вручную, чтобы докопаться до причины её возникновения. Возможно, в программе есть какой-то баг — иногда подвисает или падает. Или ночное тестирование инспектором обнаружило новую проблему, которую нужно изучить. Или вы просто решили сесть и проверить лишний раз надёжность вашего творения.
В этих случаях будет полезна интеграция Inspector XE с отладчиками. Эта функциональность появилась не так давно – в версии 2013. На данный момент поддерживается интеграция с отладчиками gdb и Intel® Debugger на Linux* и Visual Studio Debugger на Windows*.
Если мы ищем неизвестную проблему (что-то в приложении иногда глючит), для запуска инспектора в паре с отладчиком в настройках анализа выбираем “Enable debugger when problem detected”:

Теперь запускаем анализ и ждём – как только обнаружится проблема, Inspector XE остановит выполнение, и вы сможете поковыряться в ней дебаггером. Это будет делаться для всех найденных проблем.
Если же мы уже нацелились на какую-то багу, выявленную на ночном тестировании, открываем результаты анализа в инспекторе, правый клик на проблему, выбираем “Debug This Problem”. Inspector XE запустит такой же анализ снова, и, как только отмеченная проблема снова себя проявит, вас погрузят в отладочную сессию на месте её возникновения:
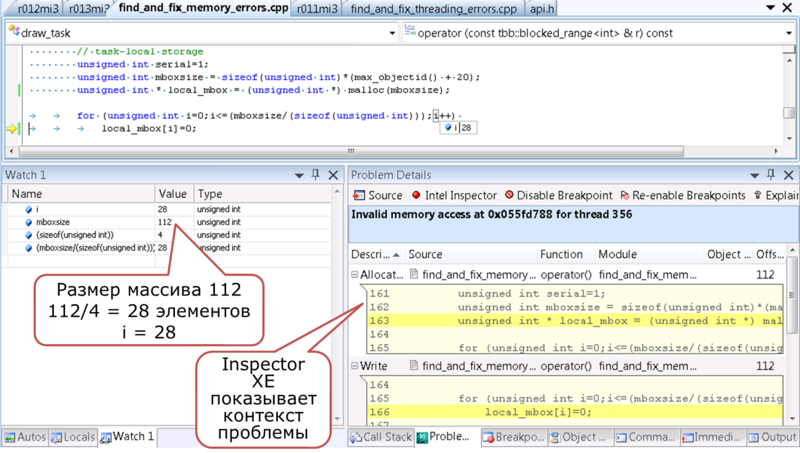
Ещё можно поставить свой брейкпойнт, и выбрать третий вариант запуска отладчика в конфигурации анализа инспектора:

В этом случае Inspector XE не будет ничего анализировать, пока выполнение не остановится на этом брейкпойнте. А если в меню Debug (Visual Studio) выбрать”Continue with Inspector XE”, выполнение продолжится, но уже с инспектированием. Дальше всё пойдёт по первому сценарию, с остановкой на каждой найденной проблеме. Это бывает полезно для того, чтобы снизить время анализа и исключить неинтересный в данном контексте код (например, долгую инициализацию).
Резюме
Inspector XE выступает универсальным инструментов для поиска ошибок памяти и многопоточного исполнения. Благодаря динамическому анализу могут быть обнаружены достаточно сложные, глубоко сидящие проблемы. Из-за него же время исполнения программы под анализом может значительно увеличиваться. Inspector XE 2013 может использоваться как для работы в GUI, в паре с отладчиком помогая находить корни хитрых проблем, так и для автоматизированной верификации. Но в обоих случаях он служит повышению стабильности кода – чем больше проблем найдётся и чем раньше это сделать, тем надёжнее будет готовое приложение.
ссылка на оригинал статьи http://habrahabr.ru/company/intel/blog/156289/
Добавить комментарий