
Введение
Тема данной статьи довольно обширна, и не ждите от неё детального и глубокого разбора всех нюансов. Если вы полагаете, что достаточно хорошо разбираетесь в Юникоде, кодировках и т.д., эта статья может быть для вас почти или даже полностью бесполезной. Тем не менее, довольно много людей не понимают, чем различаются двоичные и текстовые данные (binary и text), или что такое кодировка символов. Именно для таких людей и написана данная статья. Несмотря на, в общем-то, поверхностное описание, в ней затрагиваются некоторые сложные моменты, однако это сделано скорее для того, чтобы читатель имел представление об их существовании, нежели чтобы дать детальные разъяснения и руководства к действию.
Ресурсы
Нижеприведенные ссылки как минимум полезны настолько же, насколько и данная статья, а может — и более полезны. Я сам использовал их при написании данной статьи. В них много полезных и качественных материалов, и если в этой статье вы заметите какие-нибудь неточности, то данные ресурсы должны быть более точными.
- Официальный сайт Консорциума Юникода. Наиболее полный и точный источник информации по Юникоду, содержащий ответы на все ваши вопросы (правда, полезную информацию на сайте нужно хорошенько поискать). Некоторые нижеприведённые ссылки ведут на данный сайт.
- Глоссарий Юникода. Словарь с краткими толкованиями многих терминов, используемых при обсуждении кодировки символов и т.д.
- ЧаВо Юникода. Ответы на сотни общих вопросов, распределённые по группам.
- ЧаВо Юникода по Unix/Linux UTF-8. Не пренебрегайте данной ссылкой, судя по её названию — даже если вы не дружите с Unix/Linux, большинство информации очень релевантно и к .NET.
- Модель кодировки символов Юникода. Предоставляет больше информации о точном толковании терминов вроде «схема кодировки символа» и т.д.
- Джоэл Спольски. Обязательный минимум, который должен знать каждый разработчик ПО о Юникод и о наборах символов (Оправдания не допускаются). Статья, чем-то похожая на данную, но без акцента на .NET. (перевод на русский, перевод на Хабре часть 1, часть 2)
- О доброте Юникода. Ещё одна вводная статья, которую стоит почитать.
Двоичные и текстовые данные – это две разные вещи
Большинство современных языков программирования (как и некоторые старые) проводят ясную черту между двоичным (бинарным) контентом и символьным (или текстовым) контентом. Хотя эта разница понимается на инстинктивном уровне, я всё-таки внесу определение.
Бинарные (двоичные) данные являются последовательностью октетов (октет состоит из 8 битов) без всякого придаваемого им естественного значения, или интерпретации. И даже если существует внешнее «толкование» того или иного набора октетов как, скажем, исполняемый файл или графическое изображение, данные сами по себе являются просто набором октетов. Далее вместо термина «октет» я буду использовать «байт», хотя, если говорить точно, не всякий байт является октетом. К примеру, существовали компьютерные архитектуры с 9-битовыми байтами. Впрочем, в данном контексте такие детали не очень-то и нужны, так что далее под термином «байт» я буду подразумевать именно 8-битовый байт.
Символьные (текстовые) данные являются последовательностью символов.
Глоссарий Юникода определяет символ как:
- Наименьший компонент письменного языка, содержащий семантическое значение; указывает на абстрактный смысл и/или форму, в отличие от специальных форм (таких как глифы); в кодовых таблицах некоторые формы визуального представления символов имеют большое значение для их понимания читателем.
- Синоним абстрактного символа (см. Definition D3 в Section 3.3, Characters and Coded Representations).
- Базовая единица кодирования в системе кодировки Юникода.
- Английское наименование для идеографических письменных элементов китайского происхождения.
Это определение может быть, а может и не быть для вас полезным, но в большинстве случаев можно использовать интуитивное понимание символа, как что-то вроде некоего элемента, обозначающего большую литеру «А» или цифру «1» и т.д. Однако есть и другие символы, которые далеко не настолько интуитивно очевидны. К таковым относятся модифицирующие символы, которые предназначенные для изменения других символов (например, острое ударение, он же акут), управляющие символы (например, символ новой строки), форматирующие символы (невидимы, но влияют на другие символы). Текстовые данные — это и есть наборы символов, и это главное.
