На данный момент я занимаюсь улучшением производительности большого корпоративного решения. Его специфика позволяет множеству пользователей выполнять схожие действия, а соответственно за кулисами, сервер приложений работает с одним и тем же кодом. И вот в один из моментов длинного пути ускорения приложения, было замечено что в топе самых низкопроизводительных участков верхние места занимает log4j. Первой мыслью было — излишнее логирование, но последующий анализ ее опроверг. Тем более что это крайне важные данные для инженеров поддержки, и если убрать это сейчас — то либо код вернут обратно либо анализ проблем продакшен сервера будет существенно затруднен.
Это и натолкнуло меня на данное исследование — есть ли способ оптимизировать процесс логирования?
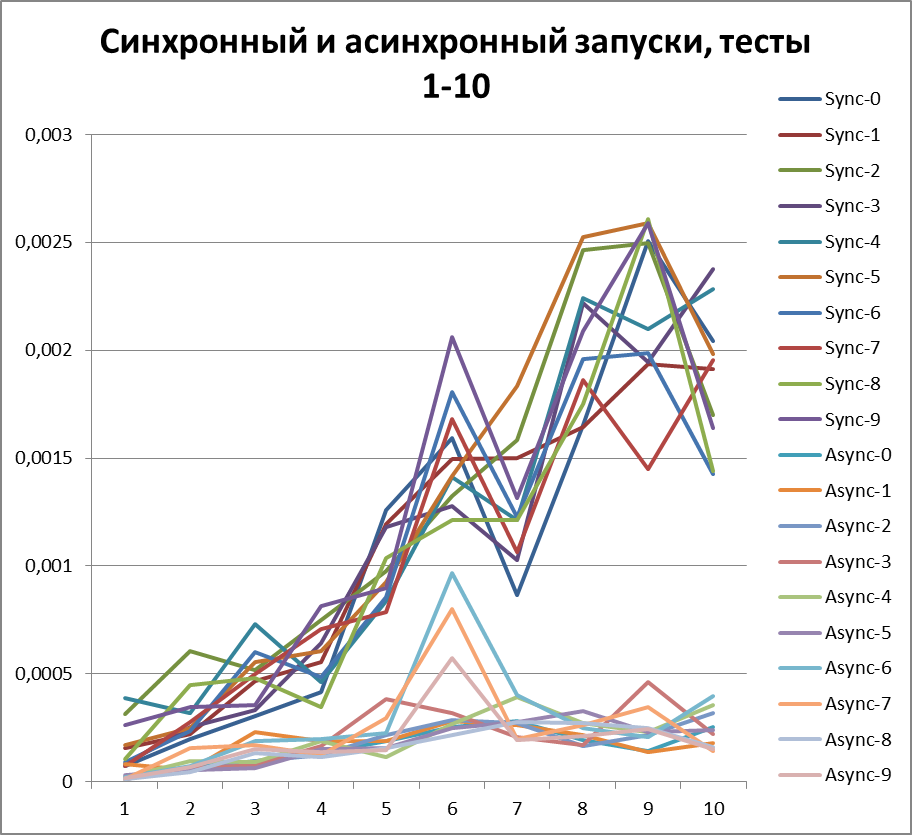
Disclaimer: в силу обилия в данной статье диаграмм вызывающих психоделические ассоциации (вроде этой: это не сравнение синхронного и асинхронного режимов логирования, тут дракон убивает змею!), не рекомендуется к просмотру несовершеннолетним, людям с неустойчивой психикой и беременным женщинам, чей код уже в продакшене а выдача ближайшего патча не в этом году.
В чем же причина?
Как обычно причина банальна — «конкурентный доступ». После нескольких экспериментов с плавающим количеством параллельных потоков стало ясно, что время работы вызова логирования не линейно, соответственно вывод — ЖД сильно проигрывает.
Вот результаты замеров:
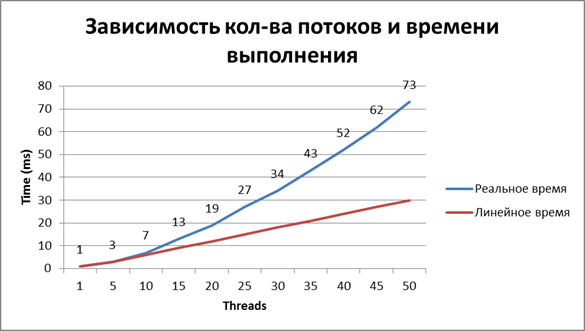
Каково решение?
Искать другие способы логирования, проводить апгрейд библиотек, это все делать можно, но задача в том что бы достичь максимум результата при минимуме усилий. О библиотеке «log4j 2» я тоже могу поведать, но это будет отдельной статьей. Сейчас же мы рассмотрим средства предоставляемые нам «из коробки» в log4j 1.x.
Среди поставляемых с библиотекой аппендеров есть AsyncAppender, который позволяет, используя промежуточный буфер для накопления событий логирования, организовать асинхронную работу с файловой системой (если конечный аппендер именно файловый, ведь изначально он задумывался для SMTP логгера). Порождаясь, события логирования накапливаются, и лишь при достижении определенного уровня заполненности буфера — попадают в файл.
Замеры
Теперь, когда подход определен, нужно бы понять на сколько он эффективен, для этого проведем соответствующие замеры.
Мерить будем так:
0) Заранее предупреждаю, «красивых данных я не делал», местами видно что процессор переключался на другую работу, и эти места я оставил как было. Это ведь тоже часть реальной работы системы.
1) Тесты разобьем на 3 группы:
— 10 событий логирования (от 1 до 10 с шагом 1)
— 550 событий логирования (от 10 до 100 с шагом 10)
— 5500 событий логирования (от 100 до 1000 с шагом 100)
2) В каждой группе будет 3 подгруппы тестов — в зависимости от объема буфера (попробуем найти оптимальный):
— 500 событий
— 1500 событий
— 5000 событий
3) Тесты будут выполняться синхронно и асинхронно.
