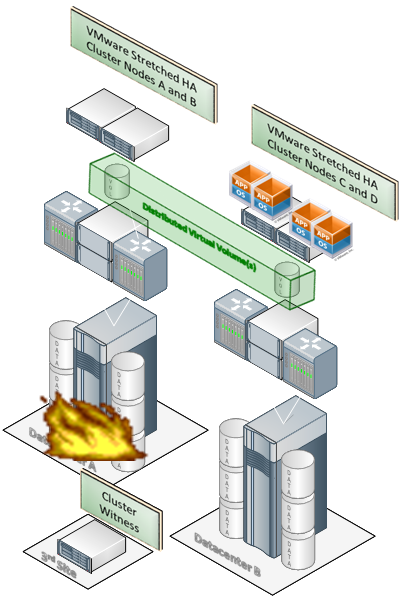
Авария в первом дата-центре и автоматический перезапуск сервисов в другом
Виртуализация — одна из моих любимых тем. Дело в том, что сейчас можно практически полностью забыть про используемое железо и организовать, например, систему хранения данных в виде «логического» юнита, который умеет взаимодействовать с информацией по простым правилам. При этом все процессы между виртуальным юнитом и реальным железом в разных ЦОДах лежат на системе виртуализации и не видны приложениям.
Это даёт кучу преимуществ, но и ставит ряд новых проблем: например, есть вопрос обеспечения консистентности данных при синхронной репликации, которая накладывает ограничения на расстояния между узлами.
К примеру — скорость света становится реальным физическим барьером, который не даёт заказчику поставить второй ЦОД дальше 40-50, а то и меньше, километров от первого.
Но давайте начнём с самого начала — как работает виртуализация систем хранения, зачем оно всё надо, и какие задачи решаются. И главное — где конкретно вы сможете выиграть и как.
Немного истории
Сначала были сервера с внутренними дисками, на которых хранилась вся информация. Это довольно простое и логичное решение быстро стало не самым оптимальным, и со временем мы стали использовать внешние хранилища. Сначала простые, но постепенно потребовались специальные системы, позволяющие хранить невероятно много данных и давать к ним очень быстрый доступ. СХД отличались друг от друга объёмом, надёжностью и скоростью. В зависимости от конкретных технологий (например, магнитная лента, жесткие диски или даже SSD, которыми сейчас, конечно, никого не удивить) можно было варьировать эти параметры в довольно широком диапазоне — главное, чтобы были деньги.
Для ИТ-директоров сейчас один из самых главных критериев СХД — надёжность. Например, час простоя для банка вполне может стоить как 10-20 таких шкафов с железом, не говоря уже о репутационных потерях — поэтому основной парадигмой стали географически распределенные отказоустойчивые решения. Проще говоря – железки, дублирующие друг друга, которые стоят в двух разных дата-центрах.
Эволюция:

I ступень: Два сервера со встроенными дисками

II ступень: СХД и две машины в одном ЦОДе.

III ступень: Разные ЦОДы и репликация между ними (самый распространенный вариант)

IV ступень: Виртуализация этого хозяйства. Кстати, в связку в середине можно воткнуть, например, дополнительно резервное копирование.

