Пользовательская активность в браузере, поисковике или на конкретном сайте является богатым источником полезной информации: переформулировки запросов, навигация до и после запроса/посещения портала. К сожалению, эта информация никак не структурирована и очень зашумлена. Основной задачей становится обработка, структуризация и очистка сырых данных. я хотел бы предложить метод для автоматического разделения пользовательской активности на логически связанные компоненты.
Пользователь взаимодействует с поисковиком и браузером непрерывно:
- задает запросы;
- кликает на документы в выдаче;
- запрашивает новые страницы в выдаче;
- перемещается между страницами, используя ссылки и навигационные кнопки браузера;
- переключается между вкладками;
- скроллит страницы, водит по ним мышкой;
- уходит в другие поисковики.
Важно научиться рассматривать эти события не только атомарно, но и связывать между собой лучше понимая, что движет пользователем. Одно событие ведет за собой другое, и если мы научимся их связывать между собой, мы сможем лучше понимать, что движет пользователем.
В связи с изучением пользовательских сессий возникает несколько задач:
- определение границ логических сессий;
- предсказание следующего действия в сессии;
- извлечение сессионной информации для помощи в совершении следующего действия;
- моделирование действий пользователя в рамках одной сессии;
- Оценка скрытых данных в течение сессии – информационная потребность, удовлетворенность сессией, усталость.
Далее нам потребуется сформулировать несколько определений и ввести несколько обозначений. Главный герой моего рассказа – браузерная сессия – это последовательность страниц, посещенных пользователем в течение дня: Du – (d1…….dn). Второстепенный объект – запросная сессия – последовательность запросов заданных пользователем в течение одного дня: Qu – (q1…….qn). Vs также хотим выделить логическую браузерную сессию (и логическую запросную сессию) – часть браузерной сессии, состоящую из логически связанных страниц, посещенных с одной и той же информационной потребностью g:
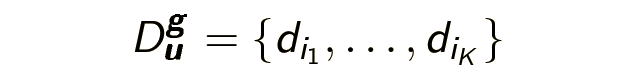
Рассмотрим пример того, какой может быть пользовательская сессия:
