Для начала, создадим «справочные» таблицы, необходимые для отладки и тестирования нашего функционала:
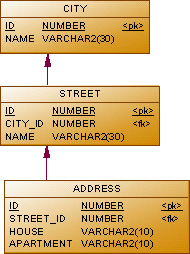
create table city ( id number not null, name varchar2(30) not null ); create unique index city_pk on city(id); alter table city add constraint city_pk primary key(id); create table street ( id number not null, city_id number not null, name varchar2(30) not null ); create unique index street_pk on street(id); create index street_fk on street(city_id); alter table street add constraint street_pk primary key(id); alter table street add constraint fk_street foreign key (city_id) references city(id); create table address ( id number not null, street_id number not null, house varchar2(10) not null, apartment varchar2(10) ); create unique index address_pk on address(id); create index address_fk on address(street_id); alter table address add constraint address_pk primary key(id); alter table address add constraint fk_address foreign key (street_id) references street(id);
… и наполним их данными:
insert into city(id, name) values (1, 'Казань'); insert into street(id, city_id, name) values (1, 1, 'Победы'); insert into street(id, city_id, name) values (2, 1, 'Победы проспект'); insert into address(id, street_id, house, apartment) values (1, 1, '10', '1'); insert into address(id, street_id, house, apartment) values (2, 2, '10', '2');
Теперь подумаем, какие действия необходимо выполнить, чтобы «слить» дубликаты? У нас есть две записи, которые мы считаем «дубликатами». Требуется удалить одну из них, а все ссылки на нее изменить таким образом, чтобы они указывали на вторую. Разумеется, все это надо сделать таким образом, чтобы это действие можно было, при необходимости, откатить. Таким образом, необходимо фиксировать всю информацию, требующуюся для отката, в служебных таблицах:

create table mg_table ( name varchar2(30) not null ); create unique index mg_table_pk on mg_table(name); alter table mg_table add constraint mg_table_pk primary key(name); create sequence mg_merge_seq; create table mg_merge ( id number not null, table_name varchar2(30) not null, old_id number not null, new_id number not null ); create unique index mg_merge_pk on mg_merge(id); create unique index mg_merge_uk on mg_merge(table_name, old_id); alter table mg_merge add constraint mg_merge_pk primary key(id); alter table mg_merge add constraint fk_mg_merge foreign key (table_name) references mg_table(name); create sequence mg_ref_seq; create table mg_ref ( id number not null, merge_id number not null, table_name varchar2(30) not null, pk_name varchar2(30) not null, column_name varchar2(30) not null, object_id number not null ); create unique index mg_ref_pk on mg_ref(id); create index mg_ref_fk on mg_ref(merge_id); alter table mg_ref add constraint mg_ref_pk primary key(id); alter table mg_ref add constraint fk_mg_ref foreign key (merge_id) references mg_merge(id);
Для сохранения удаляемой записи, будем использовать таблицу, повторяющую структуру исходной. Эта таблица будет создаваться автоматически при выполнении первого слияния дубликатов соответствующего справочника. Имя будем формировать путем добавления к имени таблицы справочника префикса «mg_» (например, если нам впервые требуется слить дубликаты в справочнике street, мы должны создать таблицу mg_street для сохранения удаляемых записей).
В таблице mg_table будут фиксироваться имена таблиц обработанных таким образом справочников. В mg_merge будем хранить ключи сливаемых записей, а в mg_ref идентификаторы записей, ссылающихся на старое значение. Легко заметить, что такая структура справочных таблиц позволяет работать только с одностолбцовыми числовыми ключами. По этой причине, первое, что нам следует сделать — это проверка того, можем ли мы работать с выбранным справочником:
select max(cn) from ( select b.constraint_name, count(*) cn from user_constraints a inner join user_constraints b on (b.r_constraint_name = a.constraint_name) inner join user_cons_columns c on (c.constraint_name = b.constraint_name) where a.table_name = upper(p_name) group by b.constraint_name ); Этим запросом мы определяем максимальное количество столбцов во внешних ключах, ссылающихся на таблицу, заданную именем p_name. Следует отметить, что составлять подобные запросы в Oracle очень просто. Не требуется помнить наизусть имена всех системных представлений Oracle. Мы всегда можем освежить память, выполнив следующий простой запрос:
select * from dictionary Далее, все действия, по выполнению слияния, довольно очевидны, хотя и требуют активного использования execute immediate (полный исходный текст пакета приведен в конце статьи).
