Коротко о задаче и вводные данные
В кластере нам нужно держать:
- БД нескольких веб-сайтов с пользователями
- БД со статистическими данными этих пользователей
- БД для тикет-систем, систем управления проектами и прочая мелочь
Иными словами, БД практически всех наших проектов, из тех что крутятся у нас на MySQL, теперь должны жить в кластере.
Большинство проектов мы держим удаленно в ДЦ, поэтому и кластер будет находится там.
Задача разнести кластер географически по разным дата-центрам не стоит.
Для построения кластера используются 3 сервера одинаковой конфигурации: HP DL160 G6, 2X Xeon E5620, 24 GB RAM, 4x SAS 300GB в аппаратном RAID 10. Неплохое брендовое железо, которое я использую уже давно и которое меня пока не подводило.
Почему Percona?
— синхронная true multi-master репликация (Galera)
— возможность коммерческой поддержки от Percona
— форк MySQL c внушительным списком оптимизаций
Схема кластера
В кластере 3 ноды, для каждой вышеописанный физический сервер (OS Ubuntu 12.04).
Используется прозрачный коннект к одному виртуальному IP-адресу, разделяемому между всеми 3 серверами при помощи keepalived. Для балансировки нагрузки на ноды используется HAProxy, конечно же установленный на каждом сервере, чтобы в случае отказа одного из них, нагрузку благодаря VIP продолжал балансировать другой. Мы намеренно решили использовать для LB и VIP те же железки, что и для кластера.
Node A используется в качестве Reference (Backup) Node, которую не будут загружать запросами наши приложения. При этом она будет полноправным членом кластера, и участвовать в репликации. Это делается в связи с тем, что в случае сбоя в кластере или нарушения целостности данных мы будем иметь ноду, которая почти наверняка содержит наиболее консистентные данные, которые приложения просто не могли порушить из-за отсутствия доступа. Возможно, это выглядит расточительным расходованием ресурсов, но для нас 99% надежность данных все же важнее чем доступность 24/7. Именно эту ноду мы будем использовать для SST — State Snapshot Transfer — автоматического слива дампа на присоединяемую к кластеру новую ноду или поднимаемую после сбоя. Кроме того, Node A — отличный кандидат для сервера, откуда мы будем снимать стандартные периодические резервные копии.
Схематично это все можно изобразить примерно так:
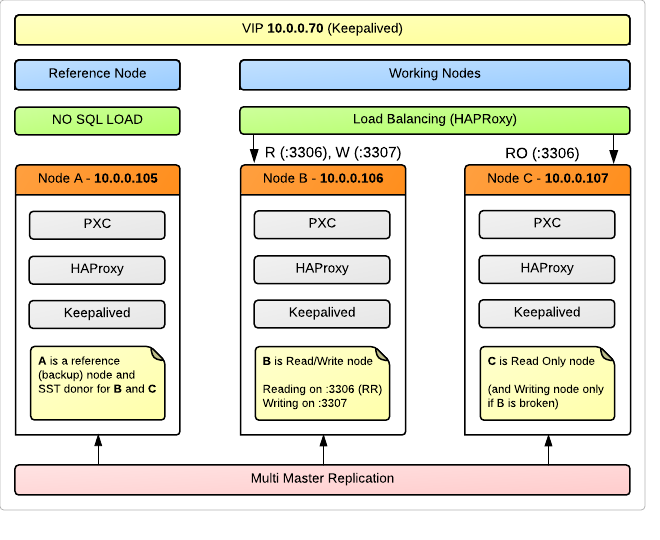
Node B и Node C это рабочие лошадки, которые держат нагрузку, но при этом операции записи берет на себя только одна из них. Такова рекомендация многих специалистов, и ниже я остановлюсь на этом вопросе подробно.
Детали балансировки
Запросы, приходящие на порт 3306, HAProxy раскидывает по Round Robin между нодами B и C.
То, что приходит на 3307, проксируется только на Node B. При этом если Node B вдруг упадет, запросы перейдут на указанную в качестве резервной Node C.
Для реализации нашей идеи (писать только на одну из нод) приложения должны быть написаны так, чтобы запросы на чтение шли через соединение с 10.0.0.70:3306 (10.0.0.70 — наш VIP), а запросы на запись направлялись на 10.0.0.70:3307.
В нашем случае это потребует некоторой работы по созданию в конфиге PHP приложения нового коннекта, и замене имени переменной-DBHandler на другое значение. В целом, это не так сложно для тех приложений, которые написаны нами. Для сторонних проектов, чьи базы тоже будут в кластере, мы просто укажем порт 3307 по умолчанию. Нагрузку эти проекты создают небольшую, и потеря возможности распределенного чтения не так критична.
Конфиг HAProxy (/etc/haproxy/haproxy.cfg):
global log 127.0.0.1 local0 log 127.0.0.1 local1 notice maxconn 4096 chroot /usr/share/haproxy daemon defaults log global mode http option tcplog option dontlognull retries 3 option redispatch maxconn 2000 contimeout 5000 clitimeout 50000 srvtimeout 50000 frontend pxc-front bind 10.0.0.70:3306 mode tcp default_backend pxc-back frontend stats-front bind *:81 mode http default_backend stats-back frontend pxc-onenode-front bind 10.0.0.70:3307 mode tcp default_backend pxc-onenode-back backend pxc-back mode tcp balance leastconn option httpchk server c1 10.0.0.106:33061 check port 9200 inter 12000 rise 3 fall 3 server c2 10.0.0.107:33061 check port 9200 inter 12000 rise 3 fall 3 backend stats-back mode http balance roundrobin stats uri /haproxy/stats stats auth haproxy:password backend pxc-onenode-back mode tcp balance leastconn option httpchk server c1 10.0.0.106:33061 check port 9200 inter 12000 rise 3 fall 3 server c2 10.0.0.107:33061 check port 9200 inter 12000 rise 3 fall 3 backup backend pxc-referencenode-back mode tcp balance leastconn option httpchk server c0 10.0.0.105:33061 check port 9200 inter 12000 rise 3 fall 3 Для того, чтобы HAProxy мог определить жив ли узел кластера, используется утилита clustercheck, (входит в пакет percona-xtradb-cluster), которая выводит сведения о состоянии ноды (Synced / Not Synced) в виде HTTP ответа. На каждом из узлов должен быть настроен xinetd сервис:
/etc/xinetd.d/mysqlchk
service mysqlchk. { disable = no flags = REUSE socket_type = stream port = 9200 wait = no user = nobody server = /usr/bin/clustercheck log_on_failure += USERID only_from = 0.0.0.0/0 per_source = UNLIMITED } /etc/services
... # Local services mysqlchk 9200/tcp # mysqlchk HAProxy поднимает веб-сервер и предоставляет скрипт для просмотра статистики, что очень удобно для визуального мониторинг состояния кластера.
URL выглядит так:
http://VIP:81/haproxy/stats
Порт, а также логин и пароль для Basic авторизации указываются в конфиге.
Хорошо рассмотрен вопрос настройки кластера с балансировкой через HAProxy здесь: www.mysqlperformanceblog.com/2012/06/20/percona-xtradb-cluster-reference-architecture-with-haproxy/
Конфигурация нод
На хабре уже есть статья об установке и тестировании PXC: habrahabr.ru/post/152969/, где оба вопроса рассмотрены подробно, поэтому на установку я опускаю. Но опишу конфигурирование.
В первую очередь, не забудьте синхронизировать время на всех нодах. Я упустил этот момент, и довольно долго не мог понять, почему у меня намертво подвисает SST — он начинался, висел в процессах, но по факту ничего не происходило.
my.cnf на Node A (в моих конфигах это node105):
[mysqld_safe] wsrep_urls=gcomm://10.0.0.106:4567,gcomm://10.0.0.107:4567 # wsrep_urls=gcomm://10.0.0.106:4567,gcomm://10.0.0.107:4567,gcomm:// # закомментированый параметр - тот, что нужно использовать # при инициализации кластера, т.е. первом запуске первой ноды # это важный момент, и он будет рассмотрен ниже [mysqld] port=33061 bind-address=10.0.0.105 datadir=/var/lib/mysql skip-name-resolve log_error=/var/log/mysql/error.log binlog_format=ROW wsrep_provider=/usr/lib/libgalera_smm.so wsrep_slave_threads=16 wsrep_cluster_name=cluster0 wsrep_node_name=node105 wsrep_sst_method=xtrabackup wsrep_sst_auth=backup:password innodb_locks_unsafe_for_binlog=1 innodb_autoinc_lock_mode=2 innodb_buffer_pool_size=8G innodb_log_file_size=128M innodb_log_buffer_size=4M innodb-file-per-table Дальше — только отличающиеся параметры:
Node B (node106)
[mysqld_safe] wsrep_urls=gcomm://10.0.0.105:4567 [mysqld] bind-address=10.0.0.106 wsrep_node_name=node106 wsrep_sst_donor=node105 Node C (node107)
[mysqld_safe] wsrep_urls=gcomm://10.0.0.105:4567 [mysqld] bind-address=10.0.0.106 wsrep_node_name=node106 wsrep_sst_donor=node105 В последних двух конфигах мы недвусмысленно сообщаем серверу, где нужно искать первую ноду в кластере (которая знает где живут все члены группы), и что именно с нее, а не с другой из доступных, нужно забирать данные для синхронизации.
Именно на такой конфигурации я остановился сейчас, и собираюсь постепенно переводить проекты в кластер. Планирую продолжить писать о своем опыте и дальше.
Проблемные вопросы
Обозначу здесь вопросы, на которые я далеко не сразу нашел ответ, но ответ на которые особенно важен для понимая технологии и правильной работы с кластером.
Почему рекомендуется писать на одну ноду из всех доступных в кластере? Ведь казалось бы, это противоречит идее мульти-мастер репликации.
Когда я впервые увидел эту рекомендацию, то очень расстроился. Я представлял себе multi-master таким образом, что можно ни о чем не заботясь писать на любой узел, и изменения гарантированно применятся синхронно на всех нодах. Но суровые реалии жизни таковы, что при таком подходе возможно повление cluster-wide deadlocks. Особенно велика вероятность в случае параллельного изменения одних и тех же данных в длинных транзакциях. Т.к. я не являюсь пока экспертом в этом вопросе, не могу объяснить этот процесс на пальцах. Но есть хорошая статья, где эта проблема освещена подробнейшим образом: Percona XtraDB Cluster: Multi-node writing and Unexpected deadlocks
Мои собственные тесты показали, что при агрессивной записи на все ноды они ложились одна за другой, оставляя рабочей только Reference Node, т.е. по факту можно сказать, что кластер прекращал работу. Это, безусловно минус такой конфигурации, ведь третий узел мог бы в этом случае взять нагрузку на себя, но зато мы уверены, что данные там в целости и сохранности и в самом крайнем случае мы можем вручную запустить его в работу в режиме одиночного сервера.
Как правильно указать IP адреса существующих в кластере нод при подключении новой?
Для этого есть 2 директивы:
[mysqld_safe] wsrep_urls [mysqld] wsrep_cluster_addressПервая, если я правильно понял, была добавлена Galera сравнительно недавно для возможности указать сразу несколько адресов нод. Больше принципиальных отличий нет.
Значения этих директив поначалу у меня вызвали особую путаницу.
Дело в том, что многие мануалы советовали на первой ноде кластера оставлять пустое значение gcomm:// в wsrep_urls.
Оказалось, что это неправильно. Наличие gcomm:// означает инициализацию нового кластера. Поэтому сразу после старта первой ноды в ее конфиге нужно удалять это значение. В противном случае после рестарта этого узла вы получите два разных кластера, один из которых будет состоять только из первой ноды.Для себя я вывел порядок конфигурации при запуске и перезапуске кластера (уже описанный выше более подробно)
1. Node A: запуск c gcomm://B,gcomm://C,gcomm://
2. Node A: удаление gcomm:// в конце строки
3. Nodes B,C: запуск с gcomm://ANB: нужно обязательно указывать номер порта для Group Communication запросов, по умолчанию это 4567. То есть, правильная запись: gcomm://A:4567
Можно ли с неблокирующим xtrabackup в качестве SST method писать на ноду-донор?
Во время SST clustercheck на доноре будет выводить HTTP 503, соответственно для HAProxy или другого LB, который использует эту утилиту для определения статуса, нода-донор будет считаться недоступной, равно как и нода, на которую делается трансфер. Но это поведение можно изменить правкой clustercheck, который по сути обычный bash-скрипт.
Это делается следующей правкой:/usr/bin/clustercheck
#AVAILABLE_WHEN_DONOR=0 AVAILABLE_WHEN_DONOR=1NB: заметьте, что делать так можно только в том случае, когда вы уверены что в качестве SST используется xtrabackup, а не какой-то другой метод. В нашем же случае, когда мы используем в качестве донора ноду, лишенную нагрузки, подобная правка вообще не имеет смысла.
Полезные ссылки
Percona XtraDB Cluster
XtraDB Cluster on mysqlperfomanceblog.com
Percona Community Forums
Percona Discussion Google group
Galera Wiki
ссылка на оригинал статьи http://habrahabr.ru/post/158377/
Добавить комментарий