Задача In-Memory Data Grid (IMDG) — обеспечить сверхвысокую доступность данных посредством хранения их в оперативной памяти в распределённом состоянии. Современные IMDG способны удовлетворить большинство требований к обработке больших массивов данных.
Упрощенно, IMDG — это распределённое хранилище объектов, схожее по интерфейсу с обычной многопоточной хэш-таблицей. Вы храните объекты по ключам. Но, в отличие от традиционных систем, в которых ключи и значения ограничены типами данных «массив байт» и «строка», в IMDG Вы можете использовать любой объект из Вашей бизнес-модели в качестве ключа или значения. Это значительно повышет гибкость, позволяя Вам хранить в Data Grid в точности тот объект, с которым работает Ваша бизнес-логика, без дополнительной сериализации/де-сериализации, которую требуют альтернативные технологии. Это также упрощает использование Вашего Data Grid-а, поскольку в большинстве случаев Вы можете работать с распределённым хранилищем данных как с обычной хэш-таблицей. Возможность работать с объектами из бизнес-модели напрямую — одно из основных отличий IMDG от In-Memory баз данных (IMDB). В последнем случае пользователи всё ещё вынуждены осуществлять объектно-реляционное отображение (Object-To-Relational Mapping), которое, как правило, приводит к значительному снижению производительности.
Есть и другие функциональные особенности, которые отличают IMDG от других продуктов, таких как IMDB, NoSql или NewSql базы данных. Одна из основных — по-настоящему масштабируемое секционирование данных (Data Partitioning) в кластере. IMDG по сути представляет собой распределённую хэш-таблицу, где каждый ключ хранится на строго определённом сервере в кластере. Чем больше кластер, тем больше данных можно в нем хранить. Принципиально важным в этой архитектуре является то, что обработку данных следует производить на том же сервере, где они расположены (локально), исключая (или сводя к минимуму) их перемещение по кластеру. Фактически, при использовании хорошо спроектированного IMDG, перемещение данных будет полностью отсутствовать за исключением случаев, когда в кластер добавляются новые сервера или удаляются существующие, меняя тем самым топологию кластера и распределение данных в нем.
Нижеприведённая схема показывает классический IMDG с набором ключей {k1, k2, k3}, в котором каждый ключ принадлежит отдельному серверу. Внешняя база данных не является обязательной. Если она присутствует, IMDG, как правило, будет автоматически читать данные из базы или записывать их в нее.
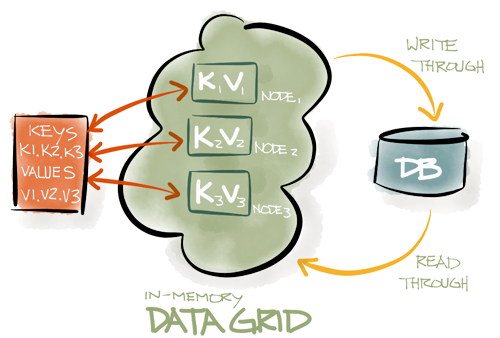
Ещё одной отличительной особенностью IMDG является поддержка транзакционности, удовлетворяющей требованиям ACID (atomicity, consistency, isolation, durability — атомарность, целостность, изоляция, сохранность). Как правило, чтобы гарантировать целостность данных в кластере, используют двухфазную фиксацию (2-phase-commit или 2PC). Разные IMDG могут иметь разные механизмы блокировок, но наиболее продвинутые реализации обычно используют параллельные блокировки (например, GridGain использует MVCC — multi-version concurrency control, управление конкурентным доступом с помощью многоверсионности), сводя тем самым сетевой обмен к минимуму, и гарантируя транзакционную целостность ACID с сохранением высокой производительности.
