От переводчика:
Доброго времени суток!
Недавно я искал способы повышения скорости работы детектора Виолы-Джонса и натолкнулся на интересную статью 2013 года «RASW: a Run-time Adaptive Sliding Windowto Improve Viola-Jones Object Detection». В ней представлен эффективный подход к улучшению работы детекторов, основанных на принципе сканирующего окна и каскадных классификаторах. Я не нашел описания данного подхода на русском языке и решил восполнить этот пробел. В данном переводе я опустил описание алгоритма Виолы-Джонса, так как о нём уже много рассказано, в том числе и на хабре habrahabr.ru/post/133826/.
RASW: a Run-time Adaptive Sliding Windowto Improve Viola-Jones Object Detection
Francesco Comaschi, Sander Stuijk, Twan Basten and Henk Corporaal
Electronic Systems Group, Eindhoven University of Technology, The Netherlands
ff.comaschi, s.stuijk, a.a.basten, h.corporaalg@tue.nl
Аннотация
Среди алгоритмов обнаружения объектов на изображениях наибольшую популярность приобрел метод Виолы – Джонса, реализованный в библиотеке OpenCV. Тем не менее, как и в других детекторах, основанных на принципе сканирующего окна, объем требуемых вычислений увеличивается с увеличением размера обрабатываемого изображения, что не хорошо при обработке изображений в реальном времени. В данной статье мы предлагаем эффективный подход – изменение шага движения сканирующего окна во время обработки — для увеличения быстродействия без потери точности. А также демонстрируем эффективность предлагаемого подхода на методе Виолы – Джонса. При сравнении с реализацией детектора в библиотеке OpenCV, мы получили прирост скорости (кадр/с) до 2.03 раз без потерь в точности.
Введение
Инновации в области полупроводниковых технологий и компьютерных архитектур делают реальными новые сценарии использования компьютерного зрения, в которых возможность анализа обстановки в реальном времени имеет решающее значение. Хорошим примером задачи реального времени, которая находит применение во многих областях, является обнаружение какого-либо объекта на изображении. Таким объектом зачастую является лицо человека[1]. На данный момент существует огромное разнообразие подходов для обнаружения лиц. Метод, предложенный Виолой и Джонсом[2] в 2001 году, стал настоящим прорывом в этой области. Этот метод приобрел большую популярность благодаря высокой точности и серьезной теоретической основе. Однако, сложность вычислений по прежнему делает этот метод достаточно серьезной задачей для удовлетворения требований реального времени (например пропускная способность) даже на мощных платформах. Скорость сканирования изображений сильно зависит от размера шага сканирующего окна Δ – количества пикселей, на которое сдвигается сканирующее окно. В большинстве доступных реализаций шаг постоянный и определяется на этапе компиляции, что означает, что окно смещается на постоянную величину и не зависит от содержания изображения. В данной статье мы предлагаем Run-time Adaptive Sliding Window (RASW), который улучшает пропускную способность без ухудшения точности алгоритма путем изменения шага сканирования во время выполнения.
Обзор существующих решений
В последние годы было предложено несколько аппаратных реализаций детектора лиц Виолы-Джонса c высокой пропускной способностью [3] — [5]. Однако такие решения имеют два основных недостатка:
1) они требуют значительных инженерных усилий, что подразумевает высокие единовременные затраты;
2) они недостаточно гибкие, что делает невозможным адаптацию системы к каким-либо изменениям в сценарии применения.
Другой способ ускорить алгоритм – применение реализации на GPU [6]-[8]. Однако количество энергии, потребляемое GPU, делает это решение непрактичным для применения во встраиваемых системах. Тем не менее, реализация на GPU может быть использована в сочетании с оптимизацией, предложенной в данной статье. В частности, может быть использовано распараллеливание для вычисления признаков и сканирования окнами разного размера. Более подробно об этом написано в работе [6].
В работе [9] авторы предлагают решение на основе реализации из OpenCV, оптимизированное для встраиваемых систем, но сама реализация остается неизменной. Наша алгоритмическая оптимизация улучшает пропускную способность за счет снижения объема требуемых вычисление без ухудшения точности.
