Если говорить коротко, у меня появилась задача, для решения которой такие возможности как детальный контроль доступа (FGAC), материализованные представления (Materialized View) и Partitioning были бы совсем не лишними. Для реализации этих возможностей, Oracle Enterprise Edition использует механизм переписывания SQL-запросов (Query Rewrite). Все это прекрасно работает, и говорить было бы совсем не о чем, если-бы одним из условий нового проекта не было использование бесплатного ПО. Поскольку мы не можем приобрести необходимый функционал, естественным образом, возникает идея реализовать его самостоятельно.
Суть механизма Query Rewrite сводится к тому, что, перед выполнением, SQL-запрос автоматически переписывается. Например, при использовании детального контроля доступа, в фразу where добавляются дополнительные условия, а при применении материализованных представлений, обращение к некоторой большой таблице подменяется на обращение к заранее построенной таблице гораздо меньшего размера, содержащей агрегированные данные. Это можно рассматривать как некую форму рефакторинга SQL-запроса, оставляющую неизменным его вывод, но существенно оптимизирующую производительность его выполнения.
Для выполнения Query Rewrite, Oracle использует метаданные, которые нам, очевидно, также необходимо где-то хранить. Поскольку мы еще не определились с тем, какая из бесплатных СУБД будет использоваться, логично реализовать СУБД-независимое хранилище метаданных. Следующая схема иллюстрирует, как это можно сделать:
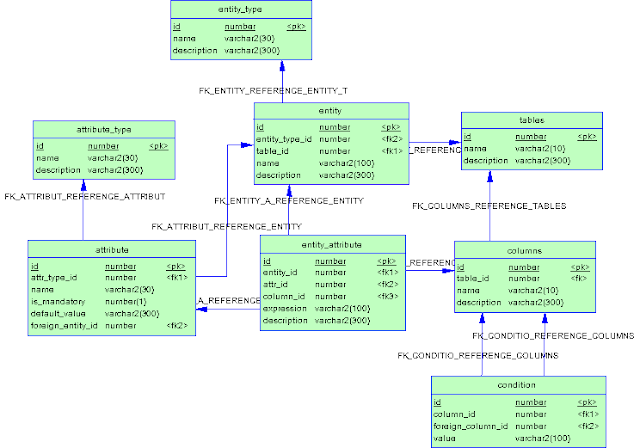
Таблица entity, как понятно из названия, будет содержать описание сущностей, которыми мы сможем манипулировать. К каждой сущности, посредством таблицы entity_attribute привязан список ее атрибутов. Один и тот-же атрибут может быть привязан к нескольким сущностям. Свойства атрибута сохраняются в таблице attribute. Свойство is_mandatory, например, управляет тем, может ли атрибут отсутствовать (или содержать NULL-значение).
Строки entity_attribute могут быть связаны с некоторым реально существующим столбцом, описанным в таблице columns, или вычисляться на основании значений других атрибутов, в соответствии с заданным арифметическим выражением expression. Столбцы, разумеется, связаны с описанием соответствующих таблиц tables.
Здесь следует заметить, что атрибут сущности может отображаться на какой-то столбец той таблицы на которую ссылается entity, но может размещаться и в другой, связанной с ней таблице. Условия соединения подчиненной и главной таблиц описываются в таблице condition и должны быть составлены таким образом, чтобы не более одной строки (0 или 1) подчиненной таблицы было связано с каждой строкой главной таблицы. Каждая строка condition содержит одно условие равенства значения столбца описываемого column_id некоторому значению value или значению столбца в другой таблице, описываемому foreign_column_id.
Помимо этого, мы можем описывать соединение внешние ключи, соединяющие сущности entity. Если в описании какого-то из атрибутов заполнено значение foreign_entity_id, этот атрибут считается внешним ключом, ссылающимся на первичный ключ упомянутой сущности.
