Прошлой осенью в блоге команды SwiftStack появился интересный обзор их подхода к созданию мультирегиональных кластеров Объектного хранилища OpenStack (кодовое название проекта — Swift). Этот подход хорошо сочетается со схемой географически распределенного кластера Swift с сокращенным числом реплик (3+1 вместо 3+3, например), над которой мы совместно работали с компанией Webex примерно в это же время. Я хотел бы кратко описать наш подход и остановиться на плане внедрения и предлагаемых изменениях кода Swift.
Текущее состояние OpenStack Swift
Я хотел бы начать с краткого обзора текущих алгоритмов Swift, чтобы затем пояснить, что именно требуется сделать, чтобы создать кластер из нескольких географически разделенных регионов.
Ring
Стандартное кольцо (ring или hash ring) кластера Swift представляет собой структуру данных, которая позволяет разделить устройства хранения по зонам. Скрипт построения колец (swift-ring-builder), включенный в релиз Essex, гарантирует, что реплики объектов не попадают в одну и ту же зону.
Структура кольца включает следующие компоненты:
— Список устройств: включает все устройства хранения (диски), известные кольцу. Каждый элемент этого списка представляет собой словарь, который включает идентификатор устройства, его символьное название, идентификатор зоны, IP-адрес узла-накопителя данных, на котором установлено устройство хранения, сетевой порт, вес и метаданные.
— Таблица распределения разделов: двумерный массив с числом строк равным числу реплик. Каждая ячейка массива содержит идентификатор устройства (из списка устройств), на котором располагается реплика раздела, соответствующего индексу столбца…
— Номер области раздела: число битов из контрольной суммы MD5 от пути до объекта (/account/container/objec), которое определяет разбиение всего пространства возможных хэшей MD5 на разделы.
В версии Folsom были внесены изменения в формат файла кольца. Эти изменения значительно повышают эффективность обработки и переопределяют алгоритм балансировки кольца. Строгое условие, которое требовало распределения реплик по различным зонам, было заменено гораздо более гибким алгоритмом, организующим зоны, узлы и устройства в слои.
Балансировщик кольца пытается расположить реплики как можно дальше друг от друга; предпочтительно в различные зоны, но если доступна только одна зона, тогда в различные узлы; а если доступен только один узел, то в различные устройства на узле. Этот алгоритм, действующий по принципу “максимального распределения”, потенциально поддерживает географически распределенный кластер. Этого можно достигнуть с помощью добавления на вершину схемы уровня региона. Регион представляет собой по сути группу зон с одним расположением, будь это стойка или целый ЦОД.
В нашем предложении регион определен в одноименном поле (region) в словаре устройств devs.
Прокси-сервер
Прокси-сервер предоставляет публичный интерфейс Swift API клиентам и выполняет базовые операции с объектами, контейнерами и аккаунтами, в том числе запись с помощью запроса PUT и чтение с помощью запроса GET.
При обслуживании запросов PUT прокси-сервер следует указанному ниже алгоритму:
1. Вычисляет контрольную сумму MD5 пути до объекта в формате /account[/container[/object]].
2. Вычисляет номер раздела как первые N бит контрольной суммы MD5.
3. Выбирает устройства из таблицы распределения разделов, на которых хранятся реплики вычисленного раздела.
4. Выбирает IP-адрес и порт узла-накопителя данных из списка устройств для всех устройств, найденных на шаге #3.
5. Проубет установить подключение ко всем узлам по соответствующим портам, если невозможно подключиться как минимум к половине узлов, отклоняет запрос PUT.
6. Пробует загрузить объект (или создать аккаунт или контейнер) на всех узлах, к которым были установлено подключение; если как минимум половина загрузок отменена, отклоняет запрос PUT.
7. Если данные загружены на N/2+1 узлов (где N — число узлов, найденных на шаге #4), отправляет подтверждение успешного запроса PUT клиенту.
При обслуживании запросов GET, прокси-сервер в общих чертах выполняет следующий алгоритм:
1. Повторяет шаги 1-4 алгоритма обработки запроса PUT и определяет список узлов, которые хранят реплики объектов.
