Пролог
Здравствуйте еще раз!
Так как первая часть была воспринята благосклонно, решил написать обо всех своих впечатлениях, уже после завершения курса.

Краткое содержание предыдущей серии: решил учить python, после Лутца и Ника Парланте записался на фундаментальный CS курс(к сожалению, не всегда python style), на легкий курс «Питон для самых маленьких» (уже окончен). Ну и где то между ними я ввязался в CS188.1x AI, рассудив раз уж тренировать питона, так на серьезных вещах.
В предыдущем обзоре я успел рассмотреть первые 2 недели курса (порядка 30%), собственно сегодня миновал hard deadline для итогового экзамена, и хочу подвести итоги
Продолжаем знакомится с тонкостями AI-бытия
После неуспешной реализации project 1 студентов ждал пласт информации про Constraint Satisfaction Problems (CSP). Вкратце эта штука про то, как технично решать проблемы с известным числом ограничений — самое типичное это, например, составить расписание для ВУЗа, учтя при этом занятость профессоров, аудиторий, сопоставив доступное время и прочее. Вроде как интуитивно все понятно (но не всегда просто), но есть всяческие приемы, которые ускоряют обход графа состояний. Желающие могут поиграться с вот этой интерактивной html-кой (Там надо назначить цвета, соседние элементы не могут быть одного цвета. Наглядно видно, чем отличается подбор решений без оптимизаций и с определенными оптимизациями обхода графа). В общем-то, эта тема сложной не показалась.
Дальше нас ждали Game Trees and Decision Theory. Тут профессор ознакомил с решением игровых задач в условиях противодействия противника (в случае с пакменом это были привидения). В принципе, тот же Search по Game Tree, с учетом всевозможных ходов соперника, как оптимальных так и нет. Отдельно стоит Alpha-Beta Pruning как способ существенно сократить время обхода большого дерева отсечением отдельных гарантированно бесперспективных ветвей.
Project 2 сказал мне: «Дружище, давай сюда опять своего питона». Собственно опять резкий, но уже не неожиданный переход от слов к коду. Остался тот же самый Pacman World, добавились лишь вражеские агенты.
Требовалось реализовать сначала ReflexAgent, который ничего не планирует, действует исключительно из текущей игровой ситуации. Далее — MinimaxAgent, исходит из оптимальных действий противника и смотрит недалеко (работает медленно) в будущее. Потом наглядно понимаешь, как сокращается на порядок время при заглядывании на несколько ходов вперед с использованием Alpha-Beta. ExpectimaxAgent действует исходя из возможной глупости соперника, что порой позволяет выходить победителем из казалось бы фатальных игровых ситуаций. Ну а на десерт — «Your extreme ghost-hunting, pellet-nabbing, food-gobbling, unstoppable evaluation function». За нее я получил 0/6, так как логику написал а отладить толком не успел. Вывод — не садитесь за project уже перед самым дедлайном, если он в воскресенье ночью, а вам в понедельник на работу.
Учимся AI учиться, или неподражаемый «Коготь»
Последние две недели были посвящены Markov Decision Processes (MDP), вариант представления мира как MDP и Reinforcement Learning (RL), когда мы не знаем ничего про условия окружающего мира, и должны его как то познавать. Ключевая мысль — это rewards, положительные или отрицательные награды за различные действия.
Тут конечно с первой встречи моим разумом завладел он, великий и ужасный Коготь.
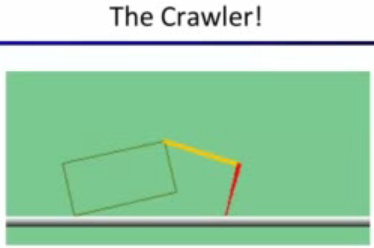
Одновременно смешной и страшный, он бестолково махает своей лапкой, но ему нужно научиться ходить, чтобы пойти в колледж 🙂 Прилагаю кусочек видео из лекции, будет понятнее.
Забегая вперед скажу, что в последнем проекте удалось обучить ходить собственного питомца.
Эти две темы показались достаточно непростыми, например, вопрос как найти баланс оптимального поведения Exploration vs Exploitation, когда решать что достаточно учиться, пора действовать в соответствии с полученными знаниями.
В project 3 немного отвлеклись от лабиринта с желтым колобком, решали вопросы так называемого GridWorld.
