Сегодня хотелось бы провести обзор такой интересной новой фичи в Windows Server 2012 как дедупликация данных (volume deduplication). Фича крайне интересная, но все же сначала нужно разобраться насколько она нужна…
А нужна ли вообще деупликация?
С каждым годом (если не днем) объемы жестких дисков растут, а при этом носители сами еще и дешевеют.
Исходя из этой тенденции возникает вопрос: «А нужна ли вообще дедупликация данных?».
Однако, если мы с вами живем в нашей вселенной и на нашей планете, то практически все в этом мире имеет свойство подчиняться 3-му закону Ньютона. Может аналогия и не совсем прозрачная, но я подвожу к тому, что как бы не дешевели дисковые системы и сами диски, как бы не увеличивался объем самих носителей — требования с точки зрения бизнеса к доступному для хранения данных пространства постоянно растут и тем самым нивелируют увеличение объем и падение цен.
По прогнозам IDC примерно через год в суммарном объеме будет требоваться порядка 90 миллионов терабайт. Объем, скажем прямо, не маленький.
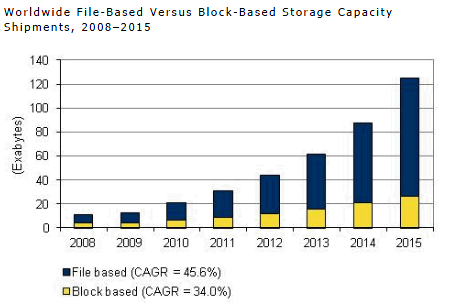
И вот тут как раз вопрос о дедупликации данных очень сильно становится актуальным. Ведь данные, которые мы используем бывают и разных типов, и назначение у них могут быть разные — где-то это production-данные, где-то это архивы и резервные копии, а где-то это потоковые данные — я специально привел такие примеры, поскольку в первом случае эффект от использования дедупликации будет средним, в архивных данных — максимальным, а в случае с потоковыми данным — минимальным. Но все же экономить пространство мы с вами сможем, тем более что теперь дедупликация — это удел не только специализированных систем хранения данных, но и компонент, фича серверной ОС Windows Server 2012.
Типы дедупликации и их применение
Прежде чем перейти к обзору самого механизма дедупликации в Windows Server 2012, давайте разберемся какие типы дедупликации бывают. Предлагаю начать сверху-вниз, на мой взгляд так оно будет нагляднее.
1) Файловая дедупликация — как и любой механизм дедупликации, работа алгоритма сводится к поиску уникальных наборов данных и повторяющихся, где вторые типы наборов заменяются ссылками на первые наборы. Иными словами алгоритм пытается хранить только уникальные данные, заменяя повторяющиеся данные ссылками на уникальные. Как нетрудно догадаться из названия данного типа дедупликации — все подобные операции происходят на уровне файлов. Если вспомнить историю продуктов Microsoft — то данный подход уже неоднократно применялся ранее — в Microsoft Exchange Server и Microsoft System Center Data Protection Manager — и назывался этот механизм S.I.S. (Single Instance Storage). В продуктах линейки Exchange от него в свое время отказались из соображений производительности, а вот в Data Protection Manager этот механизм до сих пор успешно применяется и кажется будет продолжать это делать. Как нетрудно догадаться — файловый уровень самый высокий (если вспомнить устройство систем хранения данных в общем) — а потому и эффект будет самый минимальный по сравнению с другими типами дедупликации. Область применения — в основном применяется данный тип дедупликации к архивным данным.
2) Блочная дедупликация — данный механизм уже интереснее, поскольку работает он суб-файловом уровне — а именно на уровне блоков данных. Такой тип дедупликации, как правило характерен для промышленных систем хранения данных, а также именно этот тип дедупликации применяется в Windows Server 2012. Механизмы все те же, что и раньше — но уровне блоков (кажется, я это уже говорил, да?). Здесь сфера применения дедупликации расширяется и теперь распространяется не только на архивные данные, но и на виртуализованные среды, что вполне логично — особенно для VDI-сценариев. Если учесть что VDI — это целая туча повторяющихся образов виртуальных машин, в которых все же есть отличия друг от друга (именно по этому файловая дедупликация тут бессильна) — то блочная дедупликация — наш выбор!
3) Битовая дедупликаия — самый низкий (глубокий) тип дедупликации данных — обладает самой высокой степенью эффективности, но при этом также является лидером по ресурсоемкости. Оно и понятно — проводить анализ данных на уникальность и плагиатичность — процесс нелегкий. Честно скажу — я лично не знаю систем хранения данных, которые оперируют на таком уровне дедупликации, но я точно знаю что есть системы дедупликации трафика, которые работают на битовом уровне, допустим тот же Citrix NetScaler. Смысл подобных систем и приложений заключается в экономии передаваемого траффика — это очень критично для суенариев с территориально-распределенными организациями, где есть множество разбросанных географически отделений предприятия, но отсутствуют или крайне дороги в эксплуатации широкие каналы передачи данных — тут решения в области битовой дедупликации найдут себя как нигде еще и раскрою свои таланты.
