
Как я упоминал в своих предыдущих заметках, основными трудностями при реализации lock-free структур данных являются ABA-проблема и удаление памяти. Я разделяю эти две проблемы, хоть они и связаны: дело в том, что существуют алгоритмы, решающие только одну из них.
В этой статье я дам обзор известных мне методов безопасного удаления памяти (safe memory reclamation) для lock-free контейнеров. Демонстрировать применение того или иного метода я буду на классической lock-free очереди Майкла-Скотта [MS98].
Tagged pointers
Схема меченых указателей (tagged pointers) была предложена IBM для решения ABA-проблемы. Пожалуй, это первый известный алгоритм решения данной проблемы.
Согласно этой схеме, каждый указатель представляет собой неделимую пару из собственно адреса ячейки памяти и его тега – 32-битового целого числа.
template <typename T> struct tagged_ptr { T * ptr ; unsigned int tag ; tagged_ptr(): ptr(nullptr), tag(0) {} tagged_ptr( T * p ): ptr(p), tag(0) {} tagged_ptr( T * p, unsigned int n ): ptr(p), tag(n) {} T * operator->() const { return ptr; } }; Тег выступает как номер версии и инкрементируется при каждой операции CAS над меченым указателем и никогда не сбрасывается, то есть строго возрастает. При удалении элемента из контейнера вместо физического удаления элемент следует помещать в некоторый список свободных элементов free-list. При этом вполне допустимо, если к удаленному элементу, находящемуся во free-list, будет обращение: структуры у нас lock-free, так что пока один поток удаляет элемент X, другой поток может иметь локальную копию меченого указателя на X и обращаться к полям элемента. Поэтому free-list должен быть отдельный для каждого типа T, более того, вызывать деструктор данных типа T при помещении элемента во free-list во многих случаях недопустимо (по причине параллельного доступа – во время работы деструктора другой поток может читать данные этого элемента).
Схема tagged pointer имеет следующие недостатки:
- Схема реализуема на платформах, на которых существует атомарный примитив CAS над двойным словом (dwCAS). Для 32-битных современных платформ это требование выполняется, так как dwCAS работает с 64-битными словами, а все современные архитектуры имеют полный набор 64-битных инструкций. Но для 64-битного режима работы требуется 128-битный (или, по крайней мере, 96-битный) dwCAS, что реализовано не на всех архитектурах.
Да вы ерунду написали, батенька!Особо искушенные в lock-free могут возразить, что для реализации tagged pointers не обязательно иметь широкий 128-битный (или 96-битный) CAS. Можно обойтись 64-битным, если учесть, что современные процессоры используют только 48 бит для адресации, старшие 16 бит адреса свободны и могут быть использованы для хранения счетчика-тега. Что ж, действительно, могут. Так сделано вboost.lockfree.
В таком подходе есть два «но»:- Кто гарантирует, что в будущем эти старшие 16 бит адреса не будут задействованы? Как только наступит очередной прорыв в области чипов памяти и её объем возрастет скачком на порядок, — вендоры сразу выпустят новые процессоры с полностью 64-разрядной адресацией
- Достаточно ли 16 бит для хранения тега? На этот счет проводились исследования, и результат этих исследований таков: 16 бит недостаточно, вполне возможно переполнение, что потенциально может привести к возникновению ABA-проблемы. А вот 32 бита – достаточно.
Действительно, 16 бит – это значения тега 0 – 65535. В современных операционных системах квант времени, отводящийся потоку, порядка 300 – 500 тысяч ассемблерных инструкций (взято из внутренней переписки разработчиков linux), и с увеличением производительности процессоров этот квант может только расти. Получается, за один квант вполне можно выполнить 65 тысяч даже таких тяжелых операций, как CAS (ну, если невозможно сегодня, то будет возможно уже завтра). Таким образом, при 16-битовом теге мы вполне рискуем получить ABA-проблему.
- Реализация free-list – это lock-free стек или lock-free очередь, что вносит свой отрицательный вклад в производительность: ещё как минимум по одному вызову CAS при извлечении элемента из free-list и добавлении в него. С другой стороны, наличие free-list может способствовать увеличению производительности, так как, если free-list не пустой, то не надо обращаться к системным, обычно достаточно медленным и синхронизированным функциям распределения памяти.
- Наличие отдельного free-list для каждого типа данных может являться непозволительной роскошью для некоторых приложений, так как может приводить к неэффективному использованию памяти. Например, если lock-free очередь в среднем содержит 10 элементов, но в пике её размер может достигать 1 миллиона, то размер free-list после достижения пика стабильно будет около 1 млн. Зачастую такое поведение недопустимо.
Таким образом, схема tagged pointer является примером алгоритма, решающего только ABA-проблему, и не решающего проблему освобождения памяти.
Библиотека libcds в настоящее время не использует tagged pointers для реализации lock-free контейнеров. Несмотря на относительную простоту, эта схема может привести к неконтролируемому росту потребляемой памяти из-за наличия free-list для каждого объекта-контейнера. В libcds я сосредоточился на lock-free алгоритмах с предсказуемым потреблением памяти, без применения dwCAS.
Хорошим примером применения схемы tagged pointers является библиотека boost.lockfree.
Пример использования tagged pointers
Любителям простыней (если таковые найдутся) — псевдокод MSQueue [MS98] с tagged pointer. Да, lock-free алгоритмы очень многословны!
