
Привет, Хабрахабр!
Шифрование данных с помощью кватернионов выполнялось на FPGA DE5-NET, XeonPhi 7120P, GPU Tesla k20.
У всех троих приблизительно одинаковая пиковая производительность, но имеется разница в энергопотреблении.
Дабы не нагромождать статью лишней информацией предлагаю вам ознакомиться с краткой информацией о том что такое кватернион и матрица поворота в соответствующих статьях википедии.
Каким же образом можно зашифровать и расшифровать данные с помощью кватернионов? Довольно просто!
Для начала возьмем кватернион: q = w + x*i + y*j + z*k и составим на его основе матрицу поворота, которую назовем, например P(q).
Прим. картинка ниже из википедии и матрица там названа Q.
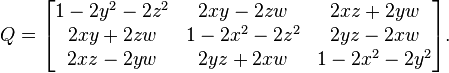
Для шифрования данных необходимо выполнить обычное умножение матриц, например: B’ = P(q) * B, где B — данные которые необходимо зашифровать, P(q) — матрица поворота, B’ — зашифрованные данные.
Для расшифровки данных, как вы уже скорее всего догадались, необходимо выполнить умножение «зашифрованной» матрицы B’ на обратную матрицу (P(q))^-1, таким образом мы получим исходные данные: B = (P(q))^-1 * B’.
Матрицы исходных данных заполняются на основе файлов или как показано в начале — изображений.
Ниже приведен вариант OpenCL кода для FPGA, необходимость передачи матрицы шифрования отдельными числами является вынужденной из-за особенностей платы.
__kernel void quat(__global uchar* arrD, uchar m1x0, uchar m1x1, uchar m1x2, uchar m1x3, uchar m1x4, uchar m1x5, uchar m1x6, uchar m1x7, uchar m1x8) { uchar matrix1[9]; matrix1[0] = m1x0; matrix1[1] = m1x1; matrix1[2] = m1x2; matrix1[3] = m1x3; matrix1[4] = m1x4; matrix1[5] = m1x5; matrix1[6] = m1x6; matrix1[7] = m1x7; matrix1[8] = m1x8; int iGID = 3*get_global_id(0); uchar buf1[3]; uchar buf2[3]; buf2[0] = arrD[iGID]; buf2[1] = arrD[iGID + 1]; buf2[2] = arrD[iGID + 2]; buf1[0] = matrix1[0] * buf2[0] + matrix1[1] * buf2[1] + matrix1[2] * buf2[2]; buf1[1] = matrix1[3] * buf2[0] + matrix1[4] * buf2[1] + matrix1[5] * buf2[2]; buf1[2] = matrix1[6] * buf2[0] + matrix1[7] * buf2[1] + matrix1[8] * buf2[2]; arrD[iGID] = buf1[0]; arrD[iGID+1] = buf1[1]; arrD[iGID+2] = buf1[2]; } При использовании XeonPhi результаты получились следующими (ось У — время, мс; ось Х — количество данных, Мб):

Как видно из графика, XeonPhi хорошо отзывается на усложнение задачи, то есть при использовании обычного настольного процессора время между 1 и 25 итерациями отличается приблизительно в 25 раз, в то время как здесь приблизительно в два раза.
К сожалению эти результаты далеко не самые лучшие, т.к. при программировании использовалась технология OpenMP и возможность автоматической оптимизации компилятора Intel. При программировании на более низком уровне, т.е. например intrinsic команд, результаты могут улучшиться в несколько раз.
При использовании Tesla k20 результаты получились следующими (ось У — время, мс; ось Х — количество данных, Мб):
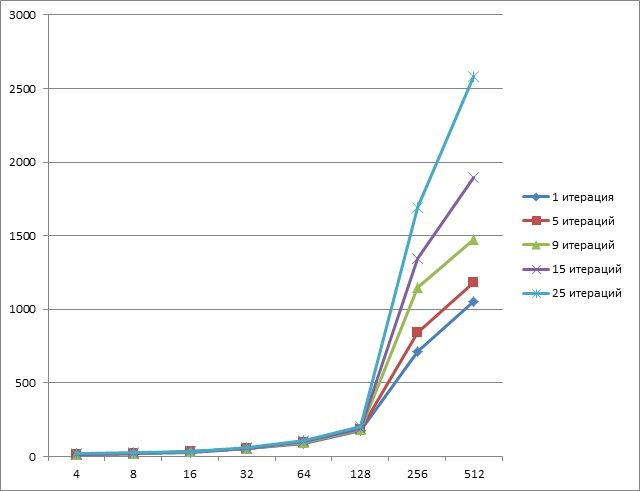
Как видно конвейеризация при небольшом размере данных отлично себя показывает.
При использовании FPGA De5-Net результаты получились следующими (ось У — время, мс; ось Х — количество данных, Мб):

На первый взгляд кажется что в графике присутствует ошибка, но на самом деле благодаря своей архитектуре FPGA показывает превосходный уровень конвейеризации вне зависимости от размера данных.
Благодарю вас за внимание к этой статье.
ссылка на оригинал статьи http://habrahabr.ru/post/226779/
Добавить комментарий