Наконец добрались до самой мякотки, в этой части — лексический и синтаксический разбор, PSI (Program Structure Interface), стабы (Stubs). Предыдущие части: 1, 2, 3
IntelliJ IDEA это не только Java IDE, но и мощная платформа для построения инструментов разработки для любого языка. Большинство функций IDEA состоят из двух частей: независимой от языка и специфической для конкретного языка программирования. Поэтому поддержка особенностей какого-либо языка не требует особых усилий – необходимо реализовать лишь специфическую часть, а независимая от языка предоставляется платформой. В дополнение, IDEA предоставляет мощный фреймворк, который позволяет реализовывать собственные функции, необходимые при разработке инструментария.
Регистрация типа файла
Первым шагом при разработке плагина специфического языка является регистрация связанного с ним файлового типа. Обычно IDEA определяет тип файла в соответствии с его именем (расширением).
Тип файла специфического языка – это класс, унаследованный от LanguageFileType, который передает экземпляр класса Language в родительский конструктор. Для регистрации типа файла необходимо предоставить реализацию интерфейса FileTypeFactory, зарегистрированную в точке расширения com.intellij.fileTypeFactory:
<extensions defaultExtensionNs="com.intellij"> … <fileTypeFactory implementation="com.intellij.lang.properties.PropertiesFileTypeFactory"/> … </extensions>
Пример реализации класса LanguageFileType в Properties плагине.
Для проверки корректности регистрации, следует убедиться, что иконка, отображаемая рядом с файлами, имеющими расширение, ассоциированное с пользовательским типом файла, совпадает с иконкой, определенной в методе getIcon().
Реализация лексического анализатора
Лексер (лексический анализатор) определяет, как содержимое файла будет разбито на последовательность токенов. Лексер служит фундаментом для почти всех функций языковых плагинов, начиная с подсветки синтаксиса и заканчивая функциями анализа кода. API лексера определен в интерфейсе Lexer.
IDEA вызывает лексер в трех основных контекстах и плагин должен предоставить реализацию для каждого из них:
- подсветка синтаксиса – лексер должен возвращаться реализацией интерфейса SyntaxHighlighterFactory, зарегистрированной в точке расширения com.intellij.lang.syntaxHighlighterFactory;
- построение абстрактного синтаксического дерева – лексер должен быть возвращен из метода ParserDefinition.createLexer(), реализация интерфейса ParserDefinition должна быть определена в точке расширения com.intellij.lang.parserDefinition;
- построение индекса слов, содержащихся в файле – если используется реализация сканера, основанная на пользовательском лексере, то он передается как аргумент конструктора класса DefaultWordsScanner.
Лексер, используемый для подсветки синтаксиса может вызываться инкрементально, для обработки лишь изменившейся части файла. В остальных случаях лексеры вызываются для обработки файла целиком, либо законченной языковой конструкции, встроенной в файл другого типа.
Вызываемый инкрементально лексер должен возвращать свое текущее состояние, т.е. контекст, соответствующий каждой позиции в файле. Важным требованием для подсветки синтаксиса является представление состояния обычным числом (возвращаемым из метода Lexer.getState()). Это состояние будет передано в метод Lexer.start() вместе со стартовым смещением фрагмента для обработки, когда необходимо продолжить лексический разбор в середине файла. Лексеры в других контекстах могут просто возвращать 0.
Для упрощения создания лексического анализатора специфического языка программирования можно воспользоваться генератором лексеров, таким как JFlex. IDEA включает классы адаптеров (FlexLexer и FlexAdapter), которые приспосабливают JFlex-лексеры к лексическому API IDEA. В исходных кодах Intellij IDEA Community Edition содержится модифицированная версия JFlex 1.4.1 и файл с заготовкой лексера, которые могут быть использованы при разработке лексеров, совместимых с FlexAdapter. Модифицированная версия JFlex предоставляет новую опцию командной строки --charat, которая изменяет генерируемый код так, чтобы он работал с IDEA (которая требует CharSequence вместо массива символов).
