Как обещалось в предыдущей статье, сегодня я продолжу рассказ о модуле pandas и анализе данных на языке Python. В данной статье хотелось бы затронуть тему быстрой визуализации данных результатов анализа. В этом нам помогут библиотека для визуализации данных matplotlib и среда разработки Spyder.
Среда разработки
Итак, как мы увидели в прошлый раз, pandas обладает широким возможностями для анализа данных, но полностью раскрыть их позволяет интерактивная оболочка IPython. О ней можно прочитать на Хабре. В качестве ее основного преимущества хотелось бы отметить ее интеграцию с библиотекой matplotlib, что удобно для визуализации данных при расчетах. Поэтому при выборе IDE я смотрел на то, чтобы у нее была поддержка IPython. В результате мой выбор остановился на Spyder.
Spyder (Scientific PYthon Development EnviRonment) – это среда разработки похожая на MATLAB. Основными плюсами данной среды являются:
- Настраиваемый интерфейс
- Интеграция с matplotlib, NumPy, SciPy
- Поддержка использования множества консолей IPython
- Динамическая справка по функциям при написании кода (показывает справку по последней напечатанной функции)
- Возможность сохранить консоль в html/xml
Подробный обзор среды написан здесь.
Предварительный анализ данных и приведение их в нужный вид средствами pandas
Итак, после небольшого обзора среды для работы, давайте перейдем непосредственно к визуализации данных. Для примера я взял данные о численности населения в РФ.
Для начала давайте загрузим скачанный файл xls в набор данных c помощью функции read_excel():
import pandas as pd data = pd.read_excel('data.xls',u'Лист1', header=4, parse_cols="A:B",skip_footer=2, index_col=0) c = data.rename(columns={u'Все':'PeopleQty'}) В нашем случае функция имеет 6 параметров:
- Имя открываемого файла
- Имя листа, на котором содержатся данные
- Номер строки содержащей названия полей (в нашем случае это строка 4, т.к. первые 3 строки содержат справочную информацию)
- Список столбцов, которые попадут в набор данных (в нашем случае из всей таблицы нам нужны только 2 столбца: год и количество населения, соответствующее ему)
- Следующий параметр означает, что мы не будет учитывать 2 последние строки (в них содержатся комментарии)
- Последний параметр указывает, что первый из полученных столбцов мы будем использовать в качестве индекса
Теперь наш набор данных будет выглядеть так:
| PeopleQty | |
|---|---|
| население, | |
| млн.человек | |
| 1897.0 | |
| в границах Российской империи | 128.2 |
| в современных границах | 67.5 |
| 1914 | |
| в границах Российской империи | 165.7 |
| в современных границах | 89.9 |
| 1917 | 91 |
| 1926 | 92.7 |
| 1939 | 108.4 |
| 1959 | 117.2 |
| 1970 | 129.9 |
| 1971 | 130.6 |
| 1972 | 131.3 |
| 1973 | 132.1 |
| 1974 | 132.8 |
| 1975 | 133.6 |
| 1976 | 134.5 |
| 1977 | 135.5 |
| 1978 | 136.5 |
| … | … |
| 2013 | 143.3 |
Ну что же данные загружены, но, как можно заметить, данные в столбце индекса не совсем корректные. Например, там содержатся не только номера годов, но и текстовые пояснения, а еще он содержит пустые значения. Кроме того, можно увидеть, что до 1970 года, данные заполнены не очень хорошо, из-за больших временных промежутков между соседними значениями.
Привести данные в красивый вид можно несколькими способами:
- Либо с помощью фильтров
- Либо с помощью соединения с DataFrame’ом, который будет содержать годы в формате даты (это поможет еще и в оформлении графики)
Базовая работа с фильтрами была показана в предыдущей статье. Поэтому в этот раз мы используем дополнительный DataFrame, т. к. в процессе его формирования будет показано, как можно средствами pandas создать временную последовательность.
Для формирования временной шкалы можно использовать функцию date_range(). В параметрах ей передается 3 параметра: начальное значение, количество периодов, размер периода (День, месяц, год и т.д.). В нашем случае давайте сформируем последовательность, начиная с 1970 по настоящий момент, т.к. с этого момента данные в нашей таблице заполнены практически за каждый год:
a = pd.date_range('1/1/1970', periods=46, freq='AS') На выходе у нас сформировалась последовательность с 1970 по 2015 год.
