Из-за большого объёма оригинальной статьи я разбила её на части, которых в общей сложности будет четыре.
Я по прежнему буду крайне признательна за любые замечания в личку по улучшению качества перевода.
Введение
Многие нынешние программисты, пишущие классные и широко распространённые программы, имеют крайне смутное представление о теоретической информатике. Это не мешает им оставаться прекрасными творческими специалистами, и мы благодарны за то, что они создают.
Тем не менее, знание теории тоже имеет своё преимущества и может оказаться весьма полезным. В этой статье, предназначенной для программистов, которые являются хорошими практиками, но имеют слабое представление о теории, я представлю один из наиболее прагматичных программистских инструментов: нотацию «большое О» и анализ сложности алгоритмов. Как человек, который работал как в области академической науки, так и над созданием коммерческого ПО, я считаю эти инструменты по-настоящему полезными на практике. Надеюсь, что после прочтения этой статьи вы сможете применить их к собственному коду, чтобы сделать его ещё лучше. Также этот пост принесёт с собой понимание таких общих терминов, используемых теоретиками информатики, как «большое О», «асимптотическое поведение», «анализ наиболее неблагоприятного случая» и т.п.
Этот текст также ориентирован на учеников средней школы из Греции или любой другой страны, участвующих в Международной олимпиаде по информатике, соревнованиях по алгоритмам для учащихся и тому подобном. Как таковой, он не нуждается в знании каких-либо математических предпосылок и даст вам основу для дальнейшего исследования алгоритмов с твёрдым пониманием стоящей за ними теории. Как тот, кто в своё время много участвовал в различных состязаниях, я настоятельно рекомендую вам прочитать и понять весь вводный материал. Эти знания будут просто необходимы, когда вы продолжите изучать алгоритмы и различные передовые технологии.
Я надеюсь, что это текст будет полезен для тех программистов-практиков, у которых нет большого опыта в теоретической информатике (то, что самые вдохновлённые инженеры-программисты никогда не ходили в колледж, уже давно свершившийся факт). Но поскольку статья предназначена и для студентов тоже, то временами она будет звучать, как учебник. Более того, некоторые темы могут показаться вам через чур простыми (например, вы могли сталкиваться с ними во время своего обучения). Так что, если вы чувствуете, что понимаете их — просто пропускайте эти моменты. Другие секции идут несколько глубже и являются более теоретическими, потому что студенты, участвующие в соревнованиях, должны разбираться в теории алгоритмов лучше, чем средний практик. Но знать эти вещи не менее полезно, а следить за ходом повествования не так уж сложно, так что они, скорее всего, заслуживают вашего внимания. Оригинальный текст был направлен учащимся старшей школы, никаких особых математических знаний он не требует, поэтому каждый, имеющий опыт программирования (например, знающий, что такое рекурсия) способен понять его без особых проблем.
В этой статье вы найдёте много интересных ссылок на материалы, выходящие за рамки нашего обсуждения. Если вы работающий программист, то вполне возможно, что вы знакомы с большинством из этих концепций. Если же вы просто студент-новичок, участвующий в соревнованиях, переход по этим ссылкам даст вам информацию о других областях информатики и разработки программного обеспечения, которые вы ещё не успели изучить. Просмотрите их ради увеличения собственного багажа знаний.
Нотация «большого О» и анализ сложности алгоритмов — это те вещи, которые и программисты-практики, и студенты-новички часто считают трудными для понимания, боятся или вообще избегают, как бесполезные. Но они не так уж сложны и заумны, как может показаться на первый взгляд. Сложность алгоритма — это всего лишь способ формально измерить, насколько быстро программа или алгоритм работают, что является весьма прагматичной целью. Давайте начнём с небольшой мотивации по этой теме.