Для облегчения разработки лексеров с помощью JFlex существует плагин, предоставляющий подсветку синтаксиса и прочие полезные функции.
Пример: лексер из плагина Properties.
Необходимо помнить, что лексеры, в том числе основанные на JFlex, должны разбирать файл целиком, без каких-либо пропусков между токенами, т.е. в случае обнаружения недопустимых символов им должен быть присвоен тип токена, зарезервированный для таких случаев — TokenType.BAD_CHARACTER. И, тем более, лексер не должен прерывать свою работу до окончания разбора.
Типы токенов в IDEA определяются как экземпляры класса IElementType. Некоторые типы токенов, общие для большинства языков, определены в интерфейсе TokenType. Пользовательские плагины должны переиспользовать их в своих реализациях лексеров. Остальные типы токенов плагин должен ассоциировать с самостоятельно созданными объектами класса IElementType. Одни и те же экземпляры IElementType должны возвращаться каждый раз, когда лексер разбирает соответствующий токен.
Пример: типы токенов, используемые в языке Properties.
Важная особенность, которая может быть реализована на уровне лексера – это смешение языков внутри файла (например, встроенные фрагменты Java-кода в файле с шаблоном). Если язык поддерживает встраивание фрагментов, они должны определяться как токены-«хамелеоны», различные для разных типов фрагментов, при этом тип токена должен реализовывать интерфейс ILazyParseableElementType. Для разбора фрагмента, IDEA вызовет парсер соответствующего языка, посредством вызова метода ILazyParseableElementType.parseContents().
Синтаксический анализ и PSI
Синтаксический разбор в IntelliJ IDEA проходит в два шага. На первом строится абстрактное синтаксическое дерево, определяющее структуру программы. Узлы AST, представленные экземплярами класс ASTNode, создает сама IDEA. Каждый узел имеет ассоциированный с ним тип элемента (как объекта типа IElementType), который определяется плагином. Узел AST верхнего уровня, представляющий файл, должен иметь специальный тип элемента, реализующий интерфейс IFileElementType.
Узлы AST имеют прямое отображение на текстовые диапазоны нижележащего документа (листовым узлам сопоставляются конкретные токены, возвращенные лексером, узлы более высокого уровня содержат фрагменты из нескольких токенов).
Операции, совершаемые над узлами AST (вставка, удаление, переупорядочение и т.д.) немедленно отражаются как изменения текста нижележащего документа.
На втором шаге создается PSI (Program Structure Interface) на основе абстрактного синтаксического дерева, добавляя семантику и методы для манипулирования конкретными языковыми конструкциями. Узлы PSI представлены классами, реализующими интерфейс PsiElement, они создаются методом ParserDefinition.createElement(). Корневой узел PSI-дерева должен реализовывать интерфейс PsiFile и создаваться в методе ParserDefinition.createFile().
Пример: ParserDefinition для плагина Properties.
Базовые классы для реализации PSI элементов (PsiFileBase, основанный на PsiFile, ASTWrapperPsiElement, на базе PsiElement) предоставляются самой IntelliJ IDEA, т.е. содержатся во внутренней реализации. Поэтому при разработке плагинов под версию 10.5 и младше необходимо убедиться, что idea.jar находится в classpath. В более новых версиях (начиная с 11.0) он добавляется в classpath автоматически.
Реализация парсера
IntelliJ IDEA не предоставляет возможность использовать готовые грамматики языков программирования (таких как ANTLR) для создания синтаксических анализаторов в пользовательских плагинах. Но парсер и PSI-классы могут быть сгенерированы с помощью плагина Grammar-Kit. Кроме генерации кода он предоставляет другие возможности для редактирования грамматик: подсветку синтаксиса, навигацию, рефакторинг и прочее.