Для простоты я опустил применение std:atomic.
template <typename T> struct node { tagged_ptr next; T data; } ; template <typename T> class MSQueue { tagged_ptr<T> volatile m_Head; tagged_ptr<T> volatile m_Tail; FreeList m_FreeList; public: MSQueue() { // Распределяем dummy node // Head & Tail указывают на dummy node m_Head.ptr = m_Tail.ptr = new node(); } void enqueue( T const& value ) { E1: node * pNode = m_FreeList.newNode(); E2: pNode–>data = value; E3: pNode–>next.ptr = nullptr; E4: for (;;) { E5: tagged_ptr<T> tail = m_Tail; E6: tagged_ptr<T> next = tail.ptr–>next; E7: if tail == Q–>Tail { // Tail указывает на последний элемент? E8: if next.ptr == nullptr { // Пробуем добавить элемент в конец списка E9: if CAS(&tail.ptr–>next, next, tagged_ptr<T>(node, next.tag+1)) { // Успех, выходим из цикла E10: break; } E11: } else { // Tail не указывает на последний элемент // Пробуем переместить tail на последний элемент E12: CAS(&m_Tail, tail, tagged_ptr<T>(next.ptr, tail.tag+1)); } } } // end loop // Пробуем переместить tail на вставленный элемент E13: CAS(&m_Tail, tail, tagged_ptr<T>(pNode, tail.tag+1)); } bool dequeue( T& dest ) { D1: for (;;) { D2: tagged_ptr<T> head = m_Head; D3: tagged_ptr<T> tail = m_Tail; D4: tagged_ptr<T> next = head–>next; // Head, tail и next консистентны? D5: if ( head == m_Head ) { // Queue пуста или tail не последний? D6: if ( head.ptr == tail.ptr ) { // Очередь пуста? D7: if (next.ptr == nullptr ) { // Очередь пуста D8: return false; } // Tail не на последнем элементе // Пробуем продвинуть tail D9: CAS(&m_Tail, tail, tagged_ptr<T>(next.ptr, tail.tag+1>)); D10: } else { // Tailна месте // Читаем значение перед CAS, так как иначе // другой dequeue может освободить next D11: dest = next.ptr–>data; // Пробуем продвинуть head D12: if (CAS(&m_Head, head, tagged_ptr<T>(next.ptr, head.tag+1)) D13: break // Успех, выходим из цикла } } } // end of loop // Освобождаем старый dummy node D14: m_FreeList.add(head.ptr); D15: return true; // результат – в dest } 
Посмотрим внимательно на алгоритмы операций enqueue и dequeue. На их примере можно увидеть несколько стандартных приемов при построении lock-free структур.
Сразу обращает на себя внимание, что оба метода содержат циклы – вся содержательная часть операций повторяется до тех пор, пока не выполнится успешно (либо успешное выполнение невозможно, например, dequeue из пустой очереди). Такая «долбежка» с помощью цикла – типичный прием lock-free программирования.
Первым элементом в очереди (на который указывает m_Head) является фиктивный элемент (dummy node). Наличие фиктивного элемента гарантирует нам, что указатели на начало и конец очереди никогда не будут равны NULL. Признаком пустоты очереди является условие m_Head == m_Tail && m_Tail->next == NULL (строки D6-D8). Последнее условие (m_Tail->next == NULL) является существенным, так как в процессе добавления в очередь мы не изменяем m_Tail, — строка E9 лишь меняет m_Tail->next. Таким образом, на первый взгляд метод enqueue нарушает структуру очереди. На самом деле, изменение хвоста m_Tail происходит в другом методе и/или другом потоке: операция enqueue перед добавлением элемента проверяет (строка E8), что m_Tail указывает на последний элемент (то есть m_Tail->next == NULL), и если это не так, пытается передвинуть указатель на конец (строка E12); точно так же, операция dequeue перед выполнением своих «непосредственных обязанностей» изменяет m_Tail, если он указывает не на конец очереди (строка D9). Это демонстрирует нам распространенный подход в lock-free программировании — взаимопомощь потоков (helping): алгоритм одной операции является «размазанным» по всем операциям контейнера и одна операция существенно полагается на то, что её работу завершит следующий вызов (возможно, другой) операции в (возможно) другом потоке.
Ещё одно принципиальное наблюдение: операции запоминают в локальных переменных значения указателей, которые им требуются для работы (строки E5-E6, D2-D4). Затем (строки E7, D5) только что считанные значения сверяются с оригиналами — типичный прием lock-free, излишний для неконкурентного программирования: за время, прошедшее с момента считывания оригинальные значения могут измениться. Чтобы компилятор не оптимизировал доступ к разделяемым данным очереди (а слишком «умный» компилятор способен и вовсе удалить строки сравнения E7 или D5), m_Head и m_Tail должны быть объявлены в C++11 как atomic (в псевдокоде – volatile). Кроме того, вспомним, что CAS-примитив сверяет значение целевого адреса с заданным, и если они равны, изменяет данные по целевому адресу на новое значение. Поэтому для CAS-примитива всегда следует указывать локальную копию текущего значения; вызов CAS(&val, val, newVal) будет успешным почти всегда, что для нас является ошибкой.
Теперь посмотрим, когда в методе dequeue происходит копирование данных (строка D11): перед исключением элемента из очереди (строка D12). Учитывая, что исключение элемента (продвижение m_Head в строке D12) может быт неудачным, копирование данных (D11) может быть многократным. С точки зрения C++, это означает, что данные, хранимые в очереди, не должны быть слишком сложными, иначе накладные расходы на оператор присвоения в строке D11 будут слишком велики. Соответственно, в условиях высокой нагрузки повышается вероятность неудачи примитива CAS. Попытка «оптимизировать» алгоритм выносом строки D11 за пределы цикла приведет к ошибке: элемент next может быть удален другим потоком. Так как рассматриваемая реализация очереди основана на схеме tagged pointer, в которой элементы никогда не удаляются, то такая «оптимизация» приведет к тому, что мы можем возвратить неправильные данные (не те, которые были в очереди на момент успешного выполнения строки D12).
MSQueue интересен тем, что m_Head всегда указывает на dummy node, а первым элементом непустой очереди является следующий за m_Head элемент. При dequeue из непустой очереди читается значение первого элемента, то есть m_Head.next, dummy-элемент удаляется, а новым dummy-элементом (и новой головой) становится следующий элемент, то есть тот самый, значение которого мы возвращаем. Получается, что физически удалить элемент можно только после следующей операции dequeue.Эта особенность может доставить много хлопот, если вы захотите использовать интрузивный вариант очереди
cds::intrusive::MSQueue. Epoch-based reclamation
Фразер [Fra03] предложил схему, основанную на эпохах. Применяется отложенное удаление в безопасный момент времени, когда есть полная уверенность, что ни один из потоков не имеет ссылок на удаленный элемент. Эту гарантию обеспечивают эпохи: есть глобальная эпоха nGlobalEpoch, а каждый поток работает в своей локальной эпохе nThreadEpoch. При входе в защищаемый epoch-based схемой код локальная эпоха потока инкрементируется, если она не превышает глобальную эпоху. Как только все потоки достигли глобальной эпохи, nGlobalEpoch инкрементируется.
