Давно я написал статью-обзор по эволюции методов моделирования нейронов и забросил это дело. В описание попали старые и всем интересующимся нейронами известные методы, можно сказать, получился обзор учебников выпущенных до распада СССР. Если кому интересно может сходить habrahabr.ru/post/101020/, посмотреть старый обзор. Сейчас у меня подсобрался материал по нескольким с моей точки зрения увлекательным и более современным методам моделирования, которые заслужили упоминания в виде структурированного обзора. Здесь я только упомяну эти методы в описательном порядке, по той простой причине, что для большинства интересней знать, зачем мы его применяем, а не как он работает и как его применять. Объем текста значительно уменьшиться, интересность повысится, а то, как в действительности работают эти методы, каждый сможет найти сам.
Итак, готовьтесь.
Асинхронный распределенный стохастический градиентный спуск мини-партиями
Богат и выразителен русский язык. Но уже и его стало не хватать.
Ужасно непонятное нагромождение умных слов. Именно этот метод описывался в статье habrahabr.ru/post/146077/ где его перевели в менее пугающую форму. Там его назвали асинхронным градиентным спуском (asynchronous SGD). Я попытался разобраться и уцепился за английское название «asynchronous SGD».
Первым стоит упомянуть сам метод градиентного спуска. Это метод нахождения локального минимума или максимума функции. Если у вас была вышка, у вас должно остаться смутное понимание, о чем идет здесь речь. Вообще он применяется как оптимизационный алгоритм, а если вы работаете с нейросетями, то спокойно называйте его алгоритмом машинного обучения.
Теперь добавляем слово «стохастический». Зачем это нужно для нашего метода? Какая в этом польза? Этот метод использует только один пример из обучаемого множества за раз в отличие от остальных методов, использующих сразу все множество. Смысл в том, что вы можете добавить еще данных для дополнительного обучения или остановить обучение, если вам надоело ждать, и вы захотели посмотреть результаты обучения на обработанной части данных.
Между этими двумя (обычным и стохастическим) видами градиентного спуска существует компромисс, называемый «mini-batch» (мини-партии). В этом случае используются небольшие пачки обучающих образцов. Именно этот метод с малыми партиями наиболее приемлем для распределения вычислений между множеством компьютеров в сети.
Теперь по поводу асинхронности и распределенности — используется распределенная асинхронная обработка данных (Asynchronous peer-to-peer). В таком случае несколько мини-партий обрабатываются одновременно на своих компьютерах в пиринговой сети позволяя продолжать обучение при любом количестве и любом сочетании доступных узлов. Никто не ждет, пока все компьютеры закончат свои вычисления последней партии для обновления общей модели. Для каждой партии используют потенциально различные и, как правило, устаревшие параметры модели. Это главный и основной недостаток. Преимуществом является то, что все машины участвующие в оптимизации заняты вычислениями постоянно, и мы можем добавлять и выключать машины в процессе обучения. Недостаток нивелируется тем, что при однородности данных, модель все равно будет сходиться (оптимизироваться, обучаться). Я не решился лезть в работы, доказывающие это утверждение. Могу лишь поделиться ссылкой достаточно просто излагающей принцип метода асинхронного «data mining» в пиринговой сети. Может кому-то пригодится, это интересно само по себе. Теперь вам не нужен суперкомпьютер, вам нужны друзья в сети.
http://www.inf.u-szeged.hu/~ormandi/presentations/europar2011.pdf
Разреженные распределенные представления
Если существует искусственный интеллект, значит, должна существовать и искусственная тупость.
На иностранном это звучит так «Sparse Distributed Representations».
Основной смысл этого метода, слямзить свойство биологических нейросетей. Хотя нейроны в коре головного мозга очень плотно связаны между собой, многочисленные подавляющие (ингибиторные) нейроны гарантируют, что одновременно будет активен только небольшой процент всех нейронов, и они обычно довольно разнесены друг от друга. То есть, получается, что информация представляется в мозге всегда только небольшим количеством активных нейронов из всех имеющихся там. Такой тип кодирования информации называется «разреженное распределенное представление»
Существует также метод разреженного автоэнкодера «Sparse Autoencoder», читать здесь habrahabr.ru/post/134950/, но его смысл в том же, просто слямзить свойство биологической нейросети.
