
Думаю многим известна особенность PostgreSQL, которая приводит к эффекту раздувания таблиц, или table bloat. Известно что она проявляет себя в случаях интенсивного обновления данных, как при частых UPDATE так и при INSERT/DELETE операциях. В результате такого раздувания снижается производительность. Рассмотрим почему это происходит и как с этим можно бороться.
Таблицы в PostgreSQL представлены в виде страниц, размером 8Kb, в которых размещены записи. Когда одна страница полностью заполняется записями, к таблице добавляется новая страница. При удалалени записей с помощью DELETE или изменении с помощью UPDATE, место где были старые записи не может быть повторно использовано сразу же. Для этого процесс очистки autovacuum, или команда VACUUM, пробегает по изменённым страницам и помечает такое место как свободное, после чего новые записи могут спокойно записываться в это место. Если autovacuum не справляется, например в результате активного изменения большего количества данных или просто из-за плохих настроек, то к таблице будут излишне добавляться новые страницы по мере поступления новых записей. И даже после того как очистка дойдёт до наших удалённых записей, новые страницы останутся. Получается что таблица становится более разряженной в плане плотности записей. Это и называется эффектом раздувания таблиц, table bloat.
Процедура очистки, autovacuum или VACUUM, может уменьшить размер таблицы убрав полностью пустые страницы, но только при условии что они находятся в самом конце таблицы. Чтобы максимально уменьшить таблицу в PostgreSQL есть VACUUM FULL или CLUSTER, но оба эти способа предполагают установку тяжелых и длительных блокировок на таблицу, что далеко не всегда является подходящим решением.
Рассмотрим одно из решений. При обновлении записи с помощью UPDATE, если в таблице есть свободное место, то новая версия пойдет именно в свободное место, без выделения новых страниц. Предпочтение отдается свободному месту ближе к началу таблицы. Если обновлять таблицу с помощью т.н. fake updates, типа some_column = some_column с последней страницы, в какой-то момент, все записи с последней страницы перейдут в свободное место в предшествующих страницах таблицы. Таким образом, после нескольких таких операций, последние страницы окажутся пустыми и обычный неблокирующий VACUUM сможет отрезать их от таблицы, тем самым уменьшив размер.
В итоге, с помощью такой техники можно максимально сжать таблицу, при этом не вызывая критичных блокировок, а значит без помех для других сессий и нормальной работы базы.
И теперь самое важное)))) Для автоматизации этой процедуры существует утилита pgcompactor.
Её основные характеристики:
- не требует никаких зависимостей кроме Perl >=5.8.8, т.е. можно просто скопировать pgcompactor на сервер и работать с ним;
- работает через адаптеры DBD::Pg, DBD::PgPP или даже через стандартную утилиту psql, если первых двух на сервере нет;
- обработка как отдельных таблиц, так и всех таблиц внутри схемы, базы или всего кластера;
- возможность исключения баз, схем или таблиц из обработки;
- анализ эффекта раздувания и обработка только тех таблиц, у которых он присутствует, для более точных расчетов рекомендуется установить расширение pgstattuple;
- анализ и перестроение индексов с эффектом раздувания;
- анализ и перестроение уникальных ограничений (unique constraints) и первичных ключей (primary keys) с эффектом раздувания;
- инкрементальное использование, т.е. можно остановить процесс сжатия без ущерба чему-либо;
- динамическая подстройка под текущую нагрузку базы данных, чтобы не влиять на производительность пользовательских запросов (с возможностью регулировки при запуске);
- рекомендации администраторам, сопровождаемые готовым DDL, для перестроения объектов базы, которые не могут быть перестроены в автоматическом режиме.
Пара примеров использования:
запуск на всём кластере с обязательным перестроением индексов:
# pgcompactor —all —reindex
запуск на отдельной таблице (с перестроением индексов):
# pgcompactor —reindex —dbname geodata —table cities —verbose info >pgcompactor.log 2>&1
Результат работы:
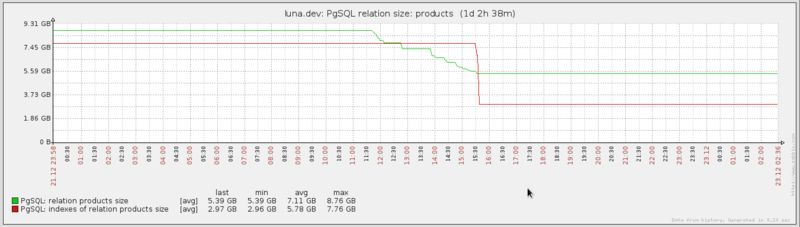
Размер таблицы снизился с 9,2GB до 5,6GB. Совокупный размер всех индексов снизился с 7,5GB до 2,8GB
URL проекта: code.google.com/p/pgtoolkit/
Большое спасибо авторам утилиты за их работу! Это действительно полезный инструмент.
Спасибо за внимание!
ссылка на оригинал статьи http://habrahabr.ru/post/169939/
Добавить комментарий