• Роль морфологии в компьютерной лингвистике
• Морфология. Задачи и подходы к их решению
• Псевдолемматизация, композиты и прочие странные словечки
Раньше автоматический перевод работал следующим образом:
- Анализировал формы слов в исходном предложении;
- Пытался подобрать одну из синтаксических схем исходного языка, в которую подошло бы предложение с найденными формами;
- Находил соответствующую синтаксическую схему для целевого языка;
- Находил перевод для каждой из словоформ в исходном предложении;
- Слова-переводы ставил в форму, необходимую для целевой синтаксической схемы.
Современные технологии пытаются пойти дальше.
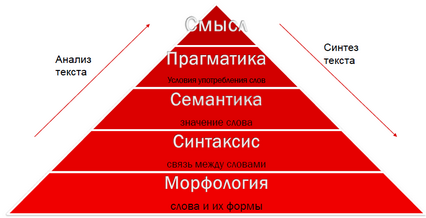
Они пытаются объяснить значение каждого слова в предложении, поднимаясь в пирамидке на рисунке на уровень семантики. Это помогает уточнить перевод, так как отметаются гипотезы, в которых не согласуется семантика отдельных слов. Кроме того, из семантических соображений некоторые синтаксические правила могут быть применимы не для всех слов языка. А также семантика в некоторой мере позволяет избавиться от омонимии.
Например:
- Standard steel helmets were painted matt greenish-grey. -> Шлемы из стандартной стали были окрашены в матово-зеленовато-серый.
- Konstantin Somov painted this exquisite still-life in 1923. -> Константин Сомов написал этот изысканный натюрморт в 1923 году.
Конечной целью такого процесса является понимание смысла текста. Тем не менее, в нашей пирамиде между значением и смыслом есть целая ступень, которая нами пока не преодолена.
Прагматика языка – это то, как человек относится к тому, что он говорит. Классический пример: «Может ли двойное утверждение означать отрицание?» — «Ну да, конечно!». Здесь за двойным утверждением прячется прагматический слой понимания языка.
Но не будем забегать вперёд, пройдёмся снизу вверх по пирамиде.
Морфология
Базовым уровнем пирамиды понимания текста на естественном языке является морфологический слой. Без знания морфологии языка выше идти очень сложно, как, впрочем, и спускаться вниз. Морфология представляет знание о формах в словаре и об их грамматических значениях.
Синтаксис
 Следующий уровень пирамиды – это синтаксис. Синтаксис определяет связь слов в предложении, управление слов, отношения между словами в естественном языке. Синтаксис должен уметь оперировать грамматическими значениями, которые он получает от морфологии. Это те данные, которые поступают к нему снизу вверх (см. схему в начале поста) на этапе анализа текста. Эти же данные он передает на уровень морфологии при синтезе текста, определяя, в какой форме должно быть то или иное слово на целевом языке.
Следующий уровень пирамиды – это синтаксис. Синтаксис определяет связь слов в предложении, управление слов, отношения между словами в естественном языке. Синтаксис должен уметь оперировать грамматическими значениями, которые он получает от морфологии. Это те данные, которые поступают к нему снизу вверх (см. схему в начале поста) на этапе анализа текста. Эти же данные он передает на уровень морфологии при синтезе текста, определяя, в какой форме должно быть то или иное слово на целевом языке.
Так происходит перевод. Нам дано предложение на русском языке. Сначала мы его анализируем морфологически, потом синтаксически, потом семантически. После этого семантика определяет синтаксическую форму предложения на целевом языке (к примеру, на английском), синтаксис выстраивает все лексемы в нужные формы, и от морфологии мы получаем непосредственно конкретные формы этих слов.
Семантика
На семантическом уровне задача существенно усложняется. Нам нужно понять, что значат те или иные слова. Морфология работает со словами по отдельности, она берет отдельное слово, – к примеру, «бокра», – и говорит: «Это существительное мужского рода в родительном падеже». Синтаксис смотрит на связь «бокра» с другими словами в предложении. «Будланула бокра» – «бокр» относится к глаголу «будланула» как дополнение.
