Классический сценарий
Вы работаете над проектом, где транзакционные данные хранятся в базе данных. Затем вы развёртываете приложение в рабочей среде, и производительность великолепна! Запросы проходят шустро, и задержка при их вводе практически незаметна. Через несколько дней/недель/месяцев база данных становится всё больше и больше, и скорость запросов замедляется.
Есть несколько подходов, с помощью которых можно ускорить работу вашего приложения и базы данных.
Администратор базы данных (DBA) посмотрит и проследит, чтобы база данных была оптимально настроена. Он предложит добавить определённые индексы, убрать логирование на отдельную партицию, подправить параметры движка базы данных и убедиться, что база данных здорова. Можно также добавить выделенных IOPS (Input/Output Operations Per second) на EBS диске, чтобы увеличить скорость дисковых партиций. Это даст вам выиграть время и даст возможность решить главную проблему.
Рано или поздно вы поймёте, что данные в вашей базе данных являются узким местом (botleneck).
В базах данных многих приложений важность информации уменьшается со временем. Если вы сможете придумать способ избавиться от этой информации, ваши запросы будут проходить быстрее, время создания бэкапов уменьшится, и вы сэкономите кучу места. Вы можете удалить эту информацию, однако тогда она пропадёт безвозвратно. Вы можете послать множество DELETE запросов, вызвав создание тонн логов, и использовать кучу ресурсов движка базы данных. Так как же мы избавимся от старой информации эффективно, но не потеряв её навсегда?
В примерах мы будем использовать PostgreSQL 9.2 на Engine Yard. Вам также нужен git для установки plsh.
Партицирование таблиц
Партицирование таблиц является хорошим решением этой проблемы. Возьмите одну гигантскую таблицу и разбейте её на кучу маленьких — эти маленькие таблицы называются партициями и дочерними таблицами (child object). Такие действия, как создание бэкапов, операции SELECT и DELETE, могут быть произведены с индивидуальными или всеми партициями. Партиции также могут быть удалены или экспортированы единичным запросом, что сведёт логирование к минимуму.
Терминология
Начнём с терминологии, которая будет использоваться в этой статье.
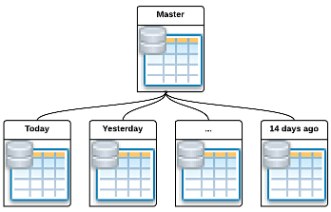
Master Table (Главная таблица)
Также именуемая Master Partition Table, это шаблон, по которому создаются дочерние таблицы. Это обычная таблица, но она не хранит никакой информации и нуждается в триггере (об этом позже). Тип отношений между главной и дочерними таблицами является один-к-многим (one-to-many), то есть есть одна главная таблица и множество дочерних.
Дочерняя таблица (Child Table)
Эти таблицы наследуют свою структуру (или другими словами, свой язык описания данных — Data Definition Language или DDL) от главной таблицы и принадлежат одной главной таблице. Именно в дочерних таблицах хранятся все данные. Эти таблицы часто называют партиционными таблицами.
Partition Function
Partition function является хранимой процедурой, которая определяет, какая из дочерних таблиц примет новую запись. Главная таблица содержит триггер, который вызывает функцию партицирования. Есть две методологии для маршрутизации записей к дочерним таблицам:
По значениям данных – примером этого является дата заказа покупки. Когда заказы покупок поступают в главную таблицу, эта функция вызывается триггером. Если вы создаёте партиции по дням, каждая дочерняя партиция будет представлять все заказы пришедшие в определённый день. Этот метод описывается в этой статье.
По фиксированным значениям – примером этого является географическое положение, такое, как штаты. В этом случае, у вас может быть 50 дочерних таблиц, по одной для каждого штата США. Когда запросы INSERT поступают в главную таблицу, функция сортирует каждый новый ряд в одну из дочерних таблиц. Эта методология не описывается в этой статье, так как не поможет нам избавиться от старых данных.