Мотивация
Мы уже знаем, что существуют инструменты, измеряющие, насколько быстро работает код. Это программы, называемые профайлерами (profilers), которые определяют время выполнения в миллисекундах, помогая нам выявлять узкие места и оптимизировать их. Но, хотя это и полезный инструмент, он не имеет отношения к сложности алгоритмов. Сложность алгоритма — это то, что основывается на сравнении двух алгоритмов на идеальном уровне, игнорируя низкоуровневые детали вроде реализации языка программирования, «железа», на котором запущена программа, или набора команд в данном CPU. Мы хотим сравнивать алгоритмы с точки зрения того, чем они, собственно, являются: идеи, как происходит вычисление. Подсчёт миллисекунд тут мало поможет. Более того, плохой алгоритм, написанный на низкоуровневом языке (например, ассемблере) будет намного быстрее, чем хороший алгоритм, написанный языке программирования высокого уровня (например, Python или Ruby). Так что, пришло время определиться, что же такое «лучший алгоритм» на самом деле.
Алгоритм — это программа, которая представляет из себя исключительно вычисление, без других часто выполняемых компьютером вещей — сетевых задач или пользовательского ввода-вывода. Анализ сложности позволяет нам узнать, насколько быстра эта программа, когда она совершает вычисления. Примерами чисто вычислительных операций могут послужить операции над числами с плавающей запятой (сложение и умножение), поиск заданного значения в находящейся в ОЗУ базе данных, определение игровым ИИ движения своего персонажа таким образом, чтобы он передвигался только на короткое расстояние внутри игрового мира, или запуск шаблона регулярного выражения на соответствие строке. Очевидно, что вычисления встречаются в компьютерных программах повсеместно.
Анализ сложности также позволяет нам объяснить, как будет вести себя алгоритм при возрастании входного потока данных. Если наш алгоритм выполняется одну секунду при 1000 элементах на входе, то как он себя поведёт, если мы удвоим это значение? Будет работать также быстро, в полтора раза быстрее или в четыре раза медленнее? В практике программирования такие предсказания крайне важны. Например, если мы создали алгоритм для web-приложения, работающего с тысячей пользователей, и измерили его время выполнения, то используя анализ сложности, мы получим весьма неплохое представление о том, что случится, когда число пользователей возрастёт до двух тысяч. Для соревнований по построению алгоритмов анализ сложности также даст нам понимание того, как долго будет выполняться наш код на наибольшем из тестов для проверки его правильности. Так что, если мы определим общее поведение нашей программы на небольшом объёме входных данных, то сможем получить хорошее представление и о том, что будет с ней при больших потоках данных. Давайте начнём с простого примера: поиска максимального элемента в массиве.
Подсчёт инструкций
В этой статье для реализации примеров я буду использовать различные языки программирования. Не переживайте, если вы не знакомы с каким-то из них — любой, кто умеет программировать, способен прочитать этот код без особых проблем, поскольку он прост, и я не собираюсь использовать какие-либо экзотические фенечки языка реализации. Если вы — студент-олимпиадник, то, скорее всего, пишите на С++, поэтому у вас тоже не должно возникать проблем. В этом случае я также рекомендую прорабатывать упражнения, используя С++ для большей практики.
Максимальный элемент массива можно найти с помощью простейшего отрывка кода. Например, такого, написанного на Javascript. Дан входной массив А размера n:
var M = A[ 0 ]; for ( var i = 0; i < n; ++i ) { if ( A[ i ] >= M ) { M = A[ i ]; } } Сначала подсчитаем, сколько здесь вычисляется фундаментальных инструкций. Мы сделаем это только один раз — по мере углубления в теорию такая необходимость отпадёт. Но пока наберитесь терпения на то время, которое мы потратим на это. В процессе анализа данного кода, имеет смысл разбить его на простые инструкции — задания, которые могут быть выполнены процессором тотчас же или близко к этому. Предположим, что наш процессор способен выполнять как единые инструкции следующие операции:
- Присваивать значение переменной
- Находить значение конкретного элемента в массиве
- Сравнивать два значения
- Инкрементировать значение
- Основные арифметические операции (например, сложение и умножение)
Мы будем полагать, что ветвление (выбор между if и else частями кода после вычисления if-условия) происходит мгновенно, и не будем учитывать эту инструкцию при подсчёте. Для первой строки в коде выше:
var M = A[ 0 ]; требуются две инструкции: для поиска A[0] и для присвоения значения M (мы предполагаем, что n всегда как минимум 1). Эти две инструкции будут требоваться алгоритму, вне зависимости от величины n. Инициализация цикла for тоже будет происходить постоянно, что даёт нам ещё две команды: присвоение и сравнение.
i = 0; i < n; Всё это происходит до первого запуска for. После каждой новой итерации мы будем иметь на две инструкции больше: инкремент i и сравнение для проверки, не пора ли нам останавливать цикл.