2. Перемешивает список узлов с помощью функции shuffle и подключается к первому из полученного списка.
3. Если невозможно установить соединение, переходит к следующему узлу из списка.
4. Если соединение установлено, начинает передавать данные клиенту в ответ на запрос.
Репликация
Репликация в Swift работает по разделам, а не по отдельным объектам. Рабочий процесс репликатора запускается периодически, с настраиваемым интервалом. Интервал по умолчанию составляет 30 секунд.
Репликатор в общих чертах следует следующему алгоритму:
1. Создать задачу репликатора. То есть отсканировать все устройства на узле, отсканировать все найденные устройства и найти список всех разделов, а затем для каждого раздела создать словарь действий по репликации.
{
‘path’: <path_to_partition>,
’nodes’: [ replica_node1, replica_node2,… ],
’delete’: <true|false>,
’partition’: }
— <path_to_partition> — это путь в файловой системе к разделу (/srv/node//objects/)
— [ replica_node1, replica_node2, … ] — это список узлов, которые хранят реплики разделов. Список импортируется из кольца для объектов.
— Для ‘delete’ установлено значение “true”, если число реплик данного раздела превышает настроенное число реплик в кластере.
— представляет собой номер идентификатора раздела.
2. Обработать каждый раздел в соответствии с заданием на репликацию. То есть:
— Если раздел помечен для удаления, репликатор сопоставляет каждый подкаталог каталога job[‘path’] всем узлам из списка job[‘nodes’], отправляет запрос REPLICATE каждому узлу, на котором расположена реплика, и удаляет директорию job[‘path’].
— Если раздел не помечен для удаления, репликатор вычисляет контрольные суммы содержимого всех подпапок директории job[‘path’] (то есть баз данных аккаунта/контейнера и файлов объектов в разделе). Репликатор выдает запрос REPLICATE всем репликам раздела job[‘partition’] и получает в ответ от удаленных подпапок раздела соответствия контрольных сумм. Затем он сравнивает соответствия контрольных сумм и использует rsync для отправки измененных подпапок удаленным узлам. Успешность репликации проверяется за счет повторной отправки запроса REPLICATE.
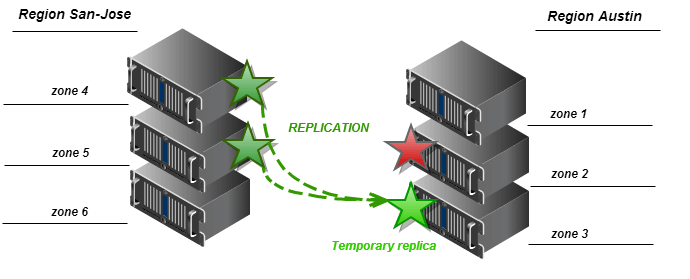
3. Если доступ к так называемой “основной” реплике отсутствует, репликатор использует метод get_more_node класса кольца. Этот метод использует определенный детерминированный алгоритм для определения набора “запасных” узлов, где можно сохранить временную копию данного раздела… Алгоритм определяет зону, к которой принадлежит “основное” устройство, которое дало сбой, и выбирает “запасное” устройство из другой зоны для сохранения временной реплики раздела. Если другое устройство также не доступно, выбирается узел из третьей зоны, и цикл продолжается, пока не будут перебраны все зоны и все узлы.
Предлагаемые изменения в OpenStack Swift
Добавление уровня “региона” в кольцо
Мы предлагаем добавить в список устройств поле региона. Этот параметр должен использовать класс RingBuilder при балансировке кольца описанным ниже способом. Параметр региона представляет собой дополнительный уровень в системе, который позволяет группировать зоны. Таким образом, все устройства, которые принадлежат зонам, составляющим один регион, должны принадлежать этому региону.
Кроме того, регионы могут быть добавлены в кольцо как дополнительная структура—словарь с регионами в качестве ключей и списком зон в качестве значений, например:
| Ключ (регион) | Значение (список зон) |
| Остин | 1,2,3 |
| Сан-Хосе | 4,5,6 |
Важно заметить, что зона может принадлежать только одному региону.
