Конечно же, я не имел опыта работы с изображениями, и распознаванием и начал поиск библиотек для распознавания бланков. К сожалению найти чего-либо бесплатного не удалось. Поэтому я засучил рукава и принялся писать самостоятельно.
Я не буду писать код здесь, так как считаю, что основная проблема при создании подобной системы заключается в алгоритме работы.
Итак…
Для начала были созданы бланки. Для каждой методики свой, но отличаются они только количеством вопросов и количеством ответов в вопросах.

Бланки с моих слов создал хороший товарищ и коллега по работе. Изначально они были созданы в Excel и сохранены в формат PDF.
Самая важная деталь в бланке — черные квадраты (я назвал их маркеры). Верхний центральный маркер нужен для определения где верх, а где низ бланка. При психодиагностике испытуемому предлагается нарисовать диагональный крестик в нужной ячейке. При этом предполагается, что:
1. Уровень образования испытуемого может быть низким.
2. Это не экзамен, и испытуемый ошибается, много раз перечеркивает.
3. Испытуемый пользуется карандашами, шариковыми, гелевыми ручками разного цвета чернил.
4. Испытуемый плохо поддается инструктированию и вместо крестиков ставит галочки.
Теперь поэтапная формализация самой задачи работы с системой распознавания бланков тестирования:
1. Снять изображение бланка с устройства ввода.
2. Привести изображение в некий стандартный вид.
3. Найти на изображении ячейки, которые необходимо распознать.
4. Распознать ячейки.
5. Сохранить ответы.
Теперь обо всем по порядку.
1. Получение изображения для обработки.
Я выбрал планшетный сканер как наиболее дешевое и распространенное средство получения изображения. В родной для C# операционной системе существуют два основных API для работы со сканерами: TWAIN и WIA. С WIA проблем не возникло. Технология отлично поддерживается в Windows, хорошо документирована и в сети имеется много примеров. Самое сложное было задать параметры сканирования.
Неприятная вещь технологии WIA это список поддерживаемых устройств. Их мало. Поэтому пришлось добавить возможность работы с TWAIN сканерами. Я использовал бесплатную библиотеку TwainDotNet. Единственный ее недостаток — проверка сканера на совместимость в начале сканирования. Старые сканера, например не проходят проверку из-за отсутствия функций автоповорота изображения. Учитывая открытость исходных кодов, я быстро исправил положение дел.
При использовании обоих API, я отключал их стандартные GUI. Задавал размер изображения A4 и разрешение 100 DPI. Для полноты возможностей я инкапсулировал в свой класс Scanner возможность выбора изображения из файла.
2. Нормализация изображения.
Приведение изображения к универсальному виду разделена на этапы:
1. Приведение изображения к разрешению 100 DPI.
2. Бинаризация изображения.
3. Нахождение маркеров.
4. Поворот изображения.
Для работы с изображениями я использовал AForge.NET Framework. Это бесплатно и удобно, так как не нужно писать многочисленные алгоритмы работы с изображениями, тем более, что для скорости работы писать бы пришлось небезопасный код, а я новичок в C#. В дальнейшем я буду ссылаться на классы именно этой библиотеки.
Итак, в начале входящее изображение приводится к 100 DPI. Меньшее разрешение грозит проблемами при бинаризации, а большее проблемами скорости обработки. Затем переводим изображение в цветовой режим «Градации серого». Для этой операции используем класс GrayScale. Для бинаризации изображения я использовал BradleyLocalThresholding. Алгоритм отлично справляется с небольшими завалами яркости.
Одним из сложных нюансов успешного распознавания является правильная ориентация изображения. Поворот на 3-4 градуса, и все пропало. Потоковой подачи нет, сканер планшетный, бланки мятые. В общем, для определения угла поворота бланка я использовал DocumentSkewChecker. А для поворота изображения RotateBilinear, потому что он быстрый. Такой поворот выравнивал изображение в диапазоне 0-45 градусов, но оно могло оставаться перевернутым. Поэтому необходимо найти маркеры и по центральному определить верх бланка.
Для поиска объектов на изображении я успешно применил BlobCounter. Для определения маркеров я отфильтровал все найденные объекты по размерам и по свойству Fullness, установив порог 0.8. И если не находил сверху трех маркеров — переворачивал изображение на 180 градусов.
Такими нехитрыми манипуляциями все изображения приводятся к единому виду и формату.
3.Нахождение ячеек ответов для распознавания
Для нахождения ячеек ответов был использован самый простой способ. Я взял эталонный пустой бланк каждой методики и сохранил в базе данных центр первой (левой) ячейки каждого вопроса. Так же сохранил расстояние между центрами ячеек каждого вопроса и размеры ячеек. Таким образом, для определения областей распознавания я просто брал данные из базы. Здесь нужно сделать два очень важных замечания. Если сканируемый бланк мятый, то области распознавания будут неверны, так как эталонный бланк ровный. Процент ошибок при этом будет слишком велик. Вот что получается, если это игнорировать:
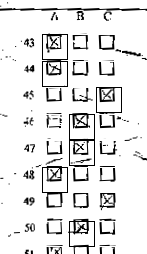
Решается довольно просто. Область первой ячейки расширяется от центра. Затем в этой области я ищу объект с помощью BlobCounter. После нахождения ячейки внутри расширенной области, область сжимается относительно найденного центра. Выглядит все примерно так:
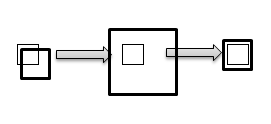
Эти манипуляции производятся только с первой ячейкой каждого вопроса, координаты остальных ячеек пересчитываются относительно ее.
