Данные, которые показывает автор Netmap Luigi Rizzo весьма впечатляют. Как известно, по опубликованным Luigi тестам, Netmap легко генерирует 14Mpps и позволяет «поднять» поток в 14Mpps из сетевого кабеля в userspace, используя только одном ядро процессора Core i7. Стало интересно применить эту технологию в фильтрах очистки трафика.
Итак, на прошедшей в сентябре выставке InfosecurityRussia 2013 мы представили стенд, на котором по запросу всех желающих генерировали различные атаки и демонстрировали защиту от них, собирая статистику и отрисовывая различные графики Zabbix’ом.
В статье мы сконцентрируемся на некоторых особенностях архитектуры NETMAP, а также показателях скорости обработки пакетов, которые с его помощью получены на «обычном» железе.
1. Краткое введение в NETMAP
Прежде, чем перейти к замерам производительности и тестам, несколько слов следует написать о фреймворке NETMAP, который делает основную работу по скоростной обработке пакетов. Детальный обзор NETMAP, сделанный на основе компиляции всех материалов, представленных его автором, сделан мной ранее в этой статье (http://habrahabr.ru/post/183832/ ). Для тех, кому нет необходимости в столь глубоком погружении предлагается краткое описание фреймворка.
1.1. Структуры данных NIC и операции с ними
Сетевые адаптеры (NIC) для обработки входящих и исходящих пакетов используют кольцевые очереди (rings) дескрипторов буферов памяти, как показано на Рис.
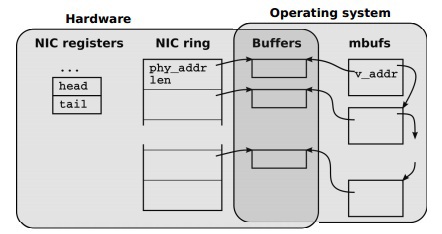
«Структуры данных NIC и их взаимосвязь со структурами данных OS»
Каждый слот в кольцевой очереди (rings) содержит длину и физический адрес буфера. Доступные (адресуемые) для CPU регистры NIC содержат информацию об очередях для приёма и передачи пакетов.
Когда пакет приходит в сетевую карту, он размещается в текущий буфер памяти, его размер и статус записываются в слот, а информация о том, что появились новые входящие данные для обработки, записывается в соответствующий регистр NIC. Сетевая карта инициирует прерывание, чтобы сообщить CPU о поступлении новых данных.
В случае, когда пакет отправляется в сеть, NIC предполагает, что OS заполнит текущий буфер, разместит в слоте информацию о размере передаваемых данных, запишет в соответствующем регистре NIC количество слотов для передачи, что инициирует отправку пакетов в сеть.
В случае высоких скоростей приёма и передачи пакетов, большое количество прерываний может привести к невозможности выполнить какую-либо полезную работу («receive live-lock»). Для решения этих проблем в OS используют механизм polling или interrupt throttling. Некоторые высокопроизводительные NIC используют множественные очереди для приёма/передачи пакетов, что позволяет распределить нагрузку на процессор по нескольким ядрам или разделить сетевую карту на несколько устройств, для использования в виртуальных системах, работающих с такой сетевой картой.
1.2. Проблемы с обработкой пакетов стеком TCP/IP OS
OS осуществляет копирование структур данных NIC в очередь из буферов памяти, которая является специфической для каждой конкретной OS. В случае FreeBSD это mbufs её эквиваленты sk_buffs (Linux) и NdisPackets (Windows). По своей сути эти буферы памяти являются контейнерами в которых содержится большое количество метаданных о каждом пакете: размер, интерфейс с/на которого пакет пришёл, различные атрибуты и флаги определяющие порядок обработки данных буфера памяти в NIC и/или OS.
Драйвер NIC и стек TCP/IP операционной системы (далее host stack), как правило, предполагают, что пакеты могут быть разбиты в произвольное количество фрагментов, следовательно и драйвер и host stack должны быть готовы к обработке пакетной фрагментации.