Partition Function
Partition function является хранимой процедурой, которая определяет, какая из дочерних таблиц примет новую запись. Главная таблица содержит триггер, который вызывает функцию партицирования. Есть две методологии для маршрутизации записей к дочерним таблицам:
По значениям данных – примером этого является дата заказа покупки. Когда заказы покупок поступают в главную таблицу, эта функция вызывается триггером. Если вы создаёте партиции по дням, каждая дочерняя партиция будет представлять все заказы пришедшие в определённый день. Этот метод описывается в этой статье.
По фиксированным значениям – примером этого является географическое положение, такое, как штаты. В этом случае, у вас может быть 50 дочерних таблиц, по одной для каждого штата США. Когда запросы INSERT поступают в главную таблицу, функция сортирует каждый новый ряд в одну из дочерних таблиц. Эта методология не описывается в этой статье, так как не поможет нам избавиться от старых данных.
Пора настроить эти партиции
Это решение демонстрирует следующее:
- Автоматическое создание партиция баз данных, основываясь на дате
- Планирование экспорта старых партиций в сжатые файлы
- Избавление от старых партиций без снижения производительности
- Перезагрузка старых партиций, чтобы они снова были доступны для главной партиции
Большинство документации о партицировании, которую я прочитал, просто используется для того чтобы содержать базу данных чистой и опрятной. Если вам нужны старые данные, вам пришлось бы хранить бэкап старой базы. Я покажу вам, как вы можете содержать свою базу данных в здоровом виде с помощью партицирования, но с доступом к старой информации при необходимости без нужды создания резервных копий.
Допущения (Conventions)
Команды выполняемые из под shell, root пользователем имеют следующий префикс:
root# Команды выполняемые из под shell, non-root пользователем, например postgres, имеют следующий префикс:
postgres$ Команды выполняемые внутри PostgreSQL базы данных будут выглядеть следующим образом:
my_database>Что вам потребуется
В примерах мы будем использовать PostgreSQL 9.2 на Engine Yard. Вам также нужен git для установки plsh.
Резюме
Вот краткое описание того, что мы собираемся сделать:
- создать главную таблицу
- создать функцию триггера
- создать триггер таблицы
- создать функцию обслуживания партиции
- запланировать обслуживание партиции
- перегрузить старые партиции, когда это потребуется
Cоздание главной таблицы
Для этого примера мы создадим таблицу для хранения базовой информации о производительности (cpu, memory, disk) группы серверов (server_id) каждую минуту (time).
CREATE TABLE myschema.server_master ( id BIGSERIAL NOT NULL, server_id BIGINT, cpu REAL, memory BIGINT, disk TEXT, "time" BIGINT, PRIMARY KEY (id) );Обратите внимание, имя time заключено в кавычки. Это необходимо, потому что time это ключевое слово в PostgreSQL. Больше о ключевых словах Date/Time и их функции вы можете узнать из документации PostgreSQL.
Создаём функцию триггера
Функция триггера делает следующее:
- Создаёт дочернюю партицию таблиц с динамически генерируемыми “CREATE TABLE” параметрами, если она ещё не существует
- Параметры (дочерних таблиц) определяются значениями колонки “time”, создавая партицию для каждого календарного дня
- Время хранится в формате epoch, который является репрезентацией количества секунд, прошедших с полуночи (00:00:00 UTC) 1 января 1970 года, в виде целого числа
- Каждый день содержит 86400 секунд, полночь каждого дня — это epoch дата, которая делится на 86400 без остатка.
- Имя каждой дочерней таблицы будет в формате myschema.server_YYYY-MM-DD.