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE log4j:configuration SYSTEM "log4j.dtd" > <log4j:configuration> <appender name="fileAppender" class="org.apache.log4j.FileAppender"> <param name="file" value="st.log"/> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%d{ABSOLUTE} %5p %t %c{1}:%M:%L - %m%n"/> </layout> </appender> <root> <priority value="info" /> <appender-ref ref="fileAppender"/> </root> </log4j:configuration>
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE log4j:configuration SYSTEM "log4j.dtd" > <log4j:configuration> <appender name="fileAppender" class="org.apache.log4j.FileAppender"> <param name="file" value="st.log"/> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%d{ABSOLUTE} %5p %t %c{1}:%M:%L - %m%n"/> </layout> </appender> <appender name="ASYNC" class="org.apache.log4j.AsyncAppender"> <param name="BufferSize" value="500"/> <appender-ref ref="fileAppender"/> </appender> <root> <priority value="info" /> <appender-ref ref="ASYNC"/> </root> </log4j:configuration>
4) Сами тесты представляют собой простые вызовы логирования вперемешку со «случайной работой» (длительностью от 1 до 15 мс, что бы иметь возможность чередовать доступ к файлу).
package com.ice.logger_test; import org.apache.commons.lang3.time.StopWatch; import org.apache.log4j.Logger; import java.util.Random; public class SimpleTest { private static Logger logger = Logger.getLogger(SimpleTest.class); private static double NANOS_TO_SEC = 1000000000.0d; private static String LOG_MESSAGE = "One hundred bytes log message for performing some tests using sync/async appenders of log4j library"; public static void main(String[] args) throws InterruptedException { //performTest("Single thread"); ThreadRunner t1 = new ThreadRunner(); new Thread(t1).start(); new Thread(t1).start(); new Thread(t1).start(); new Thread(t1).start(); new Thread(t1).start(); new Thread(t1).start(); new Thread(t1).start(); new Thread(t1).start(); new Thread(t1).start(); new Thread(t1).start(); } private static void performTest(String message) throws InterruptedException { logger.info("Warm-up..."); logger.info("Warm-up..."); logger.info("Warm-up..."); StopWatch timer = new StopWatch(); Random ran = new Random(); for(int i = 1; i <= 10000; i += getIncrementator(i)) { timer.reset(); timer.start(); int iterations = 0; for(int j = 1; j <= i; j++) { timer.suspend(); Thread.sleep(ran.nextInt(15)+1); // some work timer.resume(); logger.info(LOG_MESSAGE); timer.suspend(); Thread.sleep(ran.nextInt(15)+1); // some work timer.resume(); iterations = j; } timer.stop(); System.out.printf(message + " %d iteration(s) %f