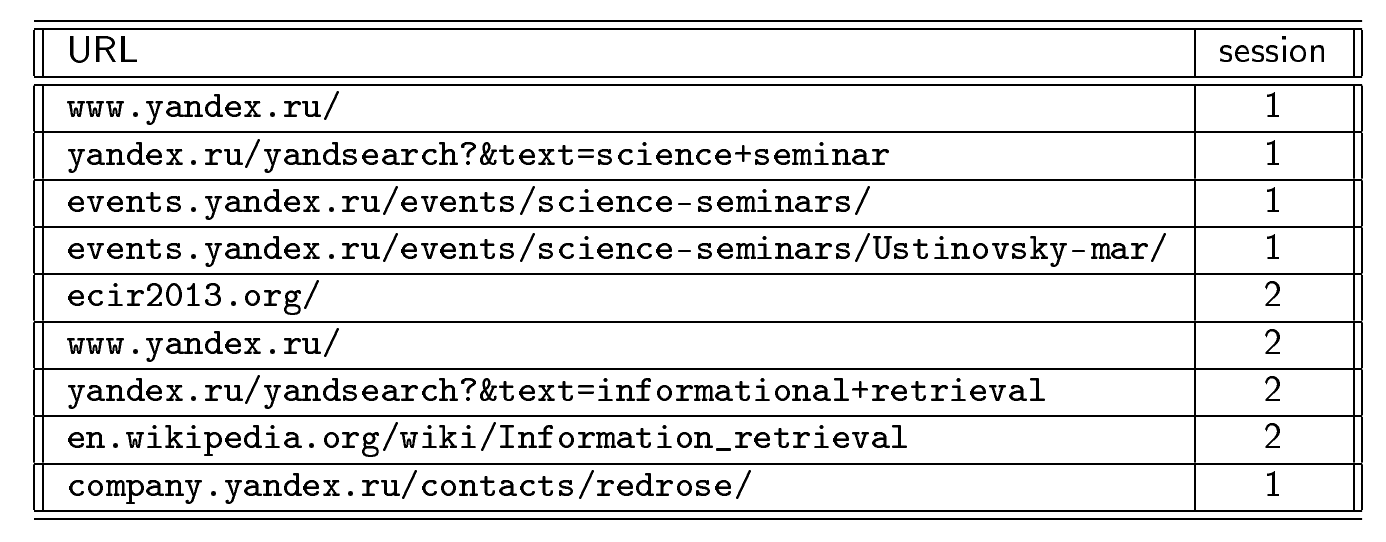
Пользователь заходит на страницу поисковика, начинает искать информацию про научные семинары, перешел на страницу со списком всех семинаров Яндекса и узнал, что 28 марта будет интересный ему доклад и прочитал его анонс. Вдруг он заметил в анонсе какое-то неизвестное ему понятие и захотел посмотреть, что это такое. Он переходит по ссылке на сайт ecir2013.org. В этот момент у него поменялась информационная потребность: в начале он хотел посмотреть информацию про семинары, теперь он заинтересовался конференцией. Посмотрев на главную страницу конференции, он находит еще одно неизвестное понятие – информационный поиск. Он снова идет в поисковик и вводит там запрос [информационный поиск]. В поиске он находит станицу в Википедии, читает про нее, решает, что ему эта тема интересна, и возвращается на портал Яндекса, чтобы посмотреть, где же будет проходить семинар, т.е. возвращается к исходной логической сессии.
Конечно, это искусственный пример, но на нем можно проследить некоторые важные особенности логических сессий:
- Как правило, логические сессии перемежаются.
- Некоторые страницы участвуют в нескольких логических сессиях.
- Пользовательская потребность изменяется до задания запроса.
Сделаем небольшое отступление и посмотрим, что можно понять глядя на запросные сессии: какую информацию о пользователе можно извлечь. Пользователи могут задавать разные запросы по одной и той же тематике, если сразу не удается найти необходимую информацию. Но как они будут себя вести, если ответ не находится на первой странице поисковой выдачи, второй, третьей и т.д. На графике представлены данные для запросных сессий разной длины.
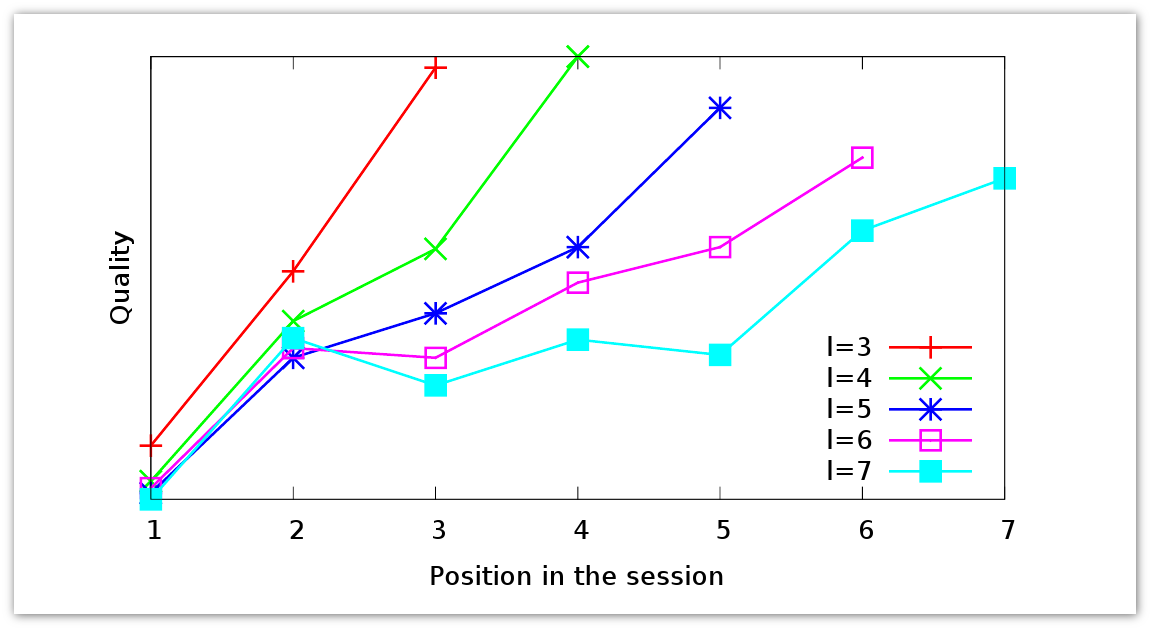
Красным отмечена запросная сессия длиной в три запроса. Видно, что в течение сессии качество ответа растет. Пользователь формирует все более хорошие ответы. Та же тенденция прослеживается на более длинных сессиях. Сколь бы долго пользователь не менял формулировку запроса, в среднем качество выдачи улучшается. Пользователь понимает, как лучше переформулировать запрос.
