 Тех, кто использует или собирается использовать Zabbix в промышленных масштабах, всегда волновал вопрос: сколько реально данных сможет Заббикс «переварить» перед тем как окончательно поперхнется и подавится? Часть моей недавней работы как раз касалось этого вопроса. Дело в том, что у меня есть огромная сеть, насчитывающая более 32000 узлов, и которая потенциально может полностью мониториться Заббиксом в будущем. На форуме давно идут обсуждения о том, как оптимизировать Zabbix для работы в больших масштабах, но, к сожалению, мне так и не удалось найти законченное решение.
Тех, кто использует или собирается использовать Zabbix в промышленных масштабах, всегда волновал вопрос: сколько реально данных сможет Заббикс «переварить» перед тем как окончательно поперхнется и подавится? Часть моей недавней работы как раз касалось этого вопроса. Дело в том, что у меня есть огромная сеть, насчитывающая более 32000 узлов, и которая потенциально может полностью мониториться Заббиксом в будущем. На форуме давно идут обсуждения о том, как оптимизировать Zabbix для работы в больших масштабах, но, к сожалению, мне так и не удалось найти законченное решение.
В этой статье я хочу показать, как я настраивал свою систему, способную обрабатывать реально много данных. Чтобы вы понимали, о чем речь, вот просто картинка со статистикой системы:
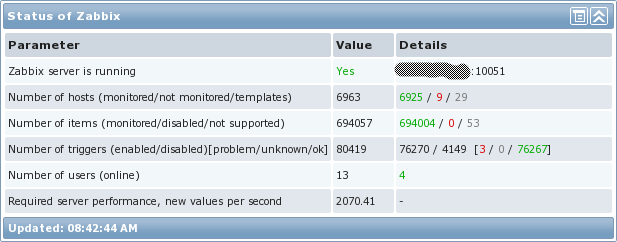
Для начала хочется обговорить, что реально означает пункт «Required server performance, new values per second (далее NVPS) (Требуемое быстродействие в секунду)». Так вот, он не соответствует тому, сколько реально данных попадает в систему в секунду, а является простым математических подсчетом всех активных элементов данных с учетом интервалов опроса. И тогда получается, что Zabbix-trapper в расчете не участвует. В нашей сети trapper использовался достаточно активно, так что давайте посмотрим, сколько реально NVPS в рассматриваемом окружении:
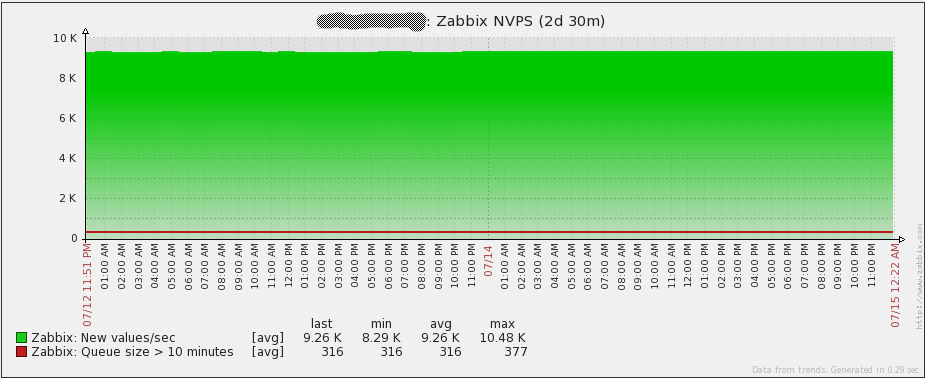
Как показано на графике, в среднем Zabbix обрабатывает около 9260 запросов в секунду. Кроме того, в сети бывали и короткие всплески до 15000 NVPS, с которыми сервер без проблем справился. Честно говоря, это здорово!
Архитектура
Первое, в чем стоит разобраться это архитектура системы мониторинга. Должен ли Zabbix быть отказоустойчивым? Будут ли иметь значение один-два часа простоя? Какие последствия ждут, если упадет база данных? Какие потребуются диски для базы, и какой настраивать RAID? Какая нужна пропускная способность между Zabbix-сервером и Zabbix-proxy? Какая максимальная задержка? Как собирать данные? Опрашивать сеть (пассивный мониторинг) или слушать сеть (активный мониторинг)?