<class 'pandas.tseries.index.DatetimeIndex'>
[1970-01-01 00:00:00, ..., 2015-01-01 00:00:00]
Теперь нам необходимо добавить эту последовательность в DataFrame, кроме того, чтобы соединиться с исходным набором данных, нам нужен непосредственно номер года, а не дата его начала, как в последовательности. Для этого у нашей временной последовательности есть свойство year, которое как раз и возвращает номер года каждой записи. Создать DataFrame можно так:
b = pd.DataFrame(a, index=a.year,columns=['year']) В качестве параметров функции передаются следующее значения:
- Массив данных, из которых будет создаваться DataFrame
- Значения индексов для набора данных
- Название полей в наборе
На набор данных принял вид:
| year | |
|---|---|
| 1970 | 1970-01-01 00:00:00 |
| 1971 | 1971-01-01 00:00:00 |
| 1972 | 1972-01-01 00:00:00 |
| 1973 | 1973-01-01 00:00:00 |
| 1974 | 1974-01-01 00:00:00 |
| 1975 | 1975-01-01 00:00:00 |
| 1976 | 1976-01-01 00:00:00 |
| 1977 | 1977-01-01 00:00:00 |
| 1978 | 1978-01-01 00:00:00 |
| 1979 | 1979-01-01 00:00:00 |
| 1980 | 1980-01-01 00:00:00 |
| 1981 | 1981-01-01 00:00:00 |
| … | … |
| 2015 | 2015-01-01 00:00:00 |
Ну что же, теперь у нас есть 2 набора данных, осталось их соединить. В прошлой статье было показано, как это сделать merge(). В этот же раз мы будем использовать другую функцию join(). Эту функцию можно применять, когда у ваших наборов данных одинаковые индексы (кстати, именно для того, чтобы продемонстрировать эту функцию мы их и добавляли). В коде это будет выглядеть так:
i = b.join(c, how=’inner’) В параметрах к функции, мы передаем набор, который присоединяется и тип соединения. Как известно результат inner-соединения будет состоять из значений, которые присутствуют в обоих наборах.
Стоит сразу отметить разницу между функциями merge() и join(). Merge() может производить соединение по разным столбцам, join() же, в свою очередь, работает только с индексами.
Визуализация результатов анализа
После проделанных нами манипуляция, набор данных выглядит так:
| year | PeopleQty | |
|---|---|---|
| 1970 | 1970-01-01 00:00:00 | 129.9 |
| 1971 | 1971-01-01 00:00:00 | 130.6 |
| 1972 | 1972-01-01 00:00:00 | 131.3 |
| 1973 | 1973-01-01 00:00:00 | 132.1 |
| 1974 | 1974-01-01 00:00:00 | 132.8 |
| 1975 | 1975-01-01 00:00:00 | 133.6 |
| … | ||
| … | … | … |
| … | … | … |
| 2013 | 2013-01-01 00:00:00 | 143.3 |
Ну что же теперь давайте нарисуем самый простой график, отображающий динамику роста населения. Сделать это можно функцией plot(). У этой функции много параметров, но для простого примера нам хватит задать значение осей x и y и параметра style, который отвечает за стиль. Выглядеть это будет так:
i.plot(x='year',y='PeopleQty',style='k--') В итоге наш график будет выглядеть так:

При вызове функции plot() в оболочке IPython, график выведется непосредственно в оболочке, что поможет избежать лишнего переключения между окнами. (при использовании стандартной оболочки график открылся бы в отдельном окне, что бывает не очень удобно). Кроме того, если вы используете IPython через Spyder, можно будет выгрузить весь сеанс в html файл вместе со всеми сформированными графиками.
Теперь давайте отобразим динамику в виде столбчатой диаграммы. Сделать это можно при помощи параметра kind. По умолчанию параметр равен `line`. Чтобы сделать диаграмму с вертикальными столбцами нужно поменять значение этого параметра на `bar`, для горизонтальных столбцов существует значение `barh`. Итак для горизонтальных столбцов, код будет выглядеть так:
i.plot(y='PeopleQty', kind='bar') Получившийся график приведен ниже:
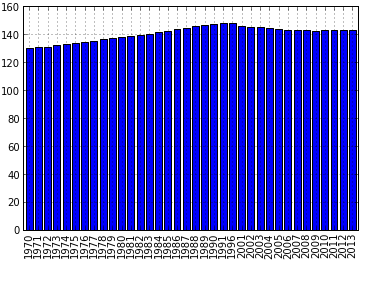
Как видно из кода, тут мы не задаем значение х в отличие от предыдущих примеров, в качестве х используется индекс. Для полноценной работы с графикой и наведения красоты необходимо использовать возможности matplotlib, про нее уже есть много статей. Это связано с тем, что функция рисования в pandas является всего лишь надстройкой, для быстрого вызова основных функций рисования из вышеуказанной библиотеки, таких как matplotlib.pyplot.bar(). Соответственно все параметры используемые в при вызове функций из matplotlib, могут быть заданы через функцию plot() пакета pandas.
Заключение
На этом введение в визуализацию результатов анализа в pandas закончено. В статье я постарался описать необходимый базис для работы с графикой. Более подробное описание всех возможностей дано в документации к pandas, а также библиотеки matplotlib. Также хотелось бы обратить Ваше внимание, что существую сборки Python заточенные именно под анализ данных, которые уже включают в себя такие библиотеки и надстройки, как matplotlib, pandas, IDE Spyder, и оболочку IPython. Мне известно две таких сборки это Python(x,y) и Anaconda. Первая поддерживает только Windows, но обладает большим набором встраиваемых пакетов. Anaconda ;t является кросс-платформенной (это одна из причин, по которой я ее использую) и ее бесплатная версия включает меньше пакетов.
ссылка на оригинал статьи http://habrahabr.ru/post/197212/
Добавить комментарий