К большому сожалению, в недалёком прошлом различие между двоичными и текстовыми данными было очень размытым, нечётким. К примеру, для программистов на языке Си термины «байт» и «символ» в большинстве случаев значили одно и то же. В современных же платформах типа .NET и Java, где различие между символами и байтами чёткое и закреплено в библиотеках ввода-вывода, старые привычки могут иметь негативные последствия (к примеру, люди могут пытаться скопировать содержимое двоичного файла, считывая из него символьные строки, что приведёт к искажению содержимого этого файла).
Так для чего же Юникод?
Консорциум Юникода пытается стандартизировать обработку символьных данных, включая преобразования из двоичной формы в текстовую и наоборот (что называется декодированием и кодированием соответственно). Кроме того, существует набор стандартов ISO (10646 в различных версиях), которые делают то же самое; Юникод и ISO 10646 могут рассматриваться как одно и то же, так как они почти полностью совместимы. (В теории, ISO 10646 определяет более широкий потенциальный набор символов, но это вряд ли когда-нибудь станет проблемой.) Большинство современных языков и платформ программирования, включая .NET и Java, используют Юникод для представления символов.
Юникод определяет, среди прочего:
- репертуар абстрактных символов (abstract character repertoire) — набор всех символов, которые поддерживаются Юникодом;
- набор кодов символов (coded character set) — содержит привязку каждого символа из репертуара к целому неотрицательному числу, называемому кодовой точкой (code point);
- некоторые формы кодировки символов (character encoding forms) — определяют соответствия между кодовыми точками и последовательностями «кодовых единиц» (попросту говоря — соответствия между кодовой точкой, выраженной одним целым числом любой длины, и группой байт, кодирующей это число);
- некоторые схемы кодировки символов (character encoding schemes) — определяют соответствия между наборами кодовых единиц и сериализованными последовательностями байтов.
Различие между формой кодировки символов и схемой кодировки символов довольно тонкое, тем не менее, оно учитывает порядок байтов (endianness). (К примеру, в кодировке UCS-2 последовательность кодовых единиц 0xC2 0xA9 может быть сериализована как 0xC2 0xA9 или как 0xA9 0xC2 — это решает именно схема кодировки символов.)
Репертуар абстрактных символов Юникода может содержать, в теории, вплоть до 1114112 символов, хотя многие уже зарезервированы как непригодные, а оставшиеся, скорее всего, никогда не будут назначены. Каждый символ кодируется целым неотрицательным числом от 0 до 1114111 (0x10FFFF). К примеру, заглавная А закодирована десятичным числом 65. Ещё несколько лет назад считалось, что все символы «влезут» в диапазон между 0 и 216-1, а это значило, что любой символ можно представить при помощи двух байтов. К сожалению, со временем потребовалось больше символов, что привело к появлению т.н. «суррогатных пар» (surrogate pair). С ними всё стало значительно сложнее (по крайней мере, для меня), а потому большая часть данной статьи их касаться не будет — я кратко их опишу в разделе «Сложные моменты».
Так что же предоставляет .NET?
Не волнуйтесь, если всё вышесказанное выглядит странно. О различиях, описанных выше, следует знать, но на самом деле они не часто выходят на первый план. Большинство ваших задач, скорее всего, будет «крутиться» вокруг конвертации некоего набора байтов в некий текст и наоборот. В таких ситуациях вы будете работать со структурой System.Char (в C# известна под псевдонимом char), классом System.String (string в C#), а также с классом System.Text.Encoding.
Структура Char является самым базовым типом символа в C#, один экземпляр Char представляет один символ Юникода и занимает 2 байта памяти, а значит, может принимать любое значение из диапазона 0-65535. Имейте в виду, что не все числа из этого диапазона являются валидными символами Юникода.
Класс String в своей основе является последовательностью символов. Он неизменяем (immutable), что значит, что после создания экземпляра строки вы уже не можете его (экземпляр) изменить, — различные методы класса String, хотя и выглядят так, будто изменяют его содержимое, на самом деле создают и возвращают новую строку.
Класс System.Text.Encoding предоставляет средства конвертации массива байт в массив символов или в строку, а также наоборот. Этот класс является абстрактным; его различные реализации как представлены в .NET’е, так и могут быть написаны самими пользователями. (Задача по созданию имплементации System.Text.Encoding возникает довольно редко — в большинстве случаев вам хватит тех классов, которые идут в составе .NET’а.) Encoding позволяет отдельно указать кодеры и декодеры, которые обрабатывают состояние между вызовами. Это необходимо для многобайтовых схем кодировок символов, когда невозможно корректно декодировать в символы все байты, полученные из потока. Например, если декодер UTF-8 получает на вход два байта 0x41 0xC2, он может возвратить только первый символ (заглавную литеру «А»), однако для определения второй литеры ему нужен третий байт.
