Что такое NEON? NEON – это SIMD движок общего назначения, используемый в ARM процессорах. На борту имеет 16 регистров по 128 бит каждый, которые можно рассматривать как 32 регистра по 64 бита. NEON делит свои регистры с VFP, хотя имеет свой отдельный пайплайн. Как и в случае с SSE данные должны быть выровнены на 16 байт. NEON так же умеет работать с невыровненными данными, но обычно это в 2 раза медленнее.
NEON умеет работать с:
- Знаковыми\без знаковыми 8\16\32\64-битными целочисленными типами данных;
- Числами с плавающей запятой одинарной точности – 32-х битный float.
Он великолепно подходит для мультимедийных задач, в том числе и игр.
Начнем с основного – сердца каждой современной мобильной системы, системы на чипе или SoC (System on Chip). Известно, что в iOS девайсах используется Apple A серия систем на чипе – А4, А5, А5х, А6 и А6х. Наиболее важные спецификации этих чипов приведены в таблице:
| Спецификации CPU | A4 | A5 | A5x | A6 |
|---|---|---|---|---|
| Архитектура | ARMv7 | ARMv7 | ARMv7 | ARMv7 |
| Ядро | Cortex A8 | Cortex A9 | Cortex A9 | Собственной разработки |
| # ядер | 1 | 2 | 2 | 2 |
| Частота, МГц | 800 | 1000 | 1000 | 1300 |
| Расширения | VFPv3 (VFPLite), NEON | VFPv3, NEON | VFPv3, NEON | VFPv4, NEON |
| Спецификации GPU | ||||
| Модель | PowerVR SGX 535 | PowerVR SGX 543MP2 | PowerVR SGX 543MP4 | PowerVR SGX 543MP3 |
| Частота, МГц | 200 | 200 | 200 | 266 |
*Внимание: каждое ядро процессора снабжено своим NEON юнитом, когда же VFP — один на процессор.
** Внимание: NEON работает на частоте CPU
Легко заметить, что NEON имеет 5-ти кратный прирост частоты по сравнению с GPU! Конечно, это не значит, что мы получим 5-ти кратное увеличение производительности по сравнению с GPU – IPC, пайплайн, т.д. имеют весомое значение. Но у NEON’а есть одна киллер фича – он может параллельно обрабатывать 4 32-х битных флоата, в то время как PowerVR SGX – только один. Кажется, у PowerVR SGX 5-й серии SIMD регистры имеют длину в 64 бита, так как GPU может параллельно обрабатывать 4 флоата половинной точности (16 бит). Рассмотрим пример:
highp vec4 v1, v2; highp float s1, s2; // Плохо v2 = (v1 * s1) * s2; //v1 * s1 будет выполнено на скалярном процессоре – 4 операции, результат этого умножения будет умножен на s2, опять на скалярном процессоре - еще 4 операции. //8 операций в общем // Хорошо v2 = v1 * (s1 * s2); //s1 * s2 – 1 операция на скалярном процессоре; результат * v1 – 4 операции на скалярном. //5 операций в общем Теперь рассмотрим другой пример, исполняемый на векторном движке GPU:
mediump vec4 v1, v2, v3; highp vec4 s1, s2, s3; v3 = v1 * v2; //исполняется на векторном процессоре – 1 операция s3 = s1 * s2; //исполняется на скалярном процессоре – 4 операции Вам понадобится highp спецификатор для ваших данных, к примеру, позиции вершин. Профит от NEON’а здесь очевиден.
Теперь перейдем к другому преимуществу NEON’а. Известно, что PowerVR SGX 5-й серии обладают USSE, шейдерный процессор, которому без разницы какой тип шейдеров обрабатывать – вершинный или пиксельный. Это значит, что у программиста есть некий бюджет мощности и ему решать, на что его потратить – вершинный или пиксельный процессинг. Вот тут-то и приходит на помощь NEON – это ваш новый вершинный процессор. Вы можете подумать, что я забыл здесь вставить троллфейс, но все вполне серьёзно. Производительность почти каждой мобильной системы ограничена филлрейтом, особенно в 2D играх, особенно в наше время гонки за разрешением экранов. Перенеся весь вершинный процессинг на NEON у вас высвобождаются ресурсы для пиксельного процессинга. В дополнение к этому NEON поможет сократить количество вызовов на отрисовку – посчитайте позиции всех вершин одного батча в мировых координатах и нарисуйте N объектов за один вызов.