CREATE OR REPLACE FUNCTION myschema.server_partition_function() RETURNS TRIGGER AS $BODY$ DECLARE _new_time int; _tablename text; _startdate text; _enddate text; _result record; BEGIN --Takes the current inbound "time" value and determines when midnight is for the given date _new_time := ((NEW."time"/86400)::int)*86400; _startdate := to_char(to_timestamp(_new_time), 'YYYY-MM-DD'); _tablename := 'server_'||_startdate; -- Check if the partition needed for the current record exists PERFORM 1 FROM pg_catalog.pg_class c JOIN pg_catalog.pg_namespace n ON n.oid = c.relnamespace WHERE c.relkind = 'r' AND c.relname = _tablename AND n.nspname = 'myschema'; -- If the partition needed does not yet exist, then we create it: -- Note that || is string concatenation (joining two strings to make one) IF NOT FOUND THEN _enddate:=_startdate::timestamp + INTERVAL '1 day'; EXECUTE 'CREATE TABLE myschema.' || quote_ident(_tablename) || ' ( CHECK ( "time" >= EXTRACT(EPOCH FROM DATE ' || quote_literal(_startdate) || ') AND "time" < EXTRACT(EPOCH FROM DATE ' || quote_literal(_enddate) || ') ) ) INHERITS (myschema.server_master)'; -- Table permissions are not inherited from the parent. -- If permissions change on the master be sure to change them on the child also. EXECUTE 'ALTER TABLE myschema.' || quote_ident(_tablename) || ' OWNER TO postgres'; EXECUTE 'GRANT ALL ON TABLE myschema.' || quote_ident(_tablename) || ' TO my_role'; -- Indexes are defined per child, so we assign a default index that uses the partition columns EXECUTE 'CREATE INDEX ' || quote_ident(_tablename||'_indx1') || ' ON myschema.' || quote_ident(_tablename) || ' (time, id)'; END IF; -- Insert the current record into the correct partition, which we are sure will now exist. EXECUTE 'INSERT INTO myschema.' || quote_ident(_tablename) || ' VALUES ($1.*)' USING NEW; RETURN NULL; END; $BODY$ LANGUAGE plpgsql;Создание триггера для таблицы
Когда функция партиции создана, в главную таблицу нужно добавить триггер ввода. Он будет вызывать функцию партиции, когда будут поступать новые записи.
CREATE TRIGGER server_master_trigger BEFORE INSERT ON myschema.server_master FOR EACH ROW EXECUTE PROCEDURE myschema.server_partition_function(); Теперь вы можете слать строки главной таблице и наблюдать, как они будут помещаться в соответствующие дочерние таблицы.
Создание функции обслуживания партиции
Теперь посадим главную таблицу на диету. Функция ниже была создана, чтобы обобщённо справляться с обслуживанием партиции. Именно поэтому вы не увидите никакого конкретного синтаксиса для сервера.
Как это работает:
- Все дочерние таблицы для определённой главной таблицы сканируются на предмет партиций, где имя партиции соответствует дате большей, нежели 15 дней.
- Каждая “слишком старая” партиция экспортируется в локальную файловую систему, вызвав функцию базы данных myschema.export_partition(text, text). Подробнее об этом в следующем разделе.
- Только в том случае, если экспорт в локальную файловую систему прошёл успешно, дочерняя таблица будет опущена (dropped)
- Эта функция подразумевает наличие папки /db/partition_dump на локальном сервере базы данных. Подробнее об этом в следующем разделе. Если вам интересно, куда будут экспортированы эти партиции, то вам как раз туда!