Встроенные схемы кодировок
Библиотека классов .NET содержит различные схемы кодировок. Ниже приведено описание этих схем и способы их использования.
ASCII
ASCII является одной из наиболее распространённых и одновременно одной из наиболее недопонимаемых кодировок символов. Вопреки популярному заблуждению, ASCII является 7-битной кодировкой, а не 8-битной: символов с кодами (кодовыми точками) больше числа 127 не существует. Если кто-либо заявляет, что он использует, к примеру, код «ASCII 154», то можно считать, что этот кто-то вообще не понимает, что он делает и говорит. Правда, в качестве отговорки он может заявить что-то о «расширенной ASCII» (extended ASCII). Так вот — нет никакой схемы под названием «расширенная ASCII». Есть множество 8-битных схем кодировок, которые являются надмножеством для ASCII, и для их обозначения иногда используют термин «расширенной ASCII», что не совсем корректно. Кодовая точка каждого ASCII-символа совпадает с кодовой точкой аналогичного символа в Юникоде: иными словами, ASCII-символ латинской литеры «x» в нижнем регистре и Юникодный символ этой же самой литеры обозначаются одинаковым числом — 120 (0х78 в шестнадцатеричном представлении). .NET-класс ASCIIEncoding (экземпляр которого легко может быть получен через свойство Encoding.ASCII), на мой взгляд, является немного странным, так как, кажется, он выполняет кодирование путём простого отбрасывания всех битов после базовых 7-ми. Это значит, что, к примеру, юникодный символ 0xB5 (знак «микро» — µ) после кодирования в ASCII и декодирования назад, в Юникод, превратится в символ 0x35 (цифра «5»). (Вместо этого я бы предпочёл, чтобы выводился какой-то специальный символ, показывающий, что исходный символ отсутствовал в ASCII и был утрачен.)
UTF-8
UTF-8 является хорошим и распространённым способом представления символов Юникода. Каждый символ кодируется последовательностью байтов в количество от одного до четырёх включительно. (Все символы с кодовыми точками меньше 65536 кодируются одним, двумя или тремя байтами; я не проверял, как .NET кодирует суррогатные пары: двумя последовательностями из 1-3 байтов или одной последовательностью из 4-х байтов.) UTF-8 может отображать все существующие в Юникоде символы и совместим с ASCII таким образом, что любая последовательность ASCII-символов будет перекодирована в UTF-8 без изменений (т.е. последовательность байтов, представляющая символы в ASCII, и последовательность байтов, представляющая те же символы в UTF-8, одинаковы). Более того, первого байта, кодирующего символ, хватит, чтобы определить, сколько ещё байт кодируют этот же символ, если такие вообще есть. UTF-8 сама по себе не требует метку порядка байтов (Byte order mark — BOM), хотя она может использоваться как способ индикации того, что текст представлен в формате UTF-8. Текст UTF-8, содержащий BOM, всегда начинается с последовательности трёх байтов 0xEF 0xBB 0xBF. Чтобы закодировать строку в UTF-8 в .NET, просто используйте свойство Encoding.UTF8. Вообще-то, в большинстве случаев вам не придётся делать даже это — много классов (включая StreamWriter) используют UTF-8 по умолчанию, когда явно не задана никакая другая кодировка. (Не заблуждайтесь, Encoding.Default сюда не относится, это совсем другое.) Тем не менее, я советую всегда явно указывать кодировку в вашем коде, хотя бы ради удобочитаемости и понимания.