Как правило Du сегментируется на основе периода неактивности τ (здесь τ(d) – момент открытия d). di и di+1 принадлежат одной сессии, соответственно, τ(di+1) — τ(di) < τ. Это самый популярный и распространенный подход. Но очевидно, что он не работает, когда сессии перемежаются друг с другом. Если пользователь вернется к какой-то теме, с точки зрения этого подхода, это уже будет новая логическая сессия.
Задача логического разбиения запросных сессий уже решалась в двух работах:
- P. Boldi et al. The Query-flow Graph: Model and Applications.
- R. Jones et al. Beyond the Session Timeout: Automatic Hierarchical Segmentation of Search Topics in Query Logs.
Там применялись разные методы и преследовались разные цели, но авторы обеих работ утверждают, что их методы позволяют значимо улучшить временное разбиение. Это и смотивировало меня попытаться найти алгоритм, который работал бы лучше для браузерных сессий.
В своем исследовании я решил поднять несколько вопросов:
- Возможно ли уточнить логическое разбиение запросных сессий до уровня браузерный сессий?
- Насколько качественное разбиение дает подход, основанный на периоде неактивности?
- Как разные алгоритмы кластеризации влияют на качество сегментации?
- Какие источники факторов важны для логической сегментации?
Метод
В качестве исходных данных применялись сырые браузерные сессии – последовательности страниц, посещенных пользователем. Сама же сегментация строится в два шага:
- Попарная классификация. Предсказываем, с одной ли целью пользователь посетил пару страниц (di,dj): учим функцию p(di,dj)∈[0;1], оценивающую вероятность принадлежности di,dj одной логической сессии.
- Кластеризация. Для разных оценок p(di,dj) кластеризовать полный граф на N вершинах di с весами ребер p(di,dj) в сильно связные компоненты
В результате у нас получается сегментация:

Рассмотрим каждый из двух шагов подробнее. Начнем с классификации. В машинном обучении всегда в первую очередь нужно собрать набор примеров. Мы разметили руками достаточно большой набор пар на предмет того, относятся ли они к одной логической сессии. Далее для каждой оценочной пары (d, d’) извлекаем факторы
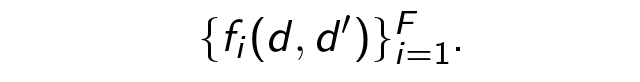
После этого учим классификатор p(di,dj).