Первым шагом в системе обнаружения объекта обычно является сканирование сцены в поисках регионов-кандидатов изображения. Этот этап содержит большой объем вычислений. Ламперт и другие в работе [10] предлагают аналитический подход, известный как Эффективный Поиск В Подокне (Efficient Subwindow Search), для обеспечения локализации объекта. Однако, предложенный подход относится именно к локализации объекта, что означает, что количество объектов присутствующих на изображении должно быть известно заранее. Такой подход может быть чрезвычайно эффективен в такой задаче, как поиск изображении в интернете, но из [10] не ясно, что будет, если на изображении будут присутствовать несколько экземпляров интересующего объекта. К тому же, для применения ESS должна быть определенным образом построена ограничивающая функция, и в работе [10] не представлена такая функция для каскадного классификатора. Подход, представленный в данной статье, предназначен для каскадных классификаторов, не требует дополнительной информации (такой как ограничивающая функция) и может быть использован для изображений с любым числом объектов.
В работе [11] авторы рассматривают метод, основанный на модели визуального поиска (visual search in humans) для быстрого обнаружения объектов. Сравнив свою работу с детектором Виолы-Джонса в OpenCV, они получили ускорении в среднем в 2 раза, за счет небольшого снижения точности. Результаты работы представлены только для одного изображения, поэтому сложно судить, сохранятся ли показатели при тестировании на большем количестве изображений. К тому же, подход предлагается для использования с изображениями, содержащими только одно лицо и не ясно как применять такой подход к изображениям с несколькими лицами. При том что результаты приводятся для различных значение масштабирующего коэффициента, влияние другие параметров на сканирование изображения систематически не изучен. Результаты работы нашего подхода представлены для стандартной базы лиц и влияние различных параметров тщательно изучено.
В работе [12] авторы предлагают интересный метод уменьшения пропущенных обнаружений в каскаде детектора при увеличении шага скольжения сканирующего окна. Авторы представили многообещающие результаты на нескольких базах лиц. Однако, подход, предложенный в [12], требует обучение офф-лайн дерева решений для оценка расположения. Кроме того, использование точек интереса добавляет дополнительный объем вычислений, что затрудняет использование в случае ограничения памяти. Алгоритмическая оптимизация представленная в данной статье основана на информации, доступной во время выполнения; она не требует дополнительного обучения и не добавляет значительных вычислений к стандартному принципу сканирующего окна.
RASW
Обычно, в реализациях метода Виолы-Джонса при каждом изменении размера сканирующего окна (либо изображения), это окно двигается по изображению с шагом сканирования Δ. Мы же будем различать размер шага вдоль оси x и оси y, т.е .ΔX и ΔY соответственно. Для простоты оставим обозначение Δ, для случаев когда ΔX = ΔY. Шаг сканирования влияния влияет и на точность обнаружение и на пропускную способность. Большее значение увеличивает пропускную способность, но в то же время ухудшает качество распознавание, так как некоторые объекты могут быть пропущены. Если для перемещений сканирующего окна мы найдем такой критерий, что окно будет двигаться быстрее в областях, которые не содержат объекты, и медленнее в непосредственной близости от объекта, то мы сможем повысить скорость сканирования всего изображения без ухудшения качества. Более того, быстрее перемещая окно в однородных областях изображения, мы уменьшаем шанс классификатора ошибочно обнаружить искомый объект в фоновом изображении.В большинстве существующих реализаций, размер шага – фиксированная величина, причем Δ = 1 или Δ = 2, т.к. более высокие значения приводят к ухудшению качества.
Проведенный нами анализ обнаружил взаимосвязь между наличием лица в области изображения и номером классификатора в каскаде, на котором данное окно отвергается(будем называть этот номер ступенью выхода). В частности, в областях, содержащих только фон, окно отвергается на более ранних ступенях каскада, и, в общем, чем ближе лицо, тем выше ступень выхода.