Метод createParser() класса ParserDefinition в языковом плагине должен предоставлять парсер, реализующий интерфейс PsiParser. Парсер получает экземляр класса PsiBuilder, который используется для получения потока токенов от лексера и создания промежуточного представления AST. Парсер обязан обработать каждый токен до конца последовательности (пока PsiBuilder.getTokenType() не возвратит null), даже если токены не совпадают с синтаксисом языка.
В ходе работы парсер устанавливает пары из маркеров (объектов класса PsiBuilder.Marker) и токенов, полученных от лексера. Каждая пара маркеров определяет диапазон токенов относящихся к каждому узлу абстрактного синтаксического дерева. Если пара из маркеров вложена в другую пару, она становится дочерним узлом внешней пары.
Тип элемента для маркерной пары (и для узла AST, созданного на базе нее) определяется, когда установлен концевой маркер (был вызван метод PsiBuilder.Marker.done()). Также возможно сбросить начальный маркер, до установки конечного. Метод drop() сбрасывает только один начальный маркер и не влияет на остальные, установленные позже него. Метод rollbackTo() сбрасывает начальный маркер и все установленные после него, возвращая позицию лексера к началу стартового маркера. Эти методы могут быть использованы для реализации заглядывания вперед (lookahead) при разборе.
Метод PsiBuilder.marker.precede() полезен для разбора справа – налево, когда неизвестно сколько маркеров нужно к определенной позиции до того как прочитать очередной токен. Например, бинарное выражение a+b+c должно быть разобрано как ((a+b) + c). Таким образом, два стартовых маркера нужны на позиции токена «a», но это неизвестно, пока не прочитан токен «с». Когда парсер достигает токена «+», следующего за «b», то он может вызвать precede() для дублирования стартового маркера на позиции «a» и затем поместить конечный маркер на позицию за «c».
Другой важной особенностью PsiBuilder является сохранение пробельных символов и комментариев. Типы токенов, обрабатываемые как пробелы и комментарии определены в методах getWhitespaceTokens() и getCommentTokens() в классе ParserDefinition. PsiBuilder автоматически пропускает токены пробелов и комментариев в последовательности, которая передается в PsiParser и подстраивает диапазоны токенов в узлах AST, так чтобы начальные и конечные пробелы не попадали в узел.
Набор токенов, возвращаемый методом ParserDefinition.getCommentTokens() также используется для поиска TO DO пунктов.
Для того чтобы лучше понять процесс построение PSI дерева, для простого выражения можно обратиться к следующей диаграмме на рисунке ниже.
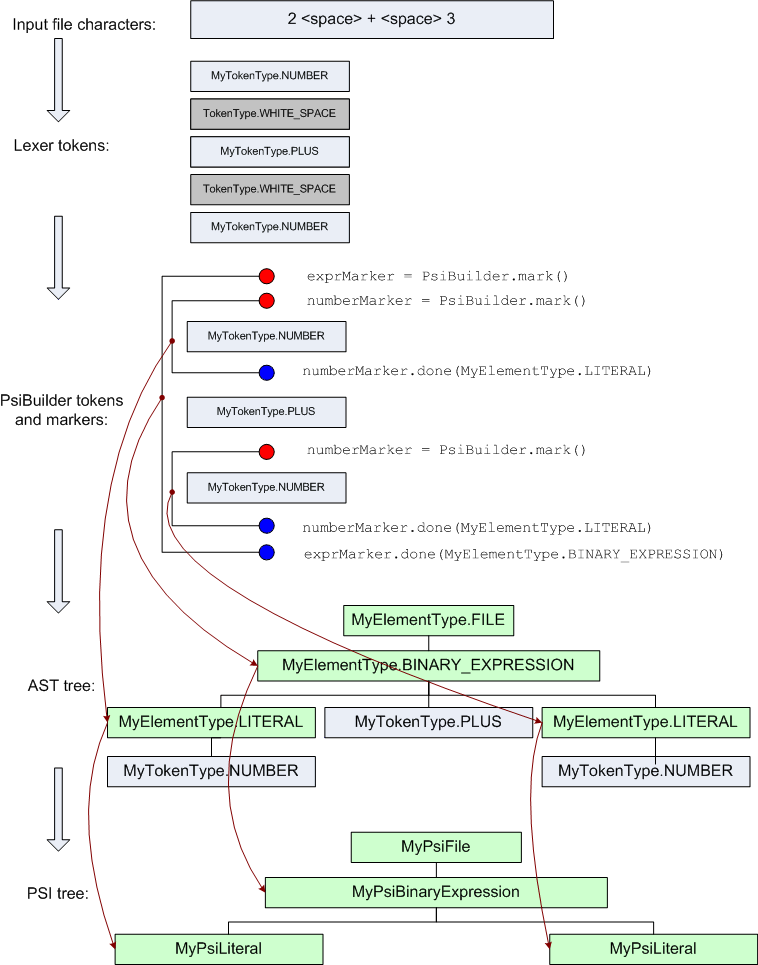
