Эта статья также назрела ввиду того, что многие крупные интернет-проекты рунета в 2014 году получили письма счастья от Google Analytics с предложением заплатить $150 000 за возможность использовать их продукт. Я лично считаю, что ничего плохого в том, чтобы оплатить труд программистов и администраторов нет. Но при этом это довольно серьезные инвестиции, и, может, вложения в собственную инфраструктуру и специалистов, даст большую гибкость в дальнейшем.
Аналитика в ElasticSearch основана на полнотекстовом поиске и фасетах. Фасеты в поиске — это некая агрегация по определенному признаку. Вы часто сталкивались с фасетами-фильтрами в интернет-магазинах: в левой или правой колонке есть уточняющие галочки. Ниже пример тестового фасетного поиска у нас на главной странице http://indexisto.com/.
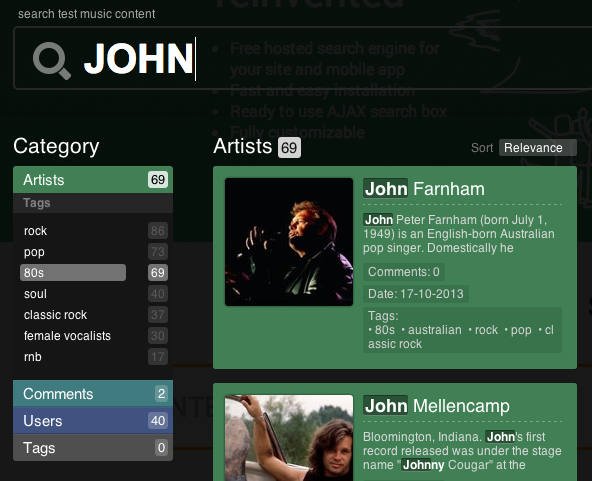
Буквально неделю назад вышла стабильная версия поискового сервера ElasticSearch 1.0, в которой разработчики настолько серьезно поработали над фасетами, что даже назвали их Aggregation.
Так как тема еще не освещалась на Хабре, я хочу рассказать, что из себя представляют аггрегации в ElasticSearch, какие возможности открываются и есть ли жизнь без Hadoop.
Во-первых, я хотел бы привести статистику из Google Trends, которая наглядно показывает, насколько велик интерес к ElasticSearch:

Дело здесь, конечно, не в том, что это поисковый сервер с морфологией и прочими плюшками. Основное — это легкая масштабируемость на больших объемах данных. Данные сами разъезжаются по шардам (логическое разбиение индекса), а шарды по нодам (серверам). Потом шарды еще и реплицируются по другим нодам, чтобы пережить падение серверов и для быстродействия запросов. Думать приходится, в основном, во время проработки схемы индексов.
Распределенные вычисления
Запрос исполняется на кластере параллельно, на тех шардах, в кототорых лежит интересующий индекс. Шарды — это, по сути, старые добрые Lucene-индексы. Все, что делает ElasticSearch, это принимает запрос, определяет ноды, где лежат шарды индекса, к которому пришел запрос, рассылает запрос на эти шарды, шарды считают и отсылают результаты ноде-инициатору. Нода-инициатор уже делает свертку и отсылает клиенту. По потокам данных это похоже на map reduce, когда индексы Lucene — это mapper’ы, а нода-инициатор — это reducer.
Некоторые запросы могут выполниться в один проход, некоторые в несколько. Например, чтобы посчитать стандартную текстовую релевантность tf/idf, основанную на частоте терма в документе (tf) и в коллекции документов (idf), очевидно, надо сначала получить idf с учетом всех шардов (первый запрос к шардам), и потом уже сделать основной запрос (второй). Хотя для скорости можно idf посчитать и локально на шарде.
Сделаем фасетный запрос «Сколько же было ошибок в логах по годам». Этот запрос ищет ERROR в документах логов, и делает фасеты по годам.
Вот так, примерно, выглядят потоки данных:

Нода, к которой пришел запрос, исполнила его сама (так как на ней есть один из шардов нужного индекса) и разослала на другие ноды, где содержатся другие шарды индекса. Каждый шард исполняет примерно такую последовательность в индексе:
- определить максимальное и минимальное значение в поле date. Lucene не хранит внутри даты или числа — все в текстовом представлении.
- подготовить нужные диапазоны дат в соответствии с тем, какое разбиение нужно пользователю. У нас это 1 год. Если логи есть за 2 года то получится 2 запроса
- пройтись по инвертированному индексу и посчитать все документы (записи в лог), которые содержат ERROR и попадают в текущий диапазон. Сделать такой запрос для всех диапазонов.