Некоторые комментарии требуются по процедуре отката изменений. Помимо возможности отката последнего изменения, описываемый пакет позволяет откатить отдельное изменение, указав его ID. Очевидно, что откатить таким образом можно не любое слияние. Возможность отката изменения проверяется при помощи следующего запроса:
select count(*) from mg_merge where old_id = l_new; Смысл этой проверки прост — мы не можем откатить слияние записей, если оставшаяся после ее выполнения запись была впоследствии удалена другим слиянием.
Реализация пакета выглядит следующим образом:
create or replace package mg_merge_pkg as procedure merge(p_name in varchar2, p_old in number, p_new in number); procedure undo(p_id in number); procedure undo; end mg_merge_pkg; / show errors; create or replace package body mg_merge_pkg as e_unsupported_error EXCEPTION; pragma EXCEPTION_INIT(e_unsupported_error, -20001); cursor c_col(p_name varchar2, p_pk varchar2) is select column_name from user_tab_columns where table_name = upper(p_name) and column_name <> p_pk; procedure merge(p_name in varchar2, p_old in number, p_new in number) as cursor c_fk is select b.table_name, c.column_name, e.column_name pk_name from user_constraints a inner join user_constraints b on (b.r_constraint_name = a.constraint_name) inner join user_cons_columns c on (c.constraint_name = b.constraint_name) inner join user_constraints d on (d.table_name = b.table_name and d.constraint_type = 'P') inner join user_cons_columns e on (e.constraint_name = d.constraint_name) where a.table_name = upper(p_name); r_fk c_fk%rowtype; r_col c_col%rowtype; l_id number default null; l_cn number default null; l_pk varchar2(30) default null; l_sql varchar2(500) default null; begin select max(cn) into l_cn from ( select b.constraint_name, count(*) cn from user_constraints a inner join user_constraints b on (b.r_constraint_name = a.constraint_name) inner join user_cons_columns c on (c.constraint_name = b.constraint_name) where a.table_name = upper(p_name) group by b.constraint_name ); if l_cn > 1 then RAISE_APPLICATION_ERROR(-20001, 'Can''t support multicolumn FK'); end if; select c.column_name into l_pk from user_constraints a inner join user_cons_columns c on (c.constraint_name = a.constraint_name) where a.table_name = upper(p_name) and a.constraint_type = 'P'; select count(*) into l_cn from mg_table where name = upper(p_name); if l_cn = 0 then insert into mg_table(name) values (upper(p_name)); execute immediate 'create table mg_' || p_name || ' as select * from ' || upper(p_name) || ' ' || 'where rownum = 0'; execute immediate 'create unique index mg_' || p_name || '_pk on mg_' || p_name || '(' || l_pk || ')'; end if; insert into mg_merge(id, table_name, old_id, new_id) values (mg_merge_seq.nextval, upper(p_name), p_old, p_new) returning id into l_id; open c_fk; loop fetch c_fk into r_fk; exit when c_fk%notfound; execute immediate 'insert into mg_ref(id, merge_id, table_name, pk_name, column_name, object_id) ' || 'select mg_ref_seq.nextval, :merge_id, :tab_name, :pk_name, :col_name, ' || r_fk.pk_name || ' ' || 'from ' || r_fk.table_name || ' where ' || r_fk.column_name || ' = :old_id' using l_id, r_fk.table_name, r_fk.pk_name, r_fk.column_name, p_old; execute immediate 'update ' || r_fk.table_name || ' set ' || r_fk.column_name || ' = :new_id ' || 'where ' || r_fk.column_name || ' = :old_id' using p_new, p_old; end loop; close c_fk; l_sql := 'insert into mg_' || p_name || '(' || l_pk; open c_col(p_name, l_pk); loop fetch c_col into r_col; exit when c_col%notfound; l_sql := l_sql || ',' || r_col.column_name; end loop; close c_col; l_sql := l_sql || ') select '|| l_pk; open c_col(p_name, l_pk); loop fetch c_col into r_col; exit when c_col%notfound; l_sql := l_sql || ',' || r_col.column_name; end loop; close c_col; l_sql := l_sql || ' from ' || p_name || ' where ' || l_pk || ' = :old_id'; execute immediate l_sql using p_old; execute immediate 'delete from ' || p_name || ' where ' || l_pk || ' = :id' using p_old; commit; exception when others then if c_fk%isopen then close c_fk; end if; if c_col%isopen then close c_col; end if; rollback; raise; end; procedure undo(p_id in number) as cursor c_fk is select table_name, pk_name, column_name from mg_ref where merge_id = p_id group by table_name, pk_name, column_name; r_fk c_fk%rowtype; r_col c_col%rowtype; l_name varchar2(30) default null; l_old number default null; l_new number default null; l_cn number default null; l_pk varchar2(30) default null; l_sql varchar2(500) default null; begin select table_name, old_id, new_id into l_name, l_old, l_new from mg_merge where id = p_id; select count(*) into l_cn from mg_merge where old_id = l_new; if l_cn > 0 then RAISE_APPLICATION_ERROR(-20001, 'Can''t undo'); end if; select c.column_name into l_pk from user_constraints a inner join user_cons_columns c on (c.constraint_name = a.constraint_name) where a.table_name = upper(l_name) and a.constraint_type = 'P'; l_sql := 'insert into ' || l_name || '(' || l_pk; open c_col(l_name, l_pk); loop fetch c_col into r_col; exit when c_col%notfound; l_sql := l_sql || ',' || r_col.column_name; end loop; close c_col; l_sql := l_sql || ') select '|| l_pk; open c_col(l_name, l_pk); loop fetch c_col into r_col; exit when c_col%notfound; l_sql := l_sql || ',' || r_col.column_name; end loop; close c_col; l_sql := l_sql || ' from mg_' || l_name || ' where ' || l_pk || ' = :old_id'; execute immediate l_sql using l_old; open c_fk; loop fetch c_fk into r_fk; exit when c_fk%notfound; execute immediate 'merge into ' || r_fk.table_name || ' d using mg_ref s '|| 'on (s.object_id = d.' || r_fk.pk_name || ' and s.merge_id = :id and s.table_name = :tab_name and s.column_name = :col_name) ' || 'when matched then ' || 'update set d.' || r_fk.column_name || ' = :old_id' using p_id, r_fk.table_name, r_fk.column_name, l_old; end loop; close c_fk; execute immediate 'delete from mg_' || l_name || ' where ' || l_pk || ' = :id' using l_old; delete from mg_ref where merge_id = p_id; delete from mg_merge where id = p_id; commit; exception when others then if c_fk%isopen then close c_fk; end if; if c_col%isopen then close c_col; end if; rollback; raise; end; procedure undo as l_id number default null; begin select max(id) into l_id from mg_merge; undo(l_id); end; end mg_merge_pkg; / show errors;
Мы можем слить словарные значения выполнив следующий запрос:
begin mg_merge_pkg.merge('street', 2, 1); end; И откатить изменения запросом:
begin mg_merge_pkg.undo; end;
ссылка на оригинал статьи http://habrahabr.ru/post/181378/
Добавить комментарий