Итак, вернемся к нашему проекту. Предметная область базы данных — учет личных финансов. Диаграмма базы данных приведена на рисунке.
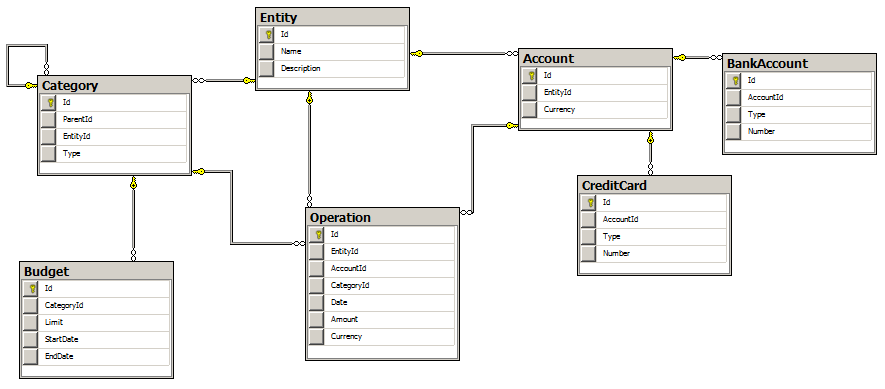
Как мы видим база данных достаточно простая. Каждый объект системы представляет собой сущность с базовыми свойствами (Id, Name, Description). Конкретными сущностями являются Аккаунт (наследуемые от него: Банковский счет, Кредитная карточка), Категория трат (наследуемые от нее: Бюджет, а также дочерние категории) и Операции по счетам.
Кроме таблиц база данных содержит некоторую логику по добавлению сущностей в базу (оформлена в виде stored procedures), а также парочка View, для отображения результатов типовых запросов к базе.
Исходный текст SQL скрипта по созданию базы данных, может быть найден здесь.
Понятно, что в реальном проекте количество артефактов в базе данных может быть на порядок больше, однако миграция даже такой небольшой базы данных может показать основные грабли, с которыми можно столкнуться при использовании SQL Azure Federations.
Анализ
Прежде чем бросаться мигрировать базу данных для использования SQL Azure Federations, необходимо определить, какие данные в базе являются логически независимыми. Данные какого типа можно распределить по разным базам данных. По сути, необходимо выбрать таблицу, данные которой будут разбиты на несколько баз данных, так называемую federated table.
Если мы посмотрим на структуру базы данных, то первым кандидатом на ум приходит базовая таблица сущностей (Entity). Скрипт создания этой таблицы выглядит следующим образом:
CREATE TABLE Entity (
[Id] INTEGER NOT NULL PRIMARY KEY IDENTITY(1,1),
[Name] NVARCHAR(MAX) NOT NULL,
[Description] NVARCHAR(MAX) NOT NULL,
)
На первый взгляд эта таблица идеально подходит для разбиения. Однако это не так. Да, она не содержит внешних ключей, имеет достаточно простую структуру, а количество записей, хранящихся в ней, максимально. Однако, согласно логике базы данных с этой таблицей связаны данные «таблиц-наследников». То есть все сущности, созданные в системе имеют запись в таблице сущностей.
Рассмотрим такой пример. Предположим мы разобьем данные по диапазону идентификаторов (полеID) сущностей. Допустим записи с ID 1-50 хранятся в первом шарде, 51-100 — во втором и т. д.
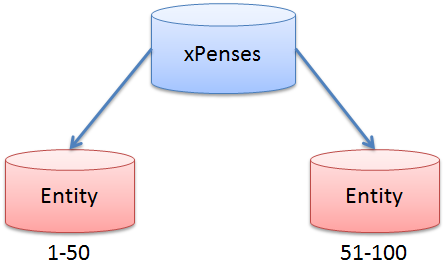
Пользователь пытается добавить в таблицу операций (Operations) новую запись. Пусть это будут данные о покупке пакета молока. ID сущности аккаунта предположим равно 1, ID категории расходов — 6. Также предположим, что 50 записей в первой базе данных уже есть, а значит новая запись должна получить идентификатор равный 51, то есть попасть во второй шард.