Не существует единственного верного пути реализации PSI в пользовательском плагине, т.е. можно выбрать ту структуру PSI и набор методов, которые наиболее удобны для реализации языковых возможностей (анализа ошибок, рефакторинга и т.д.). Тем не менее, есть один базовый интерфейс, который необходимо использовать в языковом плагине, для того чтобы реализовать поддержку таких функций как переименование и поиск использований. Каждый элемент, который может быть переименован или иметь ссылки (например, определение класса, метода и т.п.) должен реализовать интерфейс PsiNamedElement, с методами setName(), getName().
Множество функций, которые могут быть использованы для реализации и использовании PSI могут быть найдены в пакете com.intellij.psi.util, в частности классы PsiUtil, PsiTreeUtil.
Один из крайне полезных инструментов для отладки реализации PSI — это плагин PsiViewer. Он умеет показывать структуру PSI, построенную пользовательским плагином, свойства каждого элемента и подсветку текстовых диапазонов, привязанных к PSI-элементам.
Индексация и стабы
Индексирующий фреймворк IntelliJ IDEA предоставляет способ быстрого поиска определенных элементов (например, файлов, содержащих определенные слова или методы с заданным именем) в обширных кодовых базах. Разработчики могут использовать как существующие индексы встроенные в саму IDEA, так и свои собственные.
IDEA поддерживаем два основных типа индексов: основанные на файлах и индексы стабов (stubs). Файловые индексы построены поверх содержимого файлов, а индексы стабов строятся на основе сериализованных деревьев стабов. Дерево стабов для файла с исходным кодом — это подмножество его PSI-дерева, которое содержит только внешне видимые определения, сериализованные в компактном бинарном формате. Запрашивая файловые индексы, плагин получает множество, состоящее из файлов, подпадающих под заданное условие, в свою очередь индексы стабов работают напрямую с PSI-элементами. Следовательно, разработчики языковых плагинов должны отдавать предпочтение stub-индексам.
Файловые индексы
Файловые индексы в IntelliJ IDEA базируются на архитектуре map/reduce. Каждый индекс имеет определенные типы ключей и значений. Ключи используются в операциях извлечения данных из индекса, например, в индексе слов ключом является строка, содержащая слово. Значением ключа в индексе может быть любая информация, например, в индексе слов это может быть маска, определяющая контекст, в котором находится слово (код, литерал, комментарий). В простейшем случае (когда требуется лишь определить в каком файле находятся данные) значение имеет тип void и не сохраняется в индексе.
После индексации файла, индекс возвращает таблицу ключей и ассоциированных с ними значений. При обращении к индексу по определенному ключу, он возвращает список файлов и данные, связанные с этим ключом.