sec\n", iterations, (timer.getNanoTime() / NANOS_TO_SEC)); } } private static int getIncrementator(int i) { if(i >= 0 && i < 10) return 1; if(i >= 10 && i < 100) return 10; if(i >= 100 && i < 1000) return 100; if(i >= 1000 && i < 10000) return 1000; if(i >= 10000 && i <= 100000) return 10000; return 0; } static class ThreadRunner implements Runnable { @Override public void run() { try { performTest(Thread.currentThread().getName()); } catch (InterruptedException e) { e.printStackTrace(); } } } }
Оба результата (плюс промежуточные, что бы не терять нить), синхронный и асинхронный будем визуализировать диаграммами, для наглядности.
Итак начнем.
Синхронный запуск, 2 потока
Для начала посмотрим как ведет себя логгер в синхронной конфигурации. Запустим все сценарии на 2 потоках.
Вот результаты:

Асинхронный запуск, 2 потока
Буфер = 500
Теперь переключимся в асинхронный режим и заодно попытаемся найти оптимальный буфер, начнем с 500
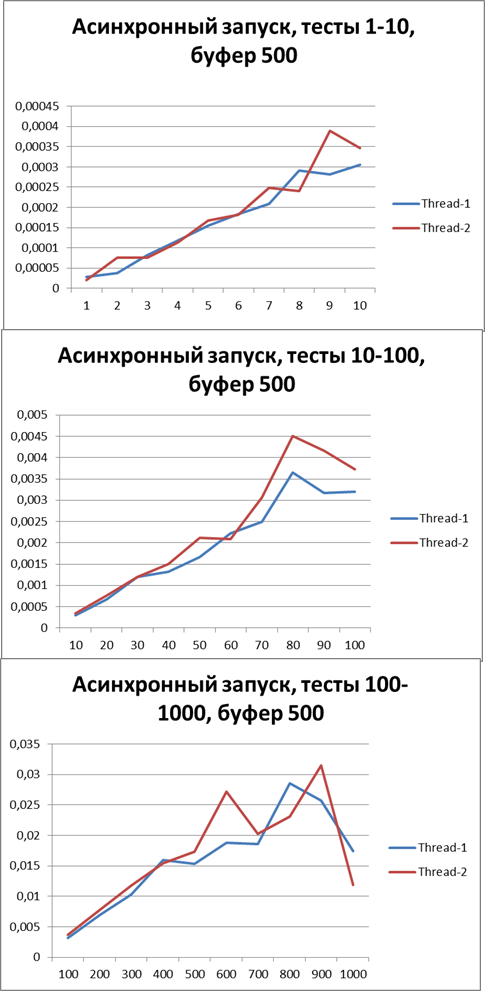
Буфер = 1500
Увеличим буфер в 3 раза и проведем те же тесты:
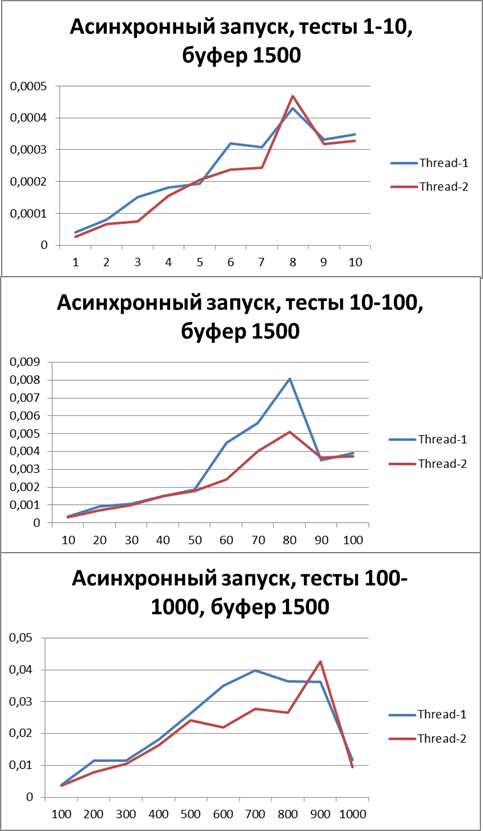
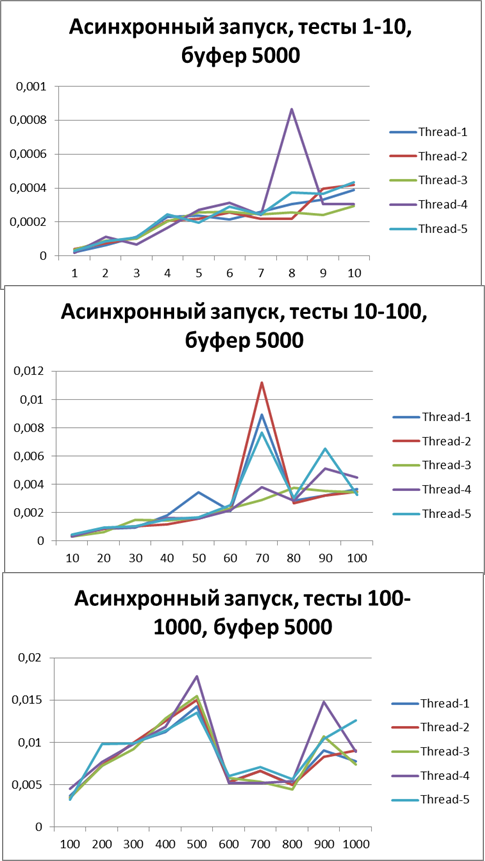
Буфер = 5000
Увеличим буфер в 10 раза и проведем те же тесты:
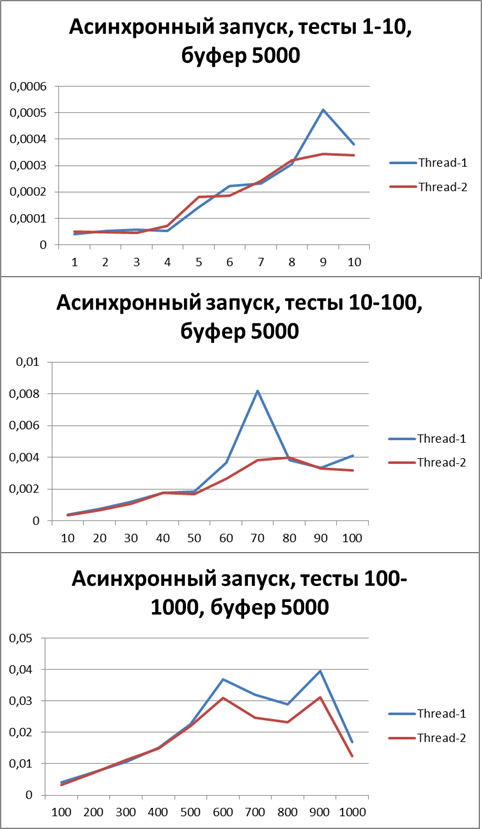
Итог для 2-х потоков
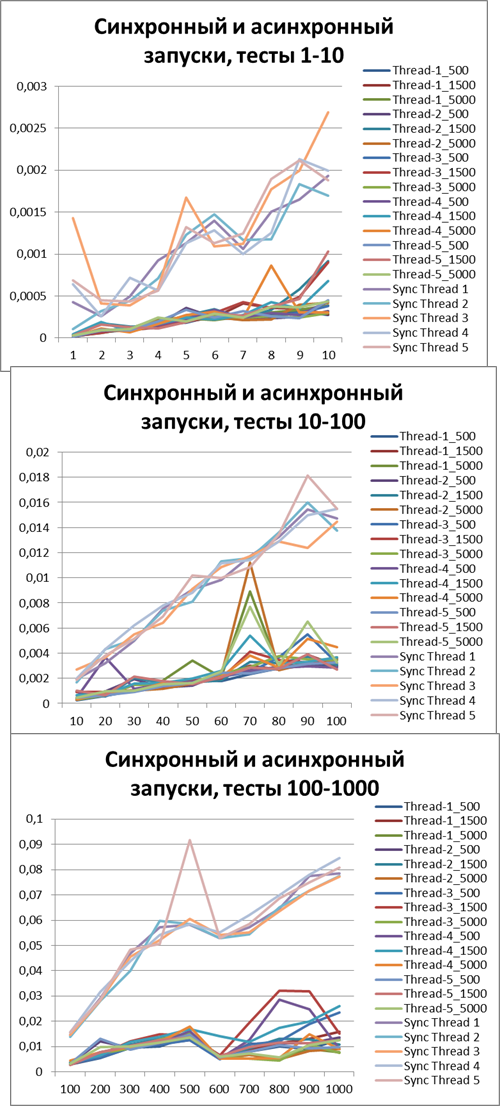
