
Работа с БД: список JDBC подключений с указанием параметров подключений.
Компания из ТОП-5 в России зарабатывает в среднем от 7 до 9 миллионов долларов за час. Соответственно, технический простой длиной в два часа, который удалось сократить до одного часа нечеловеческим усилием воли, стоит именно эту сумму.
BSM — класс систем, разработанный специально для тех, кто вдруг осознал, что одна минута в нашей сегодняшней программе равна по цене квартире в Москве. И очень хочет, чтобы простоя не было.
Сейчас расскажу, как мы внедряли такие системы.
Пример чисто софтверного решения
В нефтяных компаниях, например, есть набор ПО для учёта поставок, который, по сути, является ERP. Без этого компонента работа компании встаёт, пока «подземные гномы» не починят всё обратно.
В одной такой компании на каждое технологическое звено стояла своя система мониторинга, и если где-то что-то случалось, первым интересным квестом был поиск проблемы. Он и занимал до половины времени от каждого простоя. Мы развернули систему мониторинга, которая позволяла чётко найти проблему. И если раньше на поиск и устранение проблем в работе ПО могло уйти от нескольких часов до нескольких дней, то новое решение позволило значительно сократить время определения основной причины проблемы. Количество сбоев сейчас сильно меньше, сроки восстановления работоспособности системы тоже уменьшились.
Теперь система просто показывает, где и что не так. Чаще всего речь о конкретном не отвечающем или некорректно отвечающем сервисе, который достаточно перезапустить для продолжения работы. Хочу подчеркнуть, что в аналогичных этому случаях пропадает вся «бодаловка» с поиском того, кто отвечает за проблему – вместо решения вопроса, на чьей стороне затык (а это случается при множестве отделов и контрагентов), можно сразу бежать и устранять.
Интеграция с железом
Системы BSM могут интегрироваться и с железом. Чтобы проиллюстрировать работу в таком случае, расскажу про то, как BSM ставится в аэропорту.
Итак, есть аэропорт. В нём критичными объектами являются сервера, СХД и вообще всё, что можно отнести к классу «IT-решения местного ЦОДа». Но есть ещё и, например, система навигации, которая чуть ли не голосом GladOS время от времени сообщает, куда и какому пассажиру идти. В случае её падения, конечно, можно объявлять голосом живого человека, но лучше, конечно, этого избежать – репутация, излишняя паника… Ещё одна критичная система – это система управления багажом. Если она встаёт или начинает выдавать багаж в другую сторону, весь терминал перестаёт обслуживать пассажиров.
Соответственно, мы подходим следующим образом:
- Выполняем полное обследование критичности систем.
- Ищем бутылочные горлышки.
- Проектируем решение. В нашем случае на каждую систему нужно придумать метрику, проверяющую её работу. Например, в случае багажа – мы можем подключиться к системе управления распределеним багажа и отследить метрики указывающие на перебои или ухудшение качества сервиса. В случае работы с СХД – мы используем просто уровень нагрузки на неё для каждого процесса.
- Разворачиваем само решение. Это база данных с шаблонами «хорошего» и «плохого» поведения, набор датчиков и сборщиков информации (как в виде железа, так и в виде программных агентов), сервер приложений, сервер обработки, система оповещения.
- Если надо, настраиваем автоматизацию на уровне «событие – ответ». К примеру, если перестаёт отвечать одно из приложений – можем провести автоматизированную диагностику приложения и либо восстановить работу автоматически, либо, если восстановление работы нельзя формализовать в виде исполнимого алгоритма, автоматически выполнить переключение на другой экземпляр приложения если это необходимо. Если багажная лента сломалась и информацию об этом можно получить из соответствующей системы управления, то можно автоматически вызвать ремонтника через SMS-оповещение, завести инцидент в системе класса HelpDesk и оповестить через электронную почту тех, кто учувствует процессе поддержки.
Контроль качества
Итак, BSM умеет сокращать время на определение места сбоя. Умеет отслеживать как софт, так и железо. И ещё внутри BSM-систем обычно есть симуляторы пользователей – это и тупые «роботы», которые могут проверить, например, доступность TCP порта или наличие отклика по GET для веб-странички. В более сложной реализации роботы могут эмулировать последовательность действий пользователей с интерфейсом приложения, причем записывать эти операции и переводить в языки сценариев можно в интерактивном визуальном режиме. Также существуют модули, которые с помощью сборки трафика до уровня приложений могут вычленять основные операции и последовательности связанных операций пользователя и собирать по н им статистику по задержкам и доступности операций для каждого реального пользователя.
Теперь небольшое лирическое отступление. Каждый раз, внедряя IT-систему, нужно думать про то, какие задачи она решает. Например, если обслуживание клиента без IT-системы длилось 12 минут, и была внедрена система автоматизации, позволяющая не заполнять часть бумаг руками, то хочется верить, что обслуживание теперь займёт максимум 10 минут, правда? И если оно занимает 14 минут вместо старых 12, то где-то проблема.