В качестве модели для классификатора мы используем дерево решений с логистической функцией потерь. Она максимизирует вероятность корректной классификации всех пар:
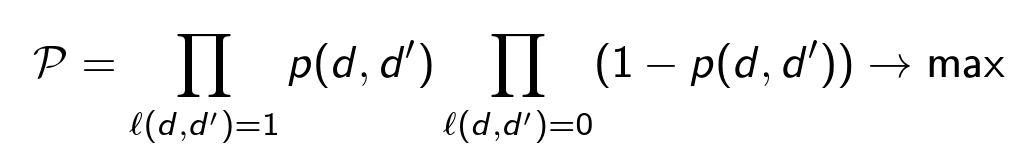
Для каждой пары (d, d’) мы извлекаем четыре типа факторов (всего около 29 штук):
- Факторы на основе URL.
- Текстовые факторы.
- Сессионные факторы. Время между посещениями d, d’, количество документов между ними, был ли переход по ссылкам.
- Контекстные обобщения. Те же, что и в предыдущих трех пунктах, только вычисление для документа d", предшествующего d’.
Будем считать, что классификация произведена, и теперь наша цель – кластеризовать полный граф, найти разбиение, максимизирующее вероятность (значения ρ фиксированы, разбиение изменяется):
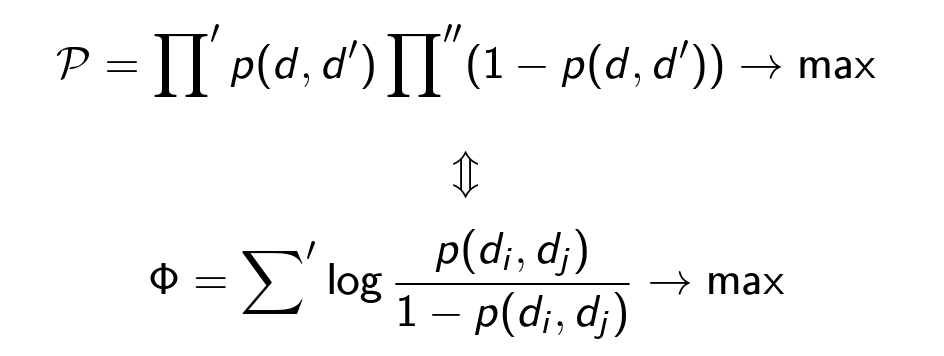
Π’ – произведение по всем парам (d, d’) из одного кластера;
Σ – сумма по всем парам (d, d’) из разных кластеров;
Π" – произведение по всем парам (d, d’) из всех кластеров.
Постановка задачи выглядит неплохо, однако в таком виде она оказывается NP-полной. Т.е. при большом размере сессий кластеризация будет очень затратна вычислительно. Поэтому приходится применять различные жадные алгоритмы. При работе с жадными алгоритмами подобного типа всегда возникает баланс между скоростью, качеством и областью применимости, который нужно подбирать непосредственно под конкретную задачу. Я разбил все жадные алгоритмы на две области применимости. Первая – это кластеризация в реальном времени: каждый новый документ dnew добавляется к текущему кластеру (g1, g2) или образует новый (gnew).
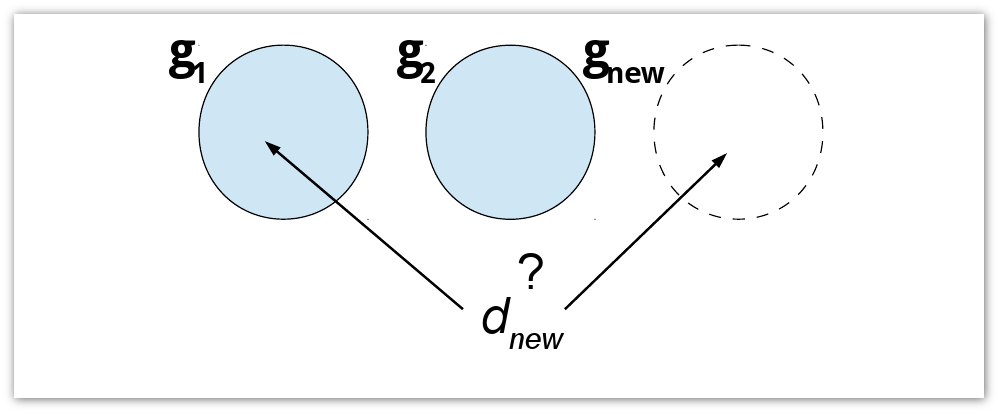
Я использовал три жадных алгоритма:
- Максимальное правдоподобие последней страницы. dg – последняя страница сегмента g. Все p(dg,dnew) < 1/2, следовательно, начинаем новую сессию. Иначе добавляем dnew к сессии с максимальной вероятностью.
