 Puppet — довольно удобный инструмент для управления конфигурациями. По сути, это система, которая позволяет автоматизировать настройку и управление большим парком машин и сервисов.
Puppet — довольно удобный инструмент для управления конфигурациями. По сути, это система, которая позволяет автоматизировать настройку и управление большим парком машин и сервисов.
Базовой информации о самой системе много, в том числе и на Хабре: здесь, здесь и здесь. Мы же постарались собрать в одной статье несколько «рецептов» использования Puppet под действительно большими нагрузками — в «боевых условиях» Badoo.
О чём пойдет речь:
- Puppet: ликбез;
- кластеризация, масштабирование;
- асинхронный Storeconfigs;
- сбор отчётов;
- анализ полученных данных.
Сразу оговоримся, что статья написана по следам доклада Антона Турецкого на конференции HighLoad++ 2012. За несколько дней наши «рецепты» обросли дополнительными подробностями и примерами.
Возвращаясь к нагрузкам, следует отметить, что в Badoo они действительно высокие:
- более 2000 серверов;
- более 30 000 строк в манифестах (англ. manifest, в данном случае — конфигурационный файл для управляющего сервера);
- более 200 серверов, обращающихся за конфигурацией к puppet master каждые 3 минуты;
- более 200 серверов, отправляющих отчеты в тот же период времени.
Как это работает

Само по себе приложение Puppet является клиент-серверным. В случае с Puppet инициатором соединения выступает клиент; в данном случае это узел (англ. node), на котором нужно развернуть конфигурацию.
Шаг 1: факты в обмен на конфигурацию

Клиент собирает факты о себе с помощью утилиты facter — неотъемлемой зависимости приложения Puppet, затем отправляет их обычным запросом HTTP POST на сервер и ждёт его ответа.
Шаг 2: обработка и ответ
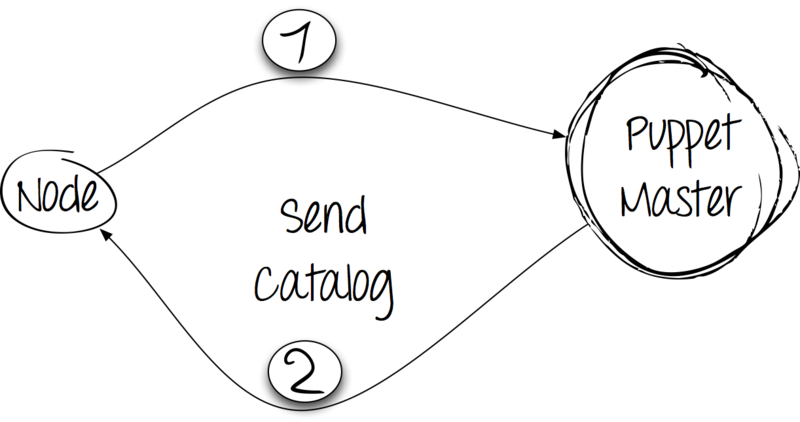
Cервер получает дамп с фактами от клиента и компилирует каталог. При этом он исходит из информации в имеющихся на сервере манифестах, но также учитывает полученые от клиента факты. Каталог отправляется клиенту.
Шаг 3: применение каталога и сообщение о результатах

Получив каталог с сервера, клиент производит изменения в системе. О результатах выполнения сообщает серверу с помощью запроса HTTP POST.
Шаг 4: сбор и хранение отчётов
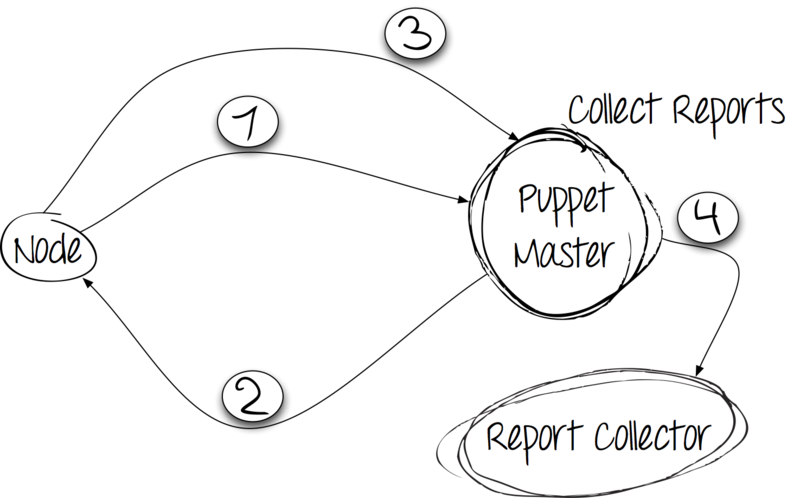
После выполнения клиентом всех правил, отчёт следует сохранить. Puppet предлагает использовать для этого как свои наработки, так и сторонние коллекторы. Пробуем!