Давайте рассмотрим каждый вопрос детально. Если быть честным, то вопрос сети я не рассматривал при разворачивании системы, что привело к проблемам, которые в дальнейшем было трудно продиагностировать. Итак, вот общая схема архитектуры системы мониторинга:

Железо
Точно подобрать правильное железо процесс не из легких. Главное что я здесь сделал, это использовал SAN для хранения данных, так как база Заббикса требует много I/O дисковой системы. Проще говоря, чем быстрее диски у сервера БД, тем больше данных сможет обработать Заббикс.
Конечно, ЦПУ и память тоже очень важны для MySQL. Большое количество ОЗУ позволяет Заббиксу хранить часто читаемые данные в памяти, что естественно способствует быстродействию системы. Изначально я планировал для сервера БД 64ГБ памяти, однако все замечательно работает и на 32ГБ до сих пор.
Сервера, на которых стоит сам zabbix_server, тоже должен иметь достаточно быстрые ЦПУ, так как необходимо, чтобы он спокойно обрабатывал сотни тысяч триггеров. Памяти же хватило бы и 12ГБ — так как на самом Заббикс сервере не так много процессов (практически весь мониторинг идет через прокси).
В отличии от СУБД и zabbix_server, Zabbix-прокси не требуют серьезного железа, поэтому я использовал «виртуалки». В основном собираются активные элементы данных, так что прокси служат как точки сбора данных, сами же практически ничего не опрашивают.
Вот сводная таблица, что я использовал в своей системе:
| Zabbix server | Zabbix БД | Zabbix proxies | SAN |
|---|---|---|---|
| HP ProLiant BL460c Gen8 12x Intel Xeon E5-2630 16GB memory 128GB disk CentOS 6.2 x64 Zabbix 2.0.6 |
HP ProLiant BL460c Gen8 12x Intel Xeon E5-2630 32GB memory 2TB SAN-backed storage (4Gbps FC) CentOS 6.2 x64 MySQL 5.6.12 |
VMware Virtual Machine 4x vCPU 8GB memory 50GB disk CentOS 6.2 x64 Zabbix 2.0.6 MySQL 5.5.18 |
Hitachi Unified Storage VM 2x 2TB LUN Tiered storage (with 2TB SSD) |
Отказоустойчивость Zabbix server
Вернемся к архитектурным вопросам, что я озвучивал выше. В больших сетях по понятным причинам не работающий мониторинг является настоящей катастрофой. Однако, архитектура Заббикса не позволяет запускать больше одного экземпляра процесса zabbix server.
Поэтому я решил воспользоваться Linux HA с Pacemaker и CMAN. Для базовой настройки прошу глянуть мануал RedHat 6.4. К сожалению, инструкция была изменена с момента, как я ее использовал, однако конечный результат должен получиться таким же. После базовой настройки дополнительно я настроил:
- Общий IP-адрес (shared IP address)
- В случае фейловера, IP-адрес переходит на сервер, который становится активным
- Так как общий IP-адрес всегда используется активным Zabbix-сервером, то отсюда следует три преимущества:
- Всегда легко найти какой сервер активен
- Все соединения от Zabbix сервера всегда с одного и того же IP (После установки параметра SourceIP= в zabbix_server.conf)
- Всем Zabbix-прокси и Zabbix-агентам в качестве сервера просто указывается общий IP
- Процесс zabbix_server
- в случае фейловера zabbix_server будет остановлен на старом сервере и запущен на новом
- Symlink для заданий cron
- Симлинк указывает на директорию, в которой лежат задания, которые должны выполняться только на активном Zabbix-сервере. Crontab должен иметь доступ ко всем задания через этот симлинк
- В случае фейловера симлинк удаляется на старом сервере и создается на новом
- crond
- В случае фейловера crond останавливается на старом сервере и запускается на новом активном сервере
Пример конфигурационного файла, а также LSB init-скрипт для zabbix-сервера можно скачать здесь. Не забудьте отредактировать параметры, заключенные в "< >". Кроме того, init-скрипт написан с учетом того, что все файлы Zabbix’а находятся в одной папке (/usr/local/zabbix). Так что поправьте пути в скрипте, если нужно.