Так вот, одна из задач BSM – это отслеживание качества предоставления сервиса. Не только его доступности, но и поиска проблем с тормозящими интерфейсами, задержкой принятия решений у пользователей, лишних звеньев в цепочках.
Если принять за основу ситуацию, когда разработчик максимально добросовестно и качественно выполняет разработку и тестирование приложений и новых релизов, все равно необходим независимый контроль со стороны заказчика качественных показателей работы приложений, так как причина очевидна – никому кроме потребителей приложения и заказчика качественная работа приложения не нужна. А уровень качества может быть определён только заказчиком.
Но на практике случается, скорее так, что одним прекрасным утром после перевода в промышленную эксплуатацию очередного релиза приложения, пользователи приходят в офис и понимают, что всё тормозит. У нас был пример, когда BSM как раз собирала информацию по качественным показателям работы системы. Система стороннего разработчика после внедрения работала как часы. Но с увеличением числа пользователей начались сюрпризы с тем, что по части операций пользователи наблюдали существенные задержки с откликом приложения. BSM побегала как пользователь, повторяя основные шаблоны за живыми людьми – и поймала пару «бутылочных горлышек», где ответ интерфейса мог при ряде условий составлять до 12 секунд.
Такое решение можно построить, например, на HP Business Service Management (BSM) — это пример пары моих последних проектов. А если интегрировать сюда еще и HP Executive Scorecard (XS), то можно соотносить бизнес-операции с мониторингом с метриками управления ИТ-активами и обслуживания пользователей.
Код-ревью
Та же HP BSM не умеет «из коробки» смотреть, где проблема в коде. Тем не менее, достаточно много задач решения проблемы простоя упирается именно в это. И поэтому у неё есть удобная интеграция с продуктами для работы на уровне кода. В данном случае скриншоты из HP Diagnostics:
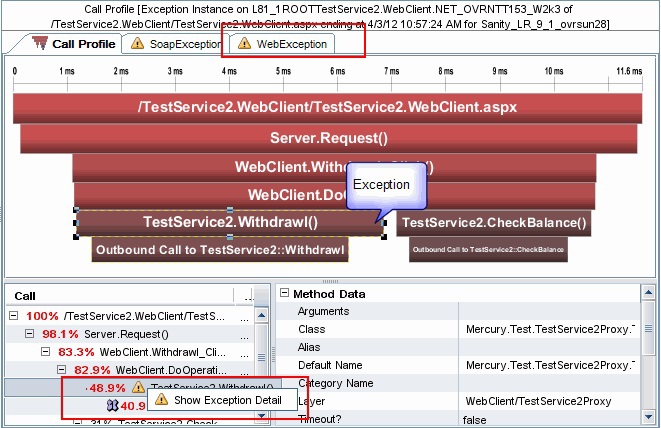
Горизонтальные полоски обозначают вызовы в приложении, их длина показывает время выполнения каждого вызова, и ниже в дереве показана их последовательность.
На этом же скриншоте показана возможность отслеживания исключений.
Просмотр вызовов позволяет понять из-за какой процедуры происходит замедление работы приложения.
Анализируя потоки данных и обнаруженные компоненты Diagnostics строит топологию работы компонент приложения между собой и клиентом:
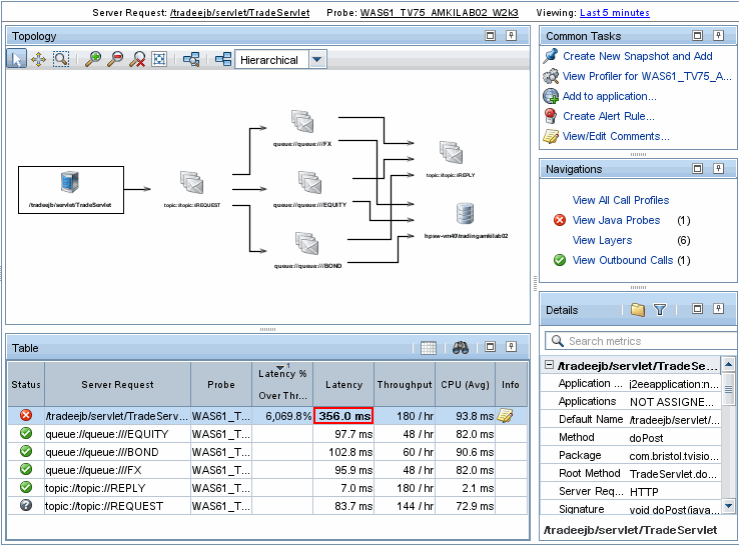
Полезно знать, где и что
Резюме
Несмотря на довольно простое описание BSM — дорогая и сложная игрушка, которая, фактически, разворачивает целую сеть сопровождающих процессов, собирающих данные ко всему, что запущено в IT-инфраструктуре.
В целом BSM внедряется около месяца-двух минимум, и позволяет на практике сократить время простоя критичных сервисов. Точнее, учитывая, что не бывает 100% надёжных сервисов – превратить неизбежный простой в более короткий.
ссылка на оригинал статьи http://habrahabr.ru/company/croc/blog/226471/
Добавить комментарий