CREATE OR REPLACE FUNCTION myschema.partition_maintenance(in_tablename_prefix text, in_master_tablename text, in_asof date) RETURNS text AS $BODY$ DECLARE _result record; _current_time_without_special_characters text; _out_filename text; _return_message text; return_message text; BEGIN -- Get the current date in YYYYMMDD_HHMMSS.ssssss format _current_time_without_special_characters := REPLACE(REPLACE(REPLACE(NOW()::TIMESTAMP WITHOUT TIME ZONE::TEXT, '-', ''), ':', ''), ' ', '_'); -- Initialize the return_message to empty to indicate no errors hit _return_message := ''; --Validate input to function IF in_tablename_prefix IS NULL THEN RETURN 'Child table name prefix must be provided'::text; ELSIF in_master_tablename IS NULL THEN RETURN 'Master table name must be provided'::text; ELSIF in_asof IS NULL THEN RETURN 'You must provide the as-of date, NOW() is the typical value'; END IF; FOR _result IN SELECT * FROM pg_tables WHERE schemaname='myschema' LOOP IF POSITION(in_tablename_prefix in _result.tablename) > 0 AND char_length(substring(_result.tablename from '[0-9-]*$')) <> 0 AND (in_asof - interval '15 days') > to_timestamp(substring(_result.tablename from '[0-9-]*$'),'YYYY-MM-DD') THEN _out_filename := '/db/partition_dump/' || _result.tablename || '_' || _current_time_without_special_characters || '.sql.gz'; BEGIN -- Call function export_partition(child_table text) to export the file PERFORM myschema.export_partition(_result.tablename::text, _out_filename::text); -- If the export was successful drop the child partition EXECUTE 'DROP TABLE myschema.' || quote_ident(_result.tablename); _return_message := return_message || 'Dumped table: ' || _result.tablename::text || ', '; RAISE NOTICE 'Dumped table %', _result.tablename::text; EXCEPTION WHEN OTHERS THEN _return_message := return_message || 'ERROR dumping table: ' || _result.tablename::text || ', '; RAISE NOTICE 'ERROR DUMPING %', _result.tablename::text; END; END IF; END LOOP; RETURN _return_message || 'Done'::text; END; $BODY$ LANGUAGE plpgsql VOLATILE COST 100; ALTER FUNCTION myschema.partition_maintenance(text, text, date) OWNER TO postgres; GRANT EXECUTE ON FUNCTION myschema.partition_maintenance(text, text, date) TO postgres; GRANT EXECUTE ON FUNCTION myschema.partition_maintenance(text, text, date) TO my_role; Функция, которую вы видите ниже, тоже является обобщающей и позволяет вам передать имя таблицы, которую вы хотите экспортировать в ОС, и имя
сжатого файла, который будет содержать эту таблицу.
-- Helper Function for partition maintenance CREATE OR REPLACE FUNCTION myschema.export_partition(text, text) RETURNS text AS $BASH$ #!/bin/bash tablename=${1} filename=${2} # NOTE: pg_dump must be available in the path. pg_dump -U postgres -t myschema."${tablename}" my_database| gzip -c > ${filename} ; $BASH$ LANGUAGE plsh; ALTER FUNCTION myschema.export_partition(text, text) OWNER TO postgres; GRANT EXECUTE ON FUNCTION myschema.export_partition(text, text) TO postgres; GRANT EXECUTE ON FUNCTION myschema.export_partition(text, text) TO my_role;Обратите внимание, что код сверху использует расширение языка plsh что объясняется ниже. Также следует отметить, что в нашей системе bash находится в /bin/bash.
Интересно, не правда ли?