Устанавливаем базовый пакет и получаем следующую картину:
На первый взгляд, всё замечательно — поставил и работай. Однако с течением времени картинка становится менее радостной. Количество клиентов увеличивается, системные администраторы пишут манифесты, вследствие которых растут временные затраты на компиляцию кода и обработку каждого клиента.
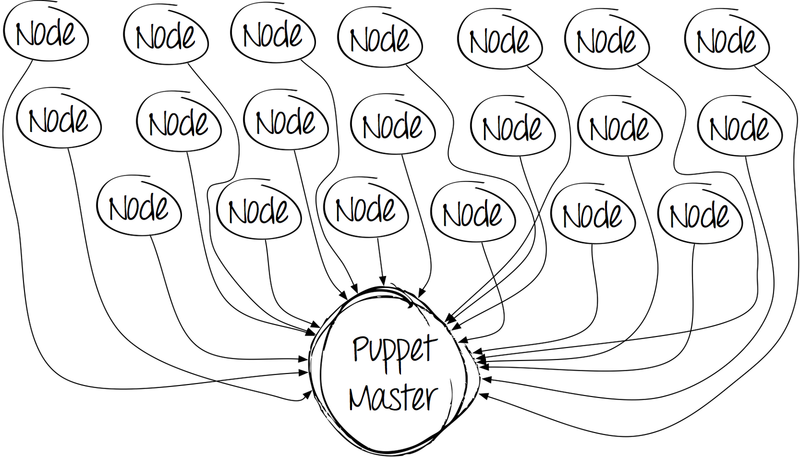
И в определённый момент картина становится совсем уж печальной.
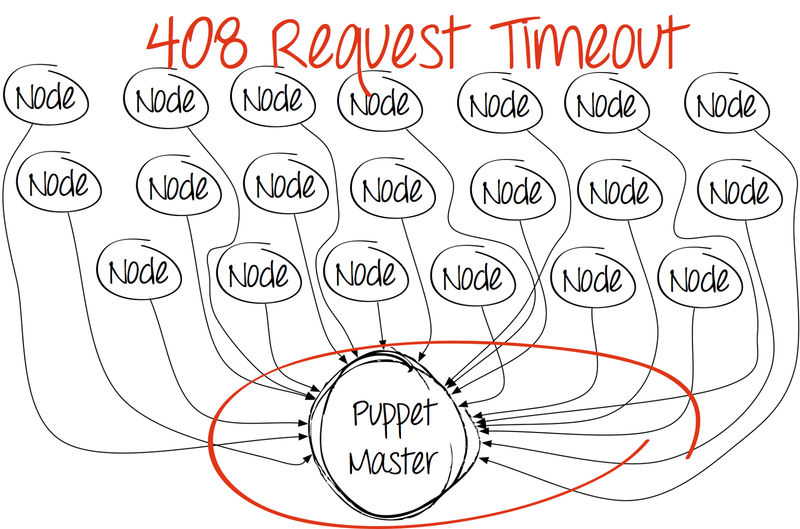
Первое, что приходит в голову — увеличить количество процессов puppet master на сервере. Да, именно потому, что в базовой поставке Puppet этого не умеет, да и по ядрам он не «размазывается».
Есть ли варинаты решения, предложенные производителем? Безусловно, но по разным причинам они оказались неприменимы в наших условиях.
Почему не Apache + mod_passenger? По определённым причинам в нашей компании веб-сервер Apache вообще не используется.
Почему не nginx + passenger? Чтобы избежать необходимости дополнительного модуля в той сборке nginx, которую мы используем.
Тогда что?