Отказоустойчивость СУБД
Очевидно, что никакой пользы от отказоустойчивости серверов с Zabbix-серверами, если база данных может упасть в любой момент. Для MySQL есть огромное количество путей создать кластер, я расскажу о способе, что я использовал.
Я также использовал Linux HA с Pacemaker и CMAN и для базы данных. Как оказалось, в нем есть пару отличный возможностей для управления репликацией MySQL. Я использую (использовал, смотри раздел «открытые проблемы») репликацию для синхронизации данных между активным(master) и резервным(slave) MySQL. Для начала, точно также как и для серверов Zabbix-сервера, мы делаем базовую настройку кластера. Затем в дополнении я настроил:
- Общий IP-адрес (shared IP address)
- В случае фейловера, IP-адрес переходит на сервер, который становится активным
- Так как общий IP-адрес всегда используется активным Zabbix-сервером, то отсюда следует два преимущества:
- Всегда легко найти, какой сервер активен
- В случае фейловера, на самом Zabbix-сервере не требуется никаких действий, чтобы указать адрес нового активного сервера MySQL
- Общий дополнительный (slave) IP-адрес
- Этот IP-адрес может использоваться, когда к происходит запрос на чтение к базе. Таким образом, запрос может обработать slave-сервер MySQL, если он доступен
- дополнительный адрес может быть у любого из серверов, это зависит от следующего:
- если slave-сервер доступен, и часы не отстают на более чем 60 секунд, то адрес будет у него
- В обратном случае адрес будет у master-сервера MySQL
- mysqld
- В случае фейловера новый сервер MySQL станет активным. Если после этого старый сервер вернется в строй, то он останется slave для уже новоиспечённого master.
Пример конфигурационного файла можно взять здесь. Не забудьте отредактировать параметры pacemaker, заключенные в "< >". Также, возможно, потребуется скачать другого MySQL resource agent для использования с pacemaker. Ссылку можно найти в документации по установке MySQL кластера с pacemaker в Percona репозитории github. Также на всякий «пожарный случай» копия лежит тут.
Zabbix-прокси
Если по какой-то причине вы не слышали о Zabbix-прокси, то, пожалуйста, срочно посмотрите в документации. Прокси позволяют Заббиксу распределить нагрузку мониторинга на несколько машин. После этого уже каждый Заббикс прокси отсылает все собранные данные на Заббикс сервер.
Работая с Заббикс прокси важно помнить:
- Заббикс прокси способны обрабатывать очень серьезные объемы данных, если их настроить как следует. Так, например, во время тестов, прокси (назовем ее Proxy А) обрабатывала 1500-1750 NVPS без каких либо проблем. И это виртуалка с двумя виртуальными ЦПУ, 4ГБ ОЗУ и БД SQLite3. При этом прокси находилась на одной площадки с самим сервером, так что задержки на сети можно было просто не учитывать. Также почти все, что собиралась, было активными элементами данных Заббикс агента
- Ранее я уже упоминал, как важна задержка на сети при мониторинге. Так вот, это действительно так, когда речь идет о крупных системах. Фактически, количество данных, которое может отослать прокси, не отставая, напрямую зависит от сети.