Псевдокод схемы:
// Глобальная эпоха static atomic<unsigned int> m_nGlobalEpoch := 1 ; const EPOCH_COUNT = 3 ; // TLS data struct ThreadEpoch { // Локальная эпоха потока unsigned int m_nThreadEpoch ; // Список отложенных для удаления элементов List<void *> m_arrRetired[ EPOCH_COUNT ] ; ThreadEpoch(): m_nThreadEpoch(1) {} void enter() { if ( m_nThreadEpoch <= m_nGlobalEpoch ) m_nThreadEpoch = m_nGlobalEpoch + 1 ; } void exit() { if ( все потоки находятся в эпохе, следующей за m_nGlobalEpoch ) { ++m_nGlobalEpoch ; освобождаем (delete) элементы m_arrRetired[ (m_nGlobalEpoch – 2) % EPOCH_COUNT ] всех потоков ; } } } ; Освобождаемые элементы lock-free контейнера помещаются в локальный для потока список ожидающих удаления элементов m_arrRetired[m_nThreadEpoch % EPOCH_COUNT]. Как только все потоки перешли через глобальную эпоху m_nGlobalEpoch, все списки всех потоков эпохи m_nGlobalEpoch – 1 можно освобождать, а саму глобальную эпоху — инкрементировать.
Каждая операция lock-free контейнера заключена в вызовы ThreadEpoch::enter() и ThreadEpoch::exit(), что очень похоже на критическую секцию:
lock_free_op( … ) { get_current_thread()->ThreadEpoch.enter() ; . . . // lock-free операция контейнера. // Мы находимся внутри “критической секции” epoch-based схемы, // так что можем быть уверены, что никто не удалит данные, с которыми // мы работаем. . . . get_current_thread()->ThreadEpoch.exit() ; } Схема довольно простая и защищает локальные ссылки (то есть ссылки внутри операций контейнера) на элементы lock-free контейнеров. Защиту глобальных ссылок (извне операций контейнера) схема обеспечить не может, то есть концепцию итераторов по элементам lock-free контейнера с помощью epoch based-схемы не реализовать. Недостатком этой схемы является то, что все потоки программы должны перейти в следующую эпоху, то есть обратиться к какому-либо lock-free контейнеру; если хотя бы один поток не перейдет в следующую эпоху, удаление отложенных указателей не произойдет. Если приоритет потоков не одинаков, низкоприоритетные потоки могут повлечь бесконтрольный рост списка отложенных для удаления элементов высокоприоритетных потоков. Таким образом, epoch-based схема может привести (а в случае краха одного из потоков – обязательно приведет) к неограниченному расходу памяти.
Библиотека libcds не имеет реализации epoch-based схемы. Причина: мне не удалось построить достаточно эффективный алгоритм определения, все ли потоки достигли глобальной эпохи. Быть может, кто-нибудь из читателей порекомендует решение?..
Hazard pointer

Схема предложена Майклом [Mic02a, Mic03] и предназначена для защиты локальных ссылок на элементы lock-free структуры данных. Пожалуй, является наиболее известной и детально проработанной схемой отложенного удаления. Она основана только на атомарных чтении и записи и вовсе не использует «тяжелые» примитивы синхронизации типа CAS.
Краеугольным камнем схемы является обязанность объявлять указатель на элемент lock-free контейнера как hazard (опасные) внутри операции lock-free структуры данных, то есть прежде чем работать с указателем на элемент, мы обязаны поместить его в массив HP hazard-указателей текущего потока. Массив HP является приватным для потока: пишет в него только поток-владелец, читать могут все потоки (в процедуре Scan). Если внимательно проанализировать операции различных lock-free контейнеров, можно заметить, что размер массива HP (число hazard-указателей одного потока) не превышает 3 – 4, так что накладные расходы на поддержку схемы невелики.
cds::container::SkipListMap) – вероятностную структуру данных, по сути, список списков, с переменной высотой каждого элемента. Такие контейнеры не очень подходят для схемы Hazard Pointer, хотя в libcds есть реализация skip-list для этой схемы. Псевдокод схемы Hazard Pointers [Mic02]:
// Константы // P : число потоков // K : число hazard pointer в одном потоке // N : общее число hazard pointers = K*P // R : batch size, R-N=Ω(N), например, R=2*N // Per-thread переменные: // Массив Hazard Pouinter потока // Пишет в него только поток-владелец // читают все потоки void * HP[N] // текущий размер dlist (значения 0..R) unsigned dcount = 0; // массив готовых к удалению данных void* dlist[R]; // Удаление данных // Помещает данные в массив dlist void RetireNode( void * node ) { dlist[dcount++] = node; // Если массив заполнен – вызываем основную функцию Scan if (dcount == R) Scan(); } // Основная функция // Удаляет все элементы массива dlist, которые не объявлены // как Hazard Pointer void Scan() { unsigned i; unsigned p=0; unsigned new_dcount = 0; // 0 .. N void * hptr, plist[N], new_dlist[N]; // Stage 1 – проходим по всем HP всех потоков // Собираем общий массив plist защищенных указателей for (unsigned t=0; t < P; ++t) { void ** pHPThread = get_thread_data(t)->HP ; for (i = 0; i < N; ++i) { hptr = pHPThread[i]; if ( hptr != nullptr ) plist[p++] = hptr; } } // Stage 2 – сортировка hazard pointer'ов // Сортировка нужна для последующего бинарного поиска sort(plist); // Stage 3 – удаление элементов, не объявленных как hazard for ( i = 0; i < R; ++i ) { // Если dlist[i] отсутствует в списке plist всех Hazard Pointer’ов // то dlist[i] может быть удален if ( binary_search(dlist[i], plist)) new_dlist[new_dcount++] = dlist[i]; else free(dlist[i]); } // Stage 4 – формирование нового массива отложенных элементов. for (i = 0; i < new_dcount; ++i ) dlist[i] = new_dlist[i]; dcount = new_dcount; } При удалении RetireNode(pNode) элемента pNode lock-free контейнера поток j помещает pNode в локальный (для потока j) список dlist отложенных (требующих удаления) элементов. Как только размер списка dlist достигает R (R сравнимо с N = P*K, но более N; например, R = 2N), вызывается процедура Scan(), которая и занимается удалением отложенных элементов. Условие R > P*K является существенным: только при выполнении этого условия гарантируется, что Scan() сможет что-нибудь удалить из массива отложенных данных. Если это условие нарушено, Scan() может ничего не удалить из массива, и мы получим ошибку алгоритма – массив полностью заполнен, но уменьшить его размер невозможно.