Реализация файлового индекса
Для лучшего понимания приведем пример довольно простой реализации файлового индекса, а именно индекс границ форм, применяемый в UI Designer.
Каждая специфическая реализация индекса наследует класс FileBasedIndexExtension и должна быть зарегистрирована в точке расширения <fileBasedIndex>. Реализация содержит следующие основные части:
- getIndexer() — возвращает класс индексатора, который отвечает за построение актуального множества пар ключ/значение, основанного на содержимом файла;
- getKeyDescriptor() — возвращает дескриптор, отвечающий за сравнение ключей и сохранение их в бинарный формат. Возможно самая распространенная реализация — это EnumeratorStringDescriptor (уже адаптирован для эффективного хранения идентификаторов);
- getValueExternalizer() — возвращает сериализатор значений, берет на себя функцию сохранения значений в сериализованный бинарный формат;
- getInputFilter() — позволяет ограничить индексацию определенным набором файлов;
- getVersion() — версия реализации индекса. Индекс автоматически перестроится, если текущая версия отличается от той с помощью которой был построен предыдущий индекс.
Если не требуется связывать значения с файлами, упростить реализацию можно унаследовав класс ScalarIndexExtension.
Отметим, что данные, возвращаемые DataIndexer.map() должны зависеть только от значений, переданных в метод, а не от каких-либо внешних файлов. В противном случае, индекс не будет корректно обновлен и когда внешнее состояние изменится, индекс будет указывать на устаревшие данные.
Доступ к файловому индексу
Доступ к индексам производится посредством класса FileBasedIndex, которые поддерживает такие операции как:
- getAllKeys() и processAllKeys() — позволяет получить список всех ключей, в файлах, относящихся к текущему проекту. Отметим, что возвращенные данные гарантировано содержат все ключи, найденные в актуальном содержимом проекта, но также могут содержать и уже несуществующие.
- getValues() — позволяет получить все значения, ассоциированные с заданным ключом (но не файлы, в которых они найдены);
- getContainingFiles() — позволяет получить список файлов, содержащих переданный ключ;
- processValues() — позволяет последовательно обработать все файлы, в которых находится определенный ключ и в то же время получить доступ к ассоциированным значениям.
Стандартные индексы
Некоторые стандартные файловые индексы, содержащиеся в IDEA часто бывают полезны разработчикам плагинов. Например, вышеупомянутый индекс слов. Не предоставляет прямой доступ плагинам, но используется открытым вспомогательным классом PsiSearchHelper. Второй полезный индекс — это FilenameIndex, позволяющий быстро находить файлы по их именам. И наконец FileTypeIndex — позволяет искать файлы по типу.
Деревья стабов
Как было отмечено выше, дерево стабов это подмножество PSI-дерева, сохраненное в компактном бинарном формате.
PSI-дерево отдельного файла может быть основано как на AST (т.е. создано в процессе синтаксического разбора текста), так и на stub-дереве (десериализовано с диска), переключение между обоими вариантами прозрачно.
Stub-дерево содержит только подмножество узлов (обычно только те узлы, которые используются для разрешения внешних ссылок на определения, находящиеся в данном файле). Попытка доступа к любому узлу вне дерева или выполнение операции, для которой не хватает данных, предоставленных деревом стабов, приводит к перестроению PSI-дерева на основе AST.
Каждый стаб в дереве является обычным Bean-классом без поведения, который сохраняет подмножество состояния соответствующего PSI-элемента (например, его имя, модификаторы доступа и т.д.). Стаб содержит указатель на родительский узел и список дочерних стабов.
Чтобы использовать стабы в собственном плагине, необходимо решить какие элементы PSI-дерева следует сохранять. Как правило, необходимо сохранить такие элементы как методы и поля, видимые из других файлов, с другой стороны операторы и локальные переменные сохранять не рекомендуется.
