 Часть 1: Введение
Часть 1: ВведениеЧасть 2: Многопоточность
Часть 3: Рендеринг (Прим. пер. — в процессе перевода)
Часть 4: Doom classic integration (Прим. пер. — в процессе перевода)
Движок для Doom III был написан в период с 2000 по 2004 год, в то время, когда большинство ПК были однопроцессорными. Хотя архитектура движка idTech4 разрабатывалась с учетом поддержки SMP, это закончилось тем, что поддержка многопоточности делалась в последнюю минуту (см. интревью с Джоном Кармаком).
С тех пор изменилось многое, есть хорошая статья от Microsoft "Программирование для многоядерных систем":
В течение многих лет производительность процессоров неуклонно возрастала, и игры, и другие программы получали выгоду от этого увеличения мощности без необходимости прикладывать усилия.
Правила изменились. Производительность одноядерных процессоров в настоящее время растет очень медленно, если вообще растет. Однако, вычислительные мощности персональных компьютеров и консолей продолжает расти. Разница лишь том, что в основном такой прирост теперь получается за счет наличия многоядерных процессоров.
Прирост мощности процессора так же впечатляющ, как и раньше, но теперь разработчики должны писать многопоточный код для того, чтобы полностью раскрыть потенциал этой мощности.
Целевые платформыи Doom III BFG многоядерны:
- Xbox 360 имеет один трёхядерный процессор Xenon. Одновременная многопоточность платформы составляет 6 логических ядер.
- PS3 имеет основной блок (PPE) основанный на процессоре PowerPC и восемь синергических ядер (SPE).
- ПК зачастую имеет четырехъядерный процессор. С Hyper-Threading эта платформа получает 8 логических ядер.
В результате idTech4 был усилены не только поддержкой многопоточности, но и компонентом idTech5 «Job Processing System», добавляющий поддержку многоядерных систем.
К сведению: не так давно были обнародованы спецификации Xbox Ona и PS4: оба будут иметь по восемь ядер. Еще одна причина, для любого разработчика игр хорошо разбираться в многопоточном программировании.
Модель потоков Doom 3 BFG
 На PC игра запускается в трех потоках:
На PC игра запускается в трех потоках:
- Поток рендеринга backend интерфейса (Отправка команд GPU)
- Поток игровой логики и рендеринга frontend интерфейса
- Поток сбора ввода данных с джойстика высокой частоты (250Hz)
Кроме того, idTech4 создает еще два рабочих потока. Они необходимы для помощи любому из трех основных потоков. Они управляются планировщиком, когда это возможно.
Основная идея
Id Software обнародовало решение проблем многоядерного программирования в 2009 в презентации "Beyond Programming Shaders". Две основные идеи тут:
- Разделять обработку задач для обработки разными потоками («jobs» by «workers»)
- Избегать делегирования синхронизации операционной системе: делать это самостоятельно для атомарных операций
Компоненты системы
Система состоит из 3х компонентов:
- Задачи (Jobs)
- Обработчики (Workers)
- Синхронизация (Synchronization)
Задачи это именно то, что можно было бы ожидать:
struct job_t { void (* function )(void *); // Job instructions void * data; // Job parameters int executed; // Job end marker...Not used. }; Примечание: В соответствии с комментариями в коде, «задание должно длиться по крайней мере пару 1000 тактов для того, чтобы перевесить издержки переключения. С другой стороны задание не должно длиться не более чем несколько 100 000 тактов для поддержания хорошего баланса нагрузку между несколькими процессами.
Обработчик представляет собой поток, который будет оставаться неактивным в ожидании сигнала. Когда он активирован он пытается найти задание. Обработчики стараются избегать синхронизации, используя атомарные операции, пытаясь получить задание из общего списка.
Синхронизация осуществляется через три примитива: сигналы, мьютексы и атомарные операции. Последний являются предпочтительным, так как позволяет двигателю сохранять фокусировку CPU. Эти три механизма реализации подробно описаны в нижней части этой страницы.
