Вступление
В своей практике мне довелось участвовать в миграции проекта (codebase имел 5+ лет истории) с централизованной системы управления версиями (centralized VCS — SVN) на распределенную (distributed VCS — Mercurial). Подобные активности часто сопровождаются определенным количеством FUD (fear, uncertainty and doubt) среди команды, вовлеченной в этот процесс. Если технические моменты конвертации (структура новых репозиториев, инструментальная поддержка, работа с большими бинарными файлами, кодировки и т.п.) по большему счету будут решены в определенный момент, то вопросы, связанные с преодолением кривой обучения для команды для эффективного использования новой системы, на момент перехода могут только начинаться.
При таких переходах важно измение взгляда на новую систему контроля версий и ее использование (mindset shift). Тут очень помогает хорошее понимание принципов, на которых основаны VCS. Если разобраться в основах, использование системы заметно упрощается. Соответственно, данный материал будет посвящен различиям в моделировании истории между централизованным и децентрализованным системами управления версиями.
Небольшое отступление про различия в структуре
Для начала вкратце приведу небольшое описание структуры обеих систем. Начнем с централизованной:
- Традиционные VCS были созданы для бэкапирования, отслеживания и синхронизации файлов
- Все изменения проходят через центральный сервер

Децентрализованная система:
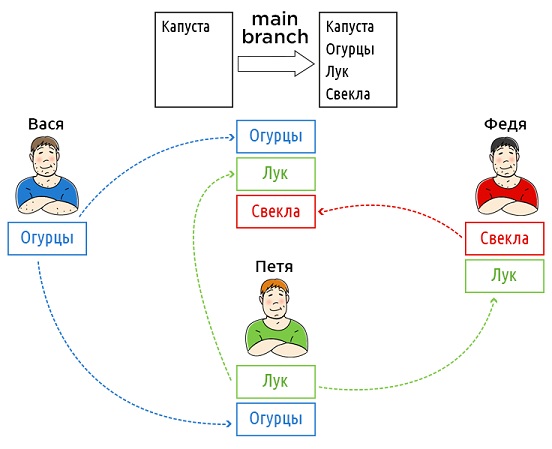
- В DVCS у каждого есть свой полноценный репозиторий
- DVCS были созданы для обмена изменениями
- При использовании DVCS нет какой-то жестко заданной структуры репозиториев с центральным сервером
Лучше не углубляться в различия по структуре, чтобы не утяжелять материал и больше сфокусироваться на главном — моделировании истории в обеих системах.
Мифы, факты и репутация
Любой человек, который решает ознакомиться с возможностями, которые предоставляют как централизованные, так децентрализованные системы, столкнется с мифами, которые связаны с их использованием, и определенной репутацией, которые имеют эти системы. Например:
- Не лучшую репутацию SVN, как средства для активного ветвления и объединения изменений (branching and merging)
- Репутацию системы Git как “волшебного” merge средства и ее большую гибкость в управлении коммитами (removing, reordering, combining, shelving etc)
Если плохая репутация SVN в основном связана с отсутствием метаданных, связанных с отслеживанием веток в более ранних версиях, то репутация Git, да и всех распределенных систем, связана с такой интересной штукой как DAG. Хочу заметить, что централизованные системы не стоят на месте и активно развиваются в направлении поддержки сценариев, требующих активного ветвления. Но это не является предметом данного материала, в отличие от DAG, который мы рассмотрим подробнее дальше по тексту.
Как моделируют свою историю централизованные системы
Ключ к успеху в использовании любой системы управления версиями лежит в понимании модели, которая используется для того, чтобы представлять историю изменений в этой системе. Начнем с централизованных систем.История тут моделируется просто как линия. Наши коммиты выстраиваются во временную цепочку. Очень просто для использования и понимания.
Правда есть тут одно но: мы можем вкоммитить новую версию, только если она основана на последней версии. Как это выглядит в реальных условиях:
- Разработчики Вася и Петя приходят с утра на работу и обновляются на последнюю ревизию – 2. И начинают работать, то есть, писать код.

- Вася успевает все сделать раньше Пети, поэтому коммитит новую ревизию – 3, и с чистой совестью идет домой.
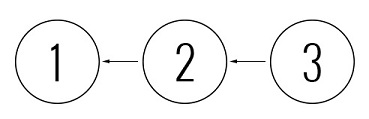
- Петя, при попытке создать новую ревизию, не может это сделать, так как его изменения основаны на ревизии 2, а последняя ревизия, благодаря стараниям Васи, — уже 3.