При передаче пакета между сетевым кабелем и userspace выполняется несколько операций копирования:
- Заполнение структур данных NIC данными из сети
- Копирование данных из структур данных NIC в mbuf’ы / sk_buf’ы / NdisPackets
- Копирование данных из mbuf / sk_buf / NdisPackets в userspace
Как видно, соответствующее API экспортируемое в userspace предполагает, что различные подсистемы могут оставить пакеты для отсроченной обработки, следовательно буферы памяти и метаданные не могут быть просто переданы по ссылке в процессе обработки вызова, но они должны быть скопированы или обработаны механизмом подсчёта ссылок (reference counting). Всё это является платой высокими overhead’ами за гибкость и удобство работы.
Рассмотренный в предыдущей статье анализ пути прохождения пакета через системный вызов sendto(), далее сетевой стек OS FreeBSD в сеть показал, что пакет проходит через несколько очень затратных уровней. Используя это стандартное API, не просматривается возможностей для обхода механизмов выделения памяти и копирования в mbuf’ах, проверке правильных маршрутов, подготовке и конструированию заголовков TCP/UDP/IP/MAC и в конце этой цепочки обработки, преобразования структур mbuf и метаданных в формат NIC для передачи пакета в сеть. Даже в случае локальной оптимизации, например, кэширования маршрутов и заголовков вместо их построения с нуля, нет радикального увеличения скорости, которая требуется для обработки пакетов на интерфейсах 10 Gbit/s.
1.3. Техники увеличения производительности, при обработке пакетов применяемая в NETMAP
Одним из простых способов избежать дополнительного копирования в процессе передачи пакета из kernel space в user space и наоборот является возможность разрешить приложению прямой доступ к структурам NIC. Как правило, для этого требуется, чтобы приложение работало в ядре OS. Примерами могут быть проект программного роутера Click или генератор трафика kernel mode pkt-gen. Наряду с простотой доступа, kernel space является очень хрупкой средой, ошибки в которой могут привести к падению системы, поэтому более правильный механизм это экспортирование пакетных буферов в userspace.
NETMAP, представляет собой систему, которая предоставляет userspace приложению очень быстрый доступ к сетевым пакетам, как для приёма, так и для отправки, как при обмене с сетью, так и при работе со стеком TCP/IP OS (host stack). При этом, эффективность не приносится в жертву рискам, возникающим при полном открытии структур данных и регистров сетевой карты в userspace. Фреймворк самостоятельно управляет сетевой картой, операционная система, при этом, выполняет защиту памяти.
Отличительной особенностью NETMAP является тесная интеграция с существующими механизмами OS и отсутствие зависимости от аппаратных особенностей специфических сетевых карт. Для достижения желаемых высоких характеристик производительности NETMAP использует несколько известных техник:
- Компактные и лёгкие структуры метаданных пакета. Простые для использования, они скрывают аппаратно-зависимые механизмы, предоставляя удобный и простой способ работы с пакетами. Кроме того, метаданные NETMAP построены таким образом, чтобы обрабатывать множество самых разных пакетов за один системный вызов, уменьшая, таким образом, накладные расходы на передачу пакетов
- Линейные preallocated буферы, фиксированных размеров. Позволяют уменьшать накладные расходы на управление памятью
- Zero copy операции при форвардинге пакетов между интерфейсами, а также между интерфейсами и host stack’ом
- Линейные preallocated буферы, фиксированных размеров. Позволяют уменьшать накладные расходы на управление памятью
- Zero copy операции при форвардинге пакетов между интерфейсами, а также между интерфейсами и host stack’ом
- Поддержка таких полезных аппаратных особенностей сетевых карт, как множественные аппаратные очереди
В NETMAP каждая подсистема делает ровно то, для чего предназначена: NIC пересылает данные между сетью и оперативной памятью, ядро OS выполняет защиту памяти, обеспечивает многозадачность и синхронизацию.