Scan() состоит из четырех стадий.
- Сначала готовится массив
plistтекущих hazard-указателей, в который включаются все отличные отnullhazard-указатели всех потоков. Только первая стадия читает разделяемые данные — массивыHPпотоков, — остальные стадии работают только с локальными данными. - Стадия 2 сортирует массив
plist, чтобы оптимизировать последующий поиск; здесь же можно и удалить изplistэлементы-дубли. - Стадия 3 – собственно удаление: просматриваются все элементы массива
dlistтекущего потока. Если элементdlist[i]находится вplist(то есть какой-то поток работает с этим указателем, объявив его как hazard pointer), его удалять нельзя и он остаётся вdlist(переносится вnew_dlist). Иначе элементdlist[i]может быть удален – ни один поток не работает с ним. - Стадия 4 копирует неудаленные элементы из
new_dlistвdlist. Так какR > N, то процедураScan()обязательно уменьшит размер массиваdlist, то есть какие-то элементы обязательно будут удалены.
Объявление указателя как Hazard Pointer, как правило, выполняется следующим образом:
std::atomic<T *> atomicPtr ; … T * localPtr ; do { localPtr = atomicPtr.load(std::memory_order_relaxed); HP[i] = localPtr ; } while ( localPtr != atomicPtr.load(std::memory_order_acquire)); Мы читаем атомарный указатель atomicPtr в локальную переменную localPtr (с которой затем будем работать) и в свободный слот HP[i] массива HP hazard-указателей текущего потока. После этого следует проверить, что за время, пока мы читали atomicPtr, его значение не было изменено другим потоком, для чего мы вновь читаем atomicPtr и сравниваем его с ранее прочитанным значением localPtr. Так происходит до тех пор, пока мы не поместим в массив HP истинное (на момент объявления как hazard) значение atomicPtr. Пока указатель находится в массиве Hazard Pointer’ов (то есть объявлен как hazard), он не может быть физически удален никаким потоком, поэтому обращение по указателю не приведет к чтению мусора или записи в свободную область памяти.
Схема Hazard Pointer (HP-схема) детально проанализирована с точки зрения атомарных операций C++11 и memory ordering в работе [Tor08].
template <typename T> class MSQueue { struct node { std::atomic<node *> next ; T data; node(): next(nullptr) {} node( T const& v): next(nullptr), data(v) {} }; std::atomic<node *> m_Head; std::atomic<node *> m_Tail; public: MSQueue() { node * p = new node; m_Head.store( p, std::memory_order_release ); m_Tail.store( p, std::memory_order_release ); } void enqueue( T const& data ) { node * pNew = new node( data ); while (true) { node * t = m_Tail.load(std::memory_order_relaxed); // объявление указателя как hazard. HP – thread-private массив HP[0] = t; // обязательно проверяем, что m_Tail не изменился! if (t != m_Tail.load(std::memory_order_acquire) continue; node * next = t->next.load(std::memory_order_acquire); if (t != m_Tail) continue; if (next != nullptr) { // m_Tail указывает на последний элемент // продвигаем m_Tail m_Tail.compare_exchange_weak( t, next, std::memory_order_release); continue; } node * tmp = nullptr; if ( t->next.compare_exchange_strong( tmp, pNew, std::memory_order_release)) break; } m_Tail.compare_exchange_strong( t, pNew, std::memory_order_acq_rel ); HP[0] = nullptr; // обнуляем hazard pointer } bool dequeue(T& dest) { while true { node * h = m_Head.load(std::memory_order_relaxed); // Устанавливаем Hazard Pointer HP[0] = h; // Проверяем, что m_Head не изменился if (h != m_Head.load(std::memory_order_acquire)) continue; node * t = m_Tail.load(std::memory_order_relaxed); node * next = h->next.load(std::memory_order_acquire); // head->next также отмечаем как Hazard Pointer HP[1] = next; // Если m_Head изменился – начинаем все заново if (h != m_Head.load(std::memory_order_relaxed)) continue; if (next == nullptr) { // Очередь пуста HP[0] = nullptr; return false; } if (h == t) { // Помогаем методу enqueue – продвигаем m_Tail m_Tail.compare_exchange_strong( t, next, std::memory_order_release); continue; } dest = next->data; if ( m_Head.compare_exchange_strong(h, next, std::memory_order_release)) break; } // Обнуляем Hazard Pointers HP[0] = nullptr; HP[1] = nullptr; // Помещаем старую голову очереди в массив // готовых к удалению данных. RetireNode(h); } };
Является ли схема Hazard Pointer универсальной? То есть применима ли она для всех структур данных? В том виде, как она описана здесь, — нет. Причина проста: количество hazard pointer’ов ограничено константой K. Для большинства структур данных это условие – ограниченное количество hazard pointer – выполняется, причем, как было отмечено, число hazard-указателей обычно довольно мало. Но существуют алгоритмы, для которых невозможно априори оценить число одновременно требуемых hazard-указателей. Пример – отсортированный список Харриса [Har01]. В алгоритме удаления элемента этого списка может удаляться цепочка неопределенной длины, что делает HP-схему неприменимой.