Рисунок 1

Рисунок 1 содержит тестовое изображение и для этого изображения для каждого сканирующего окна были записаны значения ступени выхода. Если верхний левый угол окна имеет координаты (x, y), то пиксель отображается с яркостью, обратно пропорциональной ступени выхода. Иными словами, чем выше ступень выхода, тем темнее пиксели.
Проведенный нами анализ показывает, что окно может быть смело сдвинуто на больший шаг при низком значении ступени выхода, ибо в большинстве случаев это означает, что данная область не содержит искомые объекты. А при приближении ступени выхода к максимальному значению имеет смысл уменьшить шаг сканирования, чтобы не пропустить искомый объект. Основная идея — тратить меньше времени на регионы изображения, которые с высокой вероятностью не содержат искомые объекты. Предлагаемый подход позволяет отбрасывать бесперспективные регионы, используя пространственную локальность данных. Даже если отброшенные регионы были не самыми затратными в плане вычислений, значительное снижение количества окон приводит к более быстрой обработке каждого изображения, не влияя на качество. Это особенно выгодно, т.к. при непосредственном отбрасывании окна можно избежать предварительной нормализации изображения подокна, являющейся довольно затратной операцией. Данная нормализация необходима для минимизация влияния различных условий освещения в методе Виолы-Джонса[2], [9].
Рисунок 2
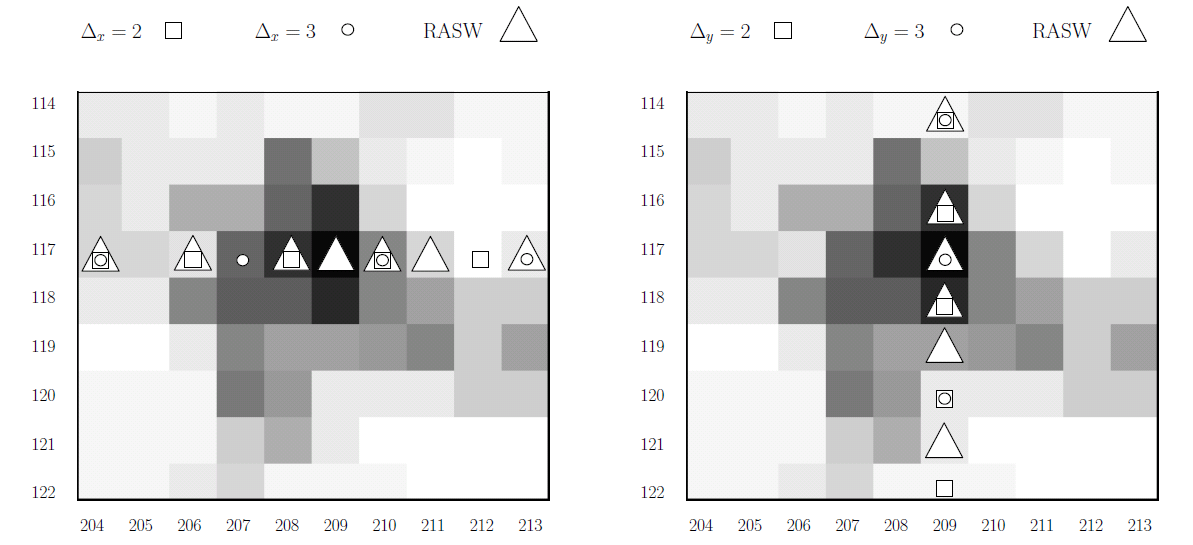
На рисунке 2 представлено графическое объяснение преимущества RASW подхода. Для того чтобы рисунок был более читабельным, мы разделим направления вдоль осей x (слева) и у (справа). Серые блоки — увеличенные пиксели от 204 до 213 (ось x) и от 114 до 122 (ось y) изображения представленного на рис. 3 (справа). Черный пиксель в позиции (209, 117) соответствует правому нижнему лицу, обнаруженному на рисунке 1. Для каждого из подходов представленных на рисунке 4, соответствующая геометрическая форма находится в пикселе где расположено сканирующее окно. На рисунке 2 (слева) мы видим, как, взяв постоянный шаг ΔX = 2 или ΔX = 3, детектор не в состоянии разместить сканирующее окно в месте, где присутствует лицо. Подход RASW автоматически уменьшает размер шага ΔX при приближении к лицу, что позволяет разместить окно должным образом. Такое же поведение можно наблюдать на рис. 4 (справа), с той разницей, что в этом случае постоянный шаг ΔY = 3 также позволяет разместить окно должным образом.
