
Понадобилось как-то выудить информацию из Интернета. Нашёл подходящий сайт, посмотрел на устройство страниц. Оказалось, что скрыто многое от ока всё скачивающего wget. Не помогла и стандартная сборка HTTrack. Хотел было паука для Scrapy написать, но не пришло ощущение надёжности и масштабируемости. Стал думу думать, да и велосипед изобретать, точнее свой web crawler писать.
Находил в Интернете разные статьи по разработке инструментов для скачивания сайтов, но не приглянулись из-за ограниченности своей, которая допустима лишь для примеров, но не для задач реальных. Приведу лишь два основных. Во-первых, заранее необходимо предусмотреть разбор всех типов страниц. Во-вторых, почти всегда информация выгружается за один раз, а при ошибке просто всё вновь запускается.
Про свои предыдущие поделки на время забыл, в сторону отложил, а всё сосредоточение направил на архитектуру, статью о которой не срамно и на Хабре будет выложить.
Упрощения ради повествования было имя выбрано «ИнКр» (InCr), что является сокращением от Intellectual Crawler, а также является началом слова Incredible (невероятный).
ИнКр должен представлять собой платформу, которая сама реализует базовые функции по управлению заданиями, скачиванию и хранению документов. Со стороны же разработчика требуется написание парсеров для конкретного сайта. В ходе анализа были сформулированы следующие основные требования:
1. Возможность гибкой настройки загрузки: ограничение количества потоков, приостановка обработки для аутентификации, распознаванию captcha и т.п.;
2. Независимость загрузки страниц и их разбора, возможность повторного разбора ранее скаченных страниц;
3. Поддержка процесса разработки парсера: отдельно отмечаются все документы, которые не смогли быть полностью разобраны;
4. Возможность дополнения данных, полученных на основе информации нескольких страниц;
5. Продолжение процесса загрузки страниц после остановки;
6. Корректная обработка изменений;
7. Одновременная работа сразу с несколькими сайтами и наборами правил.
В качестве задачи рассмотрим скачивание и разбор информации с форума. Для определённости пусть это будет форум phpBB www.phpbb.com/community/. Интересуют пользователи, форумы, темы и сообщения. Должна быть предусмотрена загрузка новых сообщений и тем, а также авторизация для отображения скрытых разделов. Непосредственно сам разбор не представляет трудностей, но при реализации загрузки нового сайта этим и должны ограничиваться усилия разработчика.
Может быть сейчас думаете, что занимаюсь бессмысленным делом, поскольку уже существуют подобные решения и статьи. Благодарен буду, если в комментариях или личном сообщении дадите о них знать.
Далее в статье опишу предлагаемую архитектуру ИнКра, а также пути реализации. Если не найдётся готового решения, то в следующей статье уже приведу саму реализацию с учётом ваших комментариев.
В ИнКре выделим следующие основные модули (функциональные блоки):
1. Подготовка (Initialization, I): отвечает за аутентификацию, получение cookies, распознаванию captcha, кэшированию записей DNS и т.д.;
2. Загрузка (Download, D): выполняет загрузку определённой страницы;
3. Проверка (Check, C): проверка корректности загрузки, например, на размер страницы, timeout, ошибку 404 и т.п.;
4. Разбор (Parse, P): разбор страницы согласно правилам;
5. Извлечение (Extraction, E): получение данных из разобранной страницы, возможно, с использованием дополнительных справочников и данных;
6. Обновление (Update, U): обновление данных в БД;
7. Контроль (Monitoring, M): обработка данных других модулей, ведение журналов, предоставление информации о текущем статусе.
На схеме кратко представлены основные пути взаимодействия модулей.