Строго говоря, HP-схему можно обобщить на случай неограниченного числа hazard-указателей. Сам автор данной схемы дает достаточно подробные указания, как это сделать. Но я в libcds решил ограничиться классическим алгоритмом, дабы не усложнять и, как следствие, не утяжелять реализацию HP-схемы. Тем более что есть другая, менее известная схема — Pass the Buck, — которая довольно похожа на Hazard Pointer, но где изначально был заложен принцип неограниченного числа hazard-указателей. О ней я расскажу позже.
Реализация Hazard Pointer в libcds
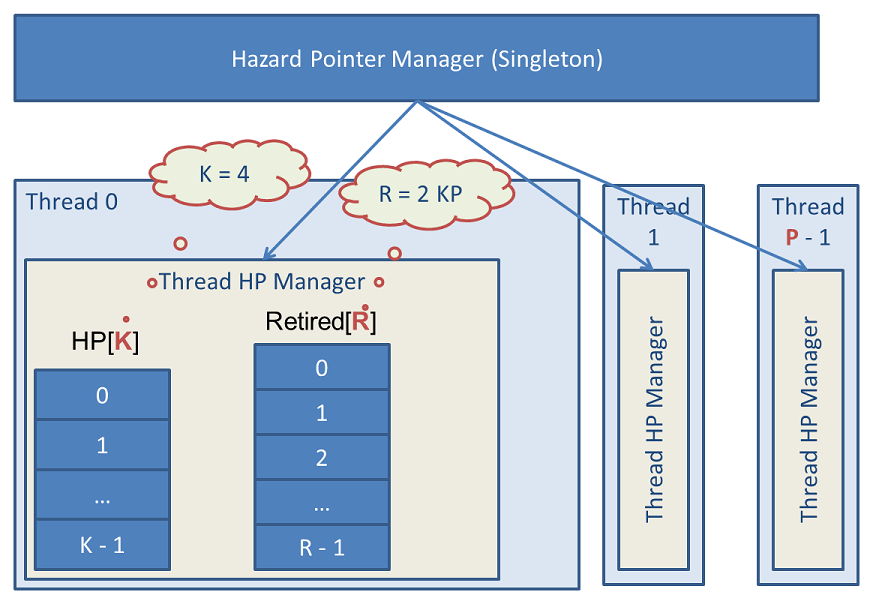
Этот рисунок демонстрирует внутреннее строение алгоритма hazard pointer в libcds. Ядро алгоритма – Hazard Pointer Manager — представляет собой синглтон, вынесенный динамическую библиотеку libcds.dll/.so. Каждый поток имеет объект — структуру Thread HP Manager, — в котором находится собственно массив HP hazard pointer’ов размера K и массив удаленных (отложенных) указателей Retired размером R. Все структуры Thread HP Manager связаны в список. Максимальное число потоков равно P. По умолчанию в libcds:
- Размер массива hazard-указателей
K = 8 - Число потоков
P = 100 - Размер массива отложенных (готовых к удалению) данных
R = 2 * K * P = 1600.
В libcds HP-схема реализована в виде трех уровней:
- Ядро – не зависящая от типа данных низкоуровневая реализация схемы (пространство имен
cds::gc::hzp). Так как ядро не типизировано (не зависит от типаTудаляемых данных), его можно вынести в динамическую библиотеку. Информация о типе данных здесь утеряна, так что мы не можем вызвать деструктор данных (точности ради следует отметить, что «удаление» – это не всегда физическое удаление. Например, для интрузивных контейнеров – это вызов функтора-диспозера, по сути – возбуждение события «данные могут быть безопасно удалены». Что за этим стоит, какой обработчик события, – мы не знаем). - Уровень реализации – типизированная реализация схемы, находится в пространстве имен
cds::gc::hzp. Этот уровень представляет собой набор шаблонных (template) структур-оболочек ядра, призванных сохранить типизацию данных (чем-то похоже на type erasure). Данный уровень не следует использовать в программах - Интерфейсный уровень (API) – класс
cds::gc::HP. Это то, что следует использовать (и используется) в lock-free контейнерах libcds, фактически, это значение (одно из, так как есть и другие схемы) параметраGCшаблона контейнера. С точки зрения кода классcds::gc::HP– это тонкая обертка вокруг уровня реализации с его множеством мелких классов.
struct retired_ptr { typedef void (* fnDisposer )( void * ); void * ptr ; // Отложенный указатель fnDisposer pDisposer; // Функция-диспозер retired_ptr( void * p, fnDisposer d): ptr(p), pDisposer(d) {} }; То есть хранится удаляемый (retired) указатель и функция его удаления. Метод Scan() HP-схемы вызывает pDisposer(ptr) для «удаления» элемента.
Функция pDisposer знает тип своего аргумента. За прозрачное формирование данной функции отвечает уровень реализации. Например, физическое удаление может быть произведено так:
template <typename T> struct make_disposer { static void dispose( void * p ) { delete reinterpret_cast<T *>(p); } }; template <typename T> void retire_ptr( T * p ) { // Помещаем p в массив arrRetired готовых к удалению данных // Заметим, что arrRetired – приватные данные потока arrRetired.push( retired_ptr( p, make_disposer<T>::dispose )); // Если массив заполнен – вызываем scan if ( arrRetired.full() ) scan(); } Это немного упрощенный подход, но суть, я думаю, ясна.
Если вы хотите использовать контейнеры на базе HP-схемы из библиотеки libcds, то достаточно просто объявить в main() объект типа cds::gc::HP и подключить его к каждому потоку, использующему контейнеры, основанные на HP-схеме, как я описал в предыдущей статье. Другое дело, если требуется написать собственный класс контейнера, основанный на cds::gc::HP. В этом случае надо знать API HP-схемы.
cds::gc::HP – статические, что подчеркивает, что класс является оберткой над синглтоном.