Все почти готово. Пока что мы сделали все необходимые изменения внутри базы данных, чтобы разместить партиции таблиц:
- Создали новую главную таблицу
- Создали триггер и функцию триггера для главной таблицы
- Создали функцию обслуживания партиции для экспорта старых партиций и их опускания
Что же нам осталось сделать для автоматизации обслуживания:
- Установить расширение plsh
- Настроить ОС для хранения дампов партиций
- Создать cron job для автоматизации вызова функции обслуживания партиции
Настройка PostgreSQL и OS
Включение PLSH в PostgreSQL
Расширение PLSH необходимо в PostgreSQL для запуска shell команд. Оно используется в myschema.export_partition(text,text) для того, чтобы динамически создавать shell строки для запуска pg_dump. Из под root, запустите следующие команды
root# cd /usr/local/src # создайте расширение файлов .so для postgresql root# curl -L href="https://github.com/petere/plsh/archive/9a429a4bb9ed98e80d12a931f90458a712d0adbd.tar.gz">https://github.com/petere/plsh/archive/9a429a4bb9ed98e80d12a931f90458a712d0adbd.tar.gz -o plsh.tar.gz root# tar zxf plsh.tar.gz root# cd plsh-*/ root# make all install # Внимание! postgres header файоы должны быть доступны root# su - postgres # или любой акаунт под которым доступен postgresql postgres$ psql my_database # Подставьте имя своей базы данных с таблицами партиций my_database> CREATE EXTENSION plsh; # ВНИМАНИЕ: Это нужно делать для каждой базы данных Создайте папку
root# mkdir -p /db/partition_dump Проследите за тем, чтобы postgres пользователю принадлежала папка, и чтобы группа deployment пользователя имела доступ для чтения этих файлов. Пользователь для развёртывания по умолчанию в Engine Yard Cloud является пользователь ‘deploy’.
root# chown postgres:deploy /db/partition_dump Больше информации о PL/SH вы можете найти в документации проекта plsh.
Планирование обслуживания партиции
Команда ниже запланирует запуск partition_maintenance каждый день в полночь
root# su - postgres ## это пользователь ОС, который запустит cron job postgres$ mkdir -p $HOME/bin/pg_jobs ## это папка содержащая нижестоящий скрипт postgres$ cat > $HOME/bin/pg_jobs/myschema_partition_maintenance #!/bin/bash # ВНИМАНИЕ: psql должна быть доступна по этому пути. psql -U postgres glimpse <<SQL SELECT myschema.partition_maintenance('server'::text, 'server_master'::text, now()::date ); SQL ## теперь нажмите <ctrl+d>для прекращения режима ввода команды “cat” postgres$ exit ## выход пользователя postgres ОС и запуск рутом: root# chmod +x /home/postgres/bin/pg_jobs/myschema_partition_maintenance # Make script executable root# crontab -u postgres -e ## добавим строку: 0 0 * * * /home/postgres/bin/pg_jobs/myschema_partition_maintenance Просмотрите cron jobs для пользователя postgres, чтобы убедиться, что crontab строка верна:
root# crontab -u postgres -l0 0 * * * /home/postgres/bin/pg_jobs/myschema_partition_maintenance
Убедитесь в том, что сделана резервная копия папки /db/partition_dump, если вы не пользуетесь инстансом на Engine Yard Cloud. Если вам опять потребуется эта информация, вам будут нужны эти файлы для восстановления старых партиций. Это можно сделать с помощью rsyncing (копирования) этих файлов на другой сервер для пущей уверенности. Мы считаем, что для такого архивирования отлично подходит S3.
Итак, мы запланировали, что обслуживание вашей главной таблицы будет совершаться в определённое время, и вы можете расслабиться, зная, что вы сделали что-то особенное: проворную базу данных, которая сама будет придерживаться диеты!
Загружаем старые партиции
Если вас томит разлука по старым данным, или может быть запрос на комплаенс-контроль очутился на вашем рабочем столе, вы всё еще можете загрузить старые партиции из системных файлов.
Для этого мы направимся к папке /db/partition_dump на вашем локальном db сервере и идентифицируем нужный файл. Затем пользователь postgres импортирует этот файл в базу данных.
postgres$ cd /db/partition_dump postgres$ ls # находим файл требуемого дампа партиции postgres$ psql my_database < name_of_partition_dump_file После того, как файл загружен, к нему опять можно слать запросы из главной таблицы. Не забывайте о том, что в следующий раз когда планировщик запустит обработку партиции, эта старая партиция опять будет экспортирована.