Очень интересным в этом плане выгляди доклад Microsoft на USENIX 2012, который состоялся в Бостоне в июне месяце. Был проведен достаточно масштабный анализ первичных данных с точки зрения применения к ним механизмов блочной дедупликации в WIndows Server 2012 — рекомендую ознакомиться с данным материалом.
Вопросы эффективности
Для того, чтобы понять насколько эффективны технологии дедупликации в Windows Server 2012, сначала нужно определить на каком типе данных эту самую эффективность следует измерять. За эталоны были взяты типичные файловые шары, документы пользователей из папки «Мои документы», Хранилища дистрибутивов и библиотеки и хранилища виртуальных жестких дисков.
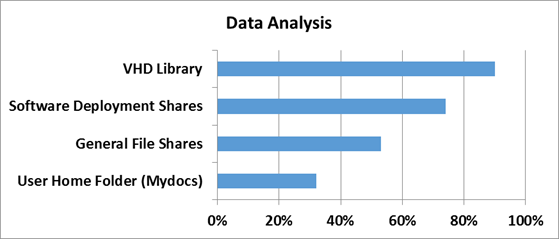
Насколько же эффективна дедупликация с точки зрения рабочих нагрузок проверили в Microsoft в отделе разработки ПО.
3 наиболее популярных сценария стали объектами исследования:
1) Сервера сборки билдов ПО — в MS каждый день собирается приличное количество билдов самых разных продуктов. Даже не значительно еизминение в коде приводит к процессу сборки билда — и следовательно дублирующихся данных создается очень много
2) Шары с дистрибутивами продуктов на релиз — Как не сложно догадаться, все сборки и готовые версии ПО нужно где-то размещать — внутри Microsoft для этого есть специальные сервера, где все версии и языковые редакции всех продуктов размещаются — это тоже достаточно эффективный сценарий, где эффективность от дедупликации может достигать до 70%.
3) Групповые шары — это сочетание шар с документами и файлами разработчиков, а также их перемещаемые профили и перенаправленные папки, которые хранятся в едином центральном пространстве.
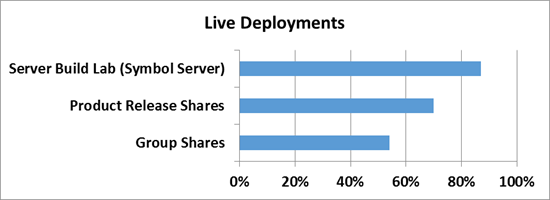
А теперь самое интересное — ниже приведен скриншот с томами в WIndows Server 2012, на которых размещаются все эти данные.
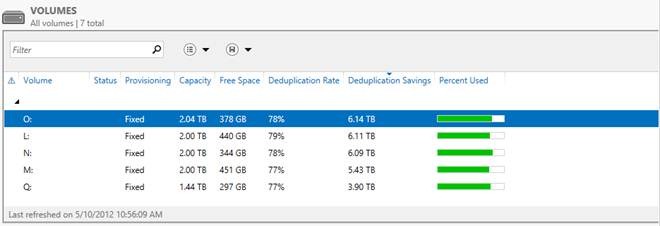
Я думаю слова здесь будут лишними — и все и так очень наглядно. Экономия в 6 Тб на носителях в 2 Тб — термоядерное хранилище? Не так опасно — но столь эффективно!
Характеристики дедупликации в Windows Server 2012
А теперь давайте рассмотрим основные характеристики дедупликации в Windows Server 2012.
1) Прозрачность и легкость в использовании — настроить дедупликацию крайне просто. Сначала в мастере ролей в Windows Server вы раскрывайте роль File and Storage Services, далее File and iSCSI Services — а у же там включаете опцию Data Deduplication.
После этого в Server Manager вы выбираете Fike and Storage Services, клик правой кнопкой мыши — и там вы выбираете пункт «Enable Volume Deduplication». Спешл линк для любителей PowerShell. Все крайне просто. С точки зрения конечного пользователя и приложений доступ и работа с данными осуществляются прозрачно и незаметно. Если говорить про дедупликацию с точки зрения фаловой системы — то поддерживается только NTFS. ReFS не поддается дедупликации, ровно как и тома защищенные с помощью EFS (Encrypted Fike System). Также под дедупликацию не попадают фалы объемом менее 32 KB и файлы с расширенными атрибутами (extended attributes). Дедупликация, однако, распространяется на динамические тома, тома зашифрованные с помощью BitLocker, но не распространяется на тома CSV, а также системные тома (что логично).