Вернемся к нашему методу. «Разреженное» это требование, что только небольшой процент нейронов слоя может быть одновременно активным. Каким путем вы этого добиваетесь, это не важно. Основополагающий принцип остается тот же, как и в энкодере, так и в разреженых представлениях. Главное — понижается размерность входных данных для следующего слоя, происходит компрессия данных, так как сеть обязана найти скрытые взаимосвязи, корреляции признаков и вообще какую-никакую часто встречающуюся структуру в данных.
«Распределенное» это тоже требование, что для представления чего-либо в слое нейросети необходима активация того самого небольшого процента нейронов, при этом нейроны разбросаны по слою удаленно друг от друга. Переизбыток молчащих нейронов тоже плохо. Достаточное количество активных нейронов в слое позволяет избегать тривиальных паттернов при нахождении тех самых скрытых взаимосвязей и корреляций. Активность одиночного нейрона, конечно, тоже что-то означает, вспомним про «бабушкин нейрон», но активность должна интерпретироваться только в контексте множества других нейронов. Одиночная активность не будет подниматься вверх по иерархии слоев. Фактически активность нейронов последнего слоя будет представлять картину мира сквозь рецептивное поле нашей нейросети.
В заключение могу сказать, что такое представление информации в нейросети как раз и приводит к образованию пресловутых «бабушкиных нейронов». Если вы не понимаете о чем речь, взгляните на картинку, это изображение отвечает максимальному стимулу для нейрона, занимающегося распознаванием морды кота из статьи habrahabr.ru/post/153945/. Чистая «концепция морды кота».

Либо посмотрите 5 минут выступление товарища Анохина с указаного момента 49:15. Основываясь на его словах можно утверждать, что в вашем мозгу существует нейрон, отвечающий за концепцию гражданки Саши Грей.
Локальные рецептивные поля
Ничто не хорошо настолько, чтобы где-то не нашелся кто-то, кто это ненавидит.
Это уже правило хорошего тона в моделировании нейросетей. В зависимости от применяемых методов и модели нейронов можно получать различные плюшки. Я даже не хочу перечислять, просто поверьте на слово. Локальные рецептивные поля – наше все.
Конечно, стоит оговорить, что наибольшая польза от этого метода получается при однородности входных данных. Простым примером являются визуальные данные. Нейроны из первого слоя на таких данных по методу разреженных представлений научаться распознавать одинаковые простейшие элементы контуров под разными углами, что очень хорошо стыкуется с биологией мозга.

Разделение дендритов по типам
Поддайся соблазну. А то он может не повториться.
Разделение дендритов по типам — замечательное новшество в моделирование нейронов, открывающее безграничные возможности для экспериментирования. Этот принцип становиться новым трендом в моделировании нейронов как на западе, так и у нас, хотя пути, которые привели к такому решению разные. На западе под этот принцип пытаются подвести биологическую основу, сейчас утверждают, что нейроны четвертого слоя неокортекса принимают синапсы из других слоев и других участков мозга на близкие к телу клетки дендриты, а между собой в слое связываются только через удаленные дендриты.
У нас тоже не отказываются от такого базиса, но вдобавок критикуют гипотезу суммации возбуждений на единичном нейроне.
Теперь перейдем к открывшимся возможностям моделирования. Мы можем назначать различные правила реагирования нейрона на сигналы с дендритов разных типов, задавать правила перехода дендритов из одного типа в другие. Естественно введение различных типов влияет и на работу всей нейросети целиком, так что многие великолепные предложения для правил не жизнеспособны внутри целой нейросети. Но уже существует несколько устоявшихся и хорошо себя проявивших моделей нейронов с разделением дендритов по типам.
Ниже я расскажу про новые свойства нейросетей, которые совпадают со свойствами человеческой памяти и которые можно получить при разделении дендритов на типы. В каждом частном случае используемого метода свойство может носить другое имя (название это всегда произвол автора метода) и серьезно различаться по механизму реализации, но это не отменяет схожесть основополагающего принципа.
А для начала взгляните на структурную схему модели нейрона из метода «Иерархическая темпоральная память».
