Вместо введения
Продолжаю вести серию отчетов по исследовательской работе, которую проводил на протяжении нескольких месяцев, обучаясь в университете и первые месяцы после защиты диплома. За все время работы многие элементы работы системы, которую разрабатывал, прошли переоценку и вектор работы в целом серьезно изменился. Тем интереснее было взглянуть на свой предыдущий опыт и опубликовать нигде не изданные материалы с новыми замечаниями В данном отчете публикую материалы, почти 2-х летней давности со свежими дополнениями, которые надеюсь еще не потеряли свою актуальность.
Содержание:
1. Поиск и анализ цветового пространства оптимального для построения выделяющихся объектов на заданном классе изображений
2. Определение доминирующих признаков классификации и разработка математической модели изображений мимики"
3. Синтез оптимального алгоритма распознавания мимики
4. Реализация и апробация алгоритма распознавания мимики
5. Создание тестовой базы данных изображений губ пользователей в различных состояниях для увеличения точности работы системы
6. Поиск оптимальной аудио-системы распознавания речи на базе открытого исходного кода
7. Поиск оптимальной системы аудио распознавания речи с закрытым исходным кодом, но имеющими открытые API, для возможности интеграции
8. Эксперимент интеграции видео расширения в систему аудио-распознавания речи с протоколом испытаний
Цели:
На основе накопленного опыта в предыдущих исследовательских работах, осуществить пробную интеграцию видео-расширения в систему аудио-распознавания речи, провести протоколы испытаний, сделать выводы.
Задачи:
Рассмотреть подробно как можно интегрировать видео-расширение с программы распознавания речи, исследовать сам принцип аудио-видео синхронизации, а также осуществить пробную интеграцию разрабатываемого видео расширения в систему аудио распознавания речи, оценить разрабатываемое решение.
Введение
В ходе проведения предыдущих исследовательских работ были сделаны выводы целесообразности использования аудио-систем распознавания речи на базе открытого и закрытого исходного кода под наши цели и задачи. Как было нами определено: реализация своей собственной системы распознавания речи является очень сложной, трудоемкой и ресурсозатратной задачей, которую сложно выполнить в рамках данной работы. Поэтому нами было решено интегрировать представленную технологию видео-идентификации в системы распознавания речи, которые имеют для этого специальные возможности. Так как системы распознавания речи с закрытым исходным кодом реализованы более качественно и точность распознавания речи в них выше за счет более емкого содержания словника, то поэтому интеграция нашей видео-разработки в их работу следует считать более перспективным направлением, по сравнению с аудио системами распознавания речи на базе открытого исходного кода. Однако же необходимо иметь в виду тот факт, что системы распознавания речи с закрытым исходным кодом часто имеют сложную документацию для возможности интеграции сторонних решений в их работу с серьезными ограничениями использования системы на основе лицензионного соглашения или же это направление является платным, то есть необходимо покупать специальную лицензию на использование речевых технологий, представленных лицензиантом.
Для начала в качестве эксперимента было принято решение попробовать улучшить качество распознавания речи системы распознавания речи Google Speech Recognition API за счет работы нашего разрабатываемого видео расширения. Замечу, что на время проведения испытаний у Google Speech API на базе браузера Chrome еще не было функции распознавания непрерывной речи Google, которая в то время уже встраивалась в технологию распознавания непрерывной речи Speech Input.
В качестве видео обработки за основу взято наше решение по анализу движения губ пользователя и алгоритмам фиксирования фазы движения точек в объекте интереса совместно с аудио обработкой. С тем, что в конечном итоге получилось можно ознакомиться ниже.