Для примера, рассмотрим простую схему данных:
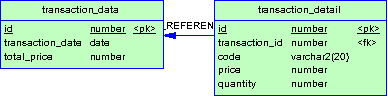
Метаданные будут содержать следующее:
tables:
| Id | name | description |
| 1 | transaction_data | Данные продажи |
| 2 | transaction_detail | Детализация продажи |
columns:
| Id | table_id | name | description |
| 1 | 1 | id | Первичный ключ |
| 2 | 1 | transaction_date | Дата продажи |
| 3 | 1 | total_price | Суммарная стоимость |
| 4 | 2 | id | Первичный ключ |
| 5 | 2 | transaction_id | Ссылка на продажу |
| 6 | 2 | code | Код товара |
| 7 | 2 | price | Цена товара |
| 8 | 2 | quantity | Количество товара |
condition:
| Id | column_id | foreign_column_id | value |
| 1 | 5 | 1 |
entity_type:
| Id | name | description |
| 1 | operational data |
Оперативные данные |
| 2 | dictionary data |
Справочные данные |
attribute_type:
| Id | name | description |
| 1 | key | Ключ |
| 2 | string | Строка |
| 3 | number | Число |
| 4 | date | Дата |
entity:
| Id | entity_type_id | table_id | name | description |
| 1 | 1 | 1 | transaction | Данные продажи |
| 2 | 1 | 2 | detail | Детализация продажи |
attribute:
| Id | attr_type_id | name | is_mandatory | foreign_entity_id |
| 1 | 1 | id | 1 | |
| 2 | 4 | transaction_date | 1 | |
| 3 | 3 | total_price | 1 | |
| 4 | 1 | transaction_id | 1 | 1 |
| 5 | 2 | code | 1 | |
| 6 | 3 | price | 1 | |
| 7 | 3 | quantity | 1 |
entity_attribute:
| Id | entity_id | attr_id | column_id | description |
| 1 | 1 | 1 | 1 | Первичный ключ |
| 2 | 1 | 2 | 2 | Дата продажи |
| 3 | 1 | 3 | 3 | Суммарная стоимость |
| 4 | 2 | 1 | 4 | Первичный ключ |
| 5 | 2 | 4 | 5 | Ссылка на продажу |
| 6 | 2 | 5 | 6 | Код товара |
| 7 | 2 | 6 | 7 | Цена товара |
| 8 | 2 | 7 | 8 | Количество товара |
Такое описание может показаться избыточным (в частности, описания таблиц и сущностей практически повторяют друг друга), но это только из-за того, что мы реализовали очень простую схему данных.
Для хранения описания мат. представлений можно использовать следующую схему:
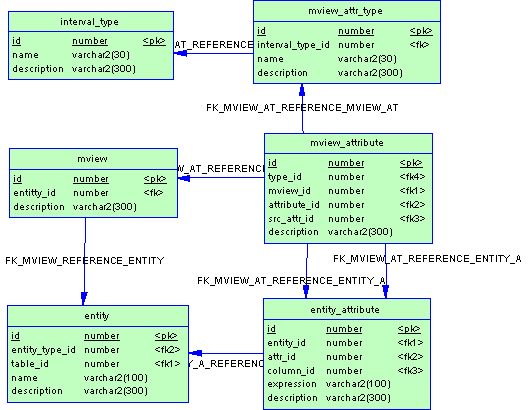
Поскольку мат. представление также является сущностью, таблица mview ссылается на entity. Атрибуты mview_attribute аналогичным образом ссылаются на entity_attribute, для наследования описания атрибутов сущности мат. представления. Но, помимо этого, mview_attribute имеет еще одну ссылку (src_attr_id) на entity_attribute, определяющую, на базе какого исходного атрибута строится атрибут мат. представления.