С теорией покончено! Теперь перейдем к хардкору! Есть несколько способов воспользоваться преимуществами NEON’a:
- Пусть компилятор векторизирует код вместо вас. Плохой способ. Компилятор может векторизировать… а может и не векторизировать. Даже если компилятор векторизирует код, то далеко не факт, что это будет оптимальный код. Но, с другой стороны, этот способ не требует никаких усилий с вашей стороны, а профит получить можно. Но все же не стоит слепо надеяться на компилятор, а вручную векторизировать хотя бы наиболее критичный код.
- NEON ассемблер. А вот и он, хардкор. Путь истинного джедая и все такое. Придется учить темную магию, проводить ночи за мануалами от ARM и т.д. Также стоит иметь в виду, что NEON код работает в обоих ARM и Thumb-2 режимах.
- NEON интринсики (такие же как SSE для x86). В отличии от ассемблера, где компилятор тупо вставит то, что ему дали, интринсики будут оптимизированны. С ними жить намного проще – нету необходимости изучать тайминги инструкций, перетасовывать их, чтобы избежать застоя пайплайна и т.д.
- Использовать либы с уже векторизированным кодом – GLKMath, math neon.
Пришло время обнаружить все преимущества и недостатки каждого из методов. Для этого я написал простенькое демо – каждый кадр 10000 спрайтов будут менять свою позицию на случайную в пределах экрана. Цель – получить максимально быстрый код с минимальной нагрузкой на CPU – ведь в играх надо много чего считать, помимо данных для рендера.
Все данные хранятся в одном VBO. Метод Update перемножает матрицу проекции на ModelView матрицу случайной позиции. Далее каждая вершина каждого спрайта будет перемножена на результирующую ModelViewProjection матрицу. Финальная позиция каждой вершины будет просто передана в gl_Position в вершинном шейдере. Все данные выравнены на границу в 16 байт.
Код Update метода:
void Update() { GLKMatrix4 modelviewMat = { 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, }; const u32 QUADS_COUNT = 10000; const u32 VERTS_PER_QUAD = 4; const float Y_DELTA = 420.0f / QUADS_COUNT; //равномерно распределить все спрайты по Y float vertDelta = Y_DELTA; for (int i = 0; i < QUADS_COUNT * VERTS_PER_QUAD; i += VERTS_PER_QUAD) { float randX = random() % 260; //Матрица смещения на случайное число modelviewMat.m[12] = randX; modelviewMat.m[13] = vertDelta; float32x4x4_t mvp; Matrix4ByMatrix4((float32x4x4_t*)proj.m, (float32x4x4_t*)modelviewMat.m, &mvp); for (int j = 0; j < 4; ++j) { Matrix4ByVec4(&mvp, &squareVertices[j], &data[i + j].pos); } vertDelta += Y_DELTA; } glBindBuffer(GL_ARRAY_BUFFER, vertexBuffer); glBufferData(GL_ARRAY_BUFFER, sizeof(data), data, GL_STREAM_DRAW); } Что ж, теперь мы подошли к сути этой статьи – векторизации кода. Далее будет представлен код, используемый в трех сравниваемых подходах для наиболее часто используемых операций в геймдеве – перемножение матрицы на вектор и перемножение матрицы на матрицу.