Теперь для наглядности я соберу все асинхронные (что бы попробовать определить оптимальный буфер) и синхронные (для наглядности, интересно ведь, кто победи) тесты в одну диаграмму:

Теперь я думаю наглядно видно ускорение при асинхронном режиме.
Но прежде чем делать выводы, давайте повторим наши тесты на 5 и 10 потоках.
Синхронный запуск, 5 потоков
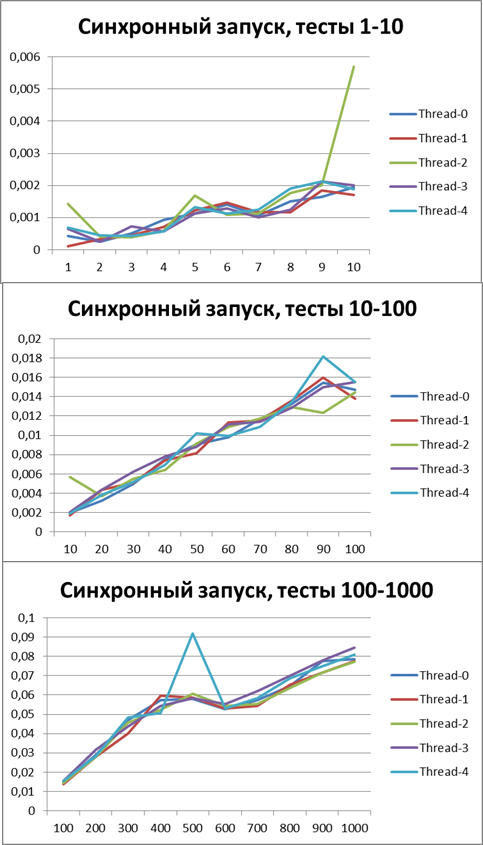
Асинхронный запуск, 5 потоков
Буфер = 500

Буфер = 1500
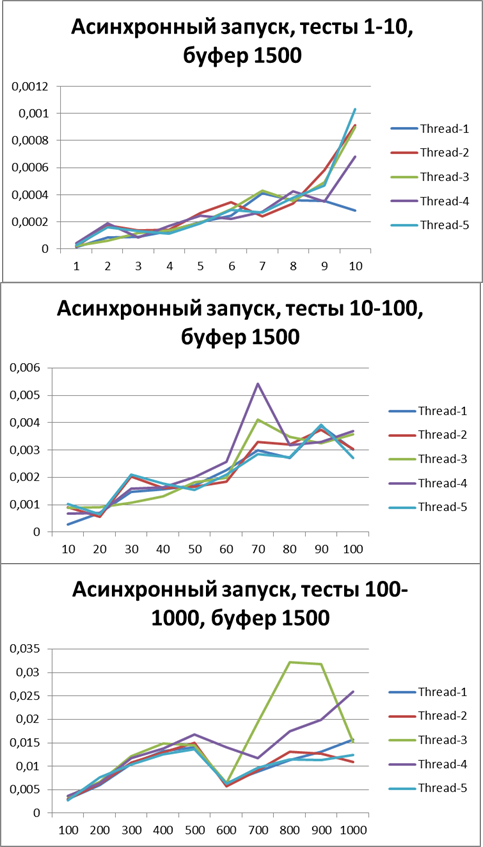
Буфер = 5000
Итог для 5-ти потоков
Синхронный запуск, 10 потоков
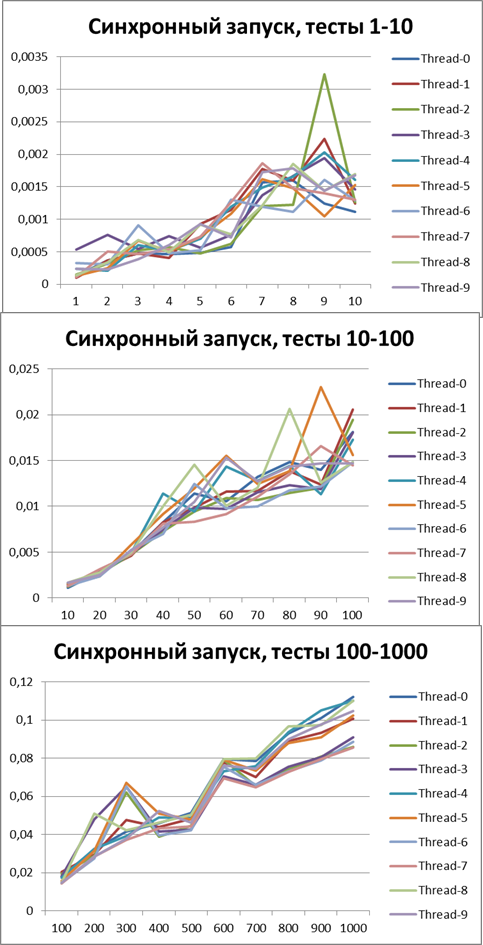
Асинхронный запуск, 10 потоков
Буфер = 500
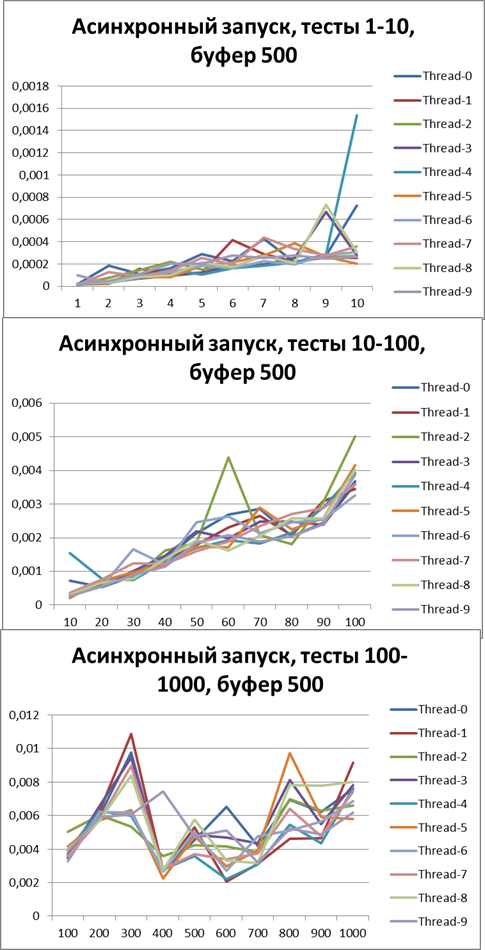
Буфер = 1500
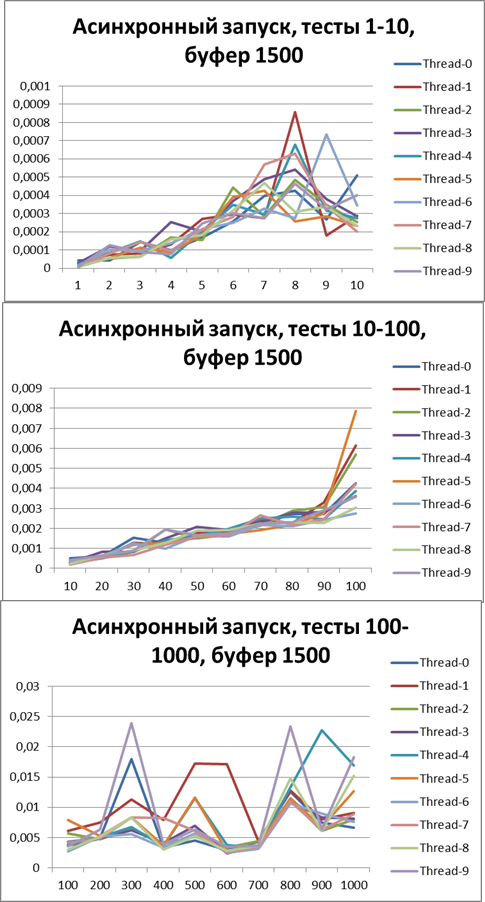
Буфер = 5000
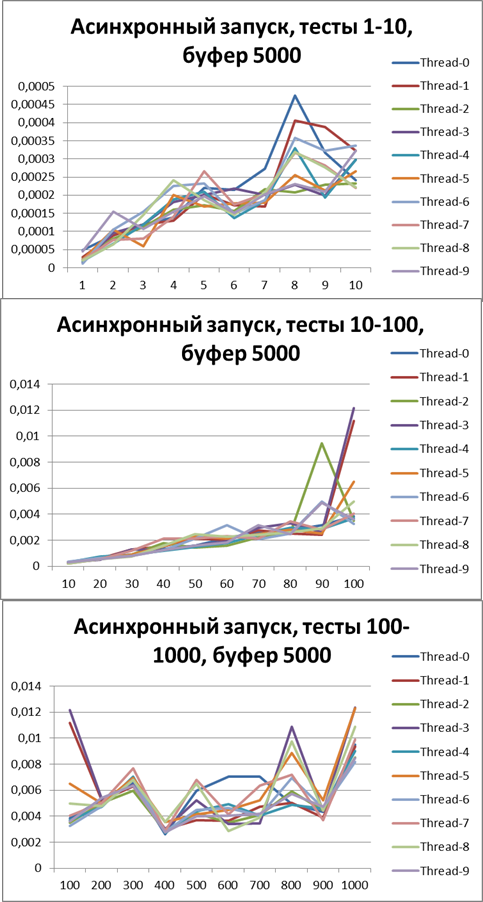
Итог для 10-х потоков
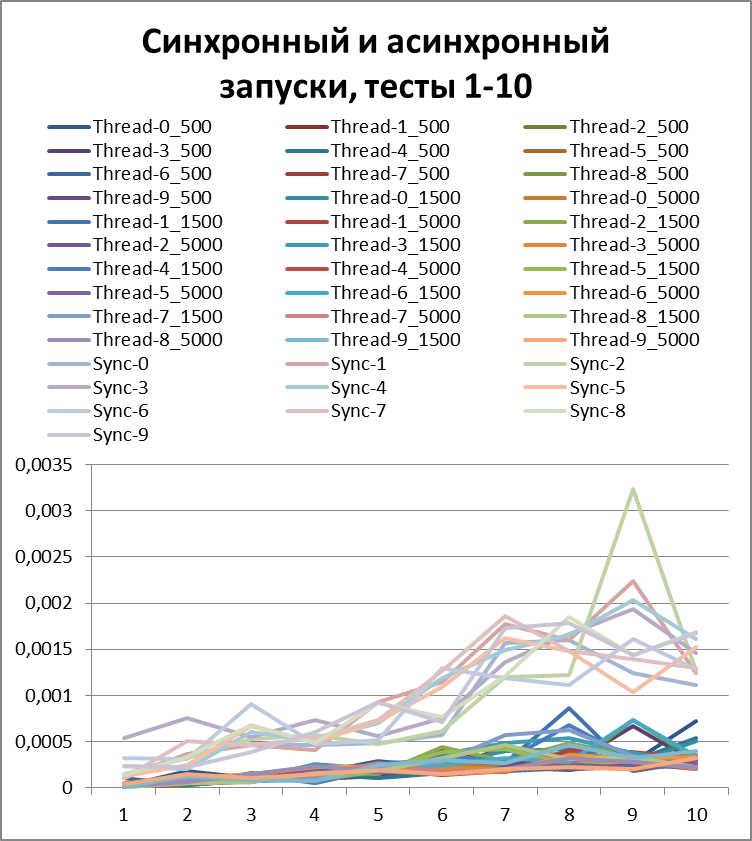
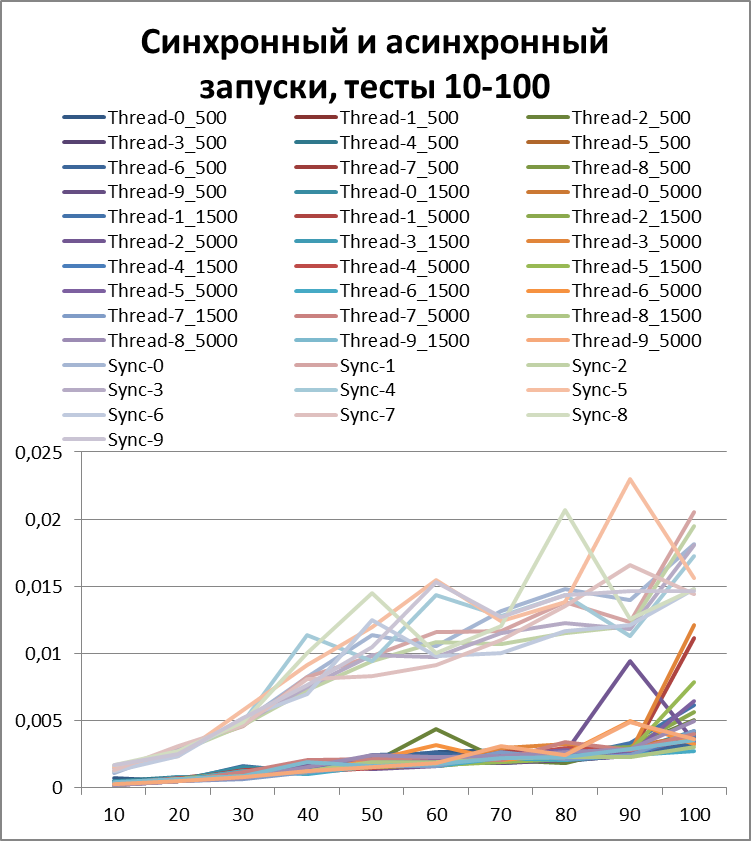
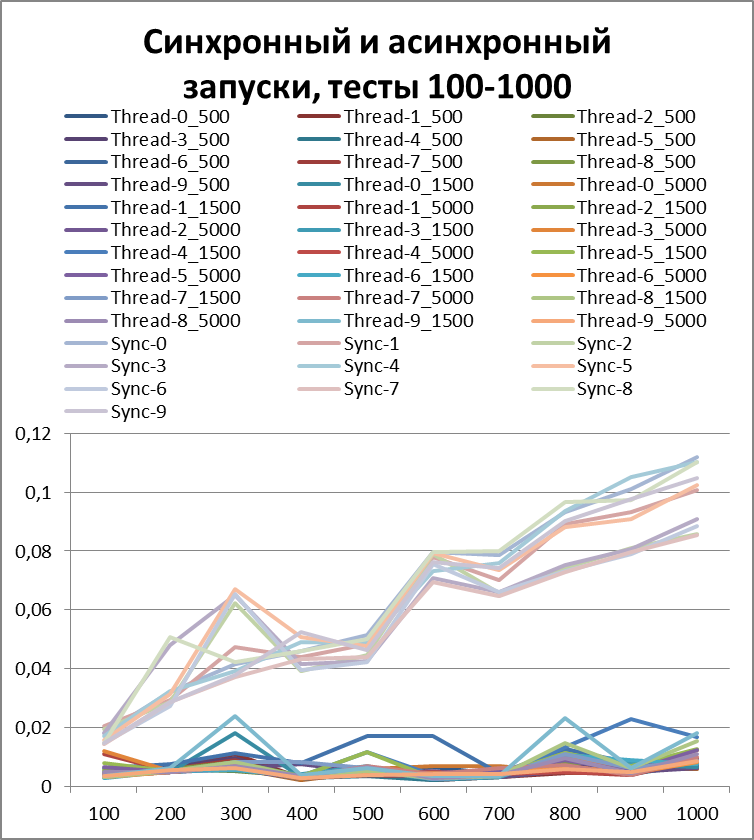
Вывод, как говорится, на лицо.
Раз уж теперь мы однозначно можем говорить о преимуществе асинхронного способа логирования, то давайте попробуем увеличить объемы тестов еще в 10 раз. Добавим тест на 55000 событий логирования (от 1000 до 10000 с шагом 1000). Буфер возьмем равным 500 (так как он на первый взгляд, а позже это будет доказано, является наиболее оптимальным в наших тестах).
