
Если вас интересует сравнение, то оно в самом конце, а здесь я пока расскажу как создать текстовый индекс в Монго и что с ним можно сделать.
Раньше для поиска текста в монге можно было использовать либо регулярные выражения, либо собственноручно созданные и проиндексированные массивы со словами. Основным недостатком поиска по регулярным выражения было, то что он не мог эффективно использовать индексы для всех запросов, да и нетривиальные регулярные выражения сложно писать. Индекс использовался хорошо, когда регулярное выражение указывало найти что-то в самом начале строки и еще в нескольких других случаях. Другой вариант с индексом созданным по массиву слов, полученных после разделения предложений, обходил этот недостаток, но был не удобным.
Теперь совершенно не нужно ничего делать чтобы получить быстрый поиск по тексту. Создаем текстовый индекс, делаем запрос, а система сама убирает стоп слова, делает токены, стемминг и проставляет числовую характеристику обозначающую релевантность результата. Для стемминга используется Стеммер Портера. Список стоп слов можно посмотреть на гитхабе — например для русского языка.
dutch
english
finnish
french
german
hungarian
italian
norwegian
portuguese
romanian
russian
spanish
swedish
turkish
Начнем с результата который можно получить:
db.text.runCommand( "text" , { search: "меч",project:{text:1,_id:0},limit: 3 } )
{ "queryDebugString" : "меч||||||", "language" : "russian", "results" : [ { "score" : 1, "obj" : { "text" : "Мой меч был отбит его щитом; его меч наткнулся на мой" } }, { "score" : 0.85, "obj" : { "text" : "С этим странным выкриком скелет несколько раз махнул мечом; с каждым взмахом меч оставлял в воздухе голубоватый след" } }, { "score" : 0.8333333333333334, "obj" : { "text" : "Лоуренс тоже слышал, что рыцари, клянясь кому-то в верности, передают ему щит и меч, ибо щит и меч являют собой саму душу рыцаря" } } ], "stats" : { "nscanned" : 168, "nscannedObjects" : 0, "n" : 3, "nfound" : 3, "timeMicros" : 320 }, "ok" : 1 }
Как видно монго нашла предложения, где чаще всего встречалось слово «меч», а также предложение где у слова изменено окончание «мечом»
Подключение текстового поиска
Текстовый поиск еще в режиме тестирования, так что необходимо явно указать соответствующую опцию mongod при запуске:
mongod --setParameter textSearchEnabled=true Создание текстового индекса
Основная команда для создания индекса:
db.collection.ensureIndex( {subject: "text", content: "text"} ) после которой будет проиндексирован весь текст в полях subject и content, выбранной коллекции
По дефолту индекс создается для английского языка, чтобы изменить это необходимо задать опцию default_language:
db.collection.ensureIndex( { content : "text" }, { default_language: "russian" }) также есть возможность создавать индекс, который к каждому документу будет применять тот язык, который указан в заданном поле документа — документация
Так же можно создать индекс, который будет искать по всем полям в документе.
Команда для создания индекса который будет рассчитывать вес результата в зависимости от веса поля указанного при создании:
db.blog.ensureIndex( {content: "text",keywords: "text", about: "text"}, {weights: { content: 10,keywords: 5, },name: "TextIndex" }) Выполнение запроса на поиск
Была добавлена новая, команда, которая позволяет делать поиск по тексту — «text»:
db.collection.runCommand( "text", { search: "меч" } ) «text» — комманда, «меч» — искомое слово
Если для поиска указать несколько слов через пробел, то они будут объединены логическим оператором ИЛИ(опции для логического И нет)
Чтобы найти точное совпадение с заданным словом или выражением его необходимо взять в кавычки:
db.quotes.runCommand( "text", { search: "\"сегодня завтра\"" } ) Если необходимо из результатов исключить тексты с определенным словом, то в запросе достаточно поставить "-" перед этим словом, например:
db.quotes.runCommand( "text" , { search: "сегодня -завтра" } ) Ограничение количества результатов задается опцией limit:
db.quotes.runCommand( "text", { search: "tomorrow", limit: 2 } ) Возвращаемые поля задаются опцией project:
db.quotes.runCommand( "text", { search: "tomorrow", project: { "src": 1 } } ) Для того чтобы выполнить поиск по документам с заданным полем, нужно задать опцию filter:
db.quotes.runCommand( "text", { search: "tomorrow", filter: { speaker : "macbeth" } } ) Разбор результата
Рассмотрим результат поиска:
вырезана часть скобок