Логика анализатора движений губ в улучшении работы систем распознавания речи
Использование дополнительной визуализации в задачах повышения точности распознавания речи в представленном видео-расширении заключается в следующих технологических особенностях:
За счет параллельной обработки движения губ пользователя и анализа частоты голоса диктора, представленное видео расширение более точно определяет тот речевой поток, который имеет прямое отношение к речи реального пользователя. Для этого разрабатываемое программное обеспечение ведет постоянный анализ звукового сигнала и движения губ пользователя. Однако же запись сигнала для определения речи пользователя, выделение пауз речи диктора и других обстоятельств, которые необходимы для последующей отправки и обработки аудио сигнала в базе данных систем распознавания речи происходит только после целого ряда причин. Рассмотрим их более подробно:
• Решение производит запись и последующую обработку тех звуковых частот, которые попадают в микрофон системы. Однако же если пользователь не производит совместно с этими звуковыми колебаниями никакое активное движение своих губ, то система не начинает вести запись речи для задач последующего распознавания. На рисунке 1 представлен процесс анализа движения губ пользователя и звуковой волны, зафиксированный в тот временной промежуток, когда не наблюдается активных звуковых колебаний и пользователь не производит активное движение губ. В этот момент система не ведет запись звукового фрагмента, который необходимо начать записывать для задач последующего распознавания речи;

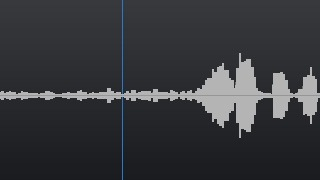
Рисунок 1. Пример работы системы, когда не наблюдается в динамике активное движение губ пользователя и активное колебание речевой волны — соответственно не производиться запись речи, для задач последующего распознавания.
• Также расширение не производит запись и последующую обработку той звуковой частоты, когда пользователь активно шевелит губами, в то время как микрофон пользователя выключен или не чувствителен к шуму, то есть отсутствуют какие-то активные звуковые колебания. В таком случае система начинает анализировать данные в динамике. В случае если за движением губ пользователя не следует никаких дальнейших звуковых колебаний, то, соответственно, изобретению не следует производить запись данного речевого потока для задач последующего распознавания. На рисунке 2 представлен такой возможный пример, когда пользователь изменил свое движение губ, однако за этим процессом не последовали какие-либо активные звуковые колебания во временной динамике;
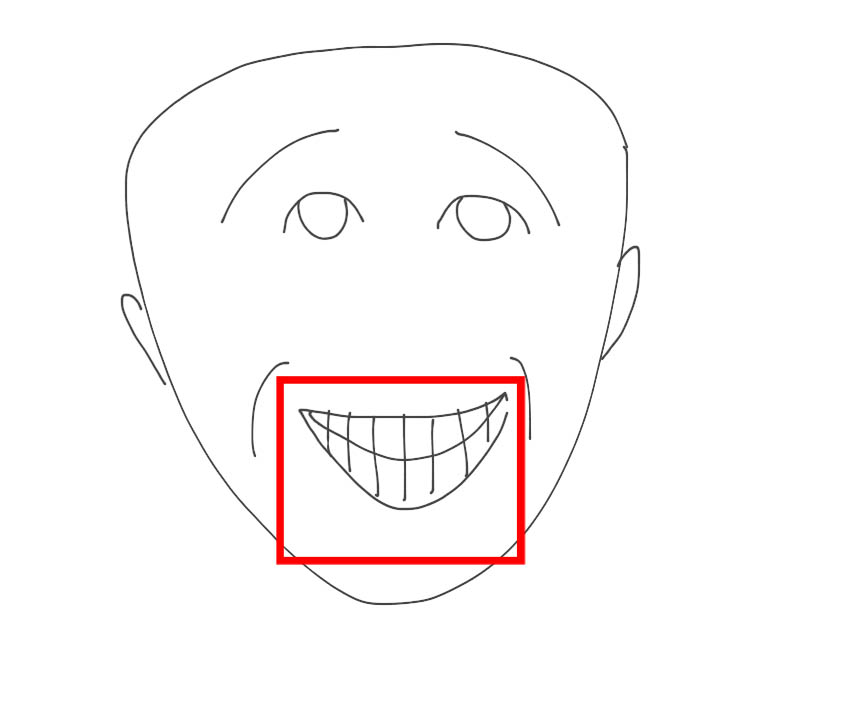
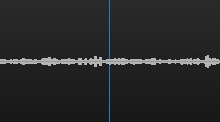
Рисунок 2. Пример работы системы, когда зафиксировано активное движение губ (в представленном случае пользователь улыбается), но во временной динамике не последовало за этим активное колебание звуковой частоты — соответственно не производиться запись речи, для последующего распознавания.
• Также представленное решение не осуществляет запись и последующую обработку звукового сигнала для задач распознавания, в случае если имеются звуковые колебания, но нет активного движения губ конкретного пользователя, которые прослеживаются во временной динамике. На рисунке 3 представлен