Копипаста с GLKMath:
static __inline__ GLKVector4 GLKMatrix4MultiplyVector4(GLKMatrix4 matrixLeft, GLKVector4 vectorRight) { float32x4x4_t iMatrix = *(float32x4x4_t *)&matrixLeft; float32x4_t v; iMatrix.val[0] = vmulq_n_f32(iMatrix.val[0], (float32_t)vectorRight.v[0]); iMatrix.val[1] = vmulq_n_f32(iMatrix.val[1], (float32_t)vectorRight.v[1]); iMatrix.val[2] = vmulq_n_f32(iMatrix.val[2], (float32_t)vectorRight.v[2]); iMatrix.val[3] = vmulq_n_f32(iMatrix.val[3], (float32_t)vectorRight.v[3]); iMatrix.val[0] = vaddq_f32(iMatrix.val[0], iMatrix.val[1]); iMatrix.val[2] = vaddq_f32(iMatrix.val[2], iMatrix.val[3]); v = vaddq_f32(iMatrix.val[0], iMatrix.val[2]); return *(GLKVector4 *)&v; } static __inline__ GLKMatrix4 GLKMatrix4Multiply(GLKMatrix4 matrixLeft, GLKMatrix4 matrixRight) { float32x4x4_t iMatrixLeft = *(float32x4x4_t *)&matrixLeft; float32x4x4_t iMatrixRight = *(float32x4x4_t *)&matrixRight; float32x4x4_t m; m.val[0] = vmulq_n_f32(iMatrixLeft.val[0], vgetq_lane_f32(iMatrixRight.val[0], 0)); m.val[1] = vmulq_n_f32(iMatrixLeft.val[0], vgetq_lane_f32(iMatrixRight.val[1], 0)); m.val[2] = vmulq_n_f32(iMatrixLeft.val[0], vgetq_lane_f32(iMatrixRight.val[2], 0)); m.val[3] = vmulq_n_f32(iMatrixLeft.val[0], vgetq_lane_f32(iMatrixRight.val[3], 0)); m.val[0] = vmlaq_n_f32(m.val[0], iMatrixLeft.val[1], vgetq_lane_f32(iMatrixRight.val[0], 1)); m.val[1] = vmlaq_n_f32(m.val[1], iMatrixLeft.val[1], vgetq_lane_f32(iMatrixRight.val[1], 1)); m.val[2] = vmlaq_n_f32(m.val[2], iMatrixLeft.val[1], vgetq_lane_f32(iMatrixRight.val[2], 1)); m.val[3] = vmlaq_n_f32(m.val[3], iMatrixLeft.val[1], vgetq_lane_f32(iMatrixRight.val[3], 1)); m.val[0] = vmlaq_n_f32(m.val[0], iMatrixLeft.val[2], vgetq_lane_f32(iMatrixRight.val[0], 2)); m.val[1] = vmlaq_n_f32(m.val[1], iMatrixLeft.val[2], vgetq_lane_f32(iMatrixRight.val[1], 2)); m.val[2] = vmlaq_n_f32(m.val[2], iMatrixLeft.val[2], vgetq_lane_f32(iMatrixRight.val[2], 2)); m.val[3] = vmlaq_n_f32(m.val[3], iMatrixLeft.val[2], vgetq_lane_f32(iMatrixRight.val[3], 2)); m.val[0] = vmlaq_n_f32(m.val[0], iMatrixLeft.val[3], vgetq_lane_f32(iMatrixRight.val[0], 3)); m.val[1] = vmlaq_n_f32(m.val[1], iMatrixLeft.val[3], vgetq_lane_f32(iMatrixRight.val[1], 3)); m.val[2] = vmlaq_n_f32(m.val[2], iMatrixLeft.val[3], vgetq_lane_f32(iMatrixRight.val[2], 3)); m.val[3] = vmlaq_n_f32(m.val[3], iMatrixLeft.val[3], vgetq_lane_f32(iMatrixRight.val[3], 3)); return *(GLKMatrix4 *)&m; } Легко заметить, что реализация этих операций от Apple использует далеко не оптимальный подход – передача переменных по значению, копирование переменных. Выглядит довольно медленно, по крайней мере в дебаг сборке оно и будет являться таковым. Посмотрим, как этот код покажет себя при профиллировке.