Архитектура
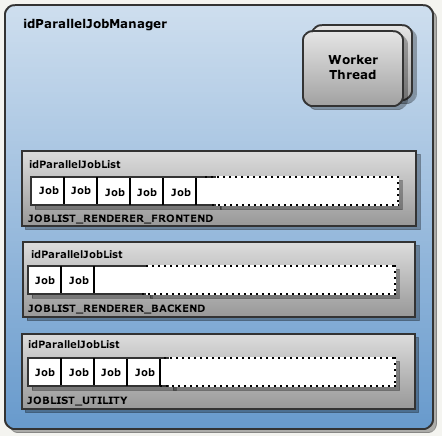 Мозгом подсистемы является ParalleleJobManager. Он отвечает за порождение обработчиков потоков и создание очередей, в которых хранятся задачи.
Мозгом подсистемы является ParalleleJobManager. Он отвечает за порождение обработчиков потоков и создание очередей, в которых хранятся задачи.
И первая идея обхода синхронизации: разделить списки заданий на несколько секций, к каждому из которых обращается только один поток и, следовательно, синхронизация не требуются. В движке такие очереди называются idParallelJobList.
В Doom III BFG присутствуют только три секции:
- Рендер frontend-a
- Рендер backend-a
- Utilities
На PC при запуске создаются два рабочих потока, но, вероятно, в XBox360 и PS3 их создается больше.
По данным 2009 презентацию, в idTech5 добавлено больше секций:
- Обнаружение дефектов
- Обработка анимации
- Обход препятствий
- Обработка текстур
- Обработка прозрачности частиц
- Симуляция ткани
- Симуляция водной поверхности
- Детальная генерация моделей
Примечание: В презентации также упоминает концепция задержки в один кадр, но эта часть кода не относится к Doom III BFG.
Распределение задач
 Запущенные обработчики постоянно находятся в ожидании задания. Этот процесс не требует использования мьютексов или мониторов: атомарная инкрементация распределяет задания без перекрытия.
Запущенные обработчики постоянно находятся в ожидании задания. Этот процесс не требует использования мьютексов или мониторов: атомарная инкрементация распределяет задания без перекрытия.
Использование
Поскольку задания разделены на секции доступные только в одному потоку, в синхронизации нет необходимости. Однако, предоставлениезадач обработчику системы действительно подразумевают мьютекс:
//tr.frontEndJobList is a idParallelJobList object. for ( viewLight_t * vLight = tr.viewDef->viewLights; vLight != NULL; vLight = vLight->next ) { tr.frontEndJobList->AddJob( (jobRun_t)R_AddSingleLight, vLight ); } tr.frontEndJobList->Submit(); tr.frontEndJobList->Wait();
Методы:
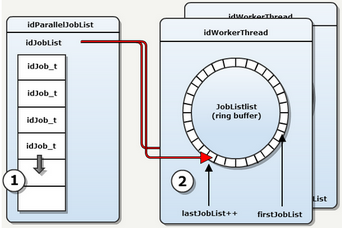
- Добавление задания: в синхронизации нет необходимости, задания добавляются в очередь
- Отправка: мьютекс синхронизация, каждый обработчик пополняет общий JobLists из своего локального JobLists .
- Сигнал синхронизации (делегирование ОС):
Как выполняется обработчик
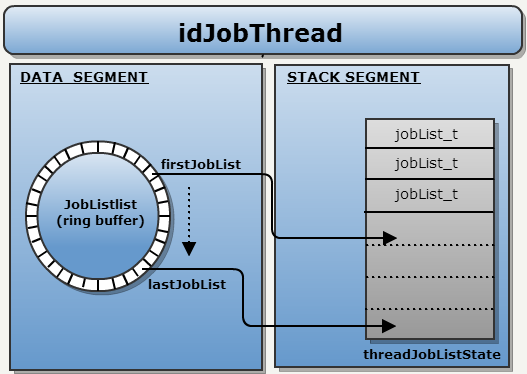
Обработчики выполняются в бесконечном цикле. В каждой итерации проверяется кольцевой буфер, и если задание найдено — оно копируется ссылкой в локальный стек.