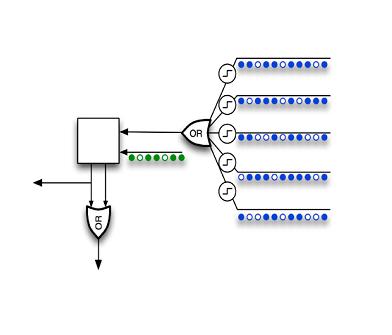
Ассоциативная память
Не все то паттерн, что активирует нейрон.
Принцип в разделении дендритов на два типа и логическом связывании сигналов на их входах.
Дендриты первого типа, который можно условно назвать дендритами «постоянной памяти», работают по вполне привычным правилам моделирования нейронов. Здесь нет новшества, можно использовать любые известные вам старые правила, которые придумали для нейросетей без разделения входов на типы, например что либо похожее на правило «Если на нужный набор входов пришел сигнал, то нейрон активируется». Для срабатывания такого правила нейрон должен распознать паттерн, а мы для удобства будем называть это «срабатыванием постоянной памяти».
Дендриты второго типа, который можно условно назвать дендритами «ассоциативной памяти», работают по новым, но интуитивно понятным правилам. Здесь и заключается так сказать новшество в моделировании. Основной принцип таких правил можно выразить следующими словами «Входы ассоциативного дендрита могут заставить нейрон активироваться, если не сработала постоянная память. Ассоциативность входа повышается, если он активен, когда срабатывает постоянная память». Если кто не понял, то мы на одном нейроне отрабатываем условный рефлекс товарища и академика Павлова. При этом собаки не страдают.
Не стоит считать, что принцип слишком прост, в зависимости от реализации, вы столкнетесь со сложностью правил и множеством особенностей моделирования. Например, ассоциативность может повышаться как от активности нейрона в целом (она уже может срабатывать от постоянной памяти и от ассоциативной), так и от распознавания паттерна постоянной памятью. Ассоциативность может понижаться при каждом срабатывании или же удерживаться и снижаться в зависимости от времени. Дендриты могут переходить из одного типа в другой, а также могут расти, добавляя новые связи. Могут существовать правила, накладывающие пространственные ограничения. Например, дендриты «постоянной памяти» могут связываться только с нейронами из предыдущего слоя, в то время как дендриты «ассоциативной памяти» связываются только с нейронами своего слоя или слоя стоящего выше по иерархии.
Распознавание новой ситуации
Извините, что я говорю, когда вы перебиваете.
Механизм распознавания нового можно добавить только в нейросети с разделением дендритов на типы. Принцип механизма можно выразить в следующих словах «Нейросеть столкнулась с новой ситуацией, если нейрон или группа нейронов проявляют повышенную активность». Смысл этого принципа не очевиден, так как правила срабатывания слишком разняться от реализации к реализации, но общее у них только повышенная активность нейрона после распознавания нового. За время пока нейрон проявляет повышенную активность, внутри сети выполняются правила, основной задачей которых является устранение этой повышенной активности.
Начнем с выгод, которые позволяет получить механизм распознавание нового для нейросети в целом. Нейросеть может реализовать известный «ориентировочный рефлекс», описанный товарищем и академиком Павловым. С некоторых пор, нейрофизиологи стали говорить о детекторах нового в составе нейронных сетей мозга, которые являются рецепторами ориентировочного рефлекса, проявляющегося при возникновении значимого нового в восприятии. Но в отличие от обычных рецепторов (сенсоров), рецепторы конкретной новой ситуации принципиально не могут быть реализованы как датчик определенного сочетания признаков. Просто потому, что они – одноразовые, новая ситуация не повторяется, так как она уже встречалась и запомнилась. А с таким механизмом распознавания нового каждый нейрон в сети становиться детектором нового. Это и есть новшество.
Кроме того распознавание нового, это замечательный повод для установления новых ассоциативных связей, то есть роста дендритов «ассоциативной памяти». В придачу можно реализовать «контекстную память», как добавлением нового типа дендритов, так и просто введением правил обработки нейросети в целом. Смысл в том, что мы должны запомнить, все встречаемые новые ситуации, они и становятся контекстом. Механизм контекстной памяти связан неотрывно с механизмом распознавания нового, но будет рассмотрен ниже в отдельном разделе.