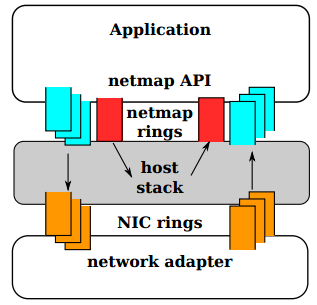
Рис. В режиме NETMAP очереди NIC отключены от стека TCP/IP OS. Обмен между сетью и host stack осуществляется только через NETMAP API.
На самом верхнем уровне, когда приложение через NETMAP API переводит сетевую карту в режим NETMAP, очереди NIC отсоединяются от host stack. Программа, таким образом получает возможность контролировать обмен пакетами между сетью и стеком OS, используя для этого кольцевые буферы, которые называются «netmap rings». Netmap rings, в свою очередь, реализованы в разделяемой памяти (shared memory). Для синхронизации очередей в NIC и стеке OS используются обычные системные вызовы OS: select()/poll(). Несмотря на отключение стека TCP/IP от сетевой карты, операционная система продолжает работать и выполнять свои операции.
2. Стенд для тестирования
Для демонстрации производительности фильтра очистки трафика DDOS, на прошедшей в сентябре 2013 г. выставке InfoSecurity Russia 2013, мы подготовили стенд, на котором генерировали и защищались от больших потоков трафика DDOS. Железо для стенда выбиралось самое обычное:
Генератор трафика/атак
- Процессор Intel Core i7-2600 3.4GHz TurboBoost
- RAM 8GB 1333MHz DDR3
- HDD SATA 500GB
- OS FreeBSD 9-STABLE
- Сетевая плата Intel X520 10Gbit/s SFP+ dual-port
Сервер фильтр DDOS
- Процессор Intel Xeon E3-1230 3.2GHz TurboBoost
- RAM 8GB 1333MHz DDR3
- HDD SATA 500GB
- OS FreeBSD 9-STABLE
- Сетевая плата Intel X520 10Gbit/s SFP+ dual-port
Коммутатор
- Juniper EX4200 with 2x10Gbit/s SFP+ interfaces
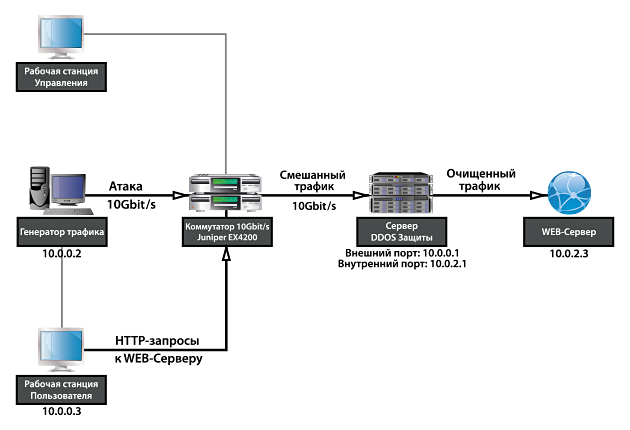
Стенд работает следующим образом:
По запросу, на генераторе стартуют разнообразные атаки с регулируемой мощностью по значениям PPS и Gbit/s. Трафик атак приходит в Juniper через 10Gbit/s интерфейс и через второй 10Gbit/s интерфейс прилетает в сервер DDOS-защиты. Легальный трафик приходит в Juniper от рабочей станции через 1Gbit/s интерфейс и смешивается в коммутаторе трафиком атаки. На сервере DDOS-защиты выполняется очистка трафика и очищенный трафик отправляется на защищаемый сервер. В качестве защищаемого сервиса используется HTTP web-сайт, главная страница которого содержит время обращения к странице.