++i; i < n; Таким образом, если мы проигнорируем содержимое тела цикла, то количество инструкций у этого алгоритма 4 + 2n — четыре на начало цикла for и по две на каждую итерацию, которых мы имеем n штук. Теперь мы можем определить математическую функцию f(n) такую, что зная n, мы будем знать и необходимое алгоритму количество инструкций. Для цикла for с пустым телом f( n ) = 4 + 2n.
Анализ наиболее неблагоприятного случая
В теле цикла мы имеем операции поиска в массиве и сравнения, которые происходят всегда:
if ( A[ i ] >= M ) { ... Но тело if может запускаться, а может и нет, в зависимости от актуального значения из массива. Если произойдёт так, что A[ i ] >= M, то у нас запустятся две дополнительные команды: поиск в массиве и присваивание:
M = A[ i ] Мы уже не можем определить f(n) так легко, потому что теперь количество инструкций зависит не только от n, но и от конкретных входных значений. Например, для A = [ 1, 2, 3, 4 ] программе потребуется больше команд, чем для A = [ 4, 3, 2, 1 ]. Когда мы анализируем алгоритмы, мы чаще всего рассматриваем наихудший сценарий. Каким он будет в нашем случае? Когда алгоритму потребуется больше всего инструкций до завершения? Ответ: когда массив упорядочен по возрастанию, как, например, A = [ 1, 2, 3, 4 ]. Тогда M будет переприсваиваться каждый раз, что даст наибольшее количество команд. Теоретики имеют для этого причудливое название — анализ наиболее неблагоприятного случая, который является ни чем иным, как просто рассмотрением максимально неудачного варианта. Таким образом, в наихудшем случае в теле цикла из нашего кода запускается четыре инструкции, и мы имеем f( n ) = 4 + 2n + 4n = 6n + 4.
Асимптотическое поведение
С полученной выше функцией мы имеем весьма хорошее представление о том, насколько быстр наш алгоритм. Однако, как я и обещал, нам нет нужды постоянно заниматься таким утомительным занятием, как подсчёт команд в программе. Более того, количество инструкций у конкретного процессора, необходимое для реализации каждого положения из используемого языка программирования, зависит от компилятора этого языка и доступного процессору (AMD или Intel Pentium на персональном компьютере, MIPS на Playstation 2 и т.п. ) набора команд. Ранее же мы говорили, что собираемся игнорировать условия такого рода. Поэтому сейчас мы пропустим нашу функцию f через «фильтр» для очищения её от незначительных деталей, на которые теоретики предпочитают не обращать внимания.
Наша функция 6n + 4 состоит из двух элементов: 6n и 4. При анализе сложности важность имеет только то, что происходит с функцией подсчёта инструкций при значительном возрастании n. Это совпадает с предыдущей идеей «наихудшего сценария»: нам интересно поведение алгоритма, находящегося в «плохих условиях», когда он вынужден выполнять что-то трудное. Заметьте, что именно это по-настоящему полезно при сравнении алгоритмов. Если один из них побивает другой при большом входном потоке данных, то велика вероятность, что он останется быстрее и на лёгких, маленьких потоках. Вот почему мы отбрасываем те элементы функции, которые при росте n возрастают медленно, и оставляем только те, что растут сильно. Очевидно, что 4 останется 4 вне зависимости от значения n, а 6n наоборот будет расти. Поэтому первое, что мы сделаем, — это отбросим 4 и оставим только f( n ) = 6n.
Имеет смысл думать о 4 просто как о «константе инициализации». Разным языкам программирования для настройки может потребоваться разное время. Например, Java сначала необходимо инициализировать свою виртуальную машину. А поскольку мы договорились игнорировать различия языков программирования, то попросту отбросим это значение.