V ступень: Виртуализация СХД (EMC VPLEX)
Один из инструментов решения такой задачи – EMC VPLEX, на примере которого можно чётко понять плюсы этой самой виртуализации.
Сравнение систем
Так в чем же суть?
До VPLEX: есть два сервера, каждый видит свой том, между томами репликация. Один всегда стоит и ждёт, второй всегда работает. Резервный сервер не имеет прав на запись, пока не отказал основной ЦОД
После внедрения VPLEX: репликация не нужна. Оба сервера видят только один виртуальный том, как подключенный напрямую к себе. Каждый сервер работает со своим томом, и каждый думает, что это локальный том. В реальности каждый работает со своей СХД.
До: для переноса данных на другое хранилище (физическую СХД), нужна перенастройка серверов, кластеров и так далее. Это снижает отказоустойчивость и может стать причиной ошибок: при переконфигурации кластер может разъехаться, например.
После: можно без снижения отказоустойчивости и прозрачно для серверов перенести данные (все СХД скрыты под VPLEX и сервера про железо даже не знают). Механика такая: добавляем новую СХД, подключаем её под VPLEX, зеркалируем, не убирая старую, потом переключаем – и сервер даже не замечает.
До: есть проблемы с разными вендорами, например, нельзя настраивать репликацию HP с массивом EMC.
После: можно подключить массив HP и EMC (или других производителей) и спокойно из двух стораджей собрать том. Это особенно круто, потому что у крупных заказчиков часто гетерогенный «зоопарк», который плотно интегрируется и легко модернизируется. Это значит, что любую критичную систему можно легко и просто перенести на новое железо без сопутствующей головной боли.
До: нужно время на переключение репликации и кластера.
После: перезапускается только приложение в кластере, оно всегда либо на одной ноде, либо на второй, но прозрачно и быстро перебрасывается.
До: архитектура — геокластер со всеми ограничениями.
После: архитектура – локальный кластер. Точнее, сервер так думает, и поэтому нет никаких сложностей в работе с ним.
До: необходимо ПО управления репликацией.
После: VPLEX на системном уровне следит за репликацией. Да и вообще, репликации, по сути, нет – есть «зеркало».
До: SRM накладывает свои ограничения на перезапуск VM в резервном ЦОДе.
После: стандартный VMotion работает при перемещении ВМ на резервную площадку (предваряя вопрос про канал: да, у нас широкий канал между площадками, так как мы говорим о серьёзном Disaster Recovery решении).
Как переезжать без простоя системы?
Переезжать с одной железки на другую приходится довольно часто: примерно раз в два-три года высоконагруженные системы требуют модернизации. В России реалии таковы, что многие заказчики просто боятся трогать свои системы и плодят «костыли» вместо переноса — и часто вполне оправданно, потому что примеров ошибок при переезде тоже много. С VPLEX переезжать просто — главное, знать про такую возможность.
Ещё один интересный момент — это перенос систем, по которым производительность непонятна. Например, банк запускает новый сервис, и его наличие становится через полгода важным конкурентным преимуществом. Нагрузка на железо растёт, нужно делать сложный и мучительный переезд (банки боятся даже одной потерянной транзакции, и даже 5 миллисекунд промаха — это проблема). В этом случае VPLEX-подобные системы становятся единственной более-менее разумной альтернативой. Иначе быстро и прозрачно подменить СХД будет непросто.
Допустим, система старая и жестко привязана к железу. При переезде на другое железо нужна среда, которая поможет осуществить перенос без влияния на работу пользователей и сервисов. Поместив такую систему под VPLEX, ее можно будет легко переносить между вендорами — приложения даже не заметят. С поддержкой ОС проблем также не возникает. В списке совместимости все основные операционки, встречающиеся у заказчика. В экзотических случаях, можно проверить совместимость с вендором или партнером и получить подтверждение.

Берём действующую систему СХД (слева) и зеркалируем средствами EMC VPLEX незаметно для сервера и приложений(справа). В терминах VPLEX это называется Distributed volume. Сервер продолжает думать что работает с одним стораджем и одним томом.

Фактически, первая СХД становится чем-то похожим на кусок зеркала. Её мы отключаем — и переезд готов.
Про синхронизацию
Есть три конфигурации – Local (1 ЦОД), Metro (синхронная репликация) и Geo (2 асинхронных ЦОД). Разновидность синхронной репликации с x-подключением – Campus. Синхронная репликация наиболее востребована (это 99% внедрений в России). Здесь в дело вступает бессердечная скорость света, которая устанавливает максимальное расстояние между ЦОДами — должно хватить 5 миллисекунд на прохождение сигнала. Можно настраивать и с 10 миллисекундами, но чем ближе ЦОДы — тем лучше. Обычно это 30-40 километров максимум.

Варианты схемы для синхронной репликации
VPLEX даёт серверам доступ на чтение-запись. Серверы видят один том данных каждый на своей площадке, но на деле это виртуальный распределённый том VPLEX. Metro позволяет большие задержки, Campus даёт большую надёжность. В Campus это выглядит так:

Самое приятное — никаких проблем с переключением репликации при перемещении виртуальных машин.

При использовании Campus отказ всех дисковых подсистем и локальной части VPLEX приведет к потере только половины путей для диска. Сами же диски останутся доступны серверам – только уже через x-подключение и удаленную часть VPLEX. Вот как это работает для Oracle.
Есть ещё ситуации типа ЦОДов в Москве и Новосибирске, они решаются асинхронной репликацией. Её VPLEX тоже умеет, но уже в конфигурации Geo.
А если авария?

