История проекта
Начиналось все прекрасно и безоблачно. Для нужд одного крупного банка было необходимо реализовать калькулятор, вычисляющий значение Value-at-Risk для конкретного инвестиционного портфеля. Как и большинство финансовых приложений методология не подразумевает “тяжелых” вычислений, но поток данных порой по истине огромен.
Проблемы обработки большого объема данных обычно решаются за счет двух известных типов масштабирования: вертикального и горизонтального. С вертикальным все обстояло достаточно приемлемо. В нашем распоряжении была машина о 16 ядрах, с 16 GB RAM, Red Hat’ом и Java’ой 1.6. На таком железе можно было достаточно хорошо развернуться что, собственно, мы и успешно делали на протяжении нескольких.
Все было прекрасно до того момента, как к нам не постучался заказчик и не сказал, что IT-инфраструктура пересмотрена и вместо 16×16 мы имеем 4×1-2:

Естественно, было увеличено требование времени работы приложения в несколько раз, но. Передать наши эмоции на тот момент было достаточно трудно, но речь, внезапно, стала сильно приправлена различными аллегориями, аллюзиями и сравнениями.
Первые попытки
Для начала поясню, что представляет из себя Value-at-Risk калькулятор. Это программа с большим количеством «простых» вычислений, пропускающая сквозь себя большой объем данных.
Ключи оптимизации, которые были наиболее полезны:
- -server — крайне полезный ключ, JVM разворачиваем циклы, инлайнит многие функции и т.д.
- Работа со строками: -XX:+UseCompressedStrings, -XX:+UseStringCache, -XX:+OptimizeStringConcat
Естественно, такой простой прием не дал желаемых результатов и мы продолжили копать в направлении дальнейших возможностей «ужатия» приложения. Первое, что было решено сделать это удалить ненужные кэши и оптимизировать существующие (те, которые дают 20% прироста производительности из 80%). Ненужные были быстро удалены, а для работы над оставшимися мы решили посмотреть на различные типы ссылок в Java.
Итак, у нас доступны следующие типы ссылок:
- Hard/Strong
- Soft
- Weak
- Phantom
Зависимости между ними выглядят примерно так:
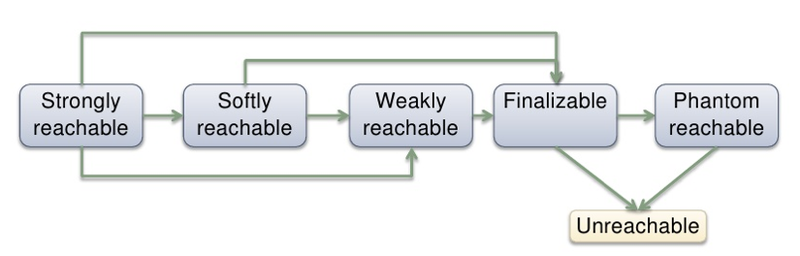
Посмотрим, что же гарантирует спецификация по работе с этими типами ссылок.
Hard/Strong ссылки — это самые обычные ссылки, которые создаются, когда мы используем ключевое слово «new». Такая ссылка будет удалена, когда количество ссылок на созданный объект достигнет нуля. Мягкие ссылки (Soft) могут быть удалены в случае, если виртуальной машине недостаточно памяти для дальнейшей работы. Слабые ссылки (Weak) могут быть собраны в любой момент, если GC так решит. Фантомная ссылка (Phantom) — это специальный тип ссылок, который необходим для более гибкой файнализации объектов, чем классический finalize.
Hard и Phantom ссылки были сразу же убраны из нашего рассмотрения в силу того, что не дают требуемой функциональности и гибкости. Hard не удаляются в нужный момент, а с файнализацией все было в порядке.
Рассмотрим, к примеру, то, как собираются Weak ссылки:

Видим, что у нас нет никакой гарантии того, что объект будет доступен все время и может быть удален в произвольный момент времени. Из-за этой специфики было решено перестроить внутренние, наиболее «тяжелые» кэши на Soft ссылки. Нами двигало примерно следующее утверждение: «Пусть объект живет в кэше как можно дольше, но в случае недостатка памяти мы сможем вычислить его заново, в силу того, что требования по времени работы были увеличены».
Результаты были существенны, но работы приложения в вожделенных 4ГБ не принесли.
Детальное исследование
Дальнейшие исследования проводились с помощью различных средств профилирования:
- Стандартные средства JVM: -XX:+PrintGCDetails, -XX:+PrintGC, -XX:PrintReferenceGC, etc
- MXBean
- VisualVM
Сбор данных занял не так много времени, в отличии от анализа. Проведя несколько замечательных дней за наблюдение цифр и букв были сделаны следующие выводы: создается очень много объектов и старое поколение очень перегружено. Для того, что бы решить эту проблему мы стали смотреть в сторону различных сборщиков мусора и приемов работы с ними.
Во-первых, необходимо было уменьшить количество генерируемых объектов. Было замечено, что большинство данных имеют схожую структуру: «XXX1:XXX2:XXX3 и тд». Все паттерны типа «XXX» были заменены ссылками на объекты из пула, что дало существенное уменьшение количества создаваемых объектов (примерно в пять раз), а также освободило дополнительный объем драгоценной памяти.
Во-вторых, мы решили более детально поработать со стратегиями сборки мусора. Как мы знаем, у нас доступны следующие стратегии сборки мусора:
- Serial
- Parallel
- Parallel compacting
- Concurrent Mark-Sweep
- G1 collector
G1 был нам недоступен в силу того, что использовалась шестая версия Java. Serial и Parallel мало чем отличаются и не очень хорошо показали себя на нашей задаче. Parallel compacting был и интересен за счет фазы, позволяющий уменьшить дефрагментацию данных. Concurrent Mark-Sweep был интересен за счет того, что позволял уменьшить время на фазу stop-the-world и также не допускал сильную фрагментацию.
После сравнения Parallel compacting и Concurrent Mark-Sweep коллекторов было решено остановиться на втором, что оказалось хорошим решением.
После боевого испытания всех вышеописанных приемов приложение стало полностью совместимо с новыми требованиями и успешно запущено в продакшен! Все с облегчением вздохнули!
Полученный урок
- Помогли ключи работы со строками: -XX:+UseCompressedStrings, -XX:+UseStringCache, -XX:+OptimizeStringConcat и сама специфика строковых данных
- Уменьшение количества используемых объектов
- Тонкая настройка JVM занимаем много времени, но результаты более чем оправдывают себя
- Узнавайте требования как можно раньше! 🙂
Более развернутую версию проблемы и этапах решения можно будет послушать на приближающейся конференции JPoint, которая пройдет в Санкт-Петербурге.
ссылка на оригинал статьи http://habrahabr.ru/company/luxoft/blog/174231/
Добавить комментарий