Алгоритм 1

Алгоритм 1 представляет реализацию RASW. При каждом перемещении сканирующего окна для него запускается каскадный классификатор, который возвращает ступень выхода (строка 7). Если ступень выхода равна n – числу классификаторов в каскаде – значит искомый объект найден (строка 8) и положение, размеры текущего окна помещаются в вектор V(строка 10). Шаг окна может принимать 3 различных значения: Δx,max, Δx,minи Δx,nom, в зависимости от ступени выхода предыдущего положения окна(это верно и для направления y). Для присвоения величинам ΔX и Δy правильных значений, мы должны хранить информацию о ступени выхода предыдущего положения окна. Эту информацию можно хранить прямо в переменных ΔX и Δy. В нашей реализации окно двигается слева направо, сверху вниз, поэтому информация, относящаяся к направлению x, может храниться в целочисленной переменной ΔX. С другой стороны, при достижении окном конца строки, информация о шаге по оси y должна быть сохранена для всей строки, то есть Δy — массив целых чисел. На каждой итерации алгоритма ΔX и Δy [x] уменьшаются на единицу, и когда обе переменные станут равны нулю, текущее окно подается на вход классификатора. Если данного условия достигает только одно значение шага, то эта переменная инициализируется минимальным значением(строки 20 и 22). Переход от одного значения Δ к другому (для обоих направлений) определяется во время выполнения на основе четырех пороговых значений: Δx,t1, Δx,t2, Δy,t1, Δy,t2. Эти параметры задаются при компиляции и они могут принимать значении от 0 до n + 1, причем Δx,t1 < Δx,t2 и Δy,t1 < Δy,t2. Мы учитываем частные случай, когда шаг Δx — константа и равен Δx,min(Δx,t1 = Δx,t2 = 0), Δx,nom(Δx,t1=0, Δx,t2= n+1) или Δx,maxΔx,t1= n+1). это же справедливо и для шага Δy. Для краткости, в строках 12-18 алгоритма 1, мы приводим только код, относящийся к оси x, но аналогичный код, с некоторыми изменениями, должен быть применен и для оси y. Различные значения пороговых значений обеспечивают различные соотношения пропускная способность – точность. Также на эти соотношения влияют другие значения: коэффициент масштабирования s, порог слияния γ. Мы выбрали следующие значения: Δx,max=3, Δx,nom=2, Δx,min=1, ибо более высокие значения ухудшают качество детектора.
Результаты
В этом разделе мы продемонстрируем эффективность нашего подхода, сравнивая реализации с фиксированным и адаптивным шагами. Эксперименты проведены на четырехъядерном Intel Core i7 с тактовой частотой 3.07 ГГц. Использовалась база лиц CMU+MIT [15].
Были рассмотрены следующие реализации: (I) статическая: ΔX и ΔY постоянны и равна 1, 2 или 3 (всего 9 комбинаций); (II) OpenCV 1: ΔX = 2 для всего изображения, если на предыдущем шаге не было обнаружено лицо, иначе ΔX уменьшается до 1. ΔY остается постоянной и равной 1; (III) OpenCV 2: Δ = 1, если размеры текущего уменьшенного изображения меньше более чем в 2 раза размеров оригинального изображения, иначе Δ = 2 в противном случае. Изменяются и ΔX и ΔY.
Заметим, что первые 2 подхода (статичный и OpenCV 1), используемые для нашего сравнения являются частными случаями предлагаемого RASW подхода. В частности, каждая комбинация статической подхода может быть получены из алгоритма 1 при присвоении Δ t2 и Δ_t1 соответствующих значений. Второй подход (OpenCV 1) можно получить, установив Δx,t1= 0, Δx,t2= n, Δy,t1=Δy,t1= 0.