Здесь VPLEX Metro и VMware HA (но может быть и Hyper-V) — и авария в одном из ЦОДов.
Сервисы перезапускаются в другом ЦОД без участия администратора, т.к. для Vmware это единый HA кластер.
В середине есть Witness — это виртуалка, которая контролирует состояние обоих кластеров и следит, чтобы при разрыве связи между ними оба не начали обрабатывать данные. То есть защищает от машинной «шизофрении». Witness позволяет в случае аварии работать с наиболее актуальной копией только одному кластеру — и после устранения проблемы второй просто получает более свежую версию данных и продолжает работать.
Witness разворачивается либо на третьей площадке, либо у облачного провайдера. Она коммуницирует с EMC VPLEX по IP посредством VPN. Больше ей ничего для работы не нужно.
Данные на удалённой площадке
Получить данные, физически расположенные в другом ЦОДе — также не вопрос. Зачем? Например, если в основном ЦОДе не хватает места. Тогда можно занять его в резервном.
Гетерогенное железо

Экосистема «VPLEX и партнеры»
В центре решений КРОК на базе технологий EMC мы построили такое решение. На одной площадке СХД EMC, сервера Cisco (для многих новость, что Cisco выпускает весьма хорошие сервера), на другой площадке виртуализована система Hitachi, а сервера IBM. Но как видите, все остальные вендоры тоже спокойно поддерживаются. На той неделе мы проводили демонстрацию системы для одного из банков, для которого и был собран стенд, и их специалисты сами убедились, что косяков нет, и интеграция реально гладкая. В ходе демонстрации мы имитировали различные аварии и сбои, которые мы заготовили, либо заказчик их предлагал по ходу встречи. Следующий этап – пилотный проект на нескольких небольших системах. Несмотря на наличие уже опыта эксплуатации этих железок, каждый заказчик хочет убедиться сам, что все работает. Центр решений сделан именно для этого, так что мы не против.
Ещё бонусы
- При работе в одном ЦОД, VPLEX ещё и решает задачу по зеркалированию внутри этого ЦОДа. Кроме того, VPLEX гораздо мягче относится к просчётам в требуемой производительности — можно по ходу пьесы переехать на более мощную СХД.
- Имея мощности в удалённом ЦОД, хочется их использовать — можно использовать «резервный» ЦОД для СХД в ряде случаев, при этом держать сервера на вашей площадке.
Как работает доступ к данным?
Наверняка вам уже интересно, как же это работает уровнем ниже. Итак, раньше при записи на одной площадке и чтении с другой был шанс попасть на неактуальные данные. В VPLEX есть система каталогов, которая показывает, на какой ноде данные наиболее свежие, поэтому кэш-память можно считать общей на всю систему.

При чтении только что записанного другой машиной участка работает вот такая связка.
Конфигурация

Можно начать с малого, например, поставить блок, который содержит 2 контроллера (то есть это уже отказоустойчивая конфигурация, до 500 000 iops) — дальше можно перейти к средней конфигурации или достичь максимальной 4-узловой конфигурации в стойке в каждом из ЦОД. То есть до 2.000.000 iops, что не всегда нужно, но вполне достижимо. Можно пойти дальше и создавать домены VPLEX, но до этого на нашем рынке еще, думаю, никто не дорос.
Плюсы и минусы
Минусы:
- Нужны затраты на внедрение и лицензии
- Нужно принять решение о переходе на новую философию и обучить персонал
- Скорее всего, процесс перехода будет поэтапным (но вспомните как мы виртуализировали наши сервера!)
Плюсы:
- Можно отвязаться от железа и не заботиться об отказах частей системы, получая надёжность в пять девяток.
- Простое масштабирование и переезды.
- Простые манипуляции с виртуальными машинами и приложениями.
- Нет проблемы мультивендорности.
- Система с определённого уровня дешевле кучи софта для решения локальных задач СХД в ЦОДах.
- Благодаря простоте и прозрачности всех действий использование VPLEX существенно снижает количество ошибок человека.
- Прощает неточные прогнозы по производительности.
- VPLEX позволяет не думать о затачивании железа под конкретную задачу, а использовать его так, как хочется.
- Переход от отказоустойчивости к мобильности
- Администраторы серверов настраивают кластеры как и раньше, используя те же инструменты.
Внедрение
Если вы хотите попробовать или посмотреть на то, как всё это работает вживую — пишите на vbolotnov@croc.ru. И ещё я отвечу на любые вопросы в комментариях.
ссылка на оригинал статьи http://habrahabr.ru/company/croc/blog/169333/
Добавить комментарий