UTF-16 и UCS-2
UTF-16 — это как раз та кодировка, в которой .NET работает с символами. Каждый символ представлен последовательностью из двух байт; соответственно суррогатная пара занимает 4 байта. Возможность использования суррогатных пар — это единственное различие между UTF-16 и UCS-2: UCS-2 (также известен просто как «Юникод») не допускает суррогатные пары и может представлять символы в диапазоне 0-65535 (0-0xFFFF). UTF-16 может иметь разный порядок байтов (Endianness): он может быть от старшего к младшему (big-endian), от младшего к старшему (little-endian), или же быть машинно-зависимым с опциональным BOM (0xFF 0xFE для little-endian, 0xFE 0xFF для big-endian). В самом .NET, насколько я знаю, на проблему суррогатных пар «забили», и каждый символ в суррогатной паре рассматривается как самостоятельный символ, что приводит своеобразной «уравниловке» между UCS-2 и UTF-16. (Точное различие между UCS-2 и UTF-16 заключается в намного более глубоком понимании суррогатных пар, и я не компетентен в этом аспекте.) UTF-16 в представлении big-endian может быть получена при помощи свойства Encoding.BigEndianUnicode, а little-endian — при помощи Encoding.Unicode. Оба свойства возвращают экземпляр класса System.Text.UnicodeEncoding, который также может быть создан при помощи различных перегрузок конструктора: здесь вы можете указать, использовать или не использовать BOM и какой порядок байт установить. Я полагаю (хотя и не тестировал этого), что при декодировании двоичного контента, BOM, присутствующий в контенте, переопределяет настройки порядка байтов, выставленные в энкодере, так что программист не должен совершать никаких лишних телодвижений, если он декодирует какой-либо контент, даже если порядок байтов и/или наличие BOM в этом контенте ему неизвестны.
UTF-7
UTF-7, судя по моему опыту, редко когда используется, но он позволяет перекодировать Юникод (вероятно, только первые 65535 символов) в ASCII-символы (не байты!). Это может пригодиться при работе с электронной почтой в ситуациях, когда почтовые шлюзы поддерживают только символы ASCII, или даже только подмножество ASCII (к примеру, кодировку EBCDIC). Моё описание выглядит невнятно, потому что я никогда не залазил в детали UTF-7 и не собираюсь этого делать впредь. Если вам необходимо использовать UTF-7, то вы, вероятно, и так знаете достаточно, а если у вас нет абсолютной необходимости использовать UTF-7, то советую не делать этого. Экземпляр класса для кодирования в UTF-7 может быть получен при помощи свойства Encoding.UTF7.
Кодовые страницы Windows/ANSI
Windows Code Pages (кодовые страницы Windows) являются, как правило, одно- или двухбайтными наборами символов, кодирующими до 256 или 65 536 символов соответственно. Каждая кодовая страница имеет свой номер, и кодировщик для кодовой страницы с известным номером можно получить при помощи статического метода Encoding.GetEncoding(Int32). В большинстве случаев кодовые страницы полезны для работы со старыми данными, которые часто хранятся в «кодовой странице по умолчанию» (default code page). Энкодер для кодовой страницы по умолчанию может быть получен при помощи свойства Encoding.Default. Снова таки, избегайте использования кодовых страниц, когда это возможно. За дополнительной информацией обращайтесь к MSDN.
ISO-8859-1 (Latin-1)
Как и в ASCII, каждый символ в кодовой странице Latin-1 имеет код, одинаковый с кодом этого же символа в Юникоде. Я не удосужился выяснить, имеет ли Latin-1 «дыру» из неучтённых символов с кодами от 128 до 159, или же Latin-1 содержит здесь те же управляющие символы, что и Юникод. (Я было начал склоняться к идее с «дырой», но Википедия со мной не согласна, поэтому я всё ещё в раздумьях. (Раздумья автора непонятны, так как в статье Википедии чётко показано наличие пробела; вероятно, на момент написания Скитом оригинальной статьи содержимое статьи в Википедии было другим. — прим. перев.)) Latin-1 имеет номер кодовой страницы 28591, поэтому чтобы получить энкодер, используйте метод Encoding.GetEncoding(28591).
Потоки, ридеры и райтеры
Потоки бинарны по своей природе, они читают и записывают байты. Всё, что принимает строку, должно её определённым образом преобразовать в байты, и это преобразование может быть как успешным для вас, так и нет. Эквивалентами потоков для чтения и записи текста служат абстрактные классы System.IO.TextReader и System.IO.TextWriter соответственно. Если у вас уже есть готовый поток, вы можете использовать классы System.IO.StreamReader (который непосредственно наследует TextReader) для чтения и System.IO.StreamWriter (который непосредственно наследует TextWriter) для записи, передавая поток в конструктор этих классов и кодируя так, как вам нужно. Если вы явно не укажете кодировку, по умолчанию будет применена UTF-8. Ниже представлен пример кода, конвертирующего файл с UTF-8 в UCS-2:
using System; using System.IO; using System.Text; public class FileConverter { const int BufferSize = 8096; public static void Main(string[] args) { if (args.Length != 2) { Console.WriteLine ("Usage: FileConverter <input file> <output file>"); return; } String inputFile = args[0]; String outputFile = args[1]; // Открыть TextReader для чтения существующего входного файла using (TextReader input = new StreamReader (new FileStream (inputFile, FileMode.Open), Encoding.UTF8)) { // Открыть TextWriter для создания и записи в новый выходной файл using (TextWriter output = new StreamWriter (new FileStream (outputFile, FileMode.Create), Encoding.Unicode)) { // Создать буфер char[] buffer = new char[BufferSize]; int len; // Копировать данные порциями до достижения конца while ( (len = input.Read (buffer, 0, BufferSize)) > 0) { output.Write (buffer, 0, len); } } } } } Отметьте, что в данном коде использованы конструкторы TextReader и TextWriter, которые принимают потоки. Существуют и другие перегрузки конструкторов, принимающие на вход пути к файлам, так что вам не нужно вручную открывать FileStream; я это сделал лишь в качестве примера. Есть и другие перегрузки конструкторов, принимающие также размер буфера и необходимость определения BOM, — в общем, гляньте документацию. И наконец, если вы используете .NET 2.0 и выше, не помешает взглянуть на статический класс System.IO.File, также содержащий множество удобных методов, позволяющих работать с кодировками.