- Максимальное правдоподобие всех страниц. Все p(d,dnew) < 1/2, следовательно начинаем новую сессию. Иначе добавляем dnew к сессии, содержащей документ с максимальной вероятностью.
- Жадное добавление. Добавление dnew чтобы максимизировать рост Φ. Если Φ всегда уменьшается для всех g, начинаем новый сегмент.
Второй тип алгоритмов работает со всей дневной активностью пользователя сразу, т.е. проводит пост-кластеризацию. К этому типу относится жадное слияние. Мы создаем N – |Du| кластеров. Жадным образом сливаем существующие кластеры, пока можно увеличить Φ.
Сложность первого алгоритма O(G × N), где G – количество сегментов. У всех остальных алгоритмов сложность O(N2).
Эксперименты
В качестве сырых данных были использованы анонимизированные браузерные логи, собранные с помощью тулбара. Они содержали адреса публичных страниц, для каждой из которых извлекалось время посещения, источник посещения (если был переход по ссылке), текст документа и ссылки, по которым пользователь с них уходил (если это происходило). Для обучающей выборки каждая браузерная сессия была вручную поделена асессорами на логические сессии. Всего у нас было 220 браузерных логических сессий и 151 тысяча пар для обучения классификатора: 78 тысяч из одной сессии и 73 тысячи из разных. Средняя длина логической сессии составляла 12 страниц, а среднее число логических сессий у пользователя в день – 4,4.
В таблице ниже представлено качество временного разбиения и классификаторов, обученных на разных наборах факторов:
| Набор факторов | Временное разбиение | Все | Без контекста | Без текста |
| F-мера | 80% | 83% | 83% | 82% |
| Точность | 72% | 82% | 81% | 81% |
Существует метод, позволяющий посчитать вклад каждого фактора в процессе машинного обучения. В таблице ниже приведены 10 лучших факторов и их вклад.
| Rk | Фактор | Очки |
| 1 | время между d1 и d1 | 1 |
| 2 | LCS | 0.58 |
| 3 | LCS/length(url1) | 0.40 |
| 4 | LCS/length(url2) | 0.40 |
| 5 | # страниц между d1 b d1 | 0.33 |
| 6 | триграммное совпадение URL | 0.32 |
| 7 | контекстный LCS/length(url1) | 0.32 |
| 8 | один хост | 0.22 |
| 9 | LCS/length(url2) | 0.20 |
| 10 | контекстный LCS | 0.20 |
Как мы и ожидали, самый важный фактор – время между посещением документов. Также довольно естественно, что важную роль играет URL и LCS (длина общей подстроки URL). Какую-то роль играют контекстные факторы. При этом здесь нет ни одного текстового фактора.