Ассемблерный подход:
inline void Matrix4ByVec4(float32x4x4_t* __restrict__ mat, const float32x4_t* __restrict__ vec, float32x4_t* __restrict__ result) { asm ( "vldmia %0, { d24-d31 } \n\t" "vld1.32 {q1}, [%1]\n\t" "vmul.f32 q0, q12, d2[0]\n\t" "vmla.f32 q0, q13, d2[1]\n\t" "vmla.f32 q0, q14, d3[0]\n\t" "vmla.f32 q0, q15, d3[1]\n\t" "vstmia %2, { q0 }" : : "r" (mat), "r" (vec), "r" (result) : "memory", "q0", "q1", "q8", "q9", "q10", "q11" ); } inline void Matrix4ByMatrix4(const float32x4x4_t* __restrict__ m1, const float32x4x4_t* __restrict__ m2, float32x4x4_t* __restrict__ r) { asm ( "vldmia %1, { q0-q3 } \n\t" "vldmia %2, { q8-q11 }\n\t" "vmul.f32 q12, q8, d0[0]\n\t" "vmul.f32 q13, q8, d2[0]\n\t" "vmul.f32 q14, q8, d4[0]\n\t" "vmul.f32 q15, q8, d6[0]\n\t" "vmla.f32 q12, q9, d0[1]\n\t" "vmla.f32 q13, q9, d2[1]\n\t" "vmla.f32 q14, q9, d4[1]\n\t" "vmla.f32 q15, q9, d6[1]\n\t" "vmla.f32 q12, q10, d1[0]\n\t" "vmla.f32 q13, q10, d3[0]\n\t" "vmla.f32 q14, q10, d5[0]\n\t" "vmla.f32 q15, q10, d7[0]\n\t" "vmla.f32 q12, q11, d1[1]\n\t" "vmla.f32 q13, q11, d3[1]\n\t" "vmla.f32 q14, q11, d5[1]\n\t" "vmla.f32 q15, q11, d7[1]\n\t" "vstmia %0, { q12-q15 }" : : "r" (result), "r" (m2), "r" (m1) : "memory", "q0", "q1", "q2", "q3", "q8", "q9", "q10", "q11", "q12", "q13", "q14", "q15" ); } Для человека не знакомого с ассемблером все кажется довольно страшным – я сам такой, могу разбираться только в NEON ассемблере. Но на самом деле здесь все просто – q1-q15 это, собственно, NEON регистры. vldmia\vld1.32 – инструкции загрузки; vstmia – сохранения в память; vmul.f32\vmla.f32 — умножить\умножить и прибавить.
Метод интринсиков:
inline void Matrix4ByVec4(float32x4x4_t* __restrict__ mat, const float32x4_t* __restrict__ vec, float32x4_t* __restrict__ result) { (*result) = vmulq_n_f32((*mat).val[0], (*vec)[0]); (*result) = vmlaq_n_f32((*result), (*mat).val[1], (*vec)[1]); (*result) = vmlaq_n_f32((*result), (*mat).val[2], (*vec)[2]); (*result) = vmlaq_n_f32((*result), (*mat).val[3], (*vec)[3]); } inline void Matrix4ByMatrix4(const float32x4x4_t* __restrict__ m1, const float32x4x4_t* __restrict__ m2, float32x4x4_t* __restrict__ r) { (*r).val[0] = vmulq_n_f32((*m1).val[0], vgetq_lane_f32((*m2).val[0], 0)); (*r).val[1] = vmulq_n_f32((*m1).val[0], vgetq_lane_f32((*m2).val[1], 0)); (*r).val[2] = vmulq_n_f32((*m1).val[0], vgetq_lane_f32((*m2).val[2], 0)); (*r).val[3] = vmulq_n_f32((*m1).val[0], vgetq_lane_f32((*m2).val[3], 0)); (*r).val[0] = vmlaq_n_f32((*r).val[0], (*m1).val[1], vgetq_lane_f32((*m2).val[0], 1)); (*r).val[1] = vmlaq_n_f32((*r).val[1], (*m1).val[1], vgetq_lane_f32((*m2).val[1], 1)); (*r).val[2] = vmlaq_n_f32((*r).val[2], (*m1).val[1], vgetq_lane_f32((*m2).val[2], 1)); (*r).val[3] = vmlaq_n_f32((*r).val[3], (*m1).val[1], vgetq_lane_f32((*m2).val[3], 1)); (*r).val[0] = vmlaq_n_f32((*r).val[0], (*m1).val[2], vgetq_lane_f32((*m2).val[0], 2)); (*r).val[1] = vmlaq_n_f32((*r).val[1], (*m1).val[2], vgetq_lane_f32((*m2).val[1], 2)); (*r).val[2] = vmlaq_n_f32((*r).val[2], (*m1).val[2], vgetq_lane_f32((*m2).val[2], 2)); (*r).val[3] = vmlaq_n_f32((*r).val[3], (*m1).val[2], vgetq_lane_f32((*m2).val[3], 2)); (*r).val[0] = vmlaq_n_f32((*r).val[0], (*m1).val[3], vgetq_lane_f32((*m2).val[0], 3)); (*r).val[1] = vmlaq_n_f32((*r).val[1], (*m1).val[3], vgetq_lane_f32((*m2).val[1], 3)); (*r).val[2] = vmlaq_n_f32((*r).val[2], (*m1).val[3], vgetq_lane_f32((*m2).val[2], 3)); (*r).val[3] = vmlaq_n_f32((*r).val[3], (*m1).val[3], vgetq_lane_f32((*m2).val[3], 3)); } Почти такой же код, как и в GLKMath, но есть небольшие отличия. Пояснения: vmulq_n_f32 – умножение вектора на скаляр; vgetq_lane_f32 – макрос, выбирающий скаляр из вектора; vmlaq_n_f32 – умножить на скаляр и прибавить. Этот код – просто отражение ассемблера на интринсики. Посмотрим, как он покажет себя в сравнении с ним.