Теперь можно поговорить о особенностях реализации в зависимости от нейросети.
В нейросетях с постоянной и ассоциативной памятью, работающих во времени и способных запоминать последовательности, ассоциативную активацию обычно называют предсказанием. Работа такой нейросети состоит в постоянном прогнозе последующих событий, и вот событие, которое не было предсказано, считается действительно новым. То есть правило звучит следующим образом «Если срабатывание постоянной памяти не последовало за срабатыванием ассоциативной памяти, то мы столкнулись с новой ситуацией». После распознавания нового в нейросеть добавляется новая ассоциативная связь.
В нейросетях с постоянной и контекстной памятью используется схожее, но более интуитивное правило «Если сработала постоянная память и молчит контекстная память, то мы столкнулись с известным паттерном в новой ситуации». Событие, произошедшее в неизвестном контексте, может считаться значимо новым и становится поводом для добавления новых контекстных связей.
В нейросетях с постоянной, ассоциативной и контекстной памятью (три типа дендритов) добавлением механизма распознавания новой ситуации решают важную проблему разделения ассоциаций и контекста. Пока нейрон не распознал новую ситуацию, все активности окружающих нейронов воспринимаются и запоминаются как контекст. В момент, когда нейрон осознал новизну ситуации, все активности окружающих нейронов воспринимаются и запоминаются как ассоциации.
Контекстная память
Каждый подумал в меру своей распущенности, но все подумали об одном и том же.
Механизм контекстной памяти можно получить, добавив новый тип дендритов вместе со своим механизмом распознавания нового. Такая контекстная память собственно и занимается тем, что обслуживает нужды механизма распознавания нового, основанного на правиле «Если сработала постоянная память и молчит контекстная память, то мы столкнулись с новой ситуацией». Контекстная память хранит в себе все ситуации, с которыми уже сталкивался нейрон, при которых срабатывала постоянная память, фактически позволяя верно распознавать новые ситуации. А новшество контекстной памяти в том что её основная задача не в ассоциативной активации нейрона, а наоборот, в гашении повышенной активности нейрона.
В действительности разница между некоторыми реализациями ассоциативной и контекстной памяти лишь в воздействии на нейрон, а правила установления и регулирования ассоциативных и контекстных связей совпадают порой до мелких деталей. Контекстную память тоже можно использовать для прогнозирования, то есть для ассоциативной активации нейрона. В тоже время ассоциативную память можно успешно использовать как контекст в последовательностях, распознавая ситуации, которые мы не смогли спрогнозировать. Я предлагаю различать их именно по воздействию на нейрон, ассоциация возбуждает, а контекст успокаивает.
Основной принцип контекстной памяти можно выразить в следующих словах «Активный контекстный вход дает понять нейрону, что постоянная память уже срабатывала в таких условиях. Два нейрона становятся контекстом друг для друга, если они активны одновременно».
Контекстная память помогает выполнять условия «Разреженных распределенных представлений» действиями правил внутри нейрона, а не правилами, затрагивающими всю сеть одновременно. Скажем так, это в большей степени биологически правдоподобно. Если предположить, что во время обучения паттерна постоянной памяти нейрон активируется, и учесть, что два одновременно активных нейрона пытаются заткнуть друг друга. То активный сосед сигнализирует нашему необразованному нейрону, что «Парниша, я лучше тебя знаю, что сейчас происходит, определяйся со своим паттерном в другой ситуации».
Это механизм, заставляющий нейроны выбирать себе различные паттерны для срабатывания постоянной памяти, и он находиться внутри нейрона. Нейроны разбираются между собой сами, не нужно применять внешний группировщик.
Нейрон с постоянной и ассоциативной памятью, а также мотивационными, санкционирующими и эмоциональными входами.
Когда ты сделал что-то, чего до тебя не делал никто, люди не в состоянии оценить, насколько трудно это было.
Данный метод предполагает наличие среди всех входов каждого нейрона в придачу мотивационных, санкционирующих и эмоциональных входов. Кроме того он основывается на теории функциональных систем Анохина и теории эмоций Симонова.