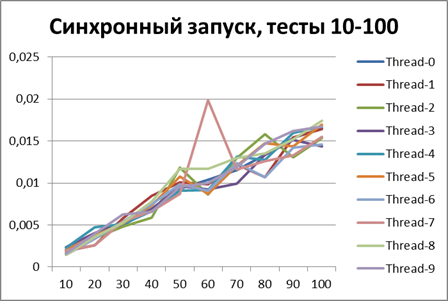
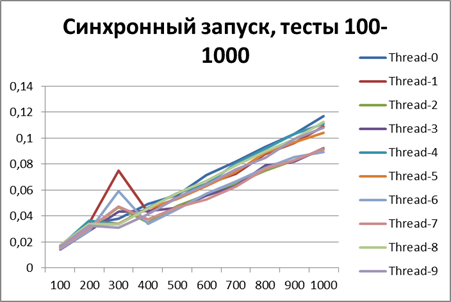
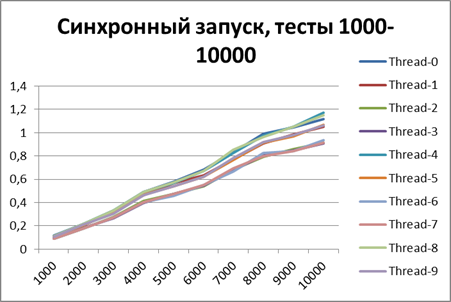
Синхронный запуск, 10 потоков на больших объемах данных
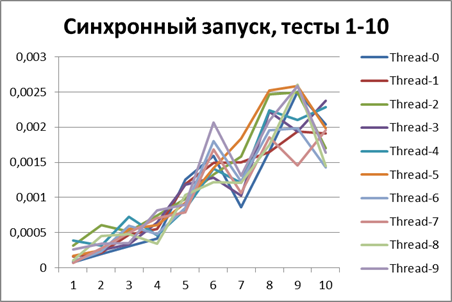
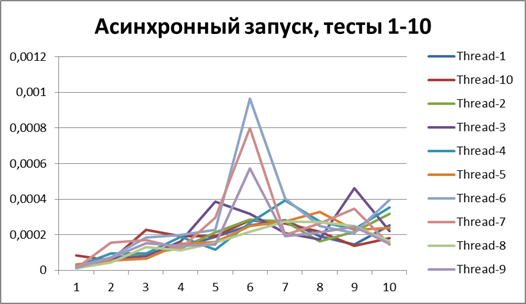
Асинхронный запуск, 10 потоков на больших объемах данных
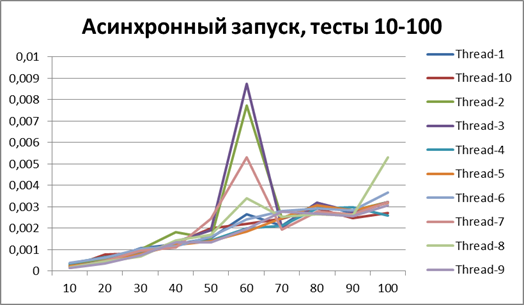
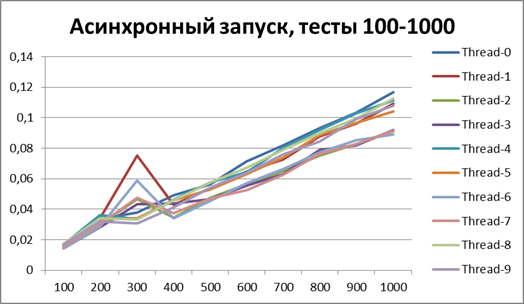
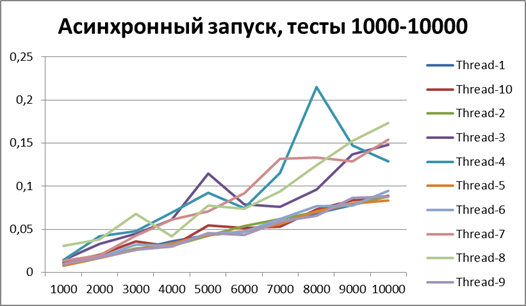