Но на уровне семантики мы бессильны: мы не знаем, кто такой «бокр», и мы не знаем, что значит «будланула». До недавних пор технология автоматического перевода текста была бессильна даже в тех случаях, которые могут показаться нам очевидными. Она не знает, что прячется за фразой «Do you want a cup of tea?» Может быть, это кубок чая (cup как спортивный кубок), а может быть, всего лишь чашка.
Прагматика
Научить переводчик понимать и отслеживать прагматику еще сложнее, но и в этой области решаются локальные задачи. По большому тексту, например, по нескольким записям в блоге мы пытаемся автоматически понять эмоциональную окраску текста. Если мы научим компьютер понимать не только слова из текста, но и слова, которые автор имел в виду за ними, то можно будет сказать, что мы научили компьютер «читать между строк».
Задачи морфологии
Компьютерную лингвистику можно рассматривать как большое здание, а морфологию – как фундамент здания, решающий конкретные задачи. Ведь в программе это отдельная dll’ка, предоставляющая определенное API, от которой мы хотим получить конкретный результат. Табличка ниже упорядочивает задачи, которые возложены на модуль морфологии.
| Задача | Как используется |
| Получение начальной формы — Лемматизация | Поиск |
| Постановка слова в заданную форму | Автоматический перевод Синтез речи |
| Получение всех форм слова | Поиск Базы знаний Текстовый редактор OCR |
| Грамматическое значение | Автоматический перевод OCR Распознавание речи |
| Словарность слова | OCR |
| Исправление слова | Поиск Текстовый редактор |
Лемматизация
 Начнем по порядку: лемматизация – это получение начальной формы слова, или, по-другому, леммы. Если нам нужно восстановить начальную форму слова «будланула», у нас в голове сразу возникает слово «будлануть». Однако если попробовать провернуть подобный эксперимент со словом на неизвестном для нас языке, задача быстро перестанет казаться тривиальной.
Начнем по порядку: лемматизация – это получение начальной формы слова, или, по-другому, леммы. Если нам нужно восстановить начальную форму слова «будланула», у нас в голове сразу возникает слово «будлануть». Однако если попробовать провернуть подобный эксперимент со словом на неизвестном для нас языке, задача быстро перестанет казаться тривиальной.
Когда я учил немецкий язык в институте, для меня было ужасно искать в бумажном словаре слово «gemacht» и не находить это слово. Или найти не то слово и пытаться понять, как оно связанно с другими словами в предложении. А причина в том, что это форма глагола «machen», а не существительное «gemächt».
Признаться, я так и не выучил немецкий язык, зато навсегда запомнил, что словари должны уметь восстанавливать начальную форму слова, и, если это слово есть в словаре, показывать его. Так что, помимо занесенного в таблицу поиска, областью применения лемматизации являются еще и компьютерные словари.
Постановка слова в заданную форму
Обратной задачей является постановка слова в заданную форму. Когда мы пытаемся поставить слово в заданную форму, мы синтезируем речь, то есть получаем текст на определенном целевом языке. Соответственно, эта технология используется в автоматическом переводе и при синтезе искусственной речи.
Получение всех форм слова
Следующая задача — получения всех форм слова — чаще всего используется при поиске. Существует два подхода к индексации текста: первый – сопоставление слова из запроса со всеми формами этого слова в индексе, второй – получение леммы запрашиваемого слова и последующее сопоставление с начальными формами в индексе. В данном случае реализация зависит от специфики решаемой задачи. Может быть, вы пытаетесь проиндексировать весь интернет, а может быть, наоборот, какую-нибудь локальную базу знаний, но вам необходима высокая точность результатов.
Получение грамматического значения слова
Необходимость запроса у модуля морфологии грамматического значения возникает при необходимости понять смысл, который можно изъять из грамматического значения (например, действие перед нами или нет, прошедшее время или настоящее).