Я еще сам не до конца разобрался в методе, но могу смело утверждать следующие вещи. Активировать нейрон кроме постоянной и ассоциативной памяти может еще и мотивация. Мотивационные, санкционирующие и эмоциональные входы используются как внешнее управление и оценивание активности нейрона. Функция нейрона, по которой он обучается и работает, называется «Семантический вероятностный вывод». И никакой речи о «жалкой» суммации выходов там нет. Эта нейросеть не занимается извлечением данных, она занимается проблемой удовлетворения своих эмоциональных потребностей. Необходимо моделировать как саму нейросеть, так и окружающую среду, с которой она связана. Выходы нейросети должны влиять на окружающий мир, иначе смыла от её функционирования не будет.
С точки зрения внешнего наблюдателя семантический вероятностный вывод для главенствующей в данный момент эмоции можно рассматривать как вычисление истинности предсказываемого удовлетворения эмоции при помощи нейросети, отражающей представление о окружающей среде. От рецептивного поля к выходам нейросети проходит сигнал-молния, идущая по пути наименьшего сопротивления (фактически путь состоит из наибольших вероятностей), а эмоции, санкции и мотивации, это ключ, который разрешает или запрещает нейронам пропустить молнию.

От логического вывода семантический вероятностный вывод отличается тем, что каждый нейрон, это достоверное с некоторой вероятностью правило вывода, которое получено наблюдением за окружающей средой, в то время как в логическом выводе все правила выведения строго заданы, абсолютно достоверны и их количество неизменно.
Получается, что нечеткая логика выезжает на нечеткой логике, да еще вероятностью погоняет. Пример работы нейросети можно описать еще и так. Если нам очень хочется попасть из лесу к себе домой, то мы запрягаем (используем вероятные правила вывода) не то корову, не то коня, и едем (вероятные результаты) не то на съемную квартиру, не то к бабушке. Выигрывает вариант с нашей точки наиболее приближённый к реальности (вероятный) в данной ситуации.
Описывать работу эмоций, санкций и мотиваций в этом методе я не буду, так как сам еще до конца не разобрался, да и место много займет. Утолять жажду знаний здесь.
www.math.nsc.ru/AP/ScientificDiscovery/PDF/principals_anokhin_simonov.pdf
Другие «современные» методы работы с нейросетями
Мало знать себе цену — надо еще пользоваться спросом.
Метод эффективной эволюции топологии в нейросетях – тот самый метод с эволюционным алгоритмом, только для топологии нейросети. В принципе эволюционный алгоритм стал в последнее время своеобразной палочкой выручалочкой. Если у вас нет идей в вашей сфере научной деятельности, достаточно применить эволюционный алгоритм, бац, и «brand new» научное направление у вас в кармане, если кто-либо смышленый не додумался до этого раньше вас. Универсальный решатель проблем существует, достаточно проблему проэволюционировать.
http://nn.cs.utexas.edu/downloads/papers/stanley.cec02.pdf
Другой способ использования эволюционного алгоритма, это заменить им алгоритм машинного обучения в нейросети. По сути ничего нового, еще более тривиальный метод, чем предыдущий. Указания ссылки не заслуживает.
Литература
Лучше помалкивать и казаться дураком, чем открыть рот и окончательно развеять сомнения.
Оригинальность — это искусство скрывать свои источники.
- Иерархическая темпоральная память (HTM) и ее кортикальные алгоритмы обучения https://www.groksolutions.com/htm-overview/education/HTM_CorticalLearningAlgorithms_ru.pdf
- Асинхронный пиринговый интеллектуальный анализ данных с градиентным спуском http://www.inf.u-szeged.hu/~ormandi/presentations/europar2011.pdf
- Витяев Е.Е. Принципы работы мозга, содержащиеся в теории функциональных систем П.К. Анохина и теории эмоций П.В. Симонова http://www.math.nsc.ru/AP/ScientificDiscovery/PDF/principals_anokhin_simonov.pdf
- Жданов А.А. Автономный искусственный интеллект. М.: БИНОМ. Лаборатория знаний, 2008.
ссылка на оригинал статьи http://habrahabr.ru/post/181456/
Добавить комментарий