Сложные моменты
Ладно, это были лишь основы Юникода. Есть множество других нюансов, на некоторые из которых я уже намекнул, и я считаю, что людям следует о них знать, даже если они полагают, что подобное никогда с ними не произойдёт. Я не предлагаю каких-либо общих методологий или руководящих принципов — я просто пытаюсь поднять вашу осведомленность в возможных проблемах. Ниже приведён список, и он ни скольким образом не исчерпывающий. Важно, чтобы вы поняли, что большинство описанных проблем и трудностей ни в коей мере не являются виной или ошибками Консорциума Юникода; так же, как и в случае даты, времени и любой из проблем интернационализации, это — «заслуга» человечества, которое с течением времени само создало многие принципиально сложные проблемы.
Культуро-зависимый поиск, сортировка и проч.
Эти проблемы описаны в моей статье, посвящённой строкам в .NET (оригинал, перевод).
Суррогатные пары
Теперь, когда Юникод содержит больше, чем 65536 символов, он не может вместить их все в 2 байта. Это значит, что один экземпляр структуры Char не может принимать все возможные символы. UTF-16 (и .NET) решает эту проблему путём использования суррогатных пар (surrogate pair) — это два 16-битных значения, где каждое значение лежит в диапазоне от 0xD800 и до 0xDFFF. Другими словами, два «типа символа» образуют один «настоящий» символ. (UCS-4 и UTF-32 полностью решают эту проблему тем, что у них доступен более широкий диапазон значений: каждый символ занимает 4 байта, и этого хватает всем и каждому.) Суррогатные пары — это головная боль, ведь это значит, что строка, которая состоит из 10 символов, на самом деле может содержать от 10 до 5 включительно «настоящих» символов Юникода. К счастью, большинство приложений не используют научные или математические нотации и символы Хан, а поэтому вам не нужно об этом особо волноваться.
Модифицирующие символы
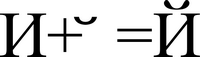
Не все символы из Юникода в результате вывода на экран или бумагу предстают в виде значка/картинки. Подчёркнутый (акцентированный) символ может быть представлен в качестве двух других символов: обычного, неподчёркнутого символа и следующего за ним символа подчёркивания, который называется модифицирующим (или комбинируемым) символом (Combining character). Некоторые графические интерфейсы поддерживают модифицирующие символы, некоторые нет, и работа вашего приложения будет зависеть от того, какое предположение вы сделаете.
Нормализация
Частично из-за таких вещей, как модифицирующие символы, может быть несколько способов представления того, что в некотором смысле является одним символом. Литера «á» с ударением, к примеру, может быть представлена одним символом «а» без ударения и следующим за ним модифицирующим символом ударения, а может быть представлена только одним символом, представляющим готовую литеру «а» с ударением. Последовательности символов могут быть нормализованы таким образом, чтобы использовать модифицирующие символы везде, где это возможно, или же наоборот — не использовать их везде, где их можно заменить одиночным символом. Должно ли ваше приложение рассматривать две строки, содержащие литеру «á» с ударением, но в одной представленную двумя символами, а во второй одним, как равные, или как разные? А что насчёт сортировки? Производят ли сторонние компоненты и библиотеки, используемые вами, нормализацию строк, и вообще, учитывают ли подобные нюансы? На эти вопросы отвечать вам.