Так же размеры изображения (области распознавания) могут незначительно изменяться, поэтому данные о ячейках сохранять нужно не в абсолютных координатах на исходном изображении а их позицию относительно маркеров. Это вторая важная функция маркеров.
Стоит отметить, что находить области распознавания можно и не зная их координаты. Это делается на основе вертикальных и горизонтальных гистограмм яркости. Однако я не использовал этот алгоритм, и описывать его не буду.
4. Распознавание ячеек
Вот здесь я и застрял. Распознавание, по сути это задача классификации. С учетом стоящей задачи имеется 3 класса ячеек:
1. Пустая (free).
2. Отмеченная испытуемым (cross).
3. Ошибочно отмеченная испытуемым (miss).
С классом free все ясно. Это абсолютно пустая ячейка, не тронутая пером испытуемого. Но у класса cross уже есть проблемы: в ячейке может находится что угодно. Не смотря на отличный инструктаж, лица, проходящие тестирование не слишком старательно выписывают диагональные крестики. Дополнительно испытуемые заинструктированы заштриховывать ячейку, если они ошиблись и хотят исправить вариант своего ответа. Это и есть класс miss.
По большому счету у меня было два варианта подхода к классификации: разделение ячеек по уровню яркости и использование методов машинного обучения. Как старый поклонник нейронных сетей (писал как-то на vba) я взял библиотеку Encog и обучил многослойный персептрон на 20 заполненных бланках тестирования. И получил ошибку 15-35% неверных ответов. Стало понятно, что необходимо использовать более тонкие алгоритмы (сверточные сети, ансамбли сетей, комбинация алгоритмов обучения). При этом необходимо было предъявить сети различные варианты классов ячеек, например такие:

В итоге всех проб и ошибок я вернулся к классификации по яркости. Только не по сумме яркостей всех пикселей ячейки, так как получается не слишком чувствительно. Я использовал класс VerticalIntensityStatistics для вертикальной гистограммы сумм яркостей пикселей ячейки. Ниже гистограмма класса cross и гистограмма класса free:
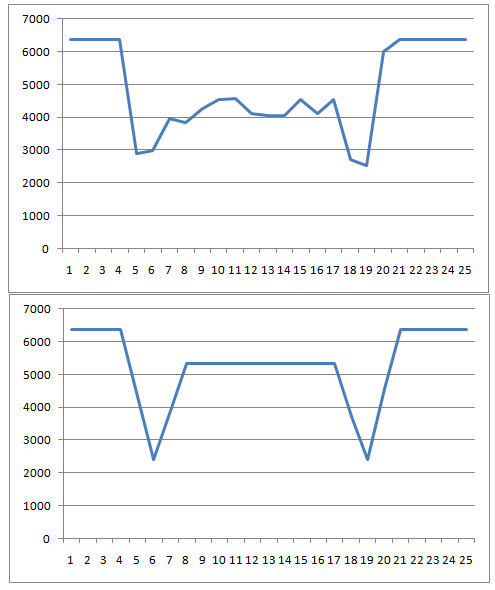
Я брал значения гистограммы для вертикальных пикселей с 8 по 17 (обрезал минимумы) и использовал формулу: порог = 1 — среднее(значение гистограммы для яркости) / максимальная яркость. По значению порога я определял класс ячейки. Как правило, классы разделялись так:
от 0 до 0.18 класс free,
от 0.18 до 0.6 класс cross,
от 0.6 до 1 класс miss.
5. Сохранение ответов.
Так как система не автоматическая, а автоматизированная возникающие при распознавании ошибки допускается исправлять вручную. После этого ID ячейки класса cross отправляется в базу.
Внешне интерфейс распознавания выглядит так:
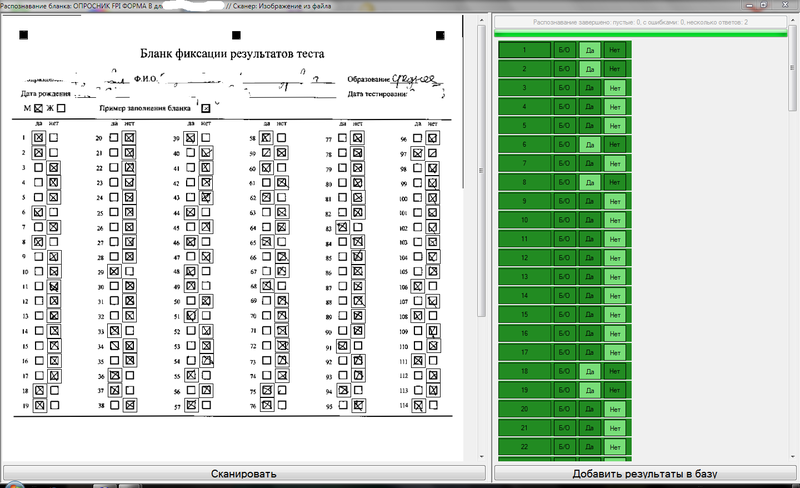
В итоге:
За три месяца изучения языка C# я сделал бесплатное приложение для распознавания бланков психологического тестирования. Предварительное использование показало пропускную способность примерно 1 бланк за полторы минуты. Это очень неплохо, учитывая ручной ввод личных данных перед распознаванием.
Сейчас я с удовольствием правлю свой ужас код, и даже, что греха таить, пишу документацию с целью выдать продукт людям. А заодно оптимизирую процесс классификации.
А может быть эта статья подстегнет какого-либо профи на написание отличного бесплатного фреймворка для распознавания бланков, хотя бы для таких простых нужд как у моего хорошего товарища и коллеги по работе…
ссылка на оригинал статьи http://habrahabr.ru/post/181878/
Добавить комментарий