Я делал тест на iPod Touch 4. Таблица содержит результаты профиллирования Update функции:
| Подход | Время выполнения, мс | CPU нагрузка, % |
|---|---|---|
| FPU | 6058 + 5067* | 35-38 |
| GLKMath | 2789 | 20-23 |
| Ассемблер | 5304 | 23-25 |
| Интринсики | 2803 | 18-20 |
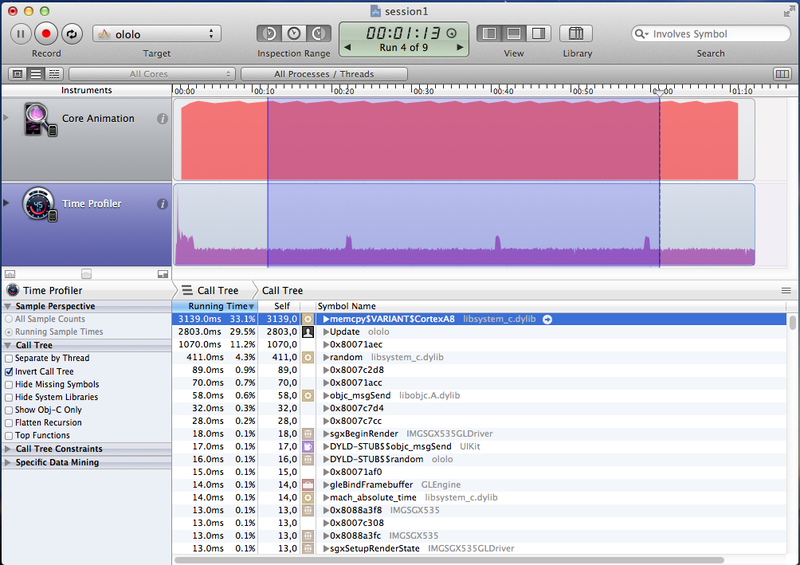
*На скриншоте из Instruments можно заметить, что функция Matrix4ByMatrix4 не заинлайнилась.
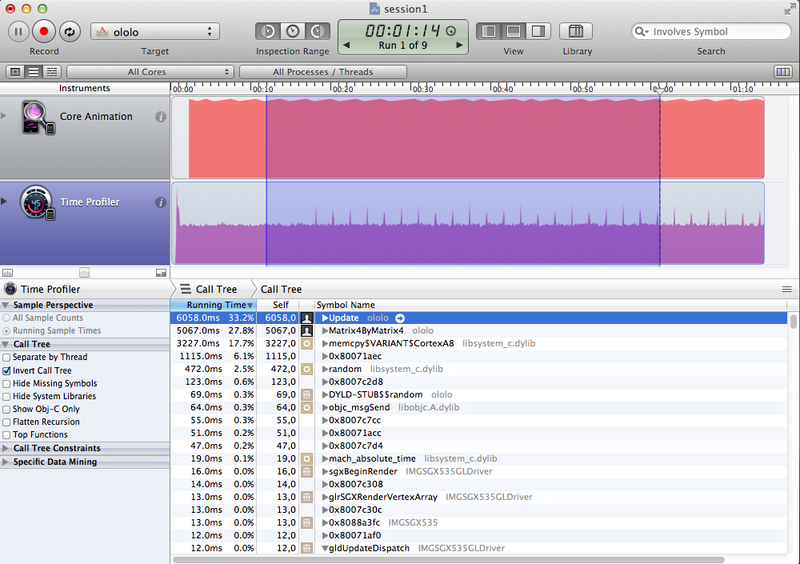{kind=link}
Вот и еще один совет – агрессивно инлайнте ваш критический к производительности код. Предпочитайте __attribute__((always_inline)) перед обычным inline в таких случаях.
