
Данная статья повествует о пользе низкоуровневых вычислений
на примере атласа звездных объектов 2MASS.
2MASS — это ~471 млн. объектов, для которых приведены координаты,
а также сопутствующая информация, всего 60 атрибутов.
Физически — это 50Гб исходных гзипнутых текстовых файлов.
Можно ли работать с такой базой, не прибегая к «тяжелой артиллерии»?
Давайте попробуем.
Прелюдия
Данная работа проводилась в 2009 году и была частью усилий компании DataEast по созданию собственной ГеоСУБД.
Ставилась цель отладить, отпрофилировать и сделать benchmark процессора запросов.
В качестве языка запросов был выбран диалект Turorial D, точнее его часть, касающаяся реляционной алгебры. Диалект был адаптирован под требования реальной жизни, в частности, добавлена возможность работы с курсорами.
Впрочем, это просто контекст и цель данного поста не рассказ о былых победах, что «растаяли, как слёзы под дождем», а демонстрация техники максимального переноса вычислений непосредственно в курсор СУБД.
Конечно, применить данную технику можно и средствами PL/SQL при помощи хранимых процедур и/или используя агрегаты.
Введение
Нет смысла подробно останавливаться на процессе подготовки данных, скажем просто, что заняло это 8ч 26мин на заливку данных и 1ч 17мин на пространственную индексацию.
В комплекте с исходными данными идет проверочный запрос
select count(*) as rows, sum(pts_key::bigint) as sum_pts_key, sum(pxcntr::bigint) as sum_pxcntr, sum(scan_key::bigint) as sum_scan_key, sum(scan::bigint) as sum_scan, sum(ext_key::bigint) as sum_ext_key, sum(coadd_key::bigint) as sum_coadd_key, sum(coadd::bigint) as sum_coadd, sum(mp_flg) as sum_mp_flg, sum(gal_contam) as sum_gal_contam, sum(use_src) as sum_use_src, sum(dup_src) as sum_dup_src, sum(nopt_mchs) as sum_nopt_mchs, sum(phi_opt::bigint) as sum_phi_opt, sum(dist_edge_ew::bigint) as sum_dist_edge_ew, sum(dist_edge_ns::bigint) as sum_dist_edge_ns, sum(err_ang::bigint) as sum_err_ang FROM twomass_psc; В нашем случае этот запрос будет выглядеть как
select "PSC" chew { "rows" INTEGER, "sum_pts_key" INTEGER, "sum_pxcntr" INTEGER, "sum_scan_key" INTEGER, "sum_scan" INTEGER, "sum_ext_key" INTEGER, "sum_coadd_key" INTEGER, "sum_coadd" INTEGER, "sum_mp_flg" INTEGER, "sum_gal_contam" INTEGER, "sum_use_src" INTEGER, "sum_dup_src "INTEGER, "sum_nopt_mchs" INTEGER, "sum_phi_opt" INTEGER, "sum_dist_edge_ew" INTEGER, "sum_dist_edge_ns" INTEGER, "sum_err_ang" INTEGER } hook "init" { "rows" := 0; "sum_pts_key" := 0; ... "sum_err_ang" := 0; } hook "row" { "rows" := "rows" + 1; if (not isnull("pts_key/cntr")) then "sum_pts_key" := "sum_pts_key" + "pts_key/cntr"; end if; ... if (not isnull("err_ang")) then "sum_err_ang" := "sum_err_ang" + "err_ang"; end if; } hook "finit" { call __interrupt (); }; Результат выполнения таков:
INFO: start [04/Jun/2009:09:37:45:822] ----------------------------------------------------------------- rows sum_pts_key sum_pxcntr sum_scan_key sum_scan sum_ext_key sum_coadd_key sum_coadd sum_mp_flg sum_gal_contam sum_use_src sum_dup_src sum_nopt_mchs sum_phi_opt sum_dist_edge_ew sum_dist_edge_ns sum_err_ang ----------------------------------------------------------------- 470992970 306810325437475788 306815556538478936 16902776758555 32666066948 2048692118201 388758631396659 64617139213 16048 729878 464456155 79798372 369187043 64916239773 69388217174 2670725813652 29279563815 ----------------------------------------------------------------- INFO: stop [04/Jun/2009:12:35:59:571] Здесь оператор chew использован для преобразования исходного потока данных (вся таблица) в синтетический с определенными полями, которые становятся локальными переменными. Оператор hook использован (аналогично агрегатам SQL) для подписки на события — старт/стоп потока и получение строки. При вызове __interrupt текущие значения локальных переменных попадают в resultset.