- Конструктор
HP(size_t nHazardPtrCount = 0, size_t nMaxThreadCount = 0, size_t nMaxRetiredPtrCount = 0, cds::gc::hzp::scan_type nScanType = cds::gc::hzp::inplace);nHazardPtrCount– максимальное число hazard pointer’ов (константа K схемы)
nMaxThreadCount– максимальное число потоков (константа P схемы)
nMaxRetiredPtrCount– размерность массива retired-указателей (константаR = 2KPсхемы)
nScanType– небольшая оптимизация: значениеcds::gc::hzp::classicуказывает, что следует точно следовать псевдокоду алгоритмаScan; значениеcds::gc::hzp::inplaceпозволяет избавиться вScan()от масиваnew_dlistи использовать вместо негоdlist(он ведь может только уменьшаться).Следует помнить, что объект
cds::gc::HPможет быть только один. Конструктор на самом деле вызывает статические функции инициализации ядра, так что попытка объявить два объекта классаcds::gc::HPне приведет к созданию двух схем Hazard Pointer, а лишь к повторной инициализации, что безопасно, но бесполезно. - Помещение указателя в массив retired (отложенное удаление) текущего потока
template <class Disposer, typename T> static void retire( T * p ) ; template <typename T> static void retire( T * p, void (* pFunc)(T *) )Аргумент
Disposer(илиpFunc) задают функтор удаления (диспозер). Вызов в первом случае довольно вычурный:struct Foo { … }; struct fooDisposer { void operator()( Foo * p ) const { delete p; } }; // Вызов диспозера myDisposer для указателя на Foo Foo * p = new Foo ; cds::gc::HP::retire<fooDisposer>( p ); -
static void force_dispose();Принудительный вызов алгоритма
Scan()схемы Hazard Pointer. Не знаю, зачем это может понадобиться в реальной жизни, но в тестах libcds это бывает необходимо.
Помимо этого, в классе cds::gc::HP объявлены три важных подкласса:
thread_gc– представляет собой обертку вокруг кода инициализации приватных для потока данных (thread data), относящихся к схеме Hazard Pointer. Этот класс предоставляет только конструктор, осуществляющий подключение HP-схемы к потоку, и деструктор, отключающий поток от схемыGuard– собственно hazard pointertemplate <size_t Count> GuardArray– массив hazard pointer’ов. При применении HP-схемы очень часто требуется объявить несколько hazard-указателей сразу. Более эффективно сделать это сразу одним массивом, а не несколькими объектами типаGuard
Классы Guard и GuardArray<N> представляют собой надстройку над внутренним массивом Hazard Pointer, приватным для потока. Они работают как аллокаторы из этого внутреннего массива.
Класс Guard суть hazard-слот и имеет следующее API:
-
template <typename T> T protect( CDS_ATOMIC::atomic<T> const& toGuard ); template <typename T, class Func> T protect( CDS_ATOMIC::atomic<T> const& toGuard, Func f );Объявление атомарного указателя (тип
T– обычно указатель) как hazard. Внутри этих методов скрыт цикл, который я описывал ранее: читается значение атомарного указателяtoGuard, присваивается hazard pointer’у и затем проверяется, что прочитанный указатель не изменился.
Второй синтаксис (с функторомFunc) необходим, если нам требуется объявить как hazard не сам указатель наT *, а некий производный от него указатель. Это специфика интрузивных контейнеров, в которых контейнер управляет указателями на узел (node), а указатель на реальные данные может от него отличаться (например,nodeможет являться полем реальных данных). ФункторFuncимеет такую сигнатуру:struct functor { value_type * operator()( T * p ) ; };Оба метода возвращают указатель, который они объявили как hazard.
-
template <typename T> T * assign( T * p ); template <typename T, int Bitmask> T * assign( cds::details::marked_ptr<T, Bitmask> p );Эти методы объявляют указатель p как hazard. Здесь, в отличие от
protect, нет никакого цикла, —pпросто помещается в hazard-слот.
Второй синтаксис предназначен для маркированных указателейcds::details::marked_ptr. В marked-указателях используются младшие 2-3 бита (которые всегда 0 на выравненных данных) в качестве хранилища битовых флагов, — очень распространенный прием в lock-free программировании. Данный метод помещает в hazard-слот указатель с обнуленными битами флагов (по маскеBitmask).
Методы возвращают указатель, который они объявили как hazard. -
template <typename T> T * get() const;Читаем значение текущего hazard-слота. Иногда это бывает нужно.
-
void copy( Guard const& src );Копирует значение hazard-слота из
srcвthis. В результате два hazard-слота содержат одно и то же значение. -
void clear();Обнуление значения hazard-слота. То е самое делает деструктор класса
Guard.
Класс GuardArray обладает аналогичным API, только указывается ещё индекс в массиве:
template <typename T> T protect(size_t nIndex, CDS_ATOMIC::atomic<T> const& toGuard ); template <typename T, class Func> T protect(size_t nIndex, CDS_ATOMIC::atomic<T> const& toGuard, Func f ) template <typename T> T * assign( size_t nIndex, T * p ); template <typename T, int Bitmask> T * assign( size_t nIndex, cds::details::marked_ptr<T, Bitmask> p ); void copy( size_t nDestIndex, size_t nSrcIndex ); void copy( size_t nIndex, Guard const& src ); template <typename T> T * get( size_t nIndex) const; void clear( size_t nIndex); Внимательный читатель заметит незнакомое CDS_ATOMIC – что это?
Это макрос, объявляющий подходящее пространство имен для std::atomic. Если компилятор поддерживает (и реализует) C++11 atomic, то CDS_ATOMIC есть std. Если не поддерживает – это cds::cxx11_atomics, пространство имен, в котором располагаются собственные libcds-велосипеды для atomic. В будущей версии libcds можно будет использовать boost.atomic, тогда CDS_ATOMIC будет равно boost.
Hazard Pointer with Reference Counter

Недостатком схемы Hazard Pointer является то, что она предназначена для защиты только локальных ссылок на узлы lock-free контейнера. Глобальные ссылки, требующиеся, например, для реализации концепции итераторов, она защитить не может: для этого потребовался бы в принципе неограниченный размер массива hazard-указателей.