Целостность данных является одним из главных отличий IMDG от NoSQL баз данных. NoSQL базы данных, в большинстве случаев, спроектированы с использованием подхода, называемого “целостность в конечном итоге” (Eventual Consistency, EC), при котором данные могут некоторое время находиться в несогласованном состоянии, но обязательно станут согласованными *со временем*. В целом, операции записи в EC системах происходят достаточно быстро по сравнению с более медленными операциями чтения (точнее, не превосходящими по скорости операции записи). Последние IMDG с *оптимизированным* 2PC как минимум соответствуют EC системам по скорости записи (если не опережают их), и значительно превосходят их по скорости чтения. Интересно, что индустрия сделала полный круг, двигаясь от тогда ещё медленных 2PC к EC, а теперь от EC к гораздо более быстрым *оптимизированным* 2PC.
Разные продукты могут предлагать разные 2PC оптимизации, но в целом задачами всех оптимизаций являются увеличение параллелизма (concurrency), минимизация сетевого обмена и снижение числа блокировок, требуемых для совершения транзакции. Например, распределённая глобальная база данных Spanner компании Google основана на транзакционном 2PC подходе просто потому, что 2PC предоставил более быстрый и простой способ гарантировать целостность данных и высокую пропускную способность в сравнении с MapReduce или EC.
Даже несмотря на то, что у разных IMDG обычно много общих базовых функциональных возможностей, существует множество дополнительных возможностей и деталей реализации, которые отличаются в зависимости от производителя. Оценивая IMDG продукт, обращайте внимание на механизмы выгрузки данных при переполнении (eviction policies), техники загрузки данных, в том числе, при старте сервера ((pre)loading techniques), параллельное секционирование (concurrent repartitioning), объём дополнительной памяти, требуемый для хранения записей (data overhead), и тому подобное. Также, обращайте внимание на возможность делать запросы (query) в кэш во время выполнения. Некоторые IMDG, например, GridGain, позволяют пользователям осуществлять запросы к данным, хранящимся в памяти, используя обычный SQL с поддержкой распределённых join-ов (distributed joins), что является довольно большой редкостью.
Хранение данных в IMDG — это лишь половина функциональности, требуемой для in-memory архитектуры. Данные, хранимые в IMDG, также должны обрабатываться параллельно и с высокой скоростью. Типичная in-memory архитектура секционирует данные в кластере с помощью IMDG, и затем исполняемый код отправляется именно на те сервера, где находятся требуемые ему данные. Поскольку исполняемый код (вычислительная задача) обычно является частью вычислительных кластеров (Compute Grids), и должен быть правильно развернут (deployment), сбалансирован по нагрузке (load-balancing), обладать отказоустойчивостью (fail-over), а также иметь возможность запуска по расписанию (scheduling), интеграция между Compute Grid и IMDG очень важна. Наибольший эффект можно получить, если IMDG и Compute Grid являются частями одного и того же продукта и используют одни и те же API. Это снимает с разработчика бремя интеграции и обычно позволяет достигнуть наибольшей производительности и надёжности in-memory решения.
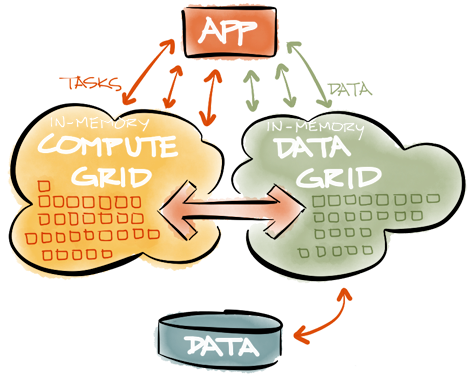
IMDG (вместе с Compute Grid) находят свое применение во многих областях, таких как анализ рисков (Risk Analytics), торговые системы (Trading Systems), системы реального времени для борьбы с мошенничеством (Fraud Detection), биометрика (Biometrics), электронная коммерция (eCommerce), онлайн-игры (Online Gaming). По сути, любой продукт, перед которым стоят проблемы масштабируемости и производительности, может выиграть от использования In-Memory Processing и IMDG архитектуры.
ссылка на оригинал статьи http://habrahabr.ru/post/160517/
Добавить комментарий