На графике ниже хорошо видно как накапливаются проблемы, когда задержка сети не учитывается. Прокси, который не успевает:
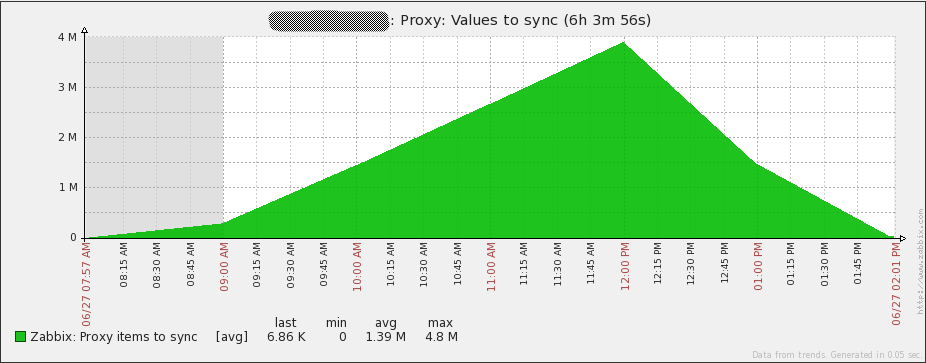
Пожалуй, достаточно очевидно, что очередь из данных для передачи не должна увеличиваться. График относится к другому Заббикс-прокси (Proxy B), которая ничем по железу не отличается от Proxy A, но может передавать без проблем только 500NVPS а не 1500NVPS, как Proxy A. Отличие как раз в том, что B находится в Сингапуре а сам сервер в Северной Америке, и задержка между площадками порядка 230мс. Данная задержка имеет серьезный эффект, учитывая способ пересылки данных. В нашем случае, Proxy B может отправить только по 1000 собранных элементов Заббикс серверу каждые 2-3 секунды. По моим наблюдениям, вот что происходит:
- Прокси устанавливает соединение до сервера
- Прокси максимум отправляет за раз 1000 собранных значений элементов данных
- Прокси закрывает соединение
Данная процедура повторяет столько раз, сколько требуется. В случае большой задержки, такой метод имеет несколько серьезных проблем:
- Первичное подключение очень медленное. В моем случае оно происходит за 0,25 секунды. Уф!
- Так как соединение закрывается после отправки 1000 элементов данных, то TCP-соединение никогда не длится достаточно долго, чтобы успеть использовать всю доступную пропускную способность канала.
Производительность базы данных
Высокая производительность базы данных является ключевой для системы мониторинга, так как абсолютно вся собранная информация попадает туда. При этом, с учетом большого количества операций записи в базу, производительность дисков — это первое бутылочное горлышко с которым сталкиваешься. Мне повезло и у меня в распоряжении оказались SSD-диски, однако все равно это не является гарантией быстрой работы базы. Вот пример:
- Изначально в системе я использовал MySQL 5.5.18. Сначала никаких видимых проблем с производительностью не наблюдалось, однако, после 700-750 NVPS MySQL стал загружать процессор на 100% и система буквально «замерла». Дальнейшие мои попытки исправить ситуацию, подкручивая параметры в конфигурационном файле, активируя large pages или partitioning ни к чему не привели. Более хорошее решение предложила моя жена: сначала обновиться MySQL до 5.6 и потом разбираться. На мое удивление, простой апдейт решил все проблемы с производительностью, который я никак победить в 5.5.18. На всякий случай, вот копия my.cnf.
На графике показано количество запросов в секунду в базе:
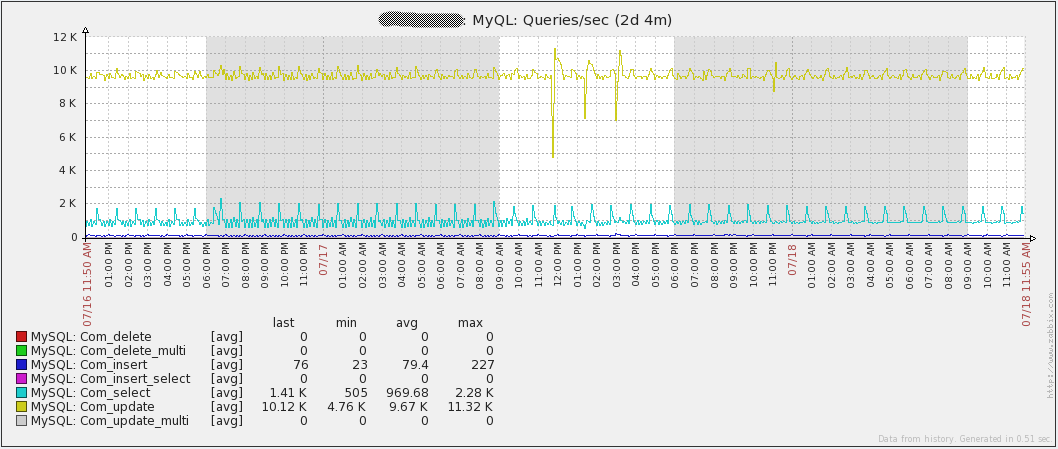
Обратите внимание, что больше всего запросов «Com_update». Причина кроется в том, что каждое полученное значение влечет Update в таблицу «items». Также в базе данных в основном операции на запись, так что MySQL query cache никак не поможет. По сути, он может быть даже вредным для производительности, учитывая, что постоянно придется маркировать запросы как неверные.