В этом случае регионы используются аналогично предыдущему использованию, но класс кольца должен включать дополнительный код для обработки словаря назначений зон регионов и определять, к какому региону принадлежит определенное устройство.
Назначение зоны региона по умолчанию должно назначать все зоны одному региону по умолчанию для воспроизведения стандартного поведения Swift.
В последнем релизе проекта Swift поддержка уровня регионов в кольце уже добавлена, что означает важный шаг на пути к полноценной реализации географически распределенных хранилищ объектов на базе Swift.
Тонкая настройка алгоритма балансировки RingBuilder
Алгоритм балансировки RingBuilder должен распознавать параметр региона в списке устройств. Алгоритм может быть настроен для распределения реплик различными способами. Ниже мы предлагаем одну из возможных реализаций алгоритма распределения, выбранную нами для разработки прототипа.
Алгоритм поочередного распределения
Реплики разделов следует помещать на устройства с соблюдением следующих условий:
— Реплики должны располагаться на устройствах, принадлежащих различным группам на как можно более высоком уровне (стандартное поведение алгоритма балансировки кольца).
— Для N реплик и M регионов (групп зон) число реплик, попадающих в каждый регион, равно целому числу частного от деления N/M. Остаток реплик добавляется в один регион (который является основным для этого раздела).
— Регион не может содержать больше реплик, чем число зон в регионе.
Например, если N = 3 и M = 2, при этом алгоритме у нас будет кольцо, в котором одна реплика входит в каждый регион (целой частью от дроби 3/2 является 1), а оставшаяся одна реплика входит в один их двух регионов, выбранный случайно. Приведенная ниже схема отражает вариант распределения реплик по регионам в примере выше.

Выполнить прямой запрос PUT от прокси-сервера к узлу хранилища в удаленном регионе не так просто: в большинстве случаев мы можем не иметь доступа к внутренней сети кластера извне. Таким образом, для изначальной реализации мы предполагаем, что только локальные реплики записываются при выполнении запроса PUT, а удаленные региональные реплики создаются процессом репликации.
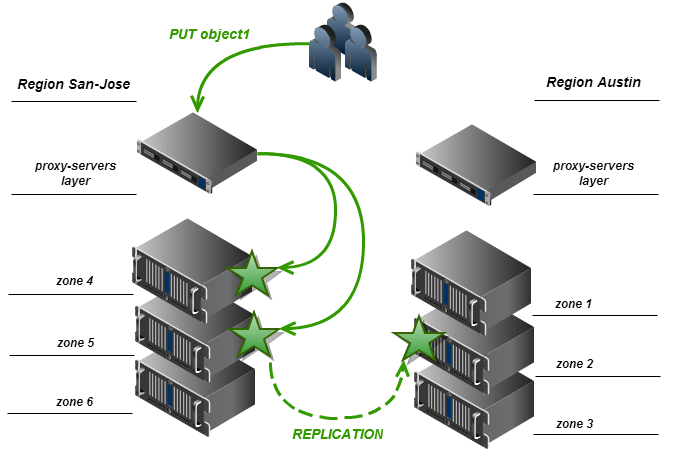
По умолчанию число реплик составляет три, а регионов – один. Этот случай воспроизводит стандартную конфигурацию Swift и алгоритм балансировки кольца.
Ещё раз о Get_more_nodes
Мы предлагаем изменения в методе get_more_nodes класса Ring для распознавания регионов при выборе “запасных” зон для временных реплик. Алгоритм должен выполнять сортировку кандидатов в “запасные” таким образом, чтобы зоны из региона, который содержит потерянную реплику, выбирались первыми. Если в локальном регионе нет доступа к зонам (например, закрыто сетевое соединение между регионами), алгоритм возвращает узел, который принадлежит зоне из одного из внешних регионов. Следующие две схемы описывают алгоритм для двух крайних случаев.