Теперь перейдем к экспериментам в кластеризации. Мера качества алгоритмов основана на Rand Index. Для двух сегментаций S1, S2 множества Du он равен доле одинаково соответственных пар документов:
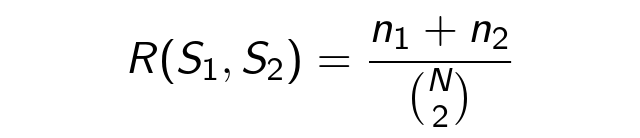
Здесь n1 – # пар из одного сегмента S1, S2, n2 – # пар из разных сегментов S1, S2, N – # элементов в Du. Далее S1 – идеальная сегментация, а S2 – оцениваемая. R(S1, S2) представляет собой точность соответствующего классификатора. На графике ниже представлен Rand Index для периода активности в τ:
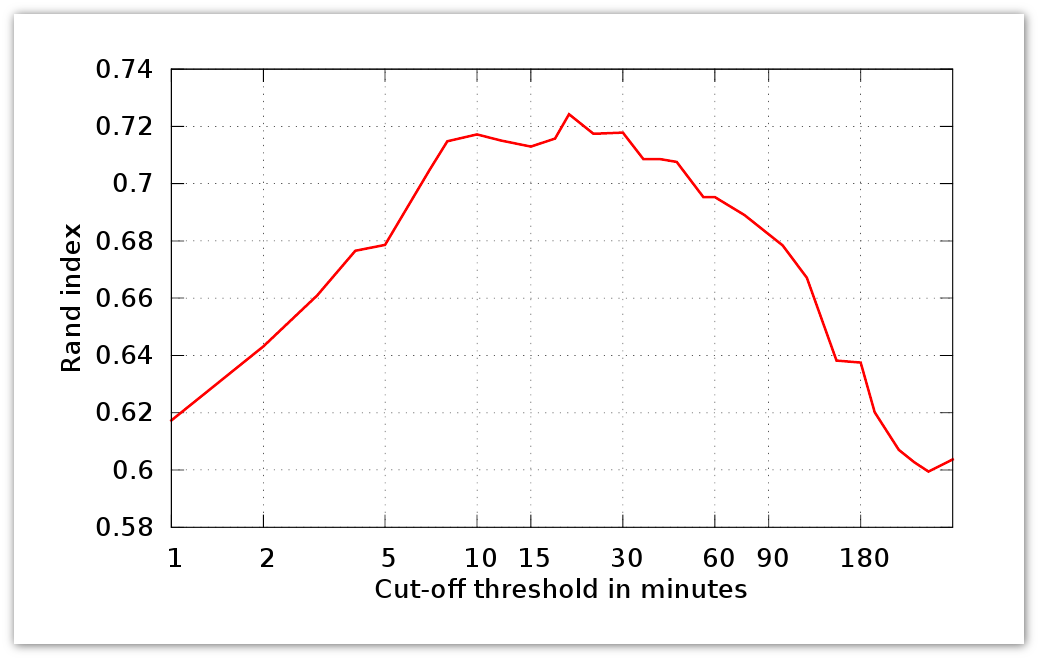
Теперь посмотрим, как работают описанные нами выше алгоритмы:
| Метод | Rand Index | Сложность |
| Временной | 0.72 | — |
| Макс. правдоподобие посл. страниц | 0.75 | O(N × G) |
| Макс. правдоподобие всех страниц | 0.79 | O(N2) |
| Жадное добавление | 0.82 | O(N2) |
| Жадное слияние | 0.86 | O(N2) |
Качество классификатора соответствующего жадному слиянию (0.86) даже выше, чем у исходного классификатора (0.82).
Выводы
- Предложен метод автоматической обработки браузерных логов, уточняющий разбиение запросных логов.
- Мы свели задачу сегментации к хорошо изученным задачам классификации и кластеризации.
- Хотя временной подход довольно неплох, более сложные алгоритмы кластеризации ощутимо его превосходят.
- Контекстные и текстовые факторы оказываются гораздо менее важными для определения логических связей между страницами в пределах одной сессии, чем факторы основанные на сессионных данных и совпадении URL.
Ближайший научно-технический семинар в Яндексе состоится 10 июня. Он будет посвящен теме рекомендательных систем и распределенных алгоритмов.
ссылка на оригинал статьи http://habrahabr.ru/company/yandex/blog/224719/
Добавить комментарий