2) Оптимизация под основные данные — стоит сразу отметить, что дедупликация — это не онлайн-процесс. Дедупликации подвергаются файлы, которые достигают определенного уровня старости с точки зрения задаваемой политики. После достижения определенного срока хранения данные начинают проходить через процесс дедупликации — по умолчанию этот промежуток времени равен 5 дням, но никто не мешает вам изменить этот параметр — но будьте разумны в своих экспериментах!
3) Планирование процессов оптимизации — механизм который каждый час проверяет файлы на соответствия параметрам дедупликации и добавляет их в расписание.
4) Механизмы исключения объектов из области дедупликации — данный механизм позволяет исключит файлы из области дедупликации по их типу (JPG, MOV, AVI — как пример, это потоковые данныет — то, что меньше всего поддается дедупликации — если вообще поддается). Можно также исключить сразу целые папки с файлами из области дедупликации (это для любителей немецких фильмов, у которых их тьма-тьмущая).
5) Мобильность — дедуплицированный том — это целостный объект — его можно переносить с одного сервера на другой (речь идет исключительно о Windows Server 2012). При этом вы без проблем получите доступ к вашим данным и сможете продолжить работу с ними. Все что для этого необходимо — это включенная опция Data Deduplication на целевом сервере.
6) Оптимизация ресурсоемкости — данные механизмы подразумевают оптимизацию алгоритмов для снижения нагрузки по операциям чтения/записи, таким образом если мы говорим про размер хеш-индекса блоков данных, то размер индекса на 1 блок данных составляет 6 байт. Таким образом применять дедупликацию можно даже к очень массивным наборам данных.
Также алгоритм всегда проверяет достаточно ли ресурсов памяти для проведения процесса дедупликации — если ответ отрицательный, то алгоритм отложит процесс до высвобождения необходимого объема ресурсов.
7) Интеграция с BranchCache — механизмы индексация для дедупликация являются общими также и для BranchCache — поэтому эффективность использования данных технологий в связке не вызывает сомнений!
Вопросы надежности дедуплицированных томов
Вопрос надежности крайне остро встает для дедуплицированных данных — представьте, что блок данных, от корого зависят по-крайней мере 1000 файлов безнадежно поврежден… Думаю, валидос-эз-э-сервис тогда точно пригодится, но не в нашем случае.
1) Резервное копирование — WIndows Server 2012, как и System Center Data Protection Manager 2012 SP1 полностью поддерживают дедуплицированные тома, с точки зрения процессов резервного копирования. Также доступно специальное API, которое позволяет сторонним разработчикам использовать и поддерживать механизмы дедупликации, а также восстанавливать данные из дедуплицированных архивов.
2) Дополнительные копии для критичных данных — те данные, которые имеет самый частый параметр обращения продвергаются процессу создания дополнительных резервных блоков — это особенности алгоритма механизма. Также, в случае использования механизмов Storage Spaces, при нахождение сбойного блока, алгоритм автоматически заменяет его на целостный из пары в зеркале.
3) По умолчанию, 1 раз в неделю запускается процесс нахождения мусора и сбойных блоков, который исправляет данные приобретенные патологии. Есть также возможность вручную запустить данный процесс на более глубоком уровне. Если процесс по умолчанию исправляет ошибки, которые были зафиксированы в логе событий, то более глубокий процесс подразумевает сканирование всего тома целиком.
С чего начать и как померить
Перед тем как включать дедупликацию, всегда нормальному человеку в голову придет мысль о том насколько эффективен будет данный механизм конкретно в его случае. Для этого вы можете использовать Deduplication Data Evaluation Tool.
После установки дедупликации вы можете найти инструмент под название DDPEval.exe, который находится в \Windows\System32\ — данная утиль может быть портирована на сменный носитель или другой том. Поддерживаются ОС WIndows 7 и выше. Так что вы можете проанализировать ваши данный и понять стоимость овечье шкурки. (смайл).
На этом мой обзор завершен. Надеюсь вам было интересно. Если у вас возникнут вопросы — можете смело найти меня в соц.сетях — ВКонтакте, Facebook — по имени и фамилии — и я постараюсь вам помочь.
Для тех, кто хочет узнать про новые возможности в Windows Server 2012, а также System Center 2012 SP1 — я всех приглашаю посетить IT Camp TechEd Pre-Day — 26 ноября, накануне TechEd Russia 2012 состоится данное мероприятие — проводить его будем я, Георгий Гаджиев и Саймон Перриман, который специально прилетает к нам из США.
До встречи на IT Camp и на TechEd!
С уважением,
человек-огонь
Георгий А. Гаджиев
Microsoft Corporation
ссылка на оригинал статьи http://habrahabr.ru/company/microsoft/blog/158887/
Добавить комментарий