Запрос на добавление новых данных в таблицу будет выглядеть следующим образом:
USE FEDERATION Entities(EntityId = 51) WITH RESET, FILTERING = OFF
GO
INSERT INTO Operation VALUES (
51, -- EntityId
1, -- AccountId
6, -- CategoryId
GETDATE(), -- Date
10, -- Amount
'USD' -- Currency
)
Запрос выполнится абсолютно корректно. Давайте попробуем теперь получить список всех операций для этого аккаунта (ID = 1). В базе данных для этого есть соответствующее view. Его код выглядит следующим образом:
SELECT
Account_Entity.Description AS 'Account',
Operation_Entity.Name AS 'Operation',
Operation_Entity.Description,
Operation.Amount,
Operation.Currency,
Operation.Date
FROM
Operation
INNER JOIN Entity AS Operation_Entity ON Operation.EntityId = Operation_Entity.Id
INNER JOIN Account ON Operation.AccountId = Account.Id
INNER JOIN Entity AS Account_Entity ON Account.EntityId = Account_Entity.Id
INNER JOIN Category ON Operation.CategoryId = Category.Id
INNER JOIN Entity AS Category_Entity ON Category.EntityId = Category_Entity.Id
WHERE
Account.Id = 1
Как мы помним данные одного аккаунта у нас хранятся на разных шардах. Поэтому чтобы этот запрос вернул корректные результаты его необходимо выполнить на каждом шарде отдельно.
USE FEDERATION Entities(EntityId = 1) WITH RESET, FILTERING = OFF
GO
...
USE FEDERATION Entities(EntityId = 51) WITH RESET, FILTERING = OFF
GO
...
Я думаю не нужно объяснять, какой огромный удар будет нанесен производительности приложения от такого подхода. Если даже простейший запрос теперь необходимо выполнить дважды! Очевидно, что таблица сущностей (Entity) нам не подходит.
Если вспомнить про multi-tenant подход к проектированию баз данных, когда каждый пользователь работает со своей базой и их данные не пересекаются, то возникает вопрос. А можно ли что-то подобное реализовать в рамках SQL Azure Federations? Где каждый шард будет содержать данные одного пользователя (Account). Действительно такой подход будет достаточно логичным. С точки зрения бизнес логики это выглядело бы так:
Допустим одной программой пользуются несколько членов семьи. Каждый из них ведет бюджет отдельно. Также допустим муж ведет свою бухгалтерию, жена — свою. Таким образом данные мужа (AccountId = 1) никак не пересекаются с данными жены (AccountId = 2). В таком случае разбиение на шарды по таблице аккаунтов выглядит вполне логичным.
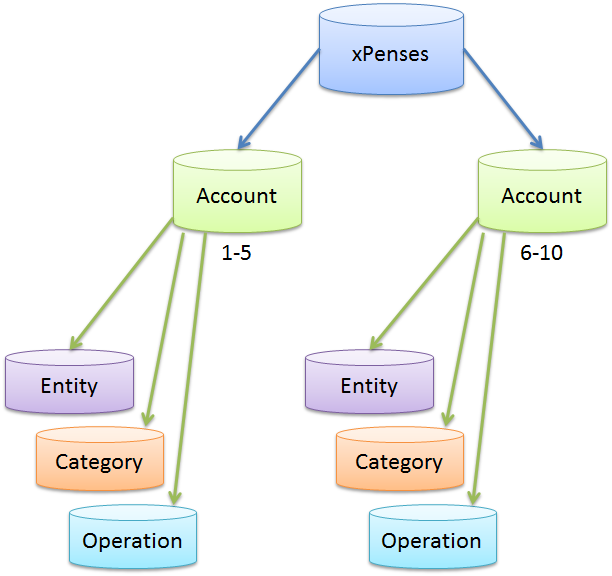
Добавление нового аккаунта будет соответствовать добавлению шарда. Частые операции, такие как: работа со списком категорий, операций и т. д. не будут приводить к падению производительности.
USE FEDERATION Accounts(AccountId = 1) WITH RESET, FILTERING = OFF
GO
После выполнения такого запроса сразу понятно с данными какого пользователя мы в данный момент работаем. А значит та же самая операция просмотра списка операций будет выполняться только один раз.
Итак, мы рассмотрели два варианта разбиение существующей базы данных. Теперь мы определились по какому полю мы будем логически разделять данные по разным базам. В следующий раз мы непосредственно разнесем данные на разные шарды. Не переключайтесь! Всем удачного начала новой рабочей недели. Спасибо за внимание!
ссылка на оригинал статьи http://habrahabr.ru/company/epam_systems/blog/193874/
Добавить комментарий