Другой проблемой для производительности может стать Zabbix Housekeeper. В больших сетях его настоятельно рекомендую отключать. Для этого в конфиг-файле выставите DisableHousekeeping=1. Понятно, что без Housekeeping старые данные(элементы данных, события, действия) не будут удаляться из базы. Тогда удаление можно организовать через partitioning.
Однако, одно из ограничений MySQL 5.6.12 в том, что partitioning не может быть использован в таблицах с foreign keys и как раз они присутствуют почти повсеместно в базе Заббикс. Но кроме таблиц history, которые нам и нужны. Partitioning дает нам два преимущества:
- Все исторические данные таблицы разбитые по днем/неделям/месяцам/и т.д. могут находиться в отдельных файлах, что позволяет в дальнейшем удалять данные без каких либо последствий для базы. Также очень просто понимать сколько данных собирается за определенный период времени.
- После очистки таблиц InnoDB не возвращает место диску, оставляя его себе для новых данных. В итоге с InnoDB невозможно очистить место на диске. В случае с partitioning это не проблема, место может быть освобождено, простым удалением старых партиций.
О partitioning в Заббикс уже писалось на Хабре.
Собирать или слушать
В Заббиксе существует два метода сбора данных: активный и пассивный: В случае пассивного мониторинга Заббикс сервер сам опрашивает Заббикс агентов, а в случае активного — ждет когда Zabbix-агенты сами подключаться к серверу. Под активный мониторинг также попадает Zabbix trapper, так как инициация отсылки остается на стороне узла сети.
Разница в производительности может быть серьезной при выборе одного или другого способа как основного. Пассивный мониторинг требует запущенных процессов на Заббикс сервере, которые будут регулярно посылать запрос к Заббикс агенту и ждать ответа, в некоторых случаях ожидание может затянуться даже до нескольких секунд. Теперь умножьте это время хотя бы на тысячу серверов, и становится ясно, что «поллинг» может занять время.
В случае активного мониторинга процессов опроса нет, сервер находится в состоянии ожидания, когда агенты сами начнут подключаться к Zabbix-серверу, чтобы получить список элементов данных, которые требуется мониторить.
Далее, агент начнет сам собирать элементы данных с учетом полученного с сервера интервала и отправлять их, при этом соединение будет открыто только тогда, когда агенту есть что отправить. Таким образом, отпадает необходимость в проверке до получения данных, которая присутствует при пассивном мониторинге. Вывод: активный мониторинг увеличивает скорость сбора данных, что и требуется в нашей большой сети.
Мониторинг самого Заббикса
Без мониторинга самого Zabbix эффективная работа большой системы просто не представляется возможной — критически важно понимать в каком месте произойдет «затык», когда система откажется принимать новые данные. Существующие элементы данных для мониторинга Заббикса могут быть найдены тут. В версиях 2.х Заббикса они были любезно собраны в шаблон для мониторинга Zabbix server, предоставляемый «из коробки». Пользуйтесь!
Одной полезной метрикой является свободное место в History Write Cache (HistoryCacheSize в в конфиг-файле сервера). Данный параметр должен всегда быть близок к 100%. Если же кэш переполняется — это означает, что Zabbix не успевает добавлять в базу поступающие данные.
