 В Badoo используется много сервисов на C и C++, большинство из которых работают с огромными объёмами данных. Как правило, сервисы выступают в роли «быстрого кэша» или «быстрой базы данных», т.е. совершают различные операции с массивами однотипных данных. Для быстрого доступа к данным мы давно и успешно используем Judy-массивы (англ. Judy arrays). Но однажды нам захотелось странного: обрабатывать большие массивы целых чисел на PHP, и мы сразу вспомнили про Judy.
В Badoo используется много сервисов на C и C++, большинство из которых работают с огромными объёмами данных. Как правило, сервисы выступают в роли «быстрого кэша» или «быстрой базы данных», т.е. совершают различные операции с массивами однотипных данных. Для быстрого доступа к данным мы давно и успешно используем Judy-массивы (англ. Judy arrays). Но однажды нам захотелось странного: обрабатывать большие массивы целых чисел на PHP, и мы сразу вспомнили про Judy.
Немного истории
Judy-массивы были изобретены Дугласом Баскинсом (англ. Douglas Baskins) в начале 2000-го года. Проект их разработки финансировался компанией HP, но примерно через два года был закрыт. За это время было выпущено четыре версии, причём разработка последней заняла больше года, и в ней разработчики смогли в два раза ускорить Judy, в два раза уменьшить потребление памяти, хоть и далось это нелёгкой ценой: объём кода вырос в 5 раз, а его сложность ― на порядок.
Алгоритм работы Judy-массивов запатентован, однако оригинальная реализация на C доступна на официальном сайте под лицензией LGPL.
Проект назвали именем сестры Баскинса, потому что разработчики не смогли придумать варианта лучше.
Массивы-деревья
По правде говоря, Judy-массивы не являются собственно массивами. Judy ― это развитие trie, т.е. префиксного дерева, с использованием разных методик сжатия. Judy-массивы выгодно отличаются от C-массивов и стандартных реализаций хеш-массивов: разреженные Judy-массивы эффективно используют память и прекрасно масштабируются, при этом показывая сравнимую скорость чтения и записи (см. бенчмарки).
Подробное описание алгоритма работы Judy вряд ли уместится в формат статьи для Хабра, поэтому мы просто оставим ссылки на официальную документацию: 1 и 2.
Существует несколько типов Judy-массивов:
- Judy1 ― битовый массив (bitmap), индексом является целое число (integer->bit);
- JudyL ― массив c целым числом в качестве индекса (integer->integer/pointer);
- JudySL ― массив указателей со строкой в качестве индекса (string->integer/pointer);
- JudyHS ― массив указателей с набором байт в качестве индекса (array of bytes->integer/pointer).
Массивы Judy не требуют инициализации, и пустой массив ― это простой NULL-указатель. Следствием этого является то, что Judy-массивы удобно вкладывать друг в друга. Настолько удобно, что JudySL и JudyHS ― это на самом деле вложенные массивы JudyL.
Бенчмарки
Встроенные массивы в PHP ― вещь универсальная и, как следствие, крайне неэффективная в некоторых случаях. Если сравнивать с Judy, то реализованы они довольно тривиально: это хеш-массивы с двусвязным списком внутри каждого элемента на случай коллизий хеша. Хранят PHP-массивы переменные PHP, т.е. указатели на структуры zval. В подавляющем большинстве случаев именно это от них и требуется, однако есть исключения.
Чтобы продемонстрировать, почему мы решили использовать Judy, проведём сравнительное тестирование Judy и PHP-массивов. В качестве интерфейса к Judy из PHP используем модуль php-judy, в котором имплементирован класс Judy с реализацией интерфейса ArrayAccess. В тесте создадим массивы вида integer -> integer (array(), Judy::INT_TO_INT, Judy::INT_TO_MIXED) или integer->boolean (Judy::BITSET) и заполним их элементами с последовательными ключами.
Для начала замерим скорость записи в массивы с помощью подобного кода:
<?php $arr = array(); for ($i = 0; $i < 10000000; $i++) { $arr[] = 1; } ?> 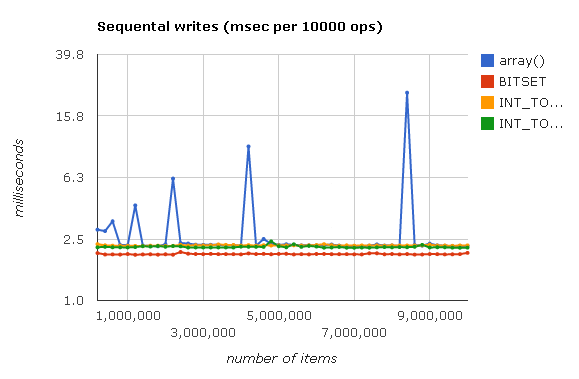
Интерактивный график см. здесь.