Обновленная таблица результатов:
| Подход | Время выполнения, мс | CPU нагрузка, % |
|---|---|---|
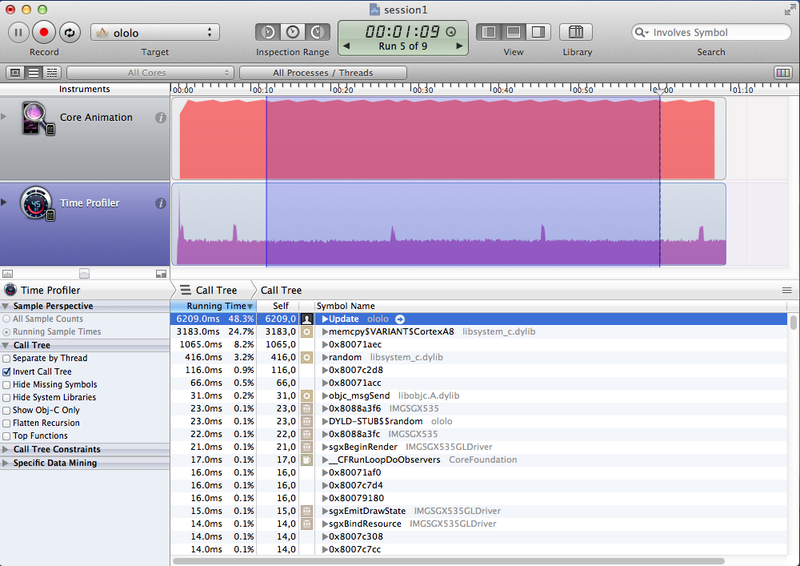
| FPU forceinlined | 6209 | 25-28 |
| GLKMath | 2789 | 20-23 |
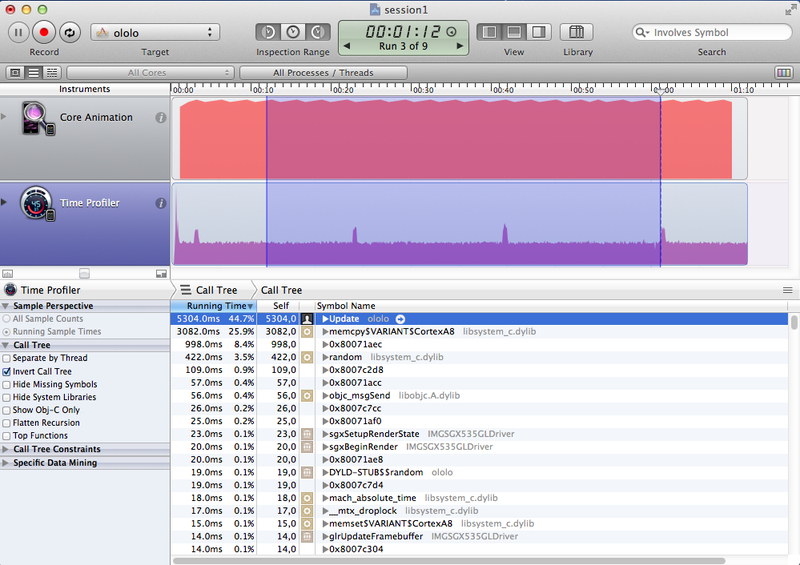
| Ассемблер | 5304 | 23-25 |
| Интринсики | 2803 | 18-20 |
Принудительный инлайн дал очень хороший прирост производительности! Посмотрим, как покажет себя автовекторизация кода. Все, что нам необходимо – это добавить –mllvm –vectorize –mllvm –bb-vectorize-aligned-only в Other C Flags в настройках проекта.