3. Упрощённое описание механизмов грубой очистки трафика
Сервер DDOS-защиты, помимо модулей работы с NETMAP и стеком TCP/IP, содержит несколько фильтров, через которые проходят сетевые пакеты.
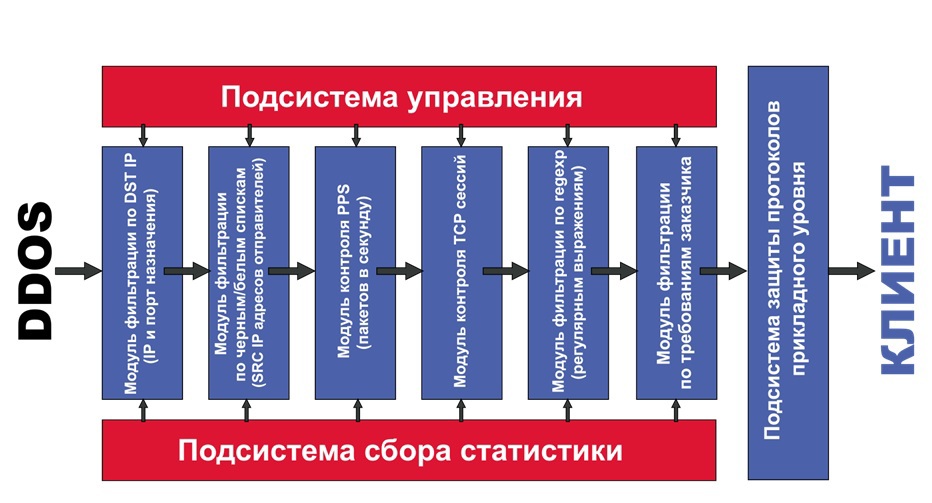
- Первый фильтр заключается в проверке адреса назначения пакета, протокола и порта назначения. Нет смысла тратить ресурсы на обработку пакетов, если например tcp/порт, в который прилетел пакет, не обслуживается. Такие пакеты сразу «забываются» в netmap-рингах и затираются вновь прибывшими
- Второй фильтр работает по ограничению pps / полосы пропускания для ip-адреса, либо ip-сети / группы сетей и т.п. Используя этот фильтр, например, можно разрешить пропускать строго заданное количество пакетов в секунду от «любого» ip-адреса из сети Интернет, пакеты, идущие на определённый адрес и порт защищаемого сервера. Все пакеты, сверх указанного лимита будут «убиты»
- Третий фильтр представляет собой реализацию механизма syncookie для защиты от SYNflood-атак. В случае, если приходит легальное соединение, выполняется соединение клиента с защищаемым сервером, для увеличения производительности, используется техника TCP splicing ( www.pam2010.ethz.ch/papers/full-length/5.pdf )
- Последний фильтр представляет собой движок на базе поиска по «регулярным выражениям», работающий на добавление ip-адресов в «чёрные», «белые», а также «чёрно-серые» и «бело-серые» списки, в которых IP-адрес находится временно
4. Замеры скорости обработки пакетов на стенде выставки Infosecurity 2013
В качестве программного обеспечения для генерации трафика используется генератор трафика, сделанный, также, на базе NETMAP и реализующий следующие виды атак:
- UDP-flood короткими и/или длинными пакетами
- Synflood короткими и/или длинными пакетами
В атаке используется параметр – количество SRC_IP в секунду, от которых идёт трафик. Очевидно, что не имеет особенного смысла тестировать DDOS генерируя атаку с одного ip-адреса. В тестах используются от 160 тыс. до 1600 тыс. новых IP-адресов каждую секунду для генерирования атаки.