Итог для 10-х потоков на больших объемах данных
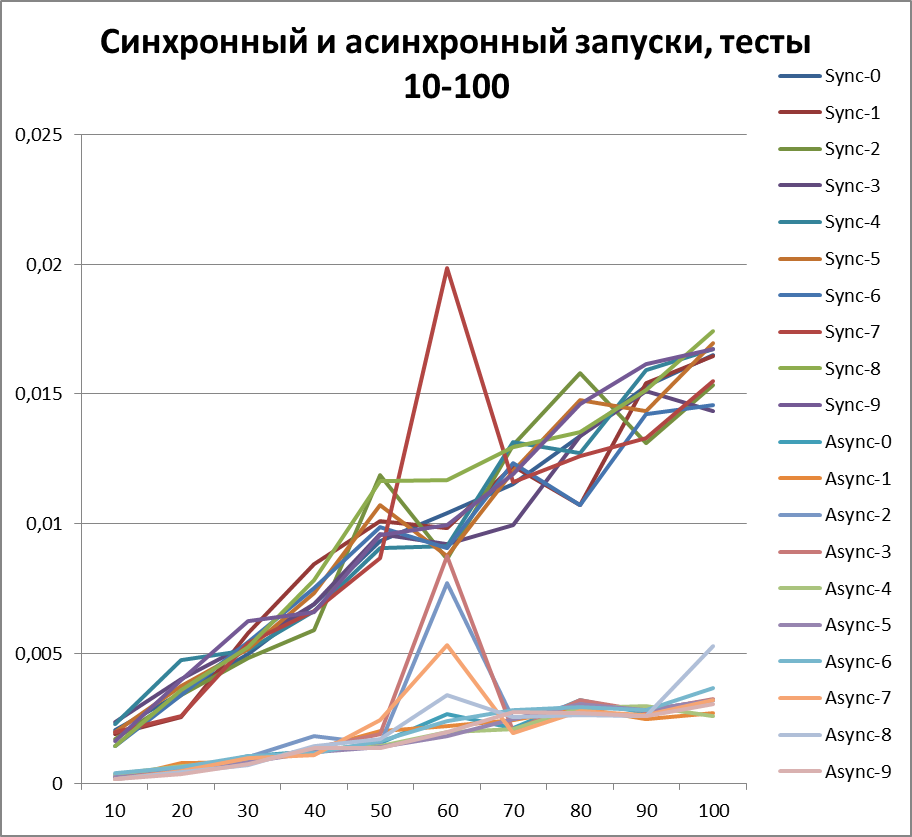
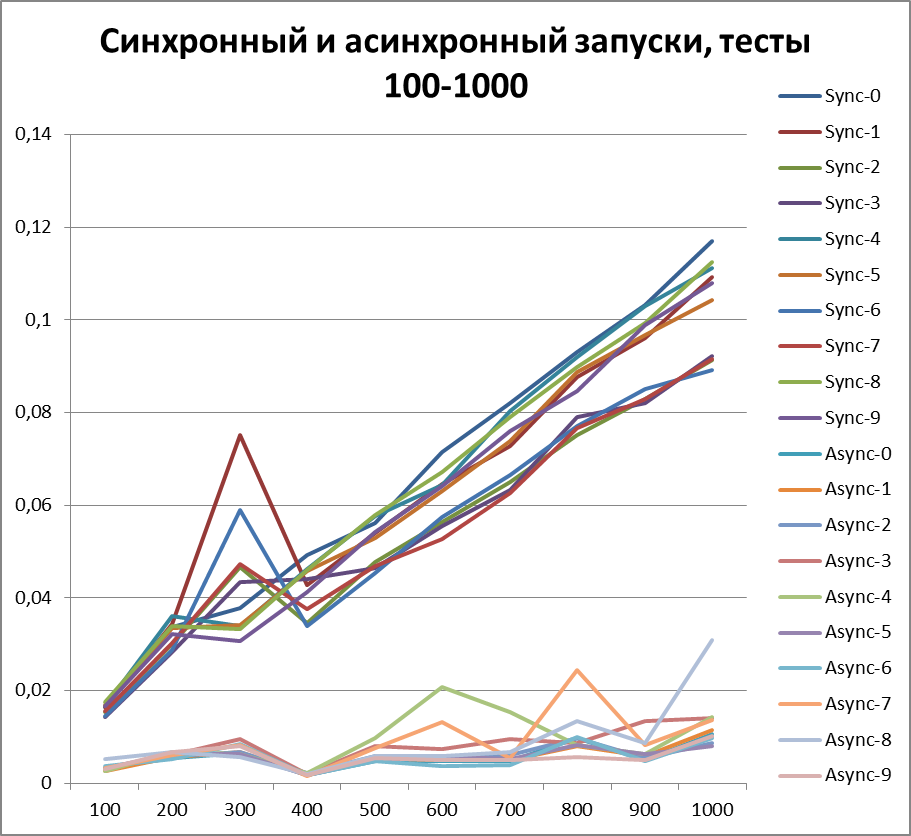
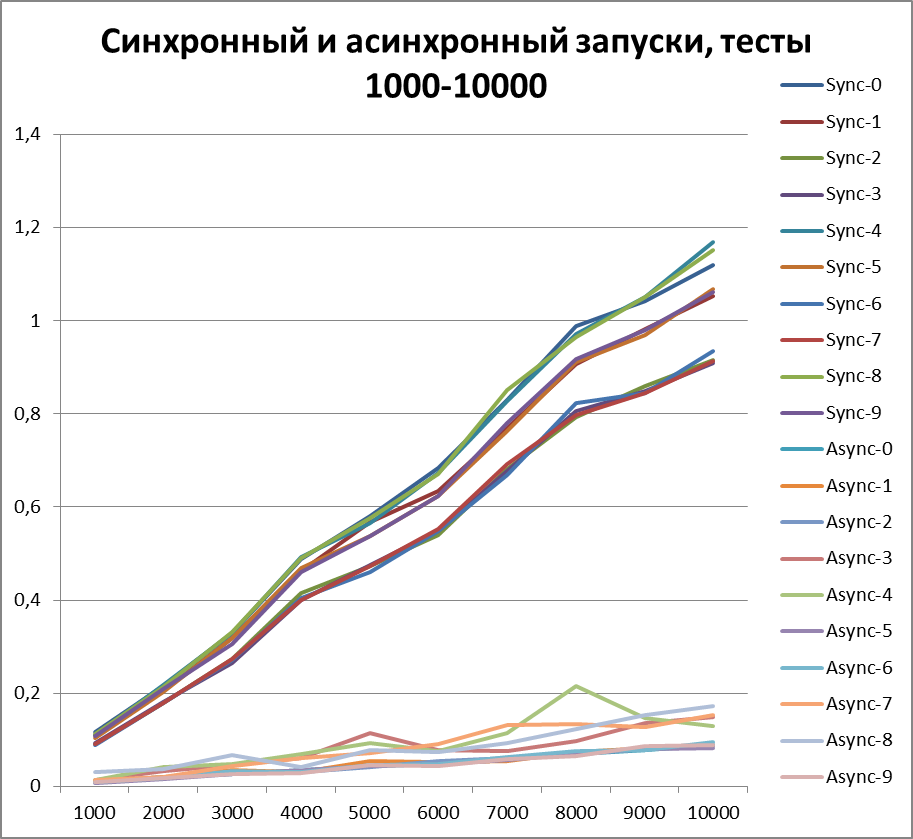
Оптимальный буфер
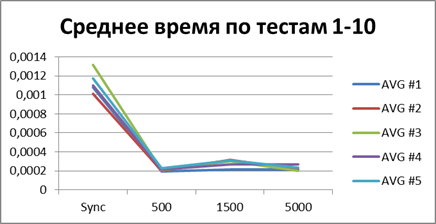
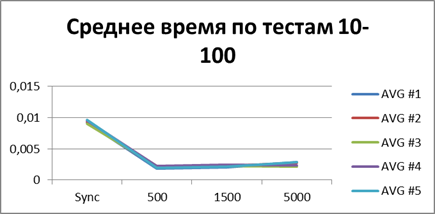
На данный момент у нас уже накопилось довольно много статистических данных, поэтому давайте усредним их все и посмотрим какой-же буфер наиболее подходящий.