Финальная таблица результатов:
| Подход | Время выполнения, мс | Время выполнения (вектор), мс | CPU нагрузка, % | CPU нагрузка (вектор), % |
|---|---|---|---|---|
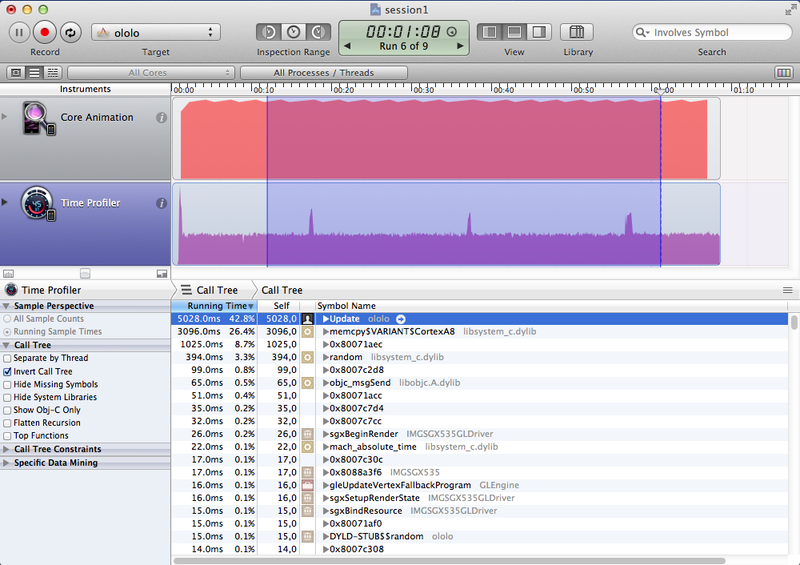
| FPU forceinlined | 6209 | 5028 | 25-28 | 22-24 |
| GLKMath | 2789 | 2776 | 20-23 | 20-23 |
| Ассемблер | 5304 | 5291 | 23-25 | 22-24 |
| Интринсики | 2803 | 2789 | 18-20 | 18-20 |
Довольно странные результаты можно наблюдать в случае с ассемблером и интринсиками – по сути код один и тот же, но результат отличается кардинально – почти в 2 раза! Ответ на этот вопрос кроется в ассемблерном листинге (желающие заглянут сами). В случае с ассемблером мы видим в листинге именно то, что мы и написали. В случае с интринсиками компилятор оптимизировал код. Медленный, на первый взгляд, код GLKMath компилятор прекрасно оптимизировал что дало такое же время исполнения кода, как и у вручную написанных интринсиков.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Настало время подводить итоги. Можно сделать несколько выводов:
- Инженеры из команды LLVM проделали великолепную работу. В итоге компилятор генерирует хорошо оптимизированный код для интринсиков. Я делал похожий тест более года назад, когда единственным компилятором в XCode был GCC 4.2 и он выдавал очень плохой результат – всего 10-15% прироста производительности по сравнению с FPU кодом. Это прекрасные новости – нет необходимости изучать ассемблер и я этому несказанно рад!
- Clang компилятор умеет автовекторизировать код. Для программиста это бонус в производительности написав лишь 4 слова. Что тут еще можно сказать кроме того, что это крутая штука?!
- NEON код дает очень хороший буст производительности по сравнению с обычным C кодом – 2.22 раз! По итогам проделанной оптимизации вершинный процессинг стал быстрее, чем копирование этих самых вершин на сторону GPU! Если заглянуть в ассемблер memcpy то можно увидеть, что там так же используется NEON код. К сожалению, я не нашел в нем прифетча, что, видимо, и является причиной более медленного кода.
- Изучение всех этих лоу левел вещей стоит потраченного времени, особенно, если ваша цель — стать профессионалом.
Ссылки
www.arm.com/products/processors/technologies/neon.php
blogs.arm.com/software-enablement/161-coding-for-neon-part-1-load-and-stores/
code.google.com/p/math-neon/
llvm.org/devmtg/2012-04-12/Slides/Hal_Finkel.pdf
Демо проект
ссылка на оригинал статьи http://habrahabr.ru/post/156809/
Добавить комментарий