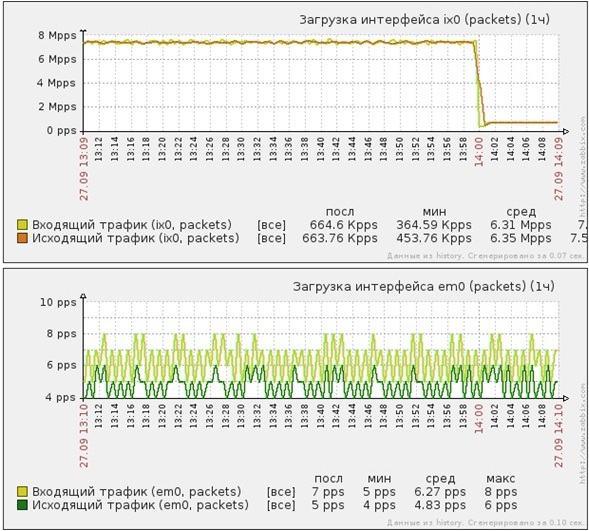
Атака UDP-flood короткими пакетами на 53 порт защищаемого web-сервера
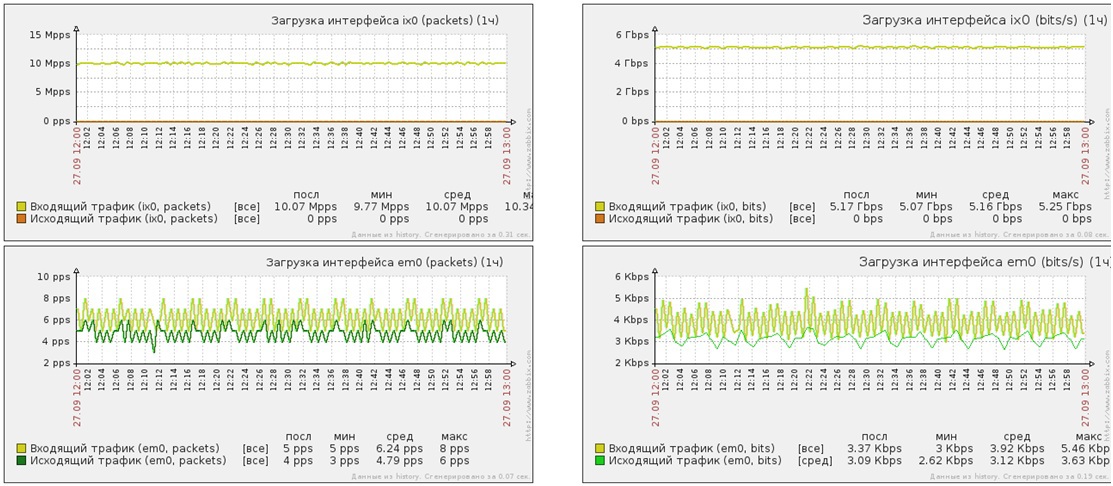
- Мощность атаки — 10 миллионов PPS
- Мощность атаки — 5Gbit/s
- Трафик после очистки — 8 PPS
- Трафик после очистки — 5Kbit/s
Атака SYN-flood короткими, затем длинными пакетами на 80 порт защищаемого сервера
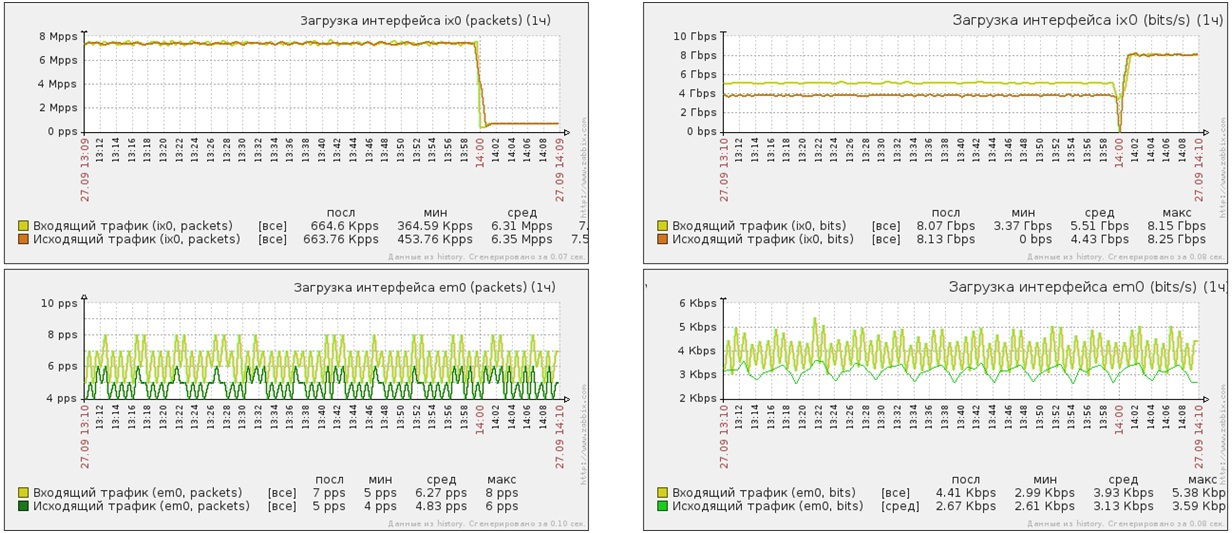
Атака SYNflood короткими пакетами
- Мощность атаки — 7 миллионов PPS
- Мощность атаки — 5 Gbit/s
- Трафик после очистки — 8 PPS
- Трафик после очистки — 5Kbit/s
Атака SYNflood длинными пакетами
- Мощность атаки — 600 тысяч PPS
- Мощность атаки — 8 Gbit/s
- Трафик после очистки — 8 PPS
- Трафик после очистки — 5Kbit/s