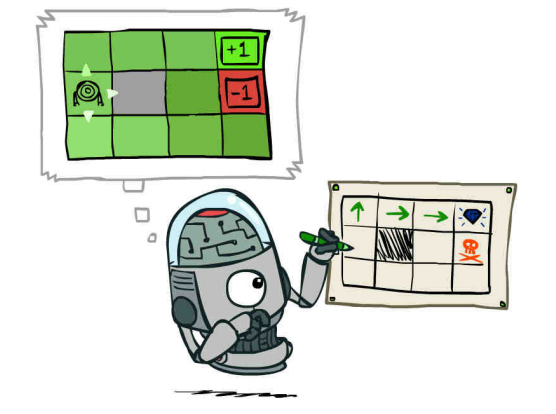
Как решить куда оптимально идти в условиях, когда мы жмем «север» а с некоей вероятностью при этом шагнем на «восток»? Как вести себя в процессе исследования этого мира? Что хорошо, что плохо? Реализованные алгоритмы оказались рабочими также и для Когтя. Небольшое допиливание — готов учиться и пекмен. Оказалось очень интересно вернуться обратно и сравнить как ведет себя обученный несколькими сотнями игр против привидений наш пекмен-убийца. Вот она разница подходов, написать ExpectiMax Search для решения игры в лабиринте, или же научить пекмена учиться как нужно выигрывать.
Финишная прямая
Неделю дали на завершение project 3 и тренировку себя родимого в Final Exam Practice, оценки за который не учитывались. На сдачу финального экзамена была отведена неделя времени, можно было выбрать 48-часовой коридор, и в это время спокойно отвечать. Это явилось одновременно и плюсом и расслабляющим минусом. Еще одним жестоким открытием оказалась одна единственная попытка ответа на большинство вопросов (примерно на 40 из 54-х, на остальные давали две попытки). И если в вопросах из серии True/False это оправдано, то в некоторых других с 4-6 чекбоксами — напрягало. С двумя попытками отвечать было нааамного легче. Вопросы достаточно плотно охватили весь курс. Лекторами экзамен был оценен в 2-5 часов времени, я потратил примерно 1 + 4 ч за 2 дня (отвечал неспешно, кое-где пересматривал лекции), ну и не удалось сдать экзамен без ошибок, окончательный результат (176/200).
Вместо заключения или суммируя свои впечатления
Очень интересно! В лекциях и проверочных заданиях питоном и не пахнет, зато пахнет им очень сильно в специализированных pacman projects. Полное ощущение использования языка в качестве инструмента для решения конкретных задач — думаю для учебы это очень хорошо. Подача материала лектором прекрасна, и лично мне для решения задач хватило информации в лекциях, хотя какие-то доп. материалы указаны в course wiki. Несколько раз был сильно полезен форум. Ну и техническая часть на высоте, все удобно, кнопочки, флажки, ответы. Стоит отметить, что по воскресным вечерам перед дедлайнами auto-grader здорово тормозит (проверяет код до 20-30 минут). Тормозит форум, если смотреть его прямо под разделом видео/вопроса, но тут я грешу на свой старенький нетбук.
К сожалению, поигравшись с youtube-dl, я так и не понял, как же добыть себе лекции с субтитрами edx, а не авто-субтитрами от youtube, если кто-то решил этот вопрос — напишите plz.
Времени я тратил часа по 4 в неделю на лекции и homework, и часов по 10 (а может и больше, сложно посчитать) на каждый project (1 раз в 2 недели). Собственного конспекта не вел, сейчас немного жалею об этом.
Ну и особенное удовольствие доставили такие пасхальные яйца от команды CS188x, как:
if 0 == 1: print 'We are in a world of arithmetic pain' В качестве бонуса собрал несколько ссылок (с указанием времени) на видео в лекциях, которые затрагивают различные реальные применения робо-AI: aibo soccer, google car, робот рубашкоскладыватель, терминатор, aibo учится ходить, человекоподобный робот учится ходить. Для слушателей курса завеса тайны над тем, а как же все таки это запрограммировано немного приоткрылась.
На 2-ю часть курса записаться стоит в любом случае!
До встречи у профессора Кляйна.
ссылка на оригинал статьи http://habrahabr.ru/post/159433/
Добавить комментарий