Пики при записи array() вызваны удвоением размера массива и его перестроением при заполнении всех элементов хеша. Небольшие возвышенности на графиках Judy можно объяснить погрешностью измерений.
Из графика видно, что разные виды Judy по скорости записи примерно равны встроенному массиву. Единственное исключение ― BITSET (Judy1), который чуть быстрее.
Потом замерим скорость последовательного чтения из массивов:
<?php /* …*/ /* предварительно заполняем массив, потом в цикле читаем все элементы */ $arr = array(); for ($i = 0; $i < 10000000; $i++) { $val = $arr[$i]; } ?> 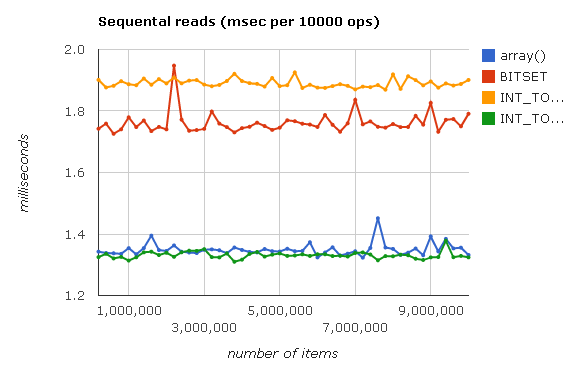
Интерактивный график см. здесь.
Из графика видно, что при чтении Judy::BITSET и Judy::INT_TO_INT незначительно проигрывают встроенному массиву PHP. Это происходит потому, что в этих массивах хранятся биты и целые числа соответственно, а не переменные PHP (т.е. zval). Именно накладные расходы на создание и заполнение переменных и отнимают у нас выигрыш в производительности.
С другой стороны, array() и Judy::INT_TO_MIXED хранят внутри как раз переменные PHP, и им не надо тратить время на их создание, поэтому они примерно равны по скорости.
Наконец, замерим потребление памяти при заполнении массивов и получим следующий график:
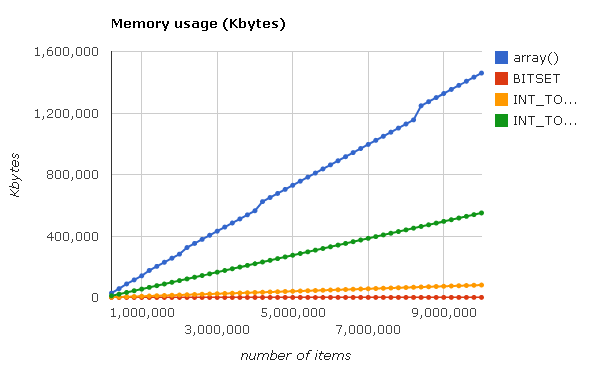
Интерактивный график по см. здесь.
Как видно из графика, разница в потреблении памяти между PHP-массивами и Judy1/JudyL огромна, и для нас это является главным критерием в данном случае, т.к. мы вполне можем пожертвовать частью скорости при чтении из массива, получив взамен возможность работать с массивами гораздо большего размера, которые раньше вообще не умещались в оперативную память сервера.
Таким образом, использование Judy-массивов в PHP оправдано при решении задач, связанных с обработкой больших массивов данных, особенно целых чисел и битов. С точки зрения скорости чтения и записи Judy-массивы не слишком отличаются от встроенных массивов, однако из-за отличий в имплементации они гораздо эффективнее используют память.
Предваряя ваши вопросы, заметим, что, несмотря на свои явные преимущества, Judy-массивы вряд ли смогут заменить штатные массивы в PHP хотя бы потому, что последние могут одновременно содержать как целочисленные индексы, так и строчные, в то время как в Judy это реализуется с помощью двух разных типов массивов.
ссылка на оригинал статьи http://habrahabr.ru/company/badoo/blog/175085/
Добавить комментарий