Небольшая справка по Lucene. Range запросы по «числам» в текстовом представлении очень эффективны NumericRangeQuery:
Comparisons of the different types of RangeQueries on an index with about 500,000 docs showed that TermRangeQuery in boolean rewrite mode (with raised BooleanQuery clause count) took about 30-40 secs to complete, TermRangeQuery in constant score filter rewrite mode took 5 secs and executing this class took <100ms to complete Переходим к практике. Подготовим данные
Так как сейчас мы просто посмотрим, что можно нааггрегировать в ElasticSearch, то не будем гнаться за объемами, а заведем индекс habr и добавим в него 20 постов.
Посты будут вот такой структуры:
{ "user": "andrey", "title": "Android заголовок 1", "body": "Android тело 1", "postDate": "2011-02-15T11:12:12", "tags": ["взрыв"], "rank": 67, "comments": 21 } Я создал 10 постов про Android и 10 постов про iPhone.
Посты могут иметь один или несколько тегов из набора
- взрыв
- обновление
- приложение
- баг
Годы постов от 2011 до 2014. Рейтинг от 0 до 100. Кол-во комментариев аналогично.
Вот что у нас в индексе в итоге:

Old-school-анализ (до версии ES 1.0)
Распределение тегов в постах про Android
Сразу на практике покажем, что можно проанализировать, сочетая полнотекстовый поиск и фасеты. Делаем поисковый запрос android к полю Title и фасетный запрос по полю tags:
{ "query": { "wildcard": { "title": "Android*" } }, "facets": { "tags": { "terms": { "field": "tags" } } } } В ответ получаем:
"facets": { "tags": { "_type": "terms", "missing": 0, "total": 18, "other": 0, "terms": [ { "term": "обновление", "count": 5 }, { "term": "баг", "count": 5 }, { "term": "приложение", "count": 4 }, { "term": "взрыв", "count": 4 } ] } } Ну и для сравнения то же самое, но если мы ищем посты про iPhone:
"facets": { "tags": { "_type": "terms", "missing": 0, "total": 16, "other": 0, "terms": [ { "term": "взрыв", "count": 5 }, { "term": "баг", "count": 5 }, { "term": "приложение", "count": 4 }, { "term": "обновление", "count": 2 } ] } } Как видно из аналитики, айфоны чаще взрываются, а андроиды обновляются.
Гистограмма распределения постов про iPhone по годам
Еще один пример, на котором мы рассмотрим, как менялся интерес к айфонам со временем. Запрос iPhone, фасеты по полю postDate:
{ "query": { "wildcard": { "title": "iPhone" } }, "facets": { "articles_over_time": { "date_histogram": { "field": "postDate", "interval": "year" } } } } Ответ:
"facets": { "articles_over_time": { "_type": "date_histogram", "entries": [ { "time": 1293840000000, "count": 2 }, { "time": 1325376000000, "count": 4 }, { "time": 1356998400000, "count": 2 }, { "time": 1388534400000, "count": 2 } ] } } Как видно, всплеск интереса пришелся на 2012 год (в ответе timestamp’ы).
Примерно понятно, как это работает. Основные типы фасетов в ElasticSearch
- term — удобно на полях типа tags. Не очень рекомендуется строить term-фасет по терминам из «Войны и мира»
- range — фасеты по диапазону значений числовых полей и дате. Можно сделать фасет: посчитай мне все товары с ценой от 0 до 100 и от 100 до 200
- histogram — это те же самые range-запросы, только диапазоны задаются автоматически, указывается шаг разбиения. Работает по числовым полям и дате. Не стоит делать гистограмму с шагом в 1 миллисекунду за 100 лет
Сочетая фасеты и полнотекстовые запросы, можно получать множество разных выборок.
Аналитика в ES 1.0 — new school!
Как вы заметили, фасеты в ES до версии 1.0 просто возвращали число документов. Запросы были довольно плоскими (никакой вложенности). Но что если мы хотим получить посты про iPhone по годам, а потом посчитать средний рейтинг этих постов?
В ES 1.0 это стало возможно благодаря Aggregation-фреймворку.
Существуют два вида аггергаций:
Bucket — которые считают число найденных документов, а также складывают в «корзину» id найденных документов. Например, приведенные выше фасетные запросы типа term, range, histogram — это Bucket-агрегаты. Теперь они не просто считают количество документов, например, по термам в поле тегов, но и выдают списки id этих документов: 7 документов с тегом «баг», id этих документов 2,5,6,10,17,19,20
Calc — которые считают только число. Например, среднее значение числового поля, минимумы, максимумы, суммы.
Bucket-агрегаты не зря возвращают id найденных документов. Дело в том, что теперь можно построить цепочку аггрегатов. Например, первым аггрегатом мы разбиваем все документы по годам, потом находим распределение тэгов по годам.