Знакомьтесь: Unicorn
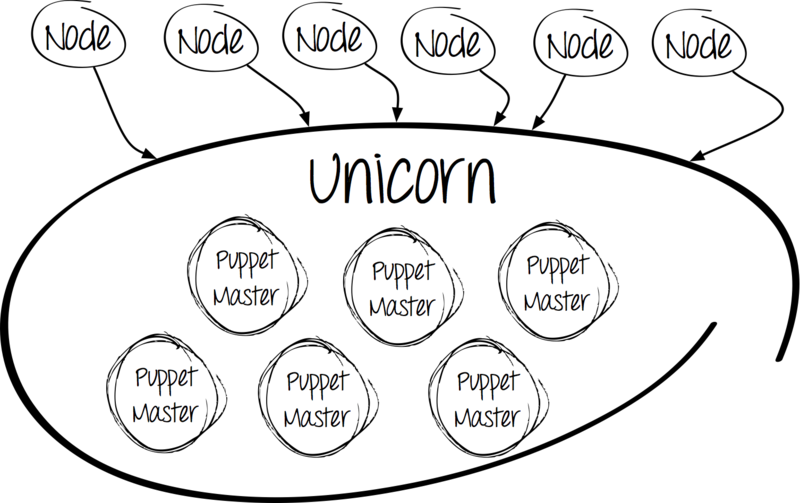
Почему именно Unicorn?
Вот, на наш взгляд, его плюсы:
- балансировка на уровне ядра Linux;
- запуск всех процессов в своем окружении;
- обновление без потери коннектов «nginx-style»;
- возможность слушать на нескольких интерфейсах;
- сходство с PHP-FPM, но для Ruby.
Ещё одной причиной выбора в пользу Unicorn послужила простота его установки и настройки.
worker_processes 12 working_directory "/etc/puppet" listen '0.0.0.0:3000', :backlog => 512 preload_app true timeout 120 pid "/var/run/puppet/puppetmaster_unicorn.pid" if GC.respond_to?(:copy_on_write_friendly=) GC.copy_on_write_friendly = true end before_fork do |server, worker| old_pid = "#{server.config[:pid]}.oldbin" if File.exists?(old_pid) && server.pid != old_pid begin Process.kill("QUIT", File.read(old_pid).to_i) rescue Errno::ENOENT, Errno::ESRCH end end end Итак, хорошая новость: у нас есть возможность запуска нескольких процессов. Но есть и плохая: управлять процессами стало гораздо сложнее. Не страшно — для этой ситуации существует свой «рецепт».
«In God We Trust»
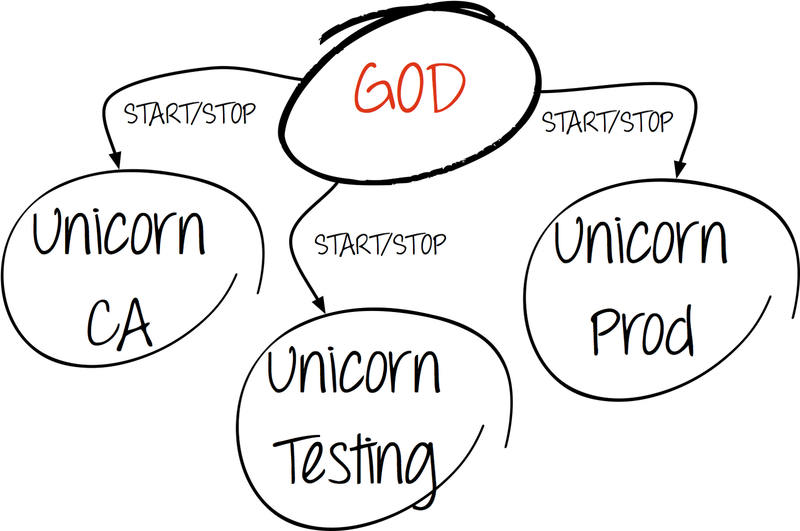
God представляет собой фреймворк для мониторинга процессов. Он прост в настройке и написан на Ruby, как и сам Puppet.
В нашем случае God управляет различными инстансами процессов puppet master:
- production-окружение;
- testing-окружение;
- Puppet CA.
C настройкой особых проблем тоже не возникает. Достаточно создать конфигурационный файл в директории /etc/god/ для обработки файлов *.god.
God.watch do |w| w.name = "puppetmaster" w.interval = 30.seconds w.pid_file = "/var/run/puppet/puppetmaster_unicorn.pid" w.start = "cd /etc/puppet && /usr/bin/unicorn -c /etc/puppet/unicorn.conf -D" w.stop = "kill -QUIT `cat #{w.pid_file}`" w.restart = "kill -USR2 `cat #{w.pid_file}`" w.start_grace = 10.seconds w.restart_grace = 10.seconds w.uid = "puppet" w.gid = "puppet" w.behavior(:clean_pid_file) w.start_if do |start| start.condition(:process_running) do |c| c.interval = 5.seconds c.running = false end end end Обратите внимание, что мы выделили Puppet CA в отдельный инстанс. Сделано это специально, чтобы все клиенты использовали единый источник для проверки и получения своих сертификатов. Немного позже мы расскажем, как этого добиться.