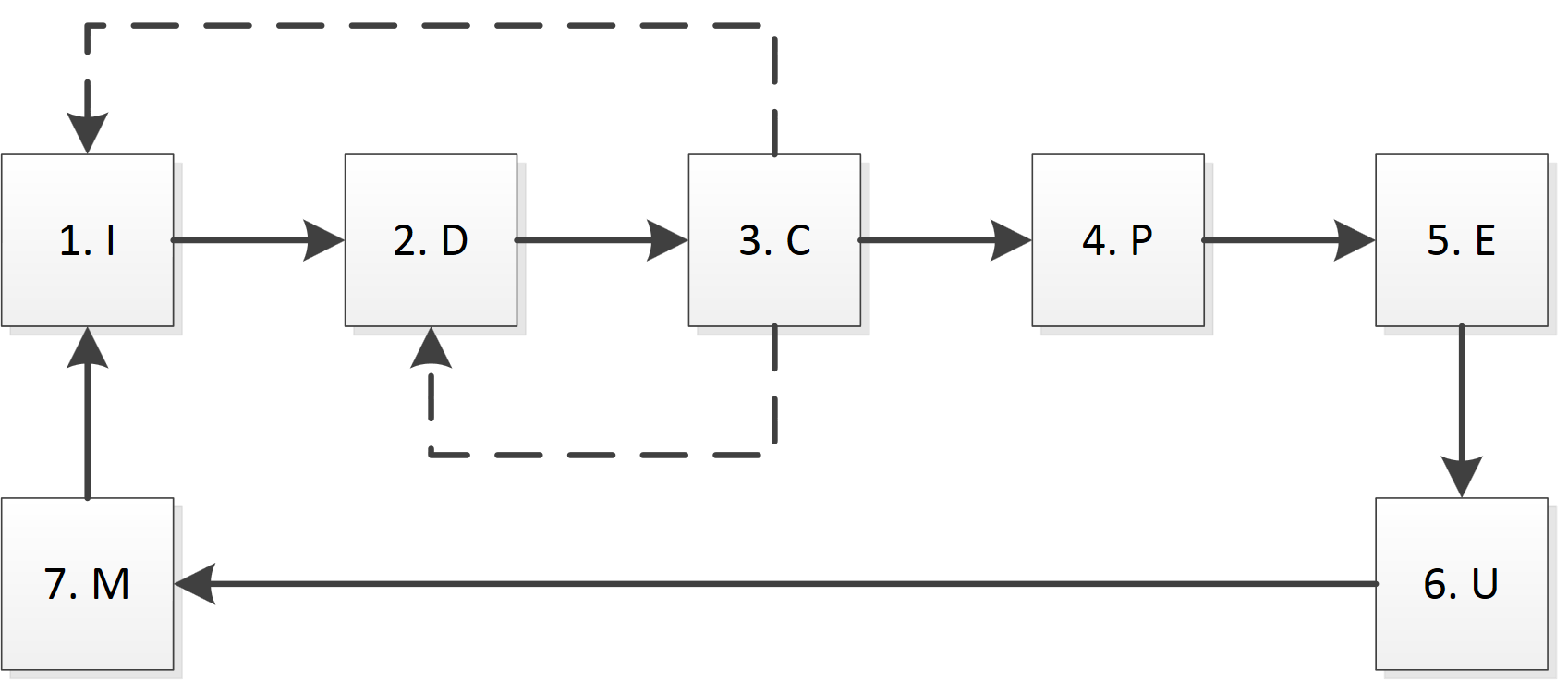
Хочется подчеркнуть важность первого и третьего блоков. В блоке подготовки (I) выполняются все операции, которые необходимы для начала работы с конкретным сервером, а также обработка «нестандартных» страниц. Возможно, что перед получением страниц с данными необходимо выполнить port knocking, загрузить определённую страницу (или картинку) для получения cookie, доказать, что страницы посещает человек (captcha, контрольный вопрос). Здесь же определяются и создаются потоки и очередь для конкретного сервера. Фактически, данный модуль может принимать решения о приостановке загрузки, а также её возобновления после устранения причины ошибки. В рамках системы данный блок должен быть один для каждого сайта, поскольку, например, повторная аутентификация может привести к сбросу сессии.
Модуль проверки © необходим для оперативной оценки корректности загрузки конкретной страницы. Хотя по времени он работает непосредственно сразу после блока загрузки (D), но часто имеет индивидуальную реализацию для каждого сайта. Корректная страница не означает, что там находится именно то, что нужно, поскольку сайт может сообщать об ошибке авторизации, необходимости пройти аутентификацию, повторить попытку через некоторое время, невозможности найти подходящую страницу и т.п. В качестве критериев распознавания можно использовать сокращённый модуль разбора (P), но дополнительно необходимо научиться обрабатывать и сообщения об ошибках.
Также друг от друга отделяется блок разбора (P) и блок экстракции (E). Причина этого в том, что целью разбора является анализ страницы и выделение фрагментов с данными, а экстракция уже привязывает данные к конкретным объектам. Разбор работает на уровне HTML и ограничен конкретной страницей, а блок экстракции работает уже с данными и может воспользоваться информацией ранее загруженных страниц.
У блока обновления (U) задача осложняется тем, что данные надо объединять, причём они могут содержать различное число полей и быть корректными лишь на определённые моменты времени.
Целью модуля контроля (M) является не только получение информации о текущем статусе и процессе выполнения операций, но и выявление сбоев и возможность перезапуска с любого этапа. Например, мы создали первую версию парсера, с помощью которого успешно скачали форум phpBB. Затем выяснилось, что есть темы-опросы, тогда достаточно лишь доработать парсер и запустить повторно парсинг для всех страниц, которые уже скачены.
ИнКр первой версии опишу в следующей статье, если не окажется, что существует уже готовое решение, которое по функционалу сопоставимо с заявленным выше.
Рад буду вашим комментариям.
Какие видите недостатки в архитектуре? Что необходимо скорректировать? Где чувствуете появление потенциальных проблем?
ссылка на оригинал статьи http://habrahabr.ru/post/194914/
Добавить комментарий