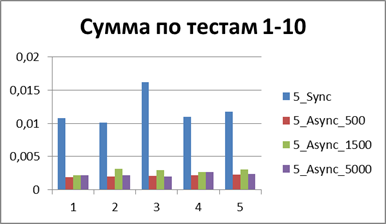
| 2 Потока | |
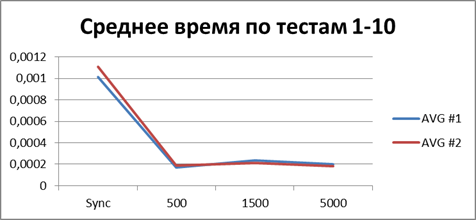 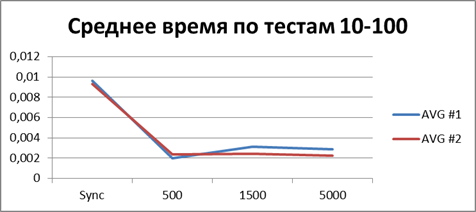 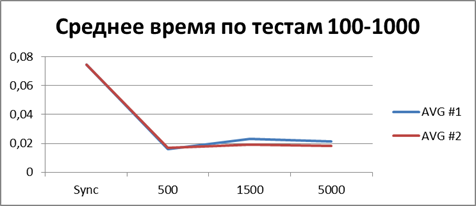 |
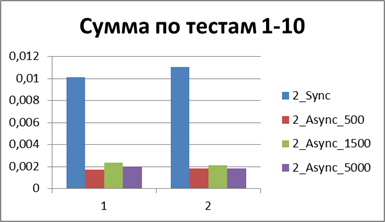 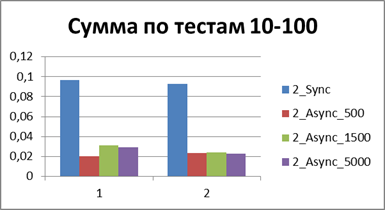  |
| 5 Потоков | |
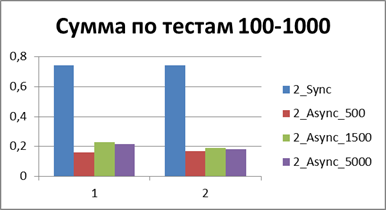
   |
 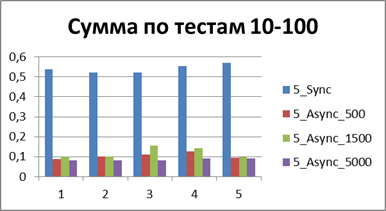 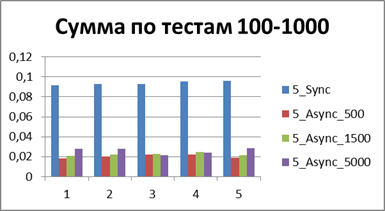 |
| 10 Потоков | |
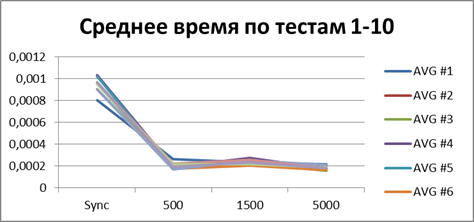 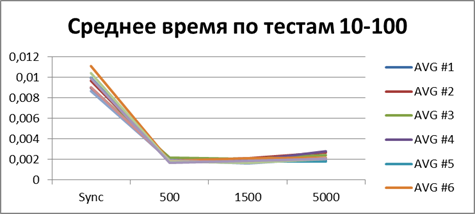  |
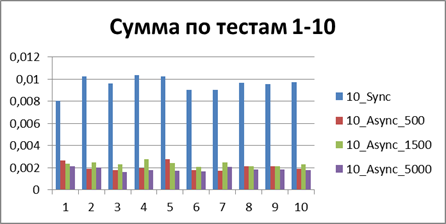 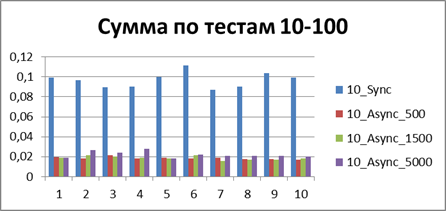 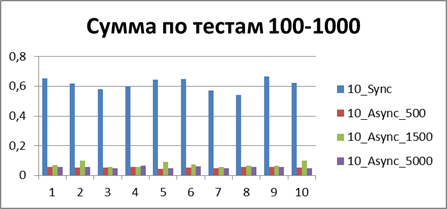 |
| 10 Потоков, большой объем тестов | |
 |
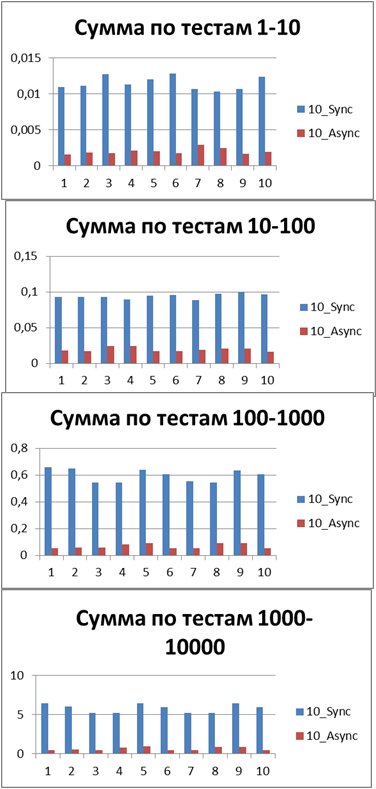 |
Итого — 500 событий, именно наш буфер, позволяющий наиболее эффективно работать в асинхронном режиме.
А теперь если и вовсе сопоставить общее (или среднее) время работы всех тестов то можно получить константу, отображающую порядок выигрыша асинхронного режима перед синхронным, у меня это — 8,9 (раз).
Заключение
Вышеизложенный материал дает понять что стратегия асинхронного логирования дает выигрыш производительности. Тогда напрашивается вопрос — почему не использовать ее всегда? Для того что бы сделать выбор в пользу того или иного способа нужно представлять механизмы которые скрываются внутри. Ниже привожу несколько тезисов взятых с оффсайта:
1) AsyncAppender оперирует своим собственным потоком (в то время как сам FileAppender выполняется в контексте текущего потока), в связи с этим при его использовании желательно повысить лимит потоков сервера приложений.
2) При использовании AsyncAppender’а происходят накладные расходы на память, так как события логирования сбрасываются в файл не моментально, а предварительно наполнив буфер.
3) Блокировка файла лога длится дольше нежели при использовании синхронного подхода, так как буфер сообщений содержит на много больше информации для записи.
В принципе все прозаично, но тут нужно понимать что сама по себе синхронизация это тоже блокировка, так что важно перенося ее из одного места в другое не сделать хуже.
Используйте асинхронность там где она действительно нужна:
— долгоиграющие аппендеры — SMTP, JDBC
— общая блокировка ресурсов — FTP, Local File Storage
Но прежде всего, обязательно профилируйте свой код.
Excel версия данной статьи:
docs.google.com/spreadsheet/ccc?key=0AkyN15vTZD-ddHV0Y3p4QVUxTXVZRldPcU0tNzNucWc&usp=sharing
docs.google.com/spreadsheet/ccc?key=0AkyN15vTZD-ddFhGakZsVWRjV1AxeGljdDczQjdNbnc&usp=sharing
Спасибо за внимание. Надеюсь статья будет вам полезна.
Производительной вам недели!
ссылка на оригинал статьи http://habrahabr.ru/post/215147/
Добавить комментарий