Второй вещью, на которую можно не обращать внимания, является множитель перед n. Так что наша функция превращается в f( n ) = n. Как вы можете заметить, это многое упрощает. Ещё раз, константный множитель имеет смысл отбрасывать, если мы думаем о различиях во времени компиляции разных языков программирования. «Поиск в массиве» для одного ЯП может компилироваться совершенно иначе, чем для другого. Например, в Си выполнение A[ i ] не включает проверку того, что i не выходит за пределы объявленного размера массива, в то время как для Паскаля она существует. Таким образом, данный паскалевский код:
M := A[ i ] эквивалентен следующему на Си:
if ( i >= 0 && i < n ) { M = A[ i ]; } Так что имеет смысл ожидать, что различные языки программирования будут подвержены влиянию различных факторов, которые отразятся на подсчёте инструкций. В нашем примере, где мы используем «немой» паскалевский компилятор, игнорирующий возможности оптимизации, требуется по три инструкции на Паскале для каждого доступа к элементу массива вместо одной на Си. Пренебрежение этим фактором идёт в русле игнорирования различий между конкретными языками программирования с сосредоточением на анализе самой идеи алгоритма как таковой.
Описанные выше фильтры — «отбрось все факторы» и «оставляй только наибольший элемент» — в совокупности дают то, что мы называем асимптотическим поведением. Для f( n ) = 2n + 8 оно будет описываться функцией f( n ) = n. Говоря языком математики, нас интересует предел функции f при n, стремящемся к бесконечности. Если вам не совсем понятно значение этой формальной фразы, то не переживайте — всё, что нужно, вы уже знаете. (В сторону: строго говоря, в математической постановке мы не могли бы отбрасывать константы в пределе, но для целей теоретической информатики мы поступаем таким образом по причинам, описанным выше). Давайте проработаем пару задач, чтобы до конца вникнуть в эту концепцию.
Найдём асимптотики для следующих примеров, используя принципы отбрасывания константных факторов и оставления только максимально быстро растущего элемента:
f( n ) = 5n + 12дастf( n ) = n.
Основания — те же, что были описаны вышеf( n ) = 109дастf( n ) = 1.
Мы отбрасываем множитель в109 * 1, но 1 по-прежнему нужен, чтобы показать, что функция не равна нулюf( n ) = n2+ 3n + 112дастf( n ) = n2
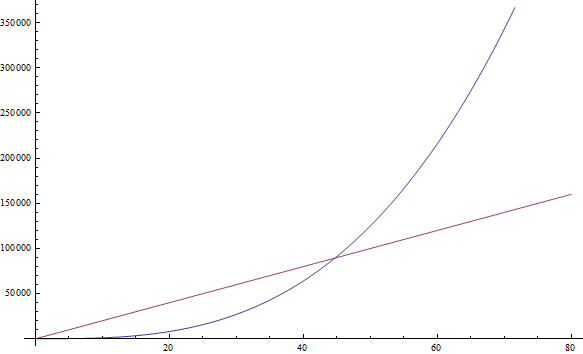
Здесьn2 возрастает быстрее, чем3n, который, в свою очередь, растёт быстрее112f( n ) = n3+ 1999n + 1337дастf( n ) = n3
Несмотря на большую величину множителя передn, мы по прежнему полагаем, что можем найти ещё большийn, поэтомуf( n ) = n3 всё ещё больше1999n(см. рисунок выше)f( n ) = n + sqrt( n )дастf( n ) = n
Потому чтоnпри увеличении аргумента растёт быстрее, чемsqrt( n )
- f( n ) = n6 + 3n
- f( n ) = 2n + 12
- f( n ) = 3n + 2n
- f( n ) = nn + n
Если у вас возникли проблемы с выполнением этого задания, то просто подставьте в выражение достаточно большое n и посмотрите, какой из его членов имеет большую величину. Всё очень просто, не так ли?
ссылка на оригинал статьи http://habrahabr.ru/post/196560/
Добавить комментарий