Результаты совпадают с проверочными, значит данные подготовлены к работе.
Время работы — 3 часа, около 10 мин на колонку при сплошном просмотре. Такая скорость (на Intel Core2 P4-2.4 GHz, 2Gb, disk ST3400620AS) характерна для всех дальнейших запросов. С другой стороны, если бы мы распаковывали исходные текстовые файлы и обрабатывали их через GAWK, например, у нас бы ушло 50Гб по 50 мб/сек = 1000 секунд на чтение данных и столько же на распаковку, 35 минут только лишь на организацию потока. На распаковку и прогон всех данных через wc уходило полтора часа. BigData всё же.
Для желающих увидеть всё своими глазами, приводится кусочек неба с дефектом пластины:

Кое-кто принимает его за боевые порядки имперского флота.
Data mining
Простая статистика. Max, Min, Avg — поиграемся с колонкой «j-m» (Default J-band magnitude).
select "PSC" chew { "nrows" INTEGER, "nulls_j_m" INTEGER, "num_j_m" INTEGER, "sum_j_m" RATIONAL, "avg_j_m" RATIONAL, "max_j_m" RATIONAL, "min_j_m" RATIONAL } hook "init" { "nrows" := 0; "nulls_j_m" := 0; "num_j_m" := 0; "sum_j_m" := 0; "avg_j_m" := 0; "max_j_m" := -1e66; "min_j_m" := 1e66; } hook "row" { nrows := nrows + 1; if (isnull("j_m")) then "nulls_j_m" := "nulls_j_m" + 1; else "num_j_m" := "num_j_m" + 1; "sum_j_m" := "sum_j_m" + "j_m"; if ("max_j_m"<"j_m") then "max_j_m" := "j_m"; end if; if ("min_j_m">"j_m") then "min_j_m" := "j_m"; end if; end if; } hook "finit" { "avg_j_m" := "sum_j_m" / "num_j_m"; call __interrupt (); }; Результат:
INFO: start [04/Jun/2009:15:00:54:821] -------------------------------------------------------------------- nrows nulls_j_m num_j_m sum_j_m avg_j_m max_j_m min_j_m -------------------------------------------------------------------- 470992970 19 470992951 7.15875e+009 15.1993 25.86 -2.989 -------------------------------------------------------------------- INFO: stop [04/Jun/2009:15:18:47:743] Дисперсия:
select "PSC" chew { "nrows" INTEGER, "nulls_j_m" INTEGER, "num_j_m" INTEGER, "disp_j_m" RATIONAL } hook "init" { "nrows" := 0; "nulls_j_m" := 0; "num_j_m" := 0; "disp_j_m" := 0; var tmp rational; var tavg rational; tavg := 15.1993; -- previously calculated } hook "row" { nrows := nrows + 1; if (isnull("j_m")) then "nulls_j_m" := "nulls_j_m" + 1; else "num_j_m" := "num_j_m" + 1; tmp := "j_m" - tavg; tmp := tmp * tmp; "disp_j_m" := "disp_j_m" + tmp; end if; } hook "finit" { "disp_j_m" := "disp_j_m" / "num_j_m"; call __interrupt (); }; Результат:
INFO: start [04/Jun/2009:15:48:27:274] -------------------------------------------------------------------- nrows nulls_j_m num_j_m disp_j_m -------------------------------------------------------------------- 470992970 19 470992951 1.98223 -------------------------------------------------------------------- INFO: stop [04/Jun/2009:16:05:01:946 Гистограмма:
select "PSC" chew { "j_m_cell" rational, "num" INTEGER } hook "init" { var tmp integer; var tmp2 integer; var tmax rational; tmax := 26.; -- previously calculated var tmin rational; tmin := -5.; -- previously calculated var ncells integer; ncells := 500; var tcell rational; tcell := (tmax - tmin)/ncells; var htptr integer; htptr := hti_alloc (0); call hti_set (htptr, 0, 0); } hook "row" { if (not isnull("j_m")) then tmp := ("j_m" - tmin)/tcell; tmp2 := hti_get (htptr, tmp); tmp2 := tmp2 + 1; call hti_set (htptr, tmp, tmp2); end if; } hook "finit" { tmp := 0; while tmp < ncells; begin; "j_m_cell" := tmin + tcell * tmp + tcell * 0.5; "num" := hti_get (htptr, tmp); tmp := tmp + 1; call __interrupt (); end; end while; call hti_free (htptr); }; Накопление в ячейках гистограммы происходит с помощью хэш таблицы за отсутствием массивов в языке. В данном случае результатом будет распечатка ячеек гистограммы, которую удобно смотреть через gnuplot.В нижеследующей картинке добавлены также распечатки по колонкам «k-m»(Default Ks-band magnitude) и «h-m»(Default H-band magnitude).