На картинке — классическая древнегреческих статуя «Самсон, поражающий дубиной Бага, покровителя говнокода». Древнегреческие программисты считали, что подсчет ссылок — универсальный инструмент, избавляющий от всех ошибок. Сейчас мы знаем, что древние ошибались.
Самым известным методом распознания, используется объект или нет, является метод подсчета ссылок на объект (reference counting, RefCount). В работах Valois – одного из пионеров lock-free подхода — именно схема на подсчете ссылок использовалась для безопасного удаления элементов контейнера. Но RefCount-схема имеет свои недостатки, главный из которых – трудность реализации циклических структур данных, когда элементы ссылаются друг на друга. Кроме того, многие исследователи отмечают неэффективность RefCount-схемы, так как её lock-free реализация слишком часто использует примитивы fetch-and-add (фактически, перед каждым использованием указателя следует увеличить счетчик ссылок на него, а после – декрементировать).
Исследовательская группа университета Гётеборга опубликовала в 2005 году работу [GPST05], в которой методы Hazard Pointer и RefCount объединены: схема Hazard Pointers используется для эффективной защиты локальных ссылок внутри операций lock-free структуры данных, а схема RefCount – для защиты глобальных ссылок и сохранения целостности структуры данных. Назовем для краткости эту схему HRC (Hazard pointer RefCounting).
Применение Hazard Pointers позволило избежать тяжелых операций инкрементирования / декрементирования числа ссылок на элемент при защите локальных ссылок, что значительно увеличило производительность RefCounting-схемы в общем. С другой стороны, применение сразу двух подходов несколько усложнило алгоритм объединенной схемы (из-за обилия технических деталей я не привожу её полный псевдокод, см. [GPST05]). Если схема Hazard Pointers не требует никакой специальной поддержки со стороны самих элементов lock-free контейнера, то HRC полагается на наличие для элемента двух вспомогательных методов:
void CleanUpNode( Node * pNode); void TerminateNode( Node * pNode); Процедура TerminateNode обнуляет внутри элемента pNode все указатели на другие элементы контейнера. Процедура CleanUpNode используется для того, чтобы быть уверенным, что элемент pNode ссылается только на «живые» (не помеченные для удаления) элементы структуры данных, изменяя (продвигая) ссылки в случае необходимости; так как каждая ссылка в RefCount-контейнере сопровождается увеличением счетчика ссылок элемента, на который ссылаемся, то CleanUpNode ещё и уменьшает счетчики ссылок удаленных элементов:
void CleanUpNode(Node * pNode) { for (all x where pNode->link[x] of node is reference-counted) { retry: node1 = DeRefLink(&pNode->link[x]); // устанавливает HP if (node1 != NULL and !is_deleted( node1 )) { node2 = DeRefLink(node1->link[x]); // устанавливает HP // Меняем ссылку, а заодно и декрементируем счетчик ссылок // на старый элемент node1 CompareAndSwapRef(&pNode->link[x],node1,node2); ReleaseRef(node2); // очищает HP ReleaseRef(node1); // очищает HP goto retry; // новая ссылка также может быть уже удаленной, поэтому повторяем } ReleaseRef(node1); // очищает HP } } Благодаря такому переносу акцентов управления lock-free контейнером из ядра схемы на сам элемент контейнера (что хорошо ложится на виртуальные функции C++) само ядро схемы HRC становится независимым от конкретной реализуемой lock-free структуры данных. Заметим, однако, что алгоритм CleanUpNode может краткосрочно нарушить целостность структуры данных, так как изменяет ссылки внутри элемента по одной, что может быть в некоторых случаях неприемлемо. Для lock-free контейнеров, для которых такое нарушение недопустимо, можно использовать программную эмуляцию MultiCAS для атомарного изменения всех связей в элементе.
Так же, как и для Hazard Pointers схемы, число отложенных элементов ограничено сверху. Алгоритм физического удаления очень похож на алгоритм Scan схемы Hazar Pointers (с некоторыми изменениями, связанными с управлением счетчиками ссылок и вызовом CleanUpNode). Основное отличие состоит в следующем: если в схеме Hazard Pointers нам гарантируется (выбором R > N = P * K), что процедура Scan обязательно удалит что-нибудь (то есть существует хотя бы один отложенный элемент, не защищенный hazard-указателем), то в схеме HRC вызов процедуры Scan может быть неудачным из-за взаимных ссылок элементов друг на друга (каждая ссылка – это инкремент счетчика). Поэтому, в случае неудачи Scan, вызывается вспомогательная процедура CleanUpAll: она пробегает по всем массивам отложенных указателей всех потоков и вызывает для каждого удаленного элемента процедуру CleanUpNode, тем самым делая успешным повторный вызов Scan.
cds::gc::HRC. API этого класса полностью аналогичен API cds::gc::HP. Детали реализации расположены в namespace cds::gc::hrc.Главное преимущество HRC-схемы – возможность воплотить концепцию итераторов – не реализована в libcds. В процессе работы над библиотекой я пришел к выводу, что в общем случае итераторы в принципе не применимы к lock-free контейнерам. Итераторы предполагают не только безопасное обращение к объекту, на который указывает итератор, но и безопасный и полный обход всего контейнера. Последнее условие – полный обход – в lock-free контейнерах обеспечить в общем случае невозможно: всегда найдется поток-конкурент, удаляющий элемент, на котором позиционируется итератор. В результате, безопасно обратиться к полям узла можно, так как узел защищен HP-схемой и не может быть физически удален, но получить следующий элемент уже невозможно, — узел может быть уже исключен из lock-free контейнера.