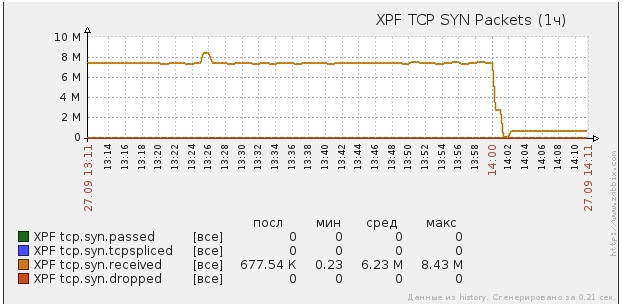
Рис. Входящие SYN-пакеты
Загрузка CPU под атакой UDP / SYN flood
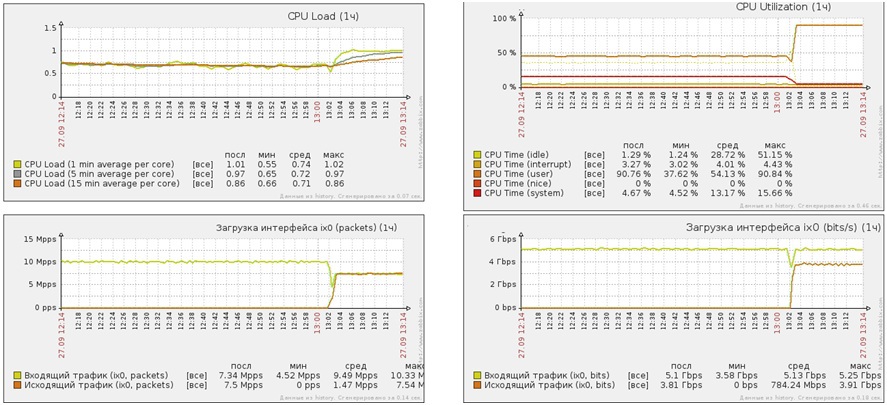
Атака UDP flood короткими пакетами
- Мощность атаки — 10 миллионов PPS
- Мощность атаки — 5 Gbit/s
- Средняя загрузка CPU (user) 50%
- Средняя загрузка CPU (system) 15%
Атака SYN flood короткими пакетами
- Мощность атаки в PPS 7 миллионов PPS
- Мощность атаки в Gbit/s 5 Gbit/s
- Средняя загрузка CPU (user) 90%
- Средняя загрузка CPU (system) 5%
Продолжительная работа под Flood-атаками
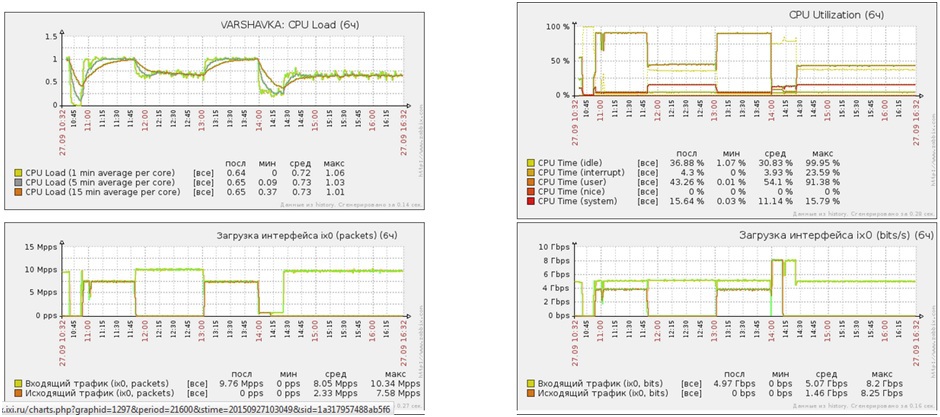
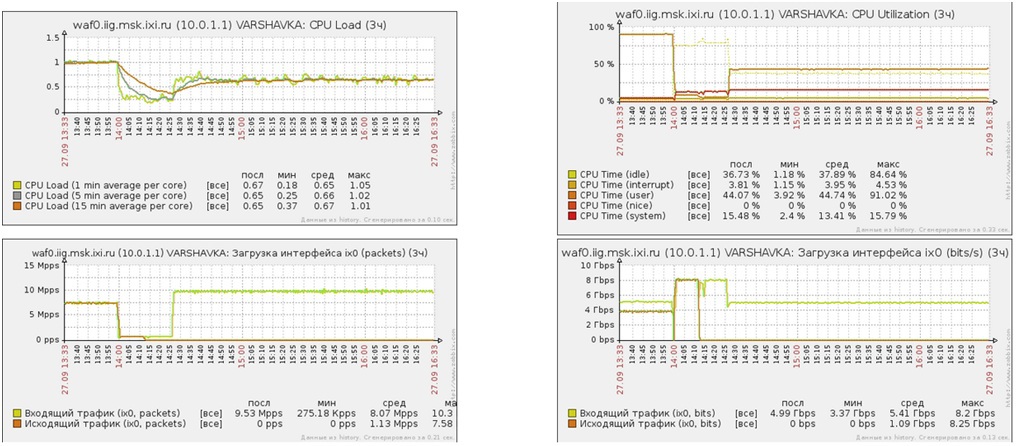
- Продолжительность атак 6 часов
- Виды атак SYNflood / UDPflood
- Мощность атак 5 Gbit/s — 10 Gbit/s
- Средняя загрузка CPU (user) 50%
- Средняя загрузка CPU (system) 11%
5. Заключение
Фреймворк NETMAP может быть использован для работы в качестве эффективных фильтров очистки трафика, а также в качестве эффективного инструмента для разработки средств нагрузочного тестирования. В качестве главного преимущества, можно отметить то, что программы, построенные на базе фреймворка NETMAP, работают на обычном железе и достигают очень высокой производительности, что позволяет использовать их в качестве замены существенно более дорогим альтернативным решениям, которые предлагаются компаниями Arbor, Radware, Spirent, RioRey etc.
ссылка на оригинал статьи http://habrahabr.ru/post/220331/
Добавить комментарий