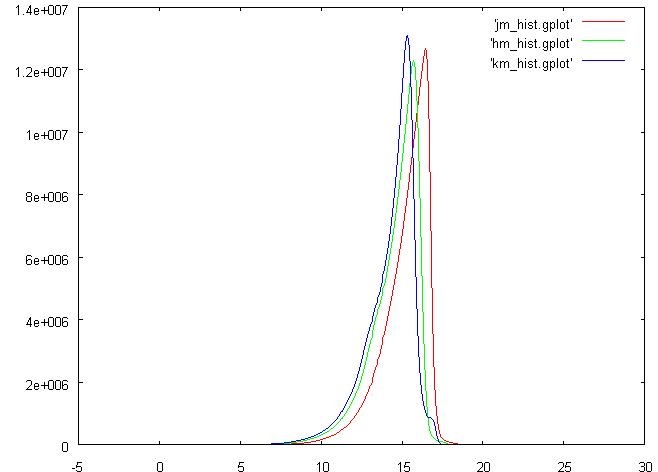
3D
Хорошо, «k-m» и «h-m» на гистограмме выглядят очень похоже, а как насчет совместного распределения?
select "PSC" chew { "cell" rational, "num" INTEGER } hook "init" { var tmp integer; var tmp2 integer; var tmp4 integer; var tmax rational; tmax := 25; var tmin rational; tmin := -5.; var ncells integer; ncells := 512; var tcell rational; tcell := (tmax - tmin)/ncells; var "hnd" integer; hnd:= img_create ( ncells, ncells, tmin, tmin, tmax, tmax, 1); var cl integer; cl := img_alloc_color (hnd, 255,0,0); } hook "row" { if ((not isnull("h_m")) and (not isnull("k_m"))) then tmp := img_get_point (hnd, "h_m", "k_m"); tmp := tmp + 1; call img_draw_point (hnd, "h_m", "k_m", tmp); end if; } hook "finit" { tmp := 0; while tmp < ncells; begin; tmp2 := 0; while tmp2 < ncells; begin; tmp4 := img_get_point (hnd, tmin + tcell * tmp, tmin + tcell * tmp2); call print ((tmin + tmp * tcell)+' '+ (tmin + tmp2* tcell)+' '+tmp4+'\n'); if tmp4 > 0 then tmp4 := cl; else tmp4 := 0; end if; call img_draw_point (hnd, tmin + tcell * tmp, tmin + tcell * tmp2, cl); tmp2 := tmp2 + 1; end; end while; tmp := tmp + 1; end; end while; call img_saveas (hnd, 'stat4.gif'); call img_destroy (hnd); }; В данном примере для хранения двумерной гистограммы использовался образ картинки, полученный посредством плагина к GD, просмотр логарифмов попаданий в клетки осуществляется опять же средствами gnuplot в режиме pm3d.
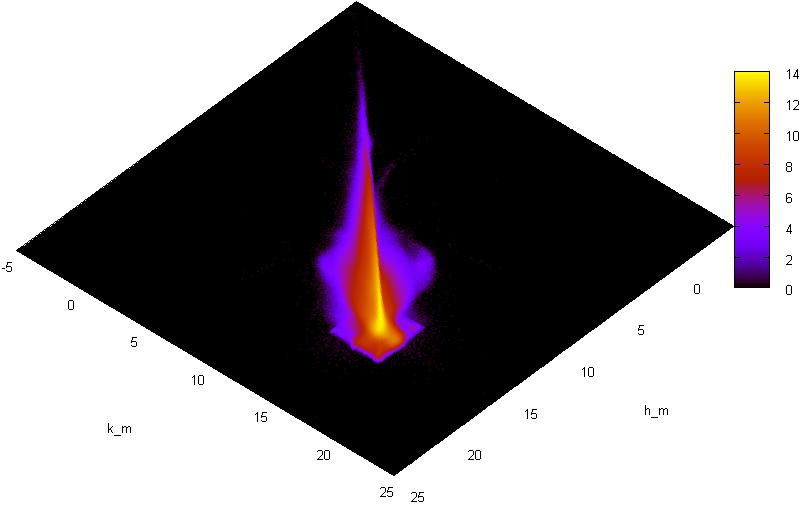
Аналогичная картинка для распределения “j_m“-“k_m“ против “h_m“-“k_m“:

Построение этих гистограмм занимает ~35мин — по 12 мин на колонку.