Для иллюстрации преимущества RASW, мы протестировали различные подходы для нескольких значений двух других параметров: коэффициент масштабирования( scalingfactor ) s и порог слияния (merging threshold) γ. Мы выбрали следующие параметры: s ∈{1.1, 1.2, 1.3, 1.4, 1.5} и γ ∈{1, 2, 3, 4, 5}. Большие значения этих параметров снижают точность. Имея пять возможных значений для х, пять значений для γ одиннадцать различных подходов к выбору Δ ( девять статичных комбинации плюс два подхода OpenCV ), мы в конечном итоге имеем 275 различных конфигураций для выбранных подходов. Что касается RASW, возможны различные варианты пороговых параметров Δx,t1, Δx,t2, Δy,t1, Δy,t2. Поскольку число ступеней выбранного классификатора n = 25, для того, чтобы выполнить тщательное тестирование нашего метода в разумные сроки мы возьмем значения параметров в диапазоне [ 0; n + 1]. В частности Δx,t1, Δx,t2, Δy,t1, Δy,t2 ∈{0, 5, 10, 15, 20, 25, 26}, что приводит к 28 возможным комбинациям для каждого направления. Учитывая возможные значения s и γ, получаем в итоге в общей сложности 19 600 конфигураций.
Для анализа производительности предложенного алгоритма, мы используем две метрики, часто используемые при сравнении алгоритмов обнаружения объектов: отзыв(recall) и точность(precision). Определяются они следующим образом:
 ;
; 
где ТП – число правильно определенных объектов, FN – число пропущенных объектов, FP — количество ложных срабатываний. Среди всех созданных конфигураций, мы показываем только, так называемые, Парето точки, которые являются локальными оптимальными решениями, фиксирующими все оптимальные компромиссы в проектных пространстве [17] (Для того чтобы наши результаты соответствовали традиционному определению Парето точки [17], мы используем 1 — recall вместо recall, 1 — precision вместо precision. Таким образом, теоретически наилучшая конфигурация совпадает с началом координат). Конфигурация преобладает над другой конфигурацией, если она как минимум не хуже в каждом из показателей. Будем рассматривать только те конфигурации, над которыми не преобладает ни одна другая конфигурация. Набор таких конфигураций является минимальным по Парето. Все элементы такого набора являются точками Парето.
Рисунок 3
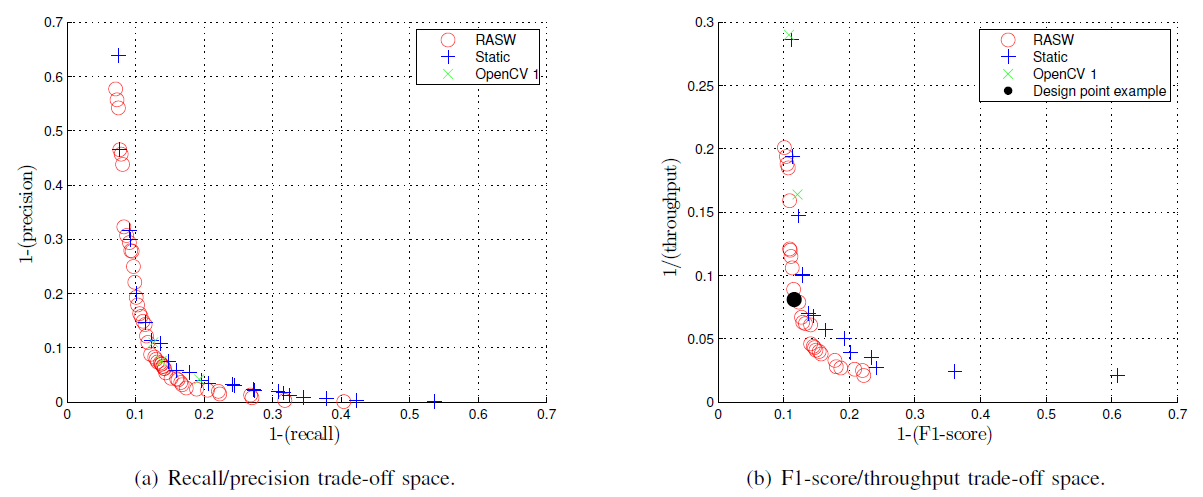
На рис. 3(а) представлены точки Парето, полученные для базовых (статический, OpenCV 1, OpenCV 2) и RASW подходов в 2-мерном пространстве вызова/точность (recall/precision). Парето-минимальный набор конфигураций базовых реализаций содержит 27 Парето точек, в то время как Парето-минимальный набор подхода RASW содержит 48 Парето точек. На рис. 3 (а) мы можем видеть, что для каждой Парето-Минимальной конфигурации базовых подходов, можно найти конфигурацию RASW с такой же точностью и таким же (или лучшим) отзывом.