Локальный стек: стек потока используется для хранения адресов JobLists для предотвращение остановки механизма. Если поток не может «заблокировать» JobList, она падает в RUN_STALLED режим. Это остановка может быть отменена путем перехода стека из локального JobLists в общий список.
Интересно то, что все будет сделано без каких-либо взаимных механизмов: только атомарные операции.
int idJobThread::Run() { threadJobListState_t threadJobListState[MAX_JOBLISTS]; while ( !IsTerminating() ) { int currentJobList = 0; // fetch any new job lists and add them to the local list in threadJobListState {} if ( lastStalledJobList < 0 ) // find the job list with the highest priority else // try to hide the stall with a job from a list that has equal or higher priority currentJobList = X; // try running one or more jobs from the current job list int result = threadJobListState[currentJobList].jobList->RunJobs( threadNum, threadJobListState[currentJobList], singleJob ); // Analyze how job running went if ( ( result & idParallelJobList_Threads::RUN_DONE ) != 0 ) { // done with this job list so remove it from the local list (threadJobListState[currentJobList]) } else if ( ( result & idParallelJobList_Threads::RUN_STALLED ) != 0 ) { lastStalledJobList = currentJobList; } else { lastStalledJobList = -1; } } }
int idParallelJobList::RunJobs( unsigned int threadNum, threadJobListState_t & state, bool singleJob ) { // try to lock to fetch a new job if ( fetchLock.Increment() == 1 ) { // grab a new job state.nextJobIndex = currentJob.Increment() - 1; // release the fetch lock fetchLock.Decrement(); } else { // release the fetch lock fetchLock.Decrement(); // another thread is fetching right now so consider stalled return ( result | RUN_STALLED ); } // Run job jobList[state.nextJobIndex].function( jobList[state.nextJobIndex].data ); // if at the end of the job list we're done if ( state.nextJobIndex >= jobList.Num() ) { return ( result | RUN_DONE ); } return ( result | RUN_PROGRESS ); }
Инструменты синхронизации Id Software
Id Software использует три типа механизмов синхронизации:
1. Мониторы (idSysSignal):
| Абстракция | Операция | Реализация | Примечание |
| idSysSignal | Event Objects | ||
| Raise | SetEvent | Устанавливает указанное событие объекта в сигнальное состояние. | |
| Clear | ResetEvent | Устанавливает указанное событие объекта в несигнальное состояние. | |
| Wait | WaitForSingleObject | Ожидает, пока указанный объект будет находиться в сигнальном состоянии или пока время ожидания не истекло. |
Сигналы используется для остановки потока. Обработчики использует idSysSignal.Wait (), чтобы удалить себя из планировщика операционной системы, если задания отсутствуют.
2. Мьютексы (idSysMutex) :
| Абстракция | Операция | Реализация | Примечание |
| idSysMutex | Critical Section Objects | ||
| Lock | EnterCriticalSection | Ожидает получения указанного объекта критической секции. Функция возвращается, когда вызывающий поток получил в собственность. | |
| Unlock | LeaveCriticalSection | Реализует получение указанного объекта критической секции. | |
3. Атомарные операции (idSysInterlockedInteger) :
| Абстракция | Операция | Реализация | Примечание |
| idSysInterlockedInteger | Interlocked Variables | ||
| Increment | InterlockedIncrementAcquire | Инкрементация значение заданной 32-битовой переменной в качестве атомарной операции.Операция выполняется при помощи выделения семантической памяти (acquire memory ordering semantics). | |
| Decrement | InterlockedDecrementRelease | Декрементация значение заданной 32-битовой переменной в качестве атомарной операции.Операция выполняется при помощи выделения семантической памяти (acquire memory ordering semantics). |
ссылка на оригинал статьи http://habrahabr.ru/post/181081/
Добавить комментарий