Региональный прокси-сервер
Для правильной работы прокси-сервера Swift в окружении с несколькими географически распределенными регионами, ему необходимо обладать информацией, к какому региону принадлежит. Прокси-сервер может получить эту информацию на основе анализа сетевой задержки при подключении к серверам-накопителям данных, или напрямую из конфигурационного файла. Первый подход реализован в текущей версии Swift (1.8.0). Прокси-сервер сортирует узлы-накопители данных на основе времени отклика после подключения к каждому из них, и выбирает для чтения наиболее быстрый. Такой подход хорошо работает для запросов на чтение, однако при записи требуется работать со всеми “основными” серверами-накопителями, а также, возможно, с несколькими “запасными”. В этом случае лучше подходит конфигурационный способ определения локального региона.
Это достаточно просто реализуется добавлением параметра региона в раздел [DEFAULT] конфигурационного файла прокси-сервера (proxy-server.conf), например:
[DEFAULT]
…
region = san-jose
Этот параметр используется прокси-сервером для операций чтения кольца, а также, возможно, при выборе узлов для обслуживания запросов GET. Наша цель – чтобы прокси-сервер предпочитал подключаться к узлам-накопителям из локальных зон (то есть зон, которые принадлежат тому же региону, что и прокси-сервер).
В статье SwiftStack эта функциональность называется proxy affinity.
Прокси-сервер не должен читать данные с узла, который принадлежит внешнему региону, если доступна локальная реплика. Это позволяет снизить нагрузку на сетевые связи между регионами, а также работать в том случае, когда сетевое соединение между регионами отсутствует (в результате временного сбоя или особенностей топологии кластера).
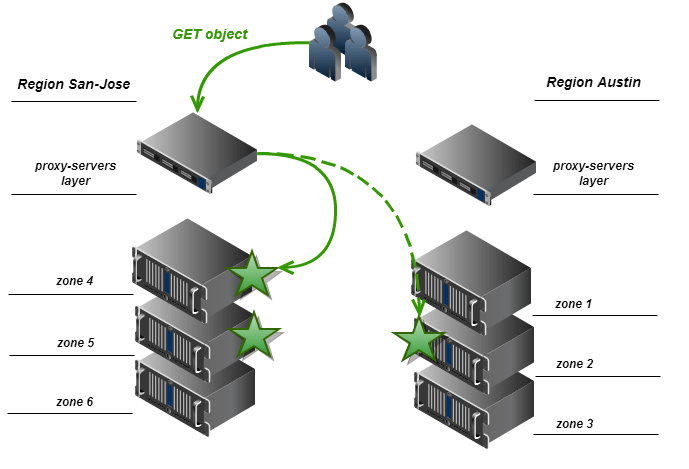
Мы затем заменяем операцию перемешивания списка узлов на шаге #2 алгоритма обработки запроса GET (см. выше) процедурой, которая расположит узлы в таком порядке, чтобы накопители, принадлежащие локальному региону прокси-сервера, находились первыми в списке. После такой сортировки списки локальных региональных и внешних региональных узлов перемешиваются независимо, а затем список внешних региональных узлов присоединяется к списку локальных региональных узлов. В качестве альтернативы на этом этапе может быть использован описанный выше метод выбора узла-накопителя данных по минимальному времени отклика.
Репликация в Swift
Репликация между географически распределенными датацентрами в нашем прототипе работает для регионов в целом так же, как для кластера с одним регионом. Однако, поскольку в рамках процесса репликации может быть отправлено огромное количество запросов REPLICATE между кластерами по низкоскоростному WAN-соединению. Это может привести к серьезному падению производительности кластера в целом.
В качестве простого обходного решения этой проблемы используется добавление счетчика в репликатор таким образом, что разделы переносятся на устройства в удаленном регионе при каждой N-ной репликации. Более сложные решения могут включать выделенные шлюзы репликатора в сосдених регионах, и будут разрабатываться в рамках нашего исследовательского проекта.
Оригинал статьи на английском языке
ссылка на оригинал статьи http://habrahabr.ru/company/mirantis_openstack/blog/176455/
Добавить комментарий