Для встраиваемых систем, где изображения должны обрабатываться в режиме реального времени, первостепенное значение имеет пропускная способность – число обработанных кадров в секунду(FPS). Для визуализации Парето-минимальных решений при учете пропускной способности мы будем использовать F1-score – часто используемую метрику, объединяющую в себе и точность и отзыв[18]. F1- score можно рассматривать как средневзвешенное значение отзыва и точности, в лучшем случае принимающее значение 1, а в худшем – 0

а рис. 3 (б) представлены точки Парето, полученных для базовых и RASW подходов в 2-мерном пространстве F1-score/throughput( используем 1 — F1-score и 1/ throughput пропускную для того, чтобы теоретически оптимальное решение совпало с началом осей). Парето-минимальный набор конфигураций базовых реализаций содержит 16 Парето точек в то время как набор RASW -. Из рис. 3 (б) мы видим, что для заданной точностью, подход RASW всегда обеспечивает хотя бы одну конфигурацию, которая обеспечивает пропускную способность по крайней мере, такую же как и конфигурации из базовых реализаций с той же (или лучше) точностью.
Результаты на рис.3 показывают, что RASW предоставляет новые конфигурации, которые преобладает над конфигурациями базовых реализаций. Это означает, что тот же самый (или лучше) отзыв может быть достигнут с большей точностью, и что та же (или лучше) точность может быть достигнута при меньшем объеме вычислений. Например, Парето- минимальная конфигурация реализации OpenCV 1 спараметрами s = 1.2 и γ = 4 (второй X-знак сверху на рис. 3 (б)). Такая точка приводит к F1-score= 87.9 и пропускной = 6.1 кадров в секунду. Выбрав Δx,t1=5, Δx,t2=10, Δy,t1=5, Δy,t2=5, s = 1.3 и γ = 4, подход RASW приводит к лучшей точности (F1-score = 88.4) и 2.03x ускорению (пропускная способность = 12.4 кадров в секунду). Точка с черным кругом на рис. 3 (б).
Выигрыш в производительности подхода RASW не является постоянным, т.е. он изменяется в зависимости от положения в проектном пространстве. Цель данной работы — показать, что с помощью RASW, проектировщик детектора объекта имеет возможность выбирать точки, которые наиболее соответствуют целевому приложению. Например, предположим, что целевой приложения требуется пропускная способность по меньшей мере 10 кадров в секунду, с отзывом больше, чем 80% и точностью выше 95%. Затем, выбрав набор параметров, упомянутых выше для RASW, проектировщик получит условную точку, соответствующую черным кругом на рис. 3 (б), характеризуемую отзывом = 82.4%, точностью = 95.2% и производительностью = 12. 4 кадров в секунду, что соответствует требованиям системы. Эта точка недостижима для любой из базовых реализаций.