Словарность слова
На этом пункте мы уже останавливались раньше, поэтому просто закрепим: для распознавания текста очень важна словарность слова — принадлежит слово языку или не принадлежит.
Исправление слова
 При работе с текстовыми редакторами и, тем более, в современных мобильных устройствах при быстрой печати часто делаются опечатки. Раньше для их выявления служила технология Т9, которая по девяти кнопкам восстанавливала символы. Сейчас в смартфонах используется полноценная qwerty-клавиатура, но пальцы часто не попадают по нужным кнопкам, и слово нужно исправлять. Исправление – задача морфологии. Сейчас любой уважающий себя смартфон подскажет вам, как слово пишется на самом деле.
При работе с текстовыми редакторами и, тем более, в современных мобильных устройствах при быстрой печати часто делаются опечатки. Раньше для их выявления служила технология Т9, которая по девяти кнопкам восстанавливала символы. Сейчас в смартфонах используется полноценная qwerty-клавиатура, но пальцы часто не попадают по нужным кнопкам, и слово нужно исправлять. Исправление – задача морфологии. Сейчас любой уважающий себя смартфон подскажет вам, как слово пишется на самом деле.
Кроме того, исправление слова используется при индексировании интернета. В случае с вебом производительность становится особенно важной, потому что слова с ошибками встречаются очень часто. Мы не можем найти их в словаре в том виде, в котором их ввел пользователь, но перевести должны, потому что человек, прочитав это слово, понял бы, что имел в виду собеседник. Как говорится, «виласипед» или «велосипед», мопедом он от этого не станет, как ни напиши (кстати, об одной из реализаций «понятливого» спеллчекера можно почитать в этой статье).
Решения задач. Начнем с простого: лемматизация

Вернемся к нашим куздрам. Как нам получить начальную форму от слова «будланула»? Первое, что приходит на ум: меняется только окончание. Почему бы просто не заменять одни окончания на другие с помощью старых добрых регулярных выражений? Кстати, очень много морфологий, которые можно найти в интернете в открытом доступе, основаны именно на регулярных выражениях. Замена -ла в конце на -ть в нашем случае прекрасно работает: «будланула» на «будлануть». Однако стоит копнуть чуть глубже, и окажется, что работает далеко не всегда.
Подводные камни: омонимия

Омонимия – это совпадение форм разных слов. Более того, бывает так, что совпадают две формы одного и того же слова, а бывает – разных слов, как в нашем примере. «Стали» – это глагол прошедшего времени множественного числа или это множественное число от слова «сталь». Какая начальная форма: «стать» или «сталь»? Эта проблема не может быть решена на уровне морфологии: морфология рассматривает отдельное слово вне контекста, поэтому, какие методы ни применяй, омонимию не разрешишь. Но самое интересное, что даже на следующих уровнях, на синтаксическом, а порой и на семантическом, не всегда возможно разрешить омонимию. Приведенный выше расхожий пример – яркое тому подтверждение.
Как будто этого мало

Есть и другое возражение: не все слова употребляются во всех формах. Если мы из перехода «кружиться» – «кружить» вынесем такое правило, что -ться следует заменять на -ть, то слово «казаться» мы должны будем заменить на слово «казать». Но такого слова в русском языке нет.
Все сложно
Таким образом, получается, что если вам нужна дешевизна морфологии — например, вы проиндексировали большую базу, поискали по ней, и вас устраивает качество поиска, вы, конечно, можете остановиться на таком нулевом приближении лемматизации, но для более серьезных лингвистических технологий этой точности недостаточно и нужно делать что-то еще.
В активном поиске
О том, что же еще мы делаем, как храним то, что у нас получается, и какие задачи компьютерной лингвистики до сих пор ждут своего решения, будет рассказано в следующей статье.
ссылка на оригинал статьи http://habrahabr.ru/company/abbyy/blog/189020/
Добавить комментарий