К сожалению, подобный параметр не поддерживается Zabbix-прокси. Кроме того, в Zabbix, отсутствует элемент данных, указывающий, сколько данных ожидает отправки на Zabbix-сервер. Впрочем, этот элемент данных легко сделать самому через SQL-запрос к базе прокси:
SELECT ((SELECT MAX(proxy_history.id) FROM proxy_history)-nextid) FROM ids WHERE field_name='history_lastid'
Запрос вернет необходимо число. Если у вас стоит SQLite3 в качестве БД для Zabbix-прокси, то просто добавьте следующую команду как UserParameter в конфиг-файле Zabbix-агента, установленного на машине, где крутится Zabbix-прокси.
UserParameter=zabbix.proxy.items.sync.remaining,/usr/bin/sqlite3 /path/to/the/sqlite/database "SELECT ((SELECT MAX(proxy_history.id) FROM proxy_history)-nextid) FROM ids WHERE field_name='history_lastid'" 2>&1
Далее просто ставите триггер, который будет оповещать о том, что прокси не справляется:
{Hostname:zabbix.proxy.items.sync.remaining.min(10m)}>100000
Итого статистика
Напоследок предлагаю графики загрузки системы. Сразу говорю, что не знаю, что произошло 16 июля — мне пришлось пересоздать все базы прокси (SQLite на тот момент), чтобы решить проблему. С тех пор я перевел все прокси на MySQL и проблема не повторялась. Остальные «неровности» графиков совпадают со временем проведения нагрузочного тестирования. В целом, из графиков видно, что у используемого железа большой запас прочности.
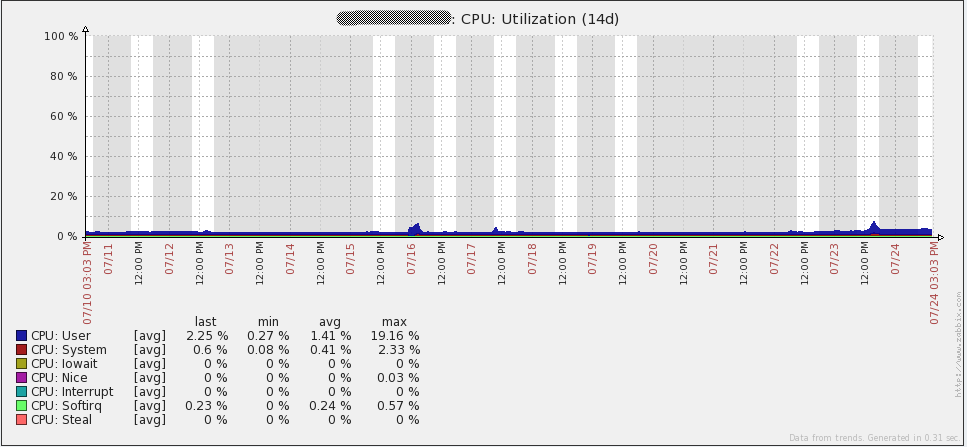
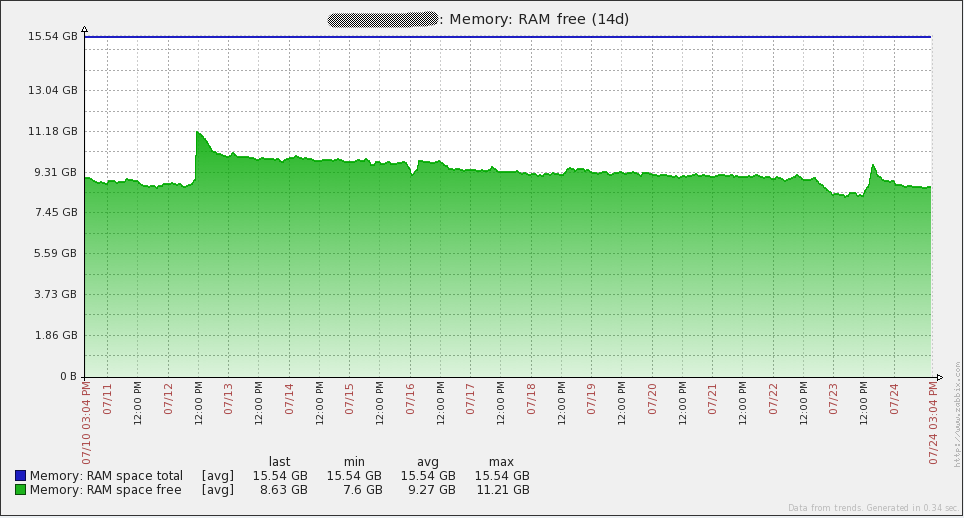