- Поэтому он вынужден обновить свою рабочую копию, объеденить изменения, и только потом он может вкомитить ревизию 4, основанную на ревизии 3, а не 2.
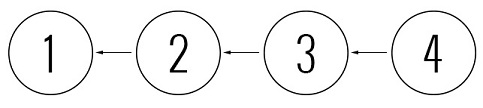
Длинные шаги, которые вынужден сделать Петя, на самом деле, автоматизируются средствами используемой системы, и не слишком заметны для разработчика. Как правило, в таком случае Петя видит грозное предупреждение сервера вроде “You must update you working copy first”, обновляется (тут будут объединены изменения Васи и Пети) и коммитит новую ревизию.
Дотошные читатели тут заметят две вещи:
- Система теряет часть информации об истории изменений (то, что изначально ревизии Васи и Пети были основаны на ревизии 2)
- Данная модель позволяет поддерживать ветвление (branching) только используя внешние механизмы
Пока оставим эту информацию как есть и перейдем к распределенным системам.
Как моделируют свою историю распределенные системы
Что если в предудущем примере система позволила бы нам вкоммитить ревизию 4, основанную на ревизии 2?
А случилось бы вот что: наша история перестала бы быть линией (спасибо, Кэп) и превратилась бы в граф. Если точнее, в направленный ациклический граф, или directed acyclic graph (DAG). Википедия любезно предоставляет нам его определение:
“Случай направленного графа, в котором отсутствуют направленные циклы, то есть пути, начинающиеся и кончающиеся в одной и той же вершине”
Распределенные системы используют DAG для моделирования истории. Как нетрудно заметить, DAG не теряет информацию о коммитах, в нашем случае то, что ревизия 4 основана на ревизии 2.
Тем не менее, в системе не существует версии, которая содержала бы в себе изменения Васи и Пети одновременно. Основанные на DAG средства решают такую проблему при помощи объединения (merge) ревизий.

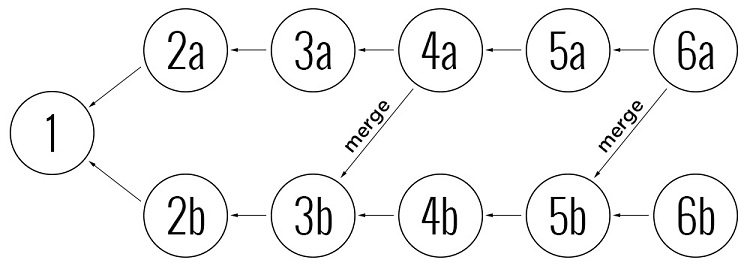
Рассмотрим пример использования DAG, в котором у нас есть две ветки с общей историей, и мы хотим синхронизировать ветку a с веткой b отталкиваясь от ревизии 5b. При переносе изменений граф содержит информацию о том, что изменения 2b и 3b уже были объединены с веткой a, поэтому необходимо только объединить изменения 4b и 5b с веткой a. Так как DAG хранит полную информацию об объединениях (merge history), то сам процесс объединений намного проще выполнить автоматически, чем если бы мы использовали систему, которая хранит историю в виде линии и использует метаданные для отслеживания веток.
Для тех, кто хочет глубже копнуть работу систем контроля версий, рекомендую книгу Eric Sink – Version Control By Example.
Проблема последней версии
На проекте, где работает более одного разработчика и используется DVCS, история разрабатываемого кода всегда будет иметь вид графа, так как это отражает реальную картину того, как разрабатывается код. Важно понимать, что любая лишняя ветка в истории имеет определенную цену, связанную с ее использованием и отслеживанием. Более подробно об этом можно прочитать тут.
Хочу остановиться лишь на так называемой “проблеме последней версии”, которая часто вызывает много вопросов у людей, которые только начали использовать DVCS. Допустим, мы с утра пришли на работу и обновили свой репозиторий. Граф истории представляет собой примерно следующую картину:

Такое положение дел способно вызвать ряд вполне логичных вопросов:
- Интеграционный сервер должен собрать последнюю версию, но он не может определить, какая из ревизий последняя
- Точно также QA не могут определить, какую версию им тестировать
- Разработчик не может обновиться на последнюю версию по той же самой причине
- Если разработчик захочет внести новый код в репозиторий, на основании какой ревизии он должен создать новую?
- Менеджер должен оценить прогресс, узнав сколько функционала выполнено. Однако, для этого он должен знать, какая версия последняя
Проблема последней версии является одной из главных причин, почему использование DAG-based иструментов кажется людям очень хаотическим и непонятным после простых в понимании централизованных систем с историей в виде линии.
Решение этой проблемы лежит в плоскости организации процесса на проекте. Можно, например, выстроить процесс вот так:
- Интеграционный сервер собирает все ревизии или ревизию, которую указывает, например, Test Lead
- QA команда решает сама или с помощью менеджера, какую версию им тестировать
- Разработчик обновляется не на “последнюю версию”, а решает сам, на основании какой ревизии должен быть создан новый коммит
Нетрудно заметить, что тут необходимо соблюдать баланс между гибкостью и сложностью применяемого решения.
Silver Bullet?
Является ли DAG идеальным решением для моделирования истории разработки кода? Давайте представим такую ситуацию: я хочу создать ревизию 4, которая содержит всю историю ревизии 1 и только ревизию 3 (без ее истории в виде ревизии 2). Такой подход называется cherry-picking и не может быть смоделирован используя DAG. Тем не менее, некоторые DVCS могут эмулировать такой сценарий посредством расширений.

Альтернативой “классическим” DVCS, таким как Git, Mercurial и Bazaar, может выступить Darcs, система управления версиями, в которой используется отличный от DAG подход к моделированию истории, и которая способна поддерживать такой сценарий как cherry-picking на уровне ядра. Вполне возможно, что в будущем подобные системы вытеснят современные DVCS.
ссылка на оригинал статьи http://habrahabr.ru/post/177855/
Добавить комментарий