Балансировка
Как уже говорилось, весь процесс обмена информацией между клиентом и сервером происходит по HTTP, значит, нам ничто не мешает настроить простую http-балансировку, прибегнув к помощи nginx.
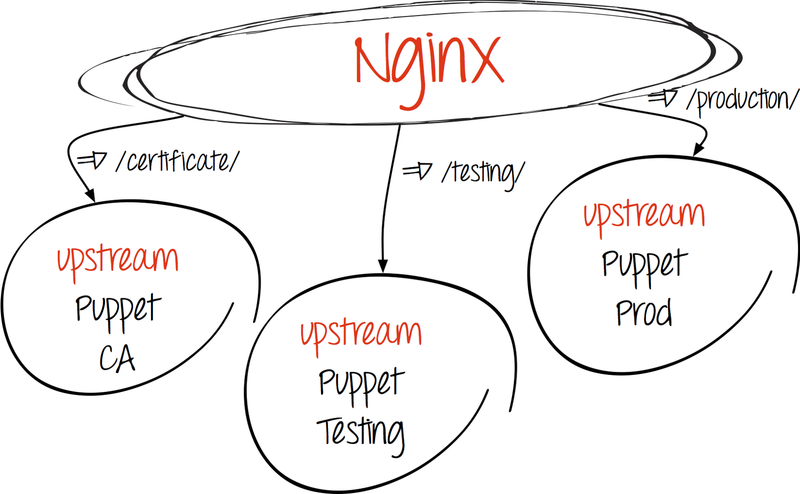
- Создаем upstream:
upstream puppetmaster_unicorn { server 127.0.0.1:3000 fail_timeout=0; server server2:3000 fail_timeout=0; } # для основного процесса puppet master (к примеру, production-окружение) upstream puppetca { server 127.0.0.1:3000 fail_timeout=0; } # для Puppet CA - Перенаправляем запросы к адресатам:
- Puppet CA
location ^~ /production/certificate/ca { proxy_pass http://puppetca; } location ^~ /production/certificate { proxy_pass http://puppetca; } location ^~ /production/certificate_revocation_list/ca { proxy_pass http://puppetca; } - Puppet Master
location / { proxy_pass http://puppetmaster_unicorn; proxy_redirect off; }
- Puppet CA
Подведем промежуточные итоги. Итак, вышеуказанные действия позволяют нам:
- запускать несколько процессов;
- управлять запуском процессов;
- балансировать нагрузку.
А масштабирование?
Технические возможности сервера puppet master не безграничны, и если нагрузки на него становятся предельно допустимыми, то встает вопрос масштабирования.
Эта проблема решается следующим образом:
- RPM-пакет для нашего puppet server хранится в нашем репозитории;
- все манифесты, а также конфигурации для God и Unicorn лежат в нашем Git-репозитории.
Для запуска ещё одного сервера нам достаточно:
- поставить базовую систему;
- установить puppet-server, Unicorn, God;
- клонировать Git-репозиторий;
- добавить машину в upstream.
На этом наш «тюнинг» не заканчивается, поэтому снова вернёмся к теории.
Storeconfigs: что и зачем?
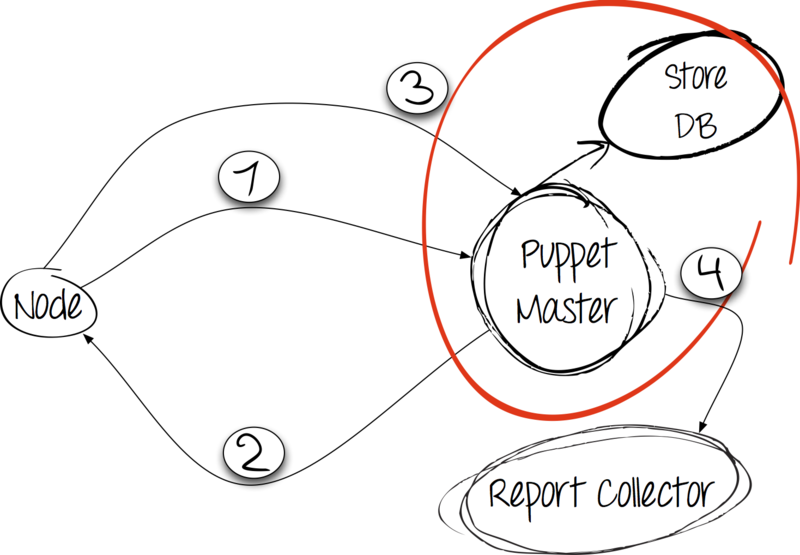
Если клиент присылает нам отчёт и факты о себе, то почему бы не хранить эту информацию?