Таким образом, HRC-схема представлена в libcds как специфический случай реализации HP-схемы. На её примере можно убедиться, насколько введение дополнительных условий (счетчика ссылок) утяжеляет HP-схему: на тестовых примерах HRC-контейнер может быть в 2-3 раза медленней, чем HP-контейнер. Плюс можно увидеть «подвисания», свойственные полноценным сборщикам мусора: при невозможности удалить что-либо в вызове
Scan (например, из-за циклических ссылок) запускается тяжелая процедура CleanUpAll, пробегающая по всем retired-узлам.Так что HRC-схема используется в libcds как разновидность HP-like схем, позволяющая при проектировании не забывать об общности. В силу специфического внутреннего строения HRC-схемы обобщение HRC-based и HP-based контейнеров иногда представляет собой очень интересную задачу.
Pass the Buck

Работая над проблемой освобождения памяти в lock-free структурах данных, Herlihy & al изобрели алгоритм Pass-the-Buck (PTB, идиома “свалить вину”) [HLM02, HLM05], по сути очень похожий на HP-схему М.Майкла, но существенно отличающийся в деталях реализации.
Так же, как в HP-схеме, PTB-схема требует объявлять указатель защищенным (guarded, аналог hazard pointer в HP-схеме). PTB-схема изначально рассчитана на заранее неопределенное число защитников (то есть hazard pointer’ов). При накоплении достаточного числа готовых к удалению (retired) данных вызывается процедура Liberate — аналог Scan в HP-схеме. Liberate возвращает массив указателей, которые можно безопасно удалить. В отличие от HP-схемы, где массив retired-указателей является приватным для потока, в PTB-схеме массив готовых к удалению данных является единым для всех потоков.
Интересно строение guard’а (hazard pointer’а): он содержит не только собственно защищаемый указатель, но и указатель на retired-данные, так называемый hand-off (“руки прочь”). Если в процессе удаления процедура Liberate обнаруживает, что некие retired-данные из общего массива готовых к удалению данных защищены guard’ом, она помещает эту retired-запись в слот hand-off guard’а. При следующем вызове Liberate hand-off данные могут быть удалены, если guard, к которому они прикреплены, изменился, то есть уже содержит указатель на другие защищаемые данные.
Авторы в [HLM05] приводят два алгоритма для Liberate: wait-free и lock-free. Wait-free алгоритм требует dwCAS (CAS над двойным словом), что делает алгоритм зависящим от поддержки dwCAS на целевой платформе. Lock-free алгоритм интересен тем, что может работать только при изменении данных. Если данные (guard’ы и retired-указатели) остаются неизменными между вызовами lock-free версии Liberate, возможно зацикливание (точнее, алгоритм не удалит все возможные retired-данные, поэтому его нужно будет вызывать ещё и ещё). Ситуация неизменности данных наступает в конце программы, когда в деструкторе синглтона PTB-схемы происходит чистка, в том числе вызывается Liberate.
Изрядно помучившись в свое время с зацикливанием, я решил изменить алгоритм Liberate PTB-схемы, сделав его по аналогии с HP-схемой. В результате реализация PTB в libcds стала более похожей на вариант HP-схемы с произвольным числом hazard-указателей и единым массивом retired-данных. На производительности это сказалось слабо: «чистая» HP-схема все же немного быстрее, чем PTB, но PTB может быть предпочтительнее за счет отсутствия ограничений на количество guard’ов.
cds::gc::PTB, детали реализации находятся в namespace cds::gc::ptb. API класса cds::gc::PTB полностью аналогичен cds::gc:::HP, за исключением аргументов конструктора. Конструктор принимает следующие аргументы:
PTB( size_t nLiberateThreshold = 1024, size_t nInitialThreadGuardCount = 8 );
nLiberateThreshold— порог вызоваLiberate. Как только общий массив retired-данных достигнет этого размера, вызываетсяLiberatenInitialThreadGuardCount— начальное число quard’ов при создании потока (точнее, при подсоединении потока к внутренней инфраструктуре libcds). В последующем в случае нехватки guard’ов автоматически создаются новые
Заключение
В этой статье я дал обзор известных мне алгоритмов safe memory reclamation, сделав особый упор на схемы типа Hazard Pointer. HP-схема и её разновидности предоставляют неплохой способ обеспечения безопасного управления памятью в lock-free структурах данных.
Все вышенаписанное относится более к области создания lock-free структур данных. Если вы просто используете библиотеку libcds, то достаточно только инициализировать выбранную схему, не забывать подключать (attach) потоки к схеме и подставлять класс схемы в качестве первого аргумента GC контейнера из библиотеки libcds. Защита ссылок, вызов Scan() / Liberate() и пр. — всё это уже зашито внутри реализации контейнера.
За бортом остался ещё один интересный алгоритм — RCU, отличающийся от HP-like схем, — но о нем я расскажу в одной из следующих статей.
[GPST05] Anders Gidenstam, Marina Papatriantafilou, Hakan Sundell, Philippas Tsigas Practical and Efficient Lock-Free Garbage Collection Based on Reference Counting, Technical Report no. 2005-04 in Computer Science and Engineering at Chalmers University of Technology and Goteborg University, 2005
[Har01] Timothy Harris A pragmatic implementation of Non-Blocking Linked List, 2001
[HLM02] M. Herlihy, V. Luchangco, and M. Moir The repeat offender problem: A mechanism for supporting
dynamic-sized lockfree data structures Technical Report TR-2002-112, Sun Microsystems
Laboratories, 2002.
[HLM05] M.Herlihy, V.Luchangco, P.Martin, and M.Moir Nonblocing Memory Management Support for Dynamic-Sized Data Structure, ACM Transactions on Computer Systems, Vol. 23, No. 2, May 2005, Pages 146–196.
[Mic02] Maged Michael Safe Memory Reclamation for Dynamic Lock-Free Objects Using Atomic Reads and Writes, 2002
[Mic03] Maged Michael Hazard Pointers: Safe Memory Reclamation for Lock-Free Objects, 2003
[MS98] Maged Michael, Michael Scott Simple, Fast and Practical Non-Bloking and Blocking Concurrent Queue Algorithms, 1998
[Tor08] Johan Torp The parallelism shift and C++’s memory model, chapter 13, 2008
ссылка на оригинал статьи http://habrahabr.ru/company/ifree/blog/202190/
Добавить комментарий