{ "queryDebugString" : "долг|хабр|чест||||||", "language" : "russian", "results" : "score" : 1.25, "obj" : { "text" : "- Накормить долг долгом" "score" : 0.9166666666666667, "obj" : { "text" : "В результате это я окажусь перед тобой в долгу, и этот долг мне никогда не выплатить" "score" : 0.8863636363636365, "obj" : { "text" : "Оставить реальный мир и полететь прямо в эту крепость… долго-долго это была моя единственная мечта" "stats" : { "nscanned" : 145, "nscannedObjects" : 0, "n" : 3, "nfound" : 3, "timeMicros" : 155 }, "ok" : 1 } Здесь:
queryDebugString — в документации не написано, что это, но наверно это слова после стемминга
language — язык, который был использован для поиска
results — список результатов
score — характеристика показывающая как точно запрос совпадает с результатом
словарь stats — дополнительная информация
nscanned — сколько документов найдено с помощью индекса
nscannedObjects — документы просканированные без использования индекса(чем меньше этот параметр тем лучше)
n — количество возвращенных результатов
nfound — количество совпадений
timeMicros — длительность поиска и микросекундах
Text search против $regex+index
db.text.runCommand( "text" , { search: "находить",project:{text:1,_id:0}} ).stats { "nscanned" : 77, "nscannedObjects" : 0, "n" : 77, "nfound" : 77, "timeMicros" : 153 } db.text2.find( { text: { $regex: 'находить'} }).explain(); { "cursor" : "BtreeCursor text_1 multi", "n" : 5, "nscannedObjects" : 5, "nscanned" : 15821, "nscannedObjectsAllPlans" : 5, "nscannedAllPlans" : 15821, "indexOnly" : false, "millis" : 31, "indexBounds" : { "text" : [["",{}], [ /находить/, /находить/ ] ] }, } таблицы text и text2 являются одинаковыми:
{
«ns»: «text_test.text»,
«count»: 15821,
«size»: 3889044,
«avgObjSize»: 245.8153087668289,
«storageSize»: 6983680,
«numExtents»: 5,
«nindexes»: 2,
«lastExtentSize»: 5242880,
«paddingFactor»: 1,
«systemFlags»: 0,
«userFlags»: 1,
«totalIndexSize»: 7358400,
«indexSizes»: {
"_id_": 523264,
«text_text»: 6835136
},
«ok»: 1
}
> db.text2.stats()
{
«ns»: «text_test.text2»,
«count»: 15821,
«size»: 2735244,
«avgObjSize»: 172.8869224448518,
«storageSize»: 5591040,
«numExtents»: 6,
«nindexes»: 2,
«lastExtentSize»: 4194304,
«paddingFactor»: 1,
«systemFlags»: 0,
«userFlags»: 0,
«totalIndexSize»: 3008768,
«indexSizes»: {
"_id_": 523264,
«text_1»: 2485504
},
«ok»: 1
}
Разница из-за различных индексов, а данные совершенно одинаковые
Как видно из результатов поиск с регулярным выражением выполнился за 31 миллисекунду, а поиск по текстовому индексу за 151 микросекунду, что в 200 раз меньше.
MongoDB vs Sphinx
Сравнение проводилось на ОС Ubuntu 12.10(Core i5, 8GB RAM, Hard drive(without raid)). Кандидаты: МонгоДМ 2.4.1 и Сфинкс 2.0.6. В Монге и Mysql были созданы таблицы вида id, text. Таблицы были идентичными и содержали 16 миллионов записей. В Монге был создан текстовый индекс. В сфинксе также был сконфигурирован индекс для поиска текста, дополнительно включены опции использования листа стоп слов и алгоритма стемминга. Для взаимодействия с конкурсантами были использованы питоновские клиенты — sphinxapi и pymongo.
Тест заключался в поиске тысячи слов в таблице. Был осуществлен «прогрев» и несколько повторных выполнений. В сфинксе никакие доп настройки включены не были за исключением стемминга, стопслов и увеличение доступного объема памяти. Использование памяти у программ приблизительно идентичное, 2.2 Гб использовал Сфинкс, 2.5 Гб использовала Монго.
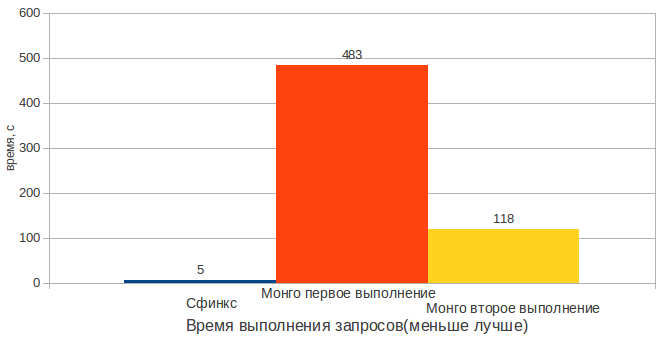
Как видно из результатов Монго проигрывает. Из-за специфочной работы с ОП Монго производит поиск во второй раз быстрее чем в первый. Это происходит из-за того что Монго хранит в памяти только востребованные данные. В певое выполнение теста индекс еще не был загружен в память. Но даже в случае загруженного индекса Монго работает более чем в 20 раз медленее.
При поиске по меньшим таблицам разрыв сокращается, но все равно находится в районе 10 кратного преймущества Сфинкса.
Также стоит отметить, что текстовый индекс в Монге для хранения себя использует примерно в 2 раза больше памяти чем проиндексированные данные.
Вывод
С внушительным отрывом в поиске текста побеждает Сфинкс.
В защиту Монго можно сказать, что:
- у монго еще много функций кроме текстового поиска
- её проще масштабировать горизонтально, повышая при этом производительность
- текстовый поиск еще в тестовом режиме
- текстовый поиск в Монго значительно проще для изучение и хорошо документирован, требует для изучения на пару часов меньше чем Сфинкс, который не блещет документацией и клиентами.
Не считаю, что эта новая функция МонгоДБ сильно изменит расклад сил в сфере хранения данных, но все-таки является приятным дополнением.
ссылка на оригинал статьи http://habrahabr.ru/post/174457/
Добавить комментарий