Чтобы не ходить вокруг да около, вернемся к нашим тестовым данным. Давайте найдем самые скучные теги постов про айфон с разбивкой по годам. Другими словами найдем все статьи про Iphone, разобьем выборку по годам, и посмотрим какие теги у статей с самым низким рейтингом. Потом запретим авторам писать статьи по этой тематике. Запрос такой:
- Ограничиваем выборку постами, которые содержат iPhone в заголовке
- делаем histogram-bucklet-фасеты по годам
- по полученным «корзинам» делаем term-bucklet-фасеты по тегам.
- по полученным «корзинам» (с тегами) делаем Average-агрегацию по рейтингу
- Так как нам нужны только самые скучные теги, то отсортируем их по значению, полученному во вложенной агрегации (средний рейтинг).
{ "query": { "wildcard": { "title": "iphone" } }, "aggs": { "post_over_time_agg": { "date_histogram": { "field": "postDate", "interval": "year" }, "aggs": { "tags_agg": { "terms": { "field": "tags", "size": 1, "order": { "avg_rating_agg": "asc" } }, "aggs": { "avg_rating_agg": { "avg": { "field": "rank" } } } } } } } } Ответ:
"aggregations": { "post_over_time_agg": { "buckets": [ { "key": 1293840000000, "doc_count": 2, "tags_agg": { "buckets": [ { "key": "взрыв", "doc_count": 1, "avg_rating_agg": { "value": 14.0 } } ] } }, { "key": 1325376000000, "doc_count": 4, "tags_agg": { "buckets": [ { "key": "взрыв", "doc_count": 1, "avg_rating_agg": { "value": 34.0 } } ] } }, { "key": 1356998400000, "doc_count": 2, "tags_agg": { "buckets": [ { "key": "приложение", "doc_count": 2, "avg_rating_agg": { "value": 41.0 } } ] } }, { "key": 1388534400000, "doc_count": 2, "tags_agg": { "buckets": [ { "key": "баг", "doc_count": 1, "avg_rating_agg": { "value": 23.0 } } ] } } ] } } Как видно, в 2011 и 2012 году людей достали посты про взрывы айфонов, в 2013 про новые приложения, а в 2014 про баги.
К реальным задачам
Стандартная задача интернет-магазина — посчитать эффективность рекламной кампании или проанализировать поведение группы пользователей. Представьте, что вы пушите все логи вашего http-сервера в ElasticSearch, при этом добавляя в документ еще немного своих данных, которые у вас хранятся, например в Битриксе
{ "url": "http://myshop.com/purchase/confirmed", "date": "2014-02-15T11:12:12", "agent": "Chrome/32.0.1667.0", "geo": "Москва", "utm_source": "super_banner", "userRegisterDate": "2011-02-15T11:12:12", "orderPrice": 4000, "orderCategory": ["Сотовые телефоны","айфоны"] } При этом схема документа не фиксирована. Есть на этой странице заказ — добавили orderPrice, нет — не добавили.
Имея всего лишь такие логи, вы уже можете многое из того, что умеет Google Anallytics.
Пример 1: Сделать когортный анализ, к примеру, разбить пользователей по дате регистрации и посмотреть, сколько заказов было сделано ими за 2 месяца с момента регистрации, высчитать среднюю сумму заказа. Вот как логически выглядит такой запрос к ElasticSearch:
- делаем текстовый запрос по url слова «purchase/confirmed»
- делаем date_histogram-фасеты по дате регистрации пользователя
- делаем date_range-фасет с начальным значением диапазона «дата регистрации пользователя» (к ней можно обратиться в запросе) и конечным + 2 месяца
- делаем count и average по полю orderPrice в полученных bucklet
Пример 2: Отcлеживать цели и конверсии по каналам с разбивкой по дате. Например, цель — посещение урлы /purchase/confirmed
Запрос:
- делаем текстовый запрос по url слова «purchase/confirmed»
- делаем date_histogram-фасет по дате посещения урлы с разбивкой в 1 день
- делаем term-фасет по utm_source
- делаем count-агрегацию
Выводы
Сочетание полнотекстового поиска и цепочек аггрегаций (фасетов), гибкой схемы документов, автоматической масштабируемости и простоты в настройке и запуске делают ElasticSearch серьезным игроком на рынке аналитических систем.
Еще добавлю, что порог вхождения очень низкий. Установка за 5 минут, дальше можно играться хоть с curl, хоть плагином к Chrome который умеет генерировать http-запросы. У нас http://indexisto.com/ сейчас кластер из 7 машин показывает себя на удивление стабильно.
Все возможности аггрегаций описаны здесь https://github.com/elasticsearch/elasticsearch/issues/3300
ссылка на оригинал статьи http://habrahabr.ru/company/mailru/blog/213849/
Добавить комментарий