Отладка проблем с Юникодом
Этот раздел (в оригинале это отдельная статья – прим. пер.) описывает, что делать в очень специфических ситуациях. А именно, у вас есть некоторые символьные данные (попросту — текст) в одном месте (как правило, в базе данных), которые проходят через разные шаги/слои/компоненты и затем выводятся пользователю (как правило, на веб-странице). И, к сожалению для вас, некоторые символы отображены неверно (крякозябры). Исходя из множества шагов-этапов, по которым проходят ваши текстовые данные, проблема может возникать во многих местах. Это страница поможет вам просто и надёжно узнать, что и где «сломалось».
Шаг 1: поймите основы Юникода
А попросту говоря — прочтите основной текст статьи. Можете также обратить внимание на ссылки, которые приведены в начале статьи. Факт в том, что без базовых знаний вам будет туговато.
Шаг 2: попытайтесь определить, какие конвертации могли произойти
Если вы можете понять, где, возможно, всё ломается, то этот участок/этап намного проще будет изолировать. Вместе с тем имейте в виду, что проблема может быть не в процессе извлечения и преобразования текста из хранилища, а в том, что уже «испорченный» текст был занесён в хранилище ранее. (С подобными проблемами я стыкался в прошлом, когда, к примеру, одно старое приложение искажало текст при записи и считывании его в/из БД. «Прикол» был в том, что ошибки конвертации накладывались друг на друга и взаимокомпенсировались, так что на выходе получался корректный текст. Вообще приложение работало нормально, но стоило его тронуть — и всё рассыпалось.) К действиям, которые могут «портить» текст, следует относить выборку из БД, чтение из файла, передачу через веб-соединение и выведение текста на экран.
Шаг 3: проверяйте данные на каждом этапе
Первое правило: не доверяйте ничему, что логирует символьные данные в виде последовательности глифов (т.е. стандартных значков символов). Вместо этого вы должны логировать данные как набор кодов символов в виде байтов. Например, если я имею строку, содержащую слово «hello», то я её отображу как «0068 0065 006C 006C 006F». (Использование шестнадцатеричных кодов позволит вам легко проверить символ по кодовым таблицам.) Чтобы это сделать, надо пройтись по всем символам в строке и для каждого символа вывести его код, что и делается в нижеприведённом методе, который отображает результат в консоль:
static void DumpString (string value) { foreach (char c in value) { Console.Write("{0:x4} ", (int)c); } Console.WriteLine(); } Ваш собственный метод логирования будет иным в зависимости от вашего окружения, но основа его должна быть именно такой, как я привёл. Более продвинутый способ отладки и логирования символьных данных я привёл в своей статье, посвящённой строкам.
Суть моей идеи в том, чтобы избавиться от всевозможных проблем с кодировками, шрифтами и т.д. Эта методика может быть полезна при работе со специфичными символами Юникода. Если же вы не можете корректно логировать шестнадцатеричные коды даже простого ASCII-текста — у вас большие проблемы.
Следующий этап — убедитесь, что у вас есть тест-кейс, который можно использовать. Найдите желательно небольшой набор исходных данных, на котором ваше приложение гарантированно «сбоит», удостоверьтесь, что вы точно знаете, каким должен быть правильный результат, и залогируйте получившийся результат во всех проблемных местах.
После того, как проблемная строка залогирована, надо удостовериться, является ли она такой, какой должна быть, или нет. В этом вам поможет веб-страница Unicode code charts. Вы можете выбрать как набор символов, в котором уверены, так и искать символы в алфавитном порядке. Убедитесь, что каждый символ в строке имеет правильное значение. Как только вы найдёте то место в вашем приложении, где поток символьных данных поврежден, исследуйте это место, выясните причину ошибки и исправьте её. Исправив все ошибки, убедитесь, что приложение работает корректно.
Заключение
Как и в случае с подавляющим большинством ошибок, возникающих в разработке ПО, проблемы с текстом решаются при помощи универсальной стратегии «разделяй и властвуй». Как только вы будете уверены в каждом шаге, вы сможете быть уверенными в целом. Если во время исправления подобных ошибок вы столкнётесь с особенно непонятными и странными их проявлениями, я настоятельно советую после их исправления покрыть данный участок кода юнит-тестами; они будут служить и документацией, показывающей, что может случиться, и защитой от будущих регрессий.
Источники
- Jon Skeet. Unicode and .NET
- Jon Skeet. Debugging Unicode Problems
ссылка на оригинал статьи http://habrahabr.ru/post/193048/
Добавить комментарий