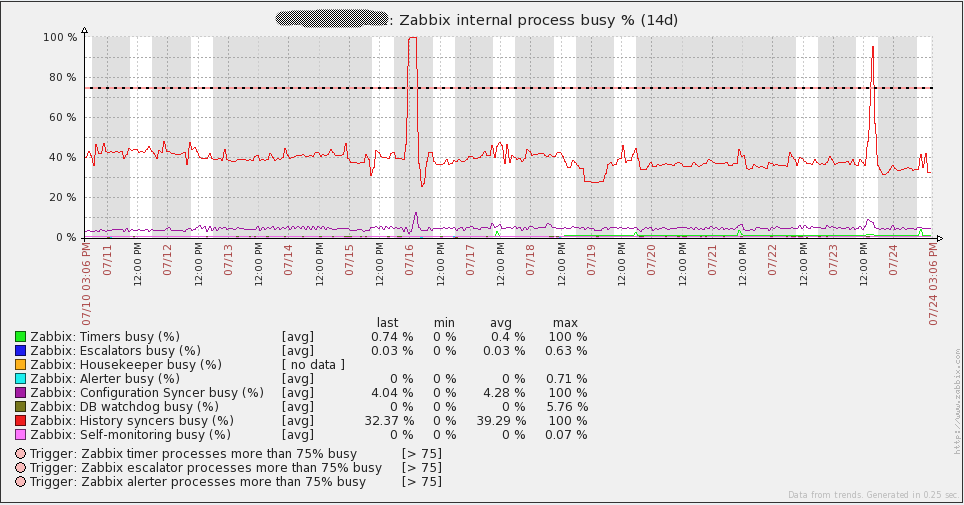
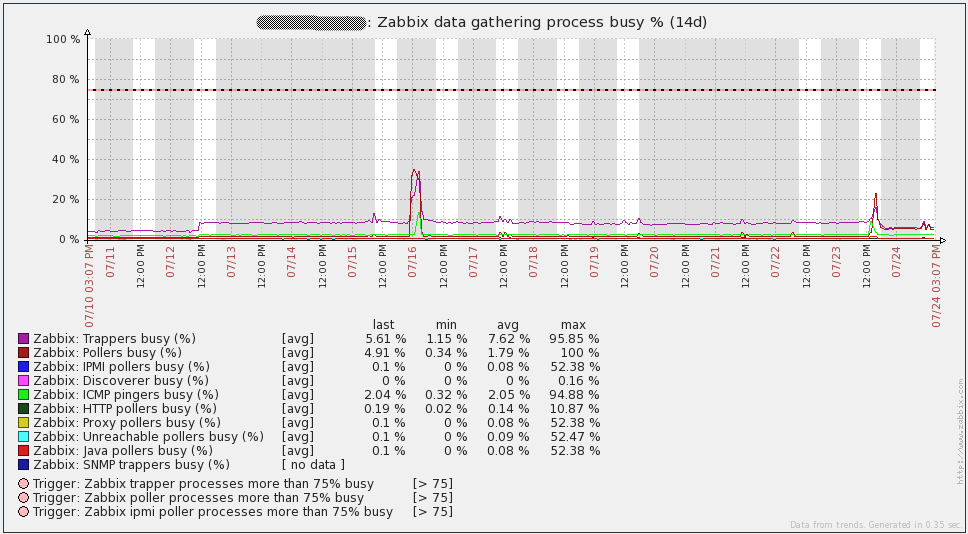
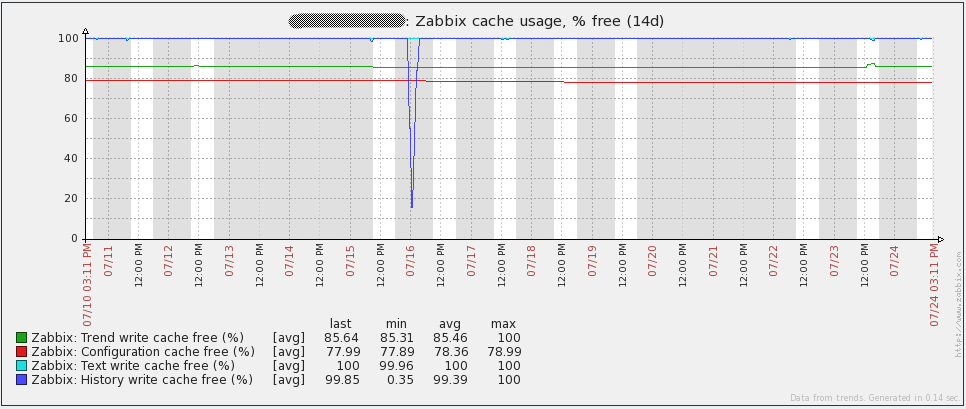
А вот графики с сервера базы данных. Приросты трафика каждый день соответствуют времени снятия дампа(mysqldump). Также провал 16 июля на графике запросов(qps) относится к той же проблеме, что я описывал выше.


Управление
Итого в системе используется 2 сервера под Zabbix-сервера, 2 сервера под MySQL, 16 виртуальных серверов под Zabbix-прокси и тысячи наблюдаемых серверов с Zabbix-агентами. При таком количестве хостов о внесении изменений руками не могло быть и речи. И решением стал Git-репозиторий, к которому имеют доступ все сервера, и где я расположил все конфигурационные файлы, скрипты, и все остальное, что нужно распространять. Далее, я написал скрипт, который вызывается через UserParameter в агенте. После запуска скрипта сервер подключается к Git-репозиторию, скачивает все необходимые файлы и обновления и затем перезагружает Zabbix-агента/прокси/сервера, если конфиг-файлы имели изменения. Обновление стало не сложнее, чем запустить zabbix_get!
Создание новых узлов сети вручную через веб-интерфейс тоже не наш метод, при таком количестве серверов. В нашей компании есть CMDB, которая содержит информацию о всех серверах и сервисах, которые они предоставляет. Поэтому другой волшебный скрипт каждый час собирает информацию из CMDB и сравнивает с тем, что есть в Zabbix. На выводах этого сравнения скрипт