Для каждого типа элемента, который требуется сохранить в дереве стабов, необходимо выполнить следующие шаги:
- Определить интерфейс, унаследованный от StubElement (пример);
- Предоставить его реализацию (пример);
- Удостовериться, что интерфейс PSI-элемента расширяет StubBasedPsiElement параметризованный типом интерфейса стаба (пример);
- Проверить, что реализация класса PSI-элемента расширяет StubBasedPsiElementBase параметризованный типом интерфейса стаба (пример). Предоставить два конструктора: один для ASTNode, второй для стаба;
- Создать класс, реализующий IStubElementType и параметризованный типами интерфейса стаба и интерфейса PSI-элемента (пример). Реализовать методы createPsi() и createStub(), реализовать serialize() и deserialize() для сохранения в бинарном потоке;
- Использовать класс, реализующий IStubElementType как тип элемента во время парсинга (пример);
- Удостовериться, что все методы в PSI-элементе получают данные либо из стаба, либо из PSI-дерева (пример: реализация Property.getKey()).
Следующие шаги необходимо выполнить только один раз для каждого языка, поддерживающего стабы:
- Изменить тип элемент для файла (возвращается из метода ParserDefinition.getFileNodeType()) на класс, расширяющий IStubFileElementType;
- В plugin.xml, в расширении
<stubElementTypeHolder>определить интерфейс, содержащий константы IElementType, используемые парсером (пример).
Для сериализации строковых данных в стабах (каких как имена элементов), рекомендуется использовать методы StubOutputStream.writeName() и StubInputStream.readName(). Эти методы гарантируют, что каждый уникальный идентификатор будет сохранен только один раз, что позволяет уменьшить размер сериализованного дерева стабов.
При необходимости изменить сохраненный бинарный формат (например, добавить дополнительные данные или новые элементы), следует убедиться, что версия в IStubFileElementType.getStubVersion() увеличена. После чего индекс будет перестроен для устранения несоответствий при попытке прочитать данные старого формата.
По-умолчанию, если PSI-элемент расширяет StubBasedPsiElement, все элементы такого типа будут сохраняться в дереве стабов. Если требуется более тонкий контроль за тем, какие элементы стоит сохранять, необходимо переопределить IStubElementType.shouldCreateStub() и возвращать false для пропуска соответствующих элементов. Исключение элементов не рекурсивно, т.е. дочерние узлы пропущенного элемента будут сохранены в stub-дереве, если они не исключены тем же способом.
Индексы стабов
Во время построения stub-дерева, можно сохранять данные об элементах в индексы, которые затем могут быть использованы для поиска PSI-элементов по соответствующему ключу.
В отличие от файловых индексов, индексы стабов не поддерживают сохранение произвольных данных как значений; значениями всегда являются PSI-элементы. Ключами stub-индексов обычно служат строки (такие как имена классов), но при желании могут использоваться другие типы данных.
Индексы стабов реализуются как классы расширяющие AbstractStubIndex. В более распространенном случае, когда тип ключа — строка, можно использовать более специфичный класс StringStubIndexExtension. Индексы должны быть зарегистрированы в точке расширения <stubIndex>.
Для того чтобы сохранить данные в индексе, следует реализовать метод IStubElementType.indexStub() (пример), который принимает IndexSink как параметр и сохраняет идентификатор и ключ в каждом индексе, где должен быть сохранен элемент.
Для получения доступа к данным индекса, используются следующие методы:
- AbstractStubIndex.getAllKeys() — возвращает список всех ключей в заданном индексе для определенного проекта (например, список всех имен классов в проекте);
- AbstractStubIndex.get() — возвращает коллекцию PSI-элементов соответствующих заданному ключу (например, классы с заданным кратким именем) в определенном скопе.
В следующей части: подсветка синтаксиса, ссылочная система и связанные с ней функции.
Все статьи цикла: 1, 2, 3, 4.
ссылка на оригинал статьи http://habrahabr.ru/post/187224/
Добавить комментарий