То, как именно атрибут мат. представления участвует в агрегации, описывает таблица mview_attr_type. Таблица interval_type содержит справочник интервалов агрегации. Для примера, опишем простейшее мат. представления, построенное на базе запроса, показывающего, какое количество каждого товара было продано в день:
select trunc(a.transaction_date, 'DAY') transaction_date, b.code code, sum(b.quantity) quantity from transaction_data a, transaction_detail b where b.transaction_id = a.id group by trunc(a.transaction_date, 'DAY'), b.code Здесь мы считаем, что функция trunc(a.transaction_date, ‘DAY’) отсекает от даты продажи время, округляя дату до суток. Аналогичным образом ‘WEEK’ и ‘MONTH’ проводят округление до недели или месяца.
tables:
| Id | name | description |
| 3 | mat_view | Материализованное представление |
columns:
| Id | table_id | name | description |
| 9 | 3 | transaction_date | Дата продажи |
| 10 | 3 | code | Код товара |
| 11 | 3 | quantity | Количество товара |
entity:
| Id | entity_type_id | table_id | name | description |
| 3 | 1 | 3 | mat_view | Материализованное представление |
entity_attribute:
| Id | entity_id | attr_id | column_id | description |
| 9 | 3 | 4 | 9 | Дата продажи |
| 10 | 3 | 5 | 10 | Код товара |
| 11 | 3 | 7 | 11 | Количество товара |
interval_type:
| Id | name | description |
| 1 | DAY | Сутки |
| 2 | WEEK | Неделя |
| 3 | MONTH | Месяц |
| 4 | YEAR | Год |
mview_attr_type:
| Id | interval_type_id | name | description |
| 1 | KEY | Ключ агрегирования | |
| 2 | 1 | DAY | Округление даты до суток |
| 3 | 2 | WEEK | Округление даты до недели |
| 4 | 3 | MONTH | Округление даты до месяца |
| 5 | 4 | YEAR | Округление даты до года |
| 6 | SUM | Сумма |
mview:
| Id | entity_id | description |
| 1 | 3 | Материализованное представление |
mview_attribute:
| Id | type_id | mview_id | attribute_id | src_attr_id |
| 1 | 2 | 1 | 9 | 2 |
| 2 | 1 | 1 | 10 | 6 |
| 3 | 6 | 1 | 11 | 8 |
Партиционирование может быть описано следующей схемой:
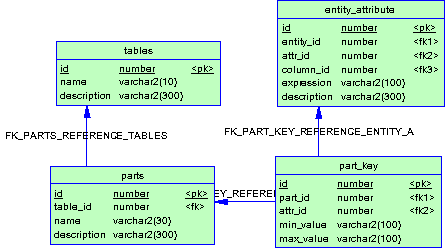
С каждой таблицей может быть связано несколько партиций, каждая из которых уникально идентифицируется набором part_key. Физически, будут храниться не таблицы описанные в tables, а партиции (в виде таблиц БД), описанные parts. В качестве примера, партиционируем построенное нами мат.представление по дате продажи, с интервалом 1 месяц.
parts:
| Id | table_id | name |
| 1 | 3 | mat_view_000001 |
| 2 | 3 | mat_view_000002 |
| 3 | 3 | mat_view_000004 |
part_key:
| Id | part_id | attr_id | min_value | max_value |
| 1 | 1 | 9 | 20120101 | 20120201 |
| 2 | 2 | 9 | 20120201 | 20120301 |
| 3 | 3 | 9 | 20120301 | 20120401 |
Нас сейчас не интересуют механизмы, которые будут автоматически разносить данные по партициям и обеспечивать актуальность мат. представлений. Я знаю, что их можно реализовать. Более интересен, на мой взгляд, механизм, который будет переписывать SQL-запрос, перед передачей его на сервер БД.
Например, если нас заинтересует количество проданного товара за два месяца, мы оперируя именами сущностей и атрибутов так, как если бы это были реальные таблицы и столбцы, напишем следующий запрос:
select code, sum(quantity) from thransaction_detail where transaction_date >= '20120201' and transaction_date < '20120401' group by code После автоматического переписывания, запрос должен обрести следующий вид:
select code, sum(quantity) from ( select code code, quantity quantity from mat_view_000001 where transaction_date >= '20120201' and transaction_date < '20120401' union all select code, quantity from mat_view_000002 where transaction_date >= '20120201' and transaction_date < '20120401') group by code Возможно, это не самая удачная идея, но мне, почему-то, очень захотелось ей заняться.
ссылка на оригинал статьи http://habrahabr.ru/post/159447/
Добавить комментарий