В этом нам поможет Storeconfigs — опция puppet-server, которая позволяет сохранять актуальную информацию о клиентах в базе данных. Система сравнивает последние данные от клиента с уже имеющимися. Storeconfigs поддерживает следующие хранилища: SQLite, MySQL, PostgreSQL. Мы используем MySQL.
В нашем случае множество клиентов забирают конфигурацию каждые три минуты, примерно столько же присылают отчёты. В итоге мы уже получаем большие очереди на запись в MySQL. А ведь нам предстоит ещё и забирать данные из БД.
Эта проблема получила следующее решение:
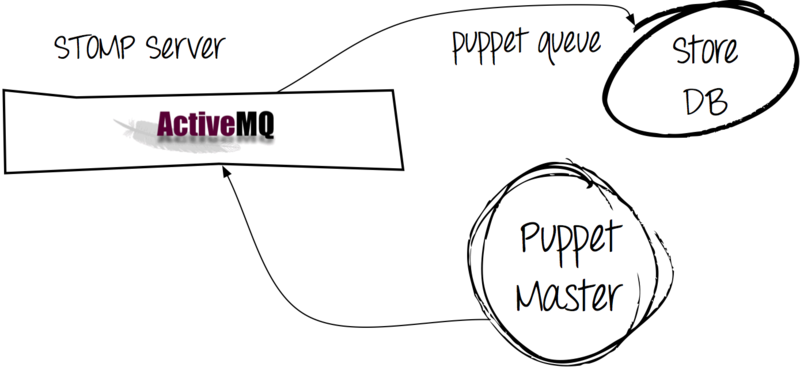
Использование Apache ActiveMQ позволило нам направлять сообщения от клиентов не сразу в БД, а пропускать их через очередь сообщений.
В результате мы имеем:
- более быстрое выполнение puppet-процесса на клиенте, потому что при попытке отправки отчёта на сервер он сразу получает «ОК» (поставить сообщение в очередь проще, чем записать его в базу);
- снижение нагрузки на MySQL (процесс puppet queue записывает данные в базу асинхронно).
Для настройки puppet-server потребовалось дописать в конфигурацию следующие строки:
[main] async_storeconfigs = true queue_type = stomp queue_source = stomp://ACTIVEMQ_address:61613 dbadapter = mysql dbuser = secretuser dbpassword = secretpassword dbserver = mysql-server И не забудем про запуск процесса puppet queue.
Благодаря описанным настройкам Puppet работает на сервере шустро и хорошо, но хорошо бы регулярно мониторить его активность. Настало время вспомнить о Puppet Reports.
Нестандартная отчётность
Что нам предлагается по умолчанию:
- http;
- tagmai;
- log;
- rrdgraph;
- store.
Увы, целиком и полностью нас не устроил ни один из вариантов по одной-единственной причине — отсутствие качественной визуальной составляющей. К сожалению, а может и к счастью, стандартный Puppet Dashboard в тот момент показался нам слишком скучным.
Поэтому мы остановили свой выбор на Foreman, который порадовал нас симпатичными диаграммами с самым необходимым.


На картинке слева мы видим, какое количество времени уходит на применение каждого типа ресурсов. За 360 градусов берется полное время выполнения на клиенте.
Картинка справа отображает количество событий с указанием статуса. В данном примере запущен всего один сервис, более 10 событий пропущено по причине того, что их текущее состояние полностью соответствует эталонному.
И последняя рекомендация: обновиться до версии 3.0.0

График отчётливо показывает выигрыш во времени после обновления. Правда, производительность выросла не на 50%, как обещали разработчики, но прирост оказался вполне ощутимым. После правки манифестов (см. сообщение) мы всё-таки добились обещанных 50%, поэтому наши усилия себя полностью оправдали.
В заключение можно сказать, что при должной настройке Puppet способен справиться с серьёзными нагрузками и управление конфигурацией на 2000 серверов ему вполне по плечу.
Антон [banuchka] Турецкий, системный администратор
Badoo
ссылка на оригинал статьи http://habrahabr.ru/company/badoo/blog/157023/
Добавить комментарий