А что, если нам надо построить такое распределение по конкретной пространственной области? Можем ли мы сделать это за секунды? Конечно:
Выборка с пространственными ограничениями.
select "PSC" where sp_overlap ("Point", [rational:xmin], [rational:ymin], [rational:xmax], [rational:ymax]) chew { "m_cell" rational, "num" INTEGER } … -- below is the same text Добавление sp_overlap изменило исходный поток идентификаторов от таблицы к пространственному индексу.
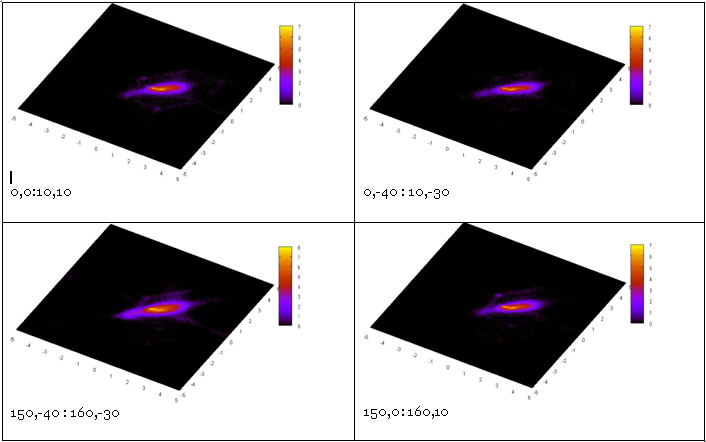
В нижних левых углах клеток указаны экстенты выборок.
А как насчет атрибутивных ограничений?
Это так же легко, как и ограничить по пространству.
select "PSC" where “j_snr” < 10. -- or you may combine your restrictions adding -- and sp_overlap ("Point", … ) chew { "m_cell" rational, "num" INTEGER } … -- below is the same text А вот и результат.
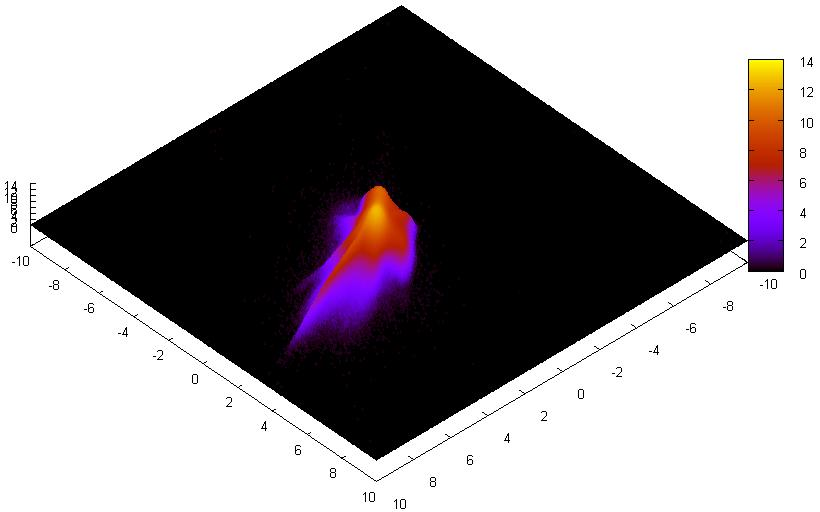
Итого
Что дает нам перенос вычислений в курсор?
- скорость, обрабатывая прочитанные данные на месте, мы свободны от того, чтобы их сериализовывать, отправлять по сети, принимать, десериализовывать…
- сохраненные ресурсы, например, полмиллиарда строк, будучи отправленными по сети, надолго займут изрядную долю ее пропускной способности
А чем нам грозит такая техника?
- Придется всё делать самим, а это потенциальный источник ошибок.
- Алгоритмы, в которых действительно много вычислений не очень удобно выполнять на общем сервере.
- Не все вычисления можно делать в потоке.
Всё так, но автор не утверждает, что так надо делать всегда, это лишь один из многих инструментов для работы с данными, пусть и удобный, особенно для исследовательской части работы, например, когда надо быстро проверять и модифицировать гипотезы.
ссылка на оригинал статьи http://habrahabr.ru/post/204254/
Добавить комментарий