Посмотрим это в работе
Создание дочерних таблиц
Загрузим две строки с информацией, чтобы посмотреть на новую дочернюю партицию в действии. Откройте psql сессию и запустите следующую команду:
postgres$ psql my_database my_database> INSERT INTO myschema.server_master (server_id, cpu, memory, disk, time) VALUES (123, 20.14, 4086000, '{sda1:510000}', 1359457620); --Will create "myschema"."servers_2013-01-29" my_database> INSERT INTO myschema.server_master (server_id, cpu, memory, disk, time) VALUES (123, 50.25, 4086000, '{sda1:500000}', 1359547500); --Will create "myschema"."servers_2013-01-30" Так что же произошло? Предполагая, что вы в первый раз запустили это, две дочерние таблицы были созданы. Смотрите комментарии в sql сообщении по поводу создания дочерних таблиц. Первый insert можно увидеть, выбирая из главной или из дочерней таблицы:
SELECT * FROM myschema.server_master; --обе записи видны SELECT * FROM myschema."server_2013-01-29"; --виден только первый ввод Заметьте, что мы используем двойные кавычки вокруг имени таблицы дочерней партиции. Мы делаем это не потому, что это унаследованная таблица, а из-за дефиса, использованного между год-месяц-день.
Запускаем обслуживание таблиц
Двум строкам, которые мы внесли более 15 дней. После ручного запуска обслуживания партиции (как было бы запущено через cron) две партиции будут экспортированы в ОС, и эти партиции будут опущены (dropped).
postgres$ /home/postgres/bin/pg_jobs/myschema_partition_maintenance
После завершения мы сможем увидеть два экспортированных файла:
postgres$ cd /db/partition_dump postgres$ ls -alh … -rw------- 1 postgres postgres 1.0K Feb 16 00:00 servers_2013-01-29_20130216_000000.000000.sql.gz -rw------- 1 postgres postgres 1.0K Feb 16 00:00 servers_2013-01-30_20130216_000000.000000.sql.gz При попытке выбрать в главной таблице вернёт вам 0 строк, так что две дочерние таблицы больше не существуют.
Загрузка старых партиций
если вы захотите загрузить старые дочерние таблицы, то сначала gunzip, а затем загрузка с помощью psql:
postgres$ cd /db/partition_dump postgres$ gunzip servers_2013-01-29_20130216_000000.000000.sql.gz postgres$ psql my_database < servers_2013-01-29_20130216_000000.000000.sql Если послать select главной таблице, результатом будет 1 строка — дочерняя таблица восстановлена.
Заметки
Наши файлы базы данных находятся на партиции на /db которая отделена от нашей root (‘/’) партиции.
Для дальнейшего ознакомления с PostgreSQL расширениями почитайте следующую документацию.
Движок базы данных не вернёт правильное количество строк затронутых таблиц (всегда 0 затронутых таблиц) после отправки INSERT или UPDATE в главную таблицу. Если вы используете Ruby, не забудьте подправить код, учитывая, что pg джем не будет правильно отображать правильные значения при отчётностях cmd_tuples. Если вы используете ORM, тогда, будем надеяться, они подправят это соответствующим образом.
Не забудьте сделать резервные копии экспортированных партиций в /db/partition_dump, эти файлы лежат вне стандартного пути создания бэкапов базы данных.
Пользователь базы данных, который осуществляет INSERT в главную таблицу, также должен иметь DDL права для создания дочерних таблиц.
При осуществлении INSERT в главную таблицу будет заметно небольшое изменение производительности, так как будет запущена функция триггера.
Проследите за тем, чтобы использовать последнюю версию PostgreSQL. Это гарантирует, что вы работаете с самой стабильной и безопасной версией.
Это решение работает для моей ситуации, ваши требования могут быть другими, так что не стесняйтесь изменять, дополнять, калечить, истерически смеяться или копировать это для своих целей.
P.S. Перевод мой. Надеюсь статья будет полезна.
ссылка на оригинал статьи http://habrahabr.ru/company/engineyard/blog/171745/
Добавить комментарий