Выводы
В данной статье предлагается использование адаптивного движения сканирующего окна ( RASW ) для улучшения процесса обнаружения объекта. Представлены результаты для реализации детектора лиц Виолы -Джонса, но данная оптимизация может быть применена для любого алгоритма обнаружения объектов, в котором используются сканирующее окно и каскадный классификатор. По сравнению с существующими подходами, RASW обеспечивает лучшие показатели в пространствах recall/precision и F1-score/throughput, что особенно важно для приложений реального времени. Предлагаемая оптимизация позволяет достичь большей точности, чем существующие реализаций, но при этом с меньшим объемом вычислений, а также может использоваться в сочетании с распараллеливанием, для повышения производительности. В будущей работе мы планируем разработать алгоритмы для поиска оптимальных параметров, соответствующих заданным требованиям. Предложенный алгоритм использует локальность данных для улучшения распознавания лиц. При захвате изображения с видео, может быть принята во внимание также и временная неоднородность для еще большего снижения объема вычислений.
Литература
[1] C. Zhang and Z. Zhang, “A survey of recent advances in face detection,” in Technical report MSR-TR-2010-66, 2010.
[2] P. Viola and M. Jones, “Rapid object detection using a boosted cascade of simple features,” in CVPR, 2001.
[3] J. Cho, B. Benson, S. Mirzaei, and R. Kastner, “Parallelized architecture of multiple classifiers for face detection,” in ASAP, 2009.
[4] M. Hiromoto, H. Sugano, and R. Miyamoto, “Partially parallel architecture for Adaboost-based detection with haar-like features,” IEEE Trans. Circuits Syst. Video Technol., vol. 19, pp. 41–52, 2009.
[5] B. Brousseau and J. Rose, “An energy-efficient, fast FPGA hardware architecture for OpenCV-compatible object detection,” in FPT, 2012.
[6] D. Hefenbrock, J. Oberg, N. Thanh, R. Kastner, and S. Baden, “Accelerating Viola-Jones face detection to FPGA-level using GPUs,” in FCCM, 2010.
[7] D. Oro, C. Fern´andez, J. R. Saeta, X. Martorell, and J. Hernando, “Real-time GPU-based face detection in HD video sequences,”
in ICCV Workshops, 2011.
[8] S. C. Tek and M. Gokmen, “GPU accelerated real-time object detection on high resolution videos using modified census transform,” in VISAPP, 2012.
[9] L. Acasandrei and A. Barriga, “Accelerating Viola-Jones face detection for embedded and SoC environments,” in ICDSC, 2011.
[10] C. Lampert, M. Blaschko, and T. Hofmann, “Beyond sliding windows: object localization by efficient subwindow search,”
in CVPR, 2008.
[11] N. J. Butko and J. R. Movellan, “Optimal scanning for faster objectdetection,” in CVPR, 2009.
[12] V. B. Subburaman and S. Marcel, “Alternative search techniques for face detection using location estimation and binary features,” Comput. Vision Image Understanding, vol. 117, no. 5, pp. 551–570, 2013.
[13] V. Jain and E. Learned-Miller, “FDDB: A benchmark for face detection in unconstrained settings,” University of Massachusetts, Amherst, Tech.
Rep. UM-CS-2010-009, 2010.
[14] G. Bradski, “The OpenCV Library,” Dr. Dobb’s J. Softw. Tools, 2000.
[15] H. Rowley, S. Baluja, and T. Kanade, “Neural network-based face detection,” IEEE Trans. Pattern Anal. Mach. Intell, vol. 20, pp. 23–38, 1998.
[16] M. Everingham, L. J. V. Gool, C. K. I. Williams, J. M. Winn, and A. Zisserman, “The pascal visual object classes (VOC) challenge,” Int. J. Comput. Vision, vol. 88, no. 2, pp. 303–338, 2010.
[17] M. Geilen, T. Basten, B. D. Theelen, and R. Otten, “An algebra of pareto points,” Fundam. Inform., vol. 78, no. 1,
pp. 35–74, 2007.
[18] C. Goutte and ´ E. Gaussier, “A probabilistic interpretation of precision, recall and f-score, with implication for evaluation,”
in ECIR, 2005.
ссылка на оригинал статьи http://habrahabr.ru/post/216019/
Добавить комментарий