удаляет/добавляет/включает/выключает хосты, создает хост группы, добавляет хостам шаблоны. Все что остается делать вручную в таком случае это имплементация нового типа триггера или элемента данных. К сожалению, скрипты эти сильно завязаны на наши системы, поэтому я не могу ими поделиться.
Открытые проблемы
Несмотря на все усилия, которые я приложил, осталась одна существенная проблема, которую мне только предстоит решить. Речь о том, что когда система достигает 8000-9000NVPS, то резервная база MySQL больше не успевает за основной, таким образом никакой отказоустойчивости на самом деле и нет.
У меня есть идеи, как данную проблему можно решить, но еще не было времени это имплементировать:
- Использовать Linux-HA с DRBD для partitioning БД.
- LUN-репликация на SAN с репликацией на другой LUN
- Percona XtraDB cluster. В версии 5.6 еще недоступен, так что с этим придется подождать( как я писал, были проблемы с производительностью в MySQL 5.5)
Ссылки
- Zip file with all downloads from the article
- Large environment forum thread
- Zabbix server configuration documentation
- Zabbix proxy distributed monitoring documentation
- Zabbix active/passive item documentation
- Zabbix internal item documentation
- Zabbix blogpost on internal items
- Pacemaker/CMAN quickstart guide
- MySQL Pacemaker configuration guide
- MySQL Large Pages
- Partitioning the Zabbix database
ссылка на оригинал статьи http://habrahabr.ru/company/zabbix/blog/193472/
Добавить комментарий