Продолжаю разговор об оптимизации приложений, начатый здесь в посте «Существует ли простая оценка качества оптимизации приложения?».
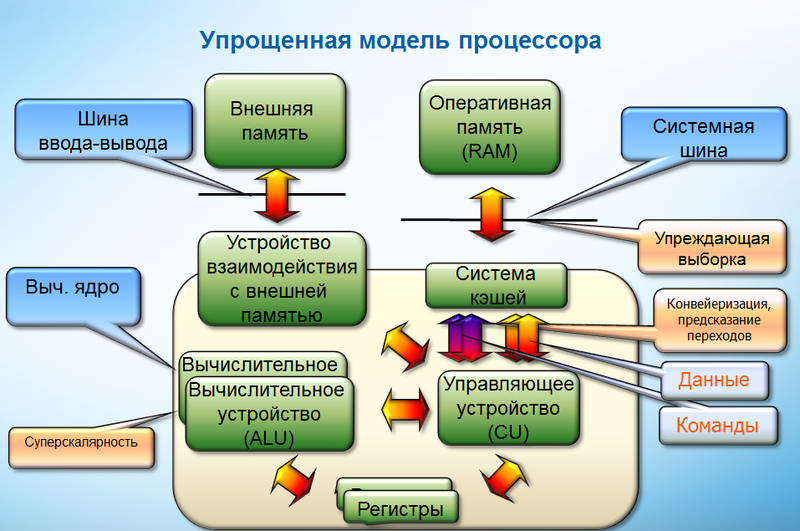
Про процессоры можно говорить много и подробно и, наверняка, среди читателей Хабра есть масса людей спопобных на такие разговоры. Но моя точка зрения на процессор сугубо прагматичная. Поскольку меня интересует производительность приложения, через призму производительности процессора, то мне достаточно понимания базовых принципов работы вычислительного ядра. А также методов, которые существуют, чтобы на эти базовые принципы воздействовать. Буду я ориентироваться на архитектуру Intel64. Это вызвано тем, что в нашей команде анализа производительности мы занимаемся анализом работы оптимизирующего компилятора Intel, в основном, именно для этой архитектуры. На рынке вычислительных систем для высокопроизводительных вычислений эта и совместимые архитектуры занимают львинную долю, поэтому большинство проблем производительности имеет довольно общую природу. Давайте я коротко перечислю те основные проблемы и возможности, которые определяют производительность ядра и вычислительной системы и предложу короткий список различных оптимизаций, призванных влиять на эти проблемы.
Уровень инструкционного параллелизма
Современное вычислительное ядро характеризуют наличие конвейера (pipelining), суперскалярности. Вычислительное ядро обладает механизмом для определения независимых команд и планирования инструкций. Т.е. эти механизмы просматривают буфер прибывших на обработку инструкций и выбирают их для исполнения, если есть подходящие вычислительные мощности и инструкции не зависят от других еще не выполненных инструкций. Таким образом для Intel64 архитектуры характерено внеочередное исполнение команд (out-of-order execution). Т.е. для такой архитектуры компилятору не нужно заниматься детальным определением порядка инструкций. Уровень загрузки конвейера будет определяться тем, насколько много независимых инструкций попадает на обработку, так называемым уровнем инструкционного параллелизма.
Количество условных переходов и качество работы предсказателя переходов
Порядок выполнения различных команд определяется графом потока управления, который связывает прямолинейные участки кода. В местах где происходит ветвление потока управления используются, как правило, различные условные переходы. Т.е до момента вычисления условия, непонятно какая инструкция должна выполняться следующей. Для того, чтобы работа конвейера не прерывалась, в вычислительном ядре существует механизм предсказания ветвления, который выбирает один из возможных путей передачи управления и продолжет доставлять на вычислительный конвейер инструкции с этого направления. Уже выполненные инструкции дожидаются валидации, которая происходит после вычисления условия. Если же предсказатель ошибся, то происходит задержка в работе вычислительного ядра, вызванная необходимостью очистить буфера вычислительного ядра и загрузить в них новые инструкции. Такая ситуация называется ошибкой предсказания (branch misprediction). Механизм предсказания ветвления довольно сложен и включает как статическую часть, которая делает попытку угадать направление при первой встрече с условным переходом, так и динамическую, накапливающую и использующую статистику.
Качество работы подсистемы памяти
Поскольку все основные данные и инструкции располагаются в оперативной памяти, то для производительности важно, за какое время эти данные могут быть доставлены в вычислительное устройство. В данном случае, задержка на получение данных из основной памяти составляет сотни процессорных циклов. Чтобы ускорить работу процессор распологает кэшем или подсистемой кэшей. Кэш хранит копии часто используемых данных из основной памяти. Для современных многоядерных процессоров типична ситуация, когда ядро владеет кэшем первого и второго уровня, а процессор имеет также кэш третьего уровня, который ядра используют совместно. Кэш первого уровня самый маленький по размерам и быстрый, кэши верхней иерархии медленнее, но больше. Процессоры архитектуры Intel64 имеют инклюзивный кэш. Это значит, что если какой-то адрес представлен в кэше какого-либо уровня, то он содержится и в кэшах верхней иерархии. Поэтому при необходимости получения данных из памяти, подсистема памяти последовательно проверяет наличие адресов в кэше первого, второго и третьего уровня. В случае промаха по кэшу (т.е. отсутствии необходимой информации в кэше) в каждом последующем случае задержка будет больше. Например, для Nehalemа приблизительное время доступа к кэшам разного уровня будет следующим: 4 для кэша первого уровня и соответственно 11 и 38 для кешей второго и третьего уровня. Задержка при доступе к оперативной памяти составляет приблизительно от 100 до 200 циклов. Для понимания работы подсистемы памяти важен факт, что передача и хранение необходимой информации в кэше происходит пакетами фиксированной длины, которые называются кэш линиями и составляют (пока?) 64 байта. При запросе определенного адреса памяти в кэш загружаются «попутно» какие-то «соседние» данные. Системная шина осуществляет передачу данных между подсистемой кэшей и CPU. Важной характеристикой подсистемы памяти является пропускная способность шины, т.е. сколько кэш линий может быть передано в кэш за единицу времени. Соответственно, работа системной шины часто становится «узким местом» при выполнении приложения.
В связи с такой организации кэша большую роль играет такой фактор как принцип локальности (locality of reference) используемых программой данных. Различают временную локальность (temporal locality), характеризующую переиспользование в процессе работы приложения основных объектов и данных и пространственную локальность (spatial locality) – использование данных, имеющих относительно близкие области хранения. И в вычислительном ядре реализованы механизмы для поддержки принципа локальности. Временную локальность поддерживает механизм кэширования, который стремиться сохранять в кэшах наиболее часто используемые данные. Когда встает вопрос о необходимости освободить кэш линию для загрузки новой, то удаляется та линия, которая не использовалась наибольшее время. На пространственную локальность работает механизм упреждающей выборки, который стремиться определить заранее адреса памяти, которые потребуются для последующей работы. При этом, чем выше пространственная локальность, (идет доступ к соседним элементам), тем меньше данных нужно закачивать в кэш, тем меньше нагрузка на системную шину.
Можно также здесь упомянуть регистры вычислительного ядра, как наибыстрейшую память. Выгодно в регистрах хранить переиспользуемые данные. Существует такая проблема производительности как вытеснение регистров (register spilling), когда при вычислениях постоянно идет копирование данных из регистров на стек и обратно.

Использование векторизации
Процессоры архитектуры intel64 поддерживают векторные инструкции. Т.е. существует возможность создания векторов различных типов и применение к ним инструкций работающих с векторами и получающих на выходе вектор результатов. Это инструкции семейства SSE. Набор инструкций развивается, дополняется новыми командами и возможностями. SSE2, SSE3, SSE4, AVX – расширения первоначальной идеи. Проблема заключается в том, что языки программирования у нас изначально скалярные и нужно делать определенные усилия, чтобы использовать эту возможность вычислительных ядер. Векторизация — это модификация кода, которая заменяет скалярный код на векторный. Т.е. скалярные данные упаковываются в вектора и скалярные операции заменяются на операции с векторами (пакетами). Можно использовать xmmintrin.h для программирования векторизации вручную, использовать какой-то оптимизирующий компилятор с автовекторизацией или оптимизированные библиотеки с утилитами, использующими векторные инструкции. Существует масса ограничений на возможность применения этой модификации. К тому-же есть много факторов определяющих ее выгодность. Поэтому я и написал модификация, поскольку оптимизация – это то, что улучшает производительность. Чтобы векторизация ее улучшала, необходимо выполнение некоторых условий. Т.е. векторизация – это всего лишь «возможность». Нужно потрудиться чтобы воплотить эту возможность в реальные достижения.
Использование многопотоковых вычислений
Наличие нескольких вычислительных ядер на современном процессоре дает возможность достижения высокой производительности приложения распределением вычислений между этими ядрами. Но и это всего лишь «возможность». Наличие миллиона высокопрофессиональных программистов не дает надежды на то, что они смогут реализовать оптимизирующий компилятор за час. Преобразование однопоточного кода в многопоточный требует серьезных усилий. Некоторые оптимизирующие компиляторы имеют автопараллелизатор, который сводит процесс создания многопоточного приложения к процессу добавления одной опции при компиляции. Но на пути автопараллелизатора столько подводных камней, что во многих случаях оптимизирующему компилятору требуется помощь, а во многих он просто бессилен. Больших успехов можно достичь используя OpenMP директивы. Но в большинстве случаев требуются усилия для того, чтобы распараллелить изначально однопоточный алгоритм. Другие методы параллелизации я не буду здесь упоминать, поскольку они связаны, на мой взгляд, с серьезными изменениями алгоритмов вычисления и лежат за рамками того, что можно назвать неалгоритмической оптимизацией кода.
На основе перечисленных проблем можно выделить 3 основных характеристики определяющих производительность выполняемого приложения и 2 большие возможности, которые могут быть реализованы:
1.) Качество работы подсистемы памяти.
2.) Количество условных переходов и качество работы предсказателя переходов.
3.) Уровень инструкционного параллелизма.
4.) Использование векторизации.
5.) Использование многопотоковых вычислений.
Оптимизации
Какие существуют средства у компилятора и у программиста, чтобы воздействовать на перечисленные характеристики вычисления?
Улучшить работу подсистемы памяти призваны многие цикловые оптимизации, такие как перестановка циклов, разбиение циклов на блоки (loop blocking), объединение и разбиение циклов (loop fusion/distribution). У этих оптимизаций есть недостаток. Не все циклы подходят для таких оптимизаций и в основном они встречаются в вычислительных программах на C и фортране. Компилятор может попытаться помочь механизму упреждающей выбоки и автоматически вставить програмные инструкции предвыборки, но опять же – это очень специализированная операция, требующая благоприятного расположения звезд. Если строится исполняемый модуль, то с динамическим профилировщиком компилятор умеет улучшать пространственную локальность данных приложения за счет перестановки полей структур и выноса холодных областей в отдельные структуры. Есть даже такая оптимизация, как перенос полей из одной структуры в другую. Компилятору достаточно трудно доказать корректность и выгодность таких оптимизаций, но программисту делать такие вещи гораздо легче, главное понимать в чем идея той или иной модификации кода.
Важную роль в улучшении локальности данных могут играть скалярные оптимизации, т.е. оптимизации занимающиеся анализом потока данных, протяжкой констант, оптимизацией графа управления, удалением общих подвыражений, удаление мертвого кода. Эти оптимизации сокращают количество вычислений, которые необходимо выполнить приложению. В результате сокращается количесво инструкций и улучшается локальность данных, поскольку инструкции так-же нужно хранить в кэше. Качество выполнения этих оптимизационных методов можно назвать эффективностью вычислений. Всем этим оптимизациям помогает межпроцедурный анализ. В случае его использования, анализ потока данных становится глобальным, т.е. анализируется перенос свойств объектов не только на уровне конкретной обрабатываемой компилятором процедуры, но и внутри всей программы. Изучаются и используются внутри процедуры свойства конкретных аргументов, с которыми эта процедура вызывалась из разных мест приложения, изучаются свойства глобальных объектов, для каждой функции создается список объектов, которые могут быть использованы или модифицированы внутри этой функции, и т. д. Подстановка тела функции (inlining) и частичная подстановка так-же может положительно сказаться на локальности данных. Многие из вышеперечисленных оптимизаций уже не сделаешь руками, поскольку эффект от каждой протянутой константы может быть мизерным, но в итоге протяжка констант дает хороший суммарный эффект и зачастую дает возможность применять и более правильно оценивать эффект от более сложных оптимизаций.
Кроме того, оптимизирующий компилятор много внимания уделяет распределению регистров.
Оптимизирующий компилятор может выполнять определенные действия и для снижения количества условных переходов и качества работы предсказателя переходов. Самое тривиальное — улучшение работы статического предсказателя ветвления за счет изменения условия при котором происходит переход. Статический предсказатель исходит из того, что если при ветвлении графа управления возможен переход вниз, то он не будет выполнен. Если компилятор считает, что вероятность ветки if меньше, чем для else, то он может поменять их местами. Очень сильной оптимизацией является вынос инвариантной проверки из циклов. Еще одна известная оптимизация — развертка циклов (loop unrolling). Существует полезная скалярная оптимизация, которая протягивает по графу управления условия, что позволяет удалять излишние проверки, объединять их и упрощать граф управления. Также компилятор способен распознавать определенные паттерны и заменять ветвления на использования инструкций типа cmov. Наверное, можно привести еще примеры, но и этот показывает, что оптимизирующий компилятор имеет методы для борьбы с задержками из-за неправильных предсказаний.
Для улучшения инструкционного параллелизма служит планирование (scheduling), выполняемое на последних стадиях работы компилятора при кодогенерации.
Для улучшения производительности приложения за счет использования векторизации в нашем компиляторе существует автоматический векторизатор, выполняющий векторизацию циклов и заменяющего скалярный код на векторный. Этот компонент компилятора все время находится в развитии, реализуя новые возможности векторных расширений, увеличивая количество распознаваемых идиом, векторизуя циклы со смешанными данными и т. п. Кроме того, векторизатор вставляет в код различные проверки времени выполнения и создает многоверсионный код, поскольку эффективность векторизации завистит от количества итераций в цикле, от расположения различных объектов в памяти, от используемого мультимедийного расширения. Для более эффективной работы необходимо взаимодействие векторизатора с другими цикловыми оптимизациями. Компилятору не всегда удается доказать допустимость векторизации, поэтому поддерживаются различные директивы, для того чтобы программист мог использовать свои знания о программе и помочь создавать производительный код.
Компилятор Intel предлагает разработчикам использовать автопараллелизацию – механизм автоматического распараллеливания циклов. Это, по сути, самый дешевый в плане затрат труда способ создать многопоточное приложение – запустить построение приложения со специальной опцией. Но с точки зрения оптимизируещего компилятора это непростая задача. Необходимо доказать допустимость оптимизации, необходимо правильно оценить объем работы, выполняемой внутри цикла, чтобы решение о параллелизации улучшило производительность. Автоматическая параллелизация так же как и автовекторизация должна взаимодействовать с другими цикловыми оптимизациями. Наверное, в этой области наилучшие оптимизационные алгоритмы еще не написаны, и простор для экспериментов и новаторских идей по прежнему велик. Для развития более наглядных для программистов методов параллелизации создаются новые языковые расширения и различные библиотеки поддержки, такие как CILK+ или Threading Building Blocks. Ну и добрый и проверенный OPENMP тоже рано сбрасывать со счетов.
Заключение:
В предыдущем посте я высказал мысль, что не существует простого критерия для понимания того, насколько хорошо оптимизировано приложение. Это происходит от того, что существует масса различных оптимизаций производительности, которые можно использовать только при выполнении определенных условий. Выполнены ли эти условия, есть ли возможность сделать ту или иную оптимизацию – разобраться в этом вопросе и нужно в процессе анализа производительности приложения. Поэтому, на мой взгляд, анализ производительности приложения сводится к выявлению критических для производительности учасков приложения, определению причин возможных задержек в работе процессора на этих участках, попыток определить возможно ли применение оптимизаций, воздействующих на выявленную причину, определение возможности улучшения производительности приложения за счет векторизации и параллелизации.
Векторизуется ли vector (маленький пример анализа)
Иногда даже одно и то же приложение может показать совершенно удивительные результаты при анализе производительности. Вот, например, зададимся вопросом векторизуется ли vector? Рассмотрим вот такой тест:
#include using namespace std;
int main ()
{
vector myvector;
vector::iterator it;
for(int j=0; j<1000; j++) {
it = myvector.end();
it = myvector.insert ( it, j );
}
for (int i=1; i < myvector.size(); ++i)
myvector[i]++;
printf("%f\n",myvector[0]);
return 0;
}
Я использую интеловский компилятор интегрированный в VS2008 для компиляции данного текста. В данном случае меня интересует вопрос, а весторизуется ли цикл в 14 строке кода. Используем опцию –Qvec_report3, чтобы посмотреть отчет автовекторизатора:
icl -Qvec_report3 -Qipo -Qansi_alias vector.cpp
Intel® C++ Intel® 64 Compiler XE for applications running on Intel® 64, Version Mainline Beta Build x
…
…\vector.cpp(14): (col. 30) remark: loop was not vectorized: unsupported loop structure.
…
Теперь я использую тот-же компилятор, но уже интегрированный в VS2010.
icl -Qvec_report3 -Qipo -Qansi_alias vector.cpp
…
…\vector.cpp(14): (col. 30) remark: LOOP WAS VECTORIZED.
…
Я здесь не буду рассказывать о том, какими путями можно докопаться здесь до причины разного поведения компилятора при компиляции одной и той же программы. (Можно посмотреть ассемблер, можно препроцессированный код). Поскольку интеловский компилятор интегрируется в разные версии VS, то в данном случае используются разные версии STL библиотеки. В версии STL VS2008 оператор [] содержит проверку выхода за границы массива. В результате, внутри цикла появляется вызов процедуры __invalid_parameter_noinfo с выходом из программы и компилятор не в состоянии векторизовать такой цикл. А в VS2010 такой проверки уже нет. Интересно почему?
Забавно, что если убрать опцию –Qansi_alias, то векторизация тоже пропадает. То же самое происходит, если создавать вектор для хранения целых чисел, а не вещественных. Но причины этих «чудес» повод для отдельной статьи.
Первоисточники
Литература по исследованию различных вопросов производительности: The Software Optimization Cookbook, Second Edition или The Software Vectorization Handbook.
Базовые источники по различным техникам оптимизаций: Randy Allen, Ken Kennedy. Optimizing compilers for modern architectures, а также David F. Bacon, Susan L. Graham, Oliver J. Sharp. Compiler transformations for High-Performance Computing.
Для программистов, заинтересованных в программном улучшении кода, можно рекомендовать книгу Agner Fog, Optimizing software in C++: An optimization guide for Windows, Linux and Mac platforms.
Не постеснялся скопировать какие-то мысли из своей статьи «Оптимизирующие компиляторы» в журнале «Открытые системы».
ссылка на оригинал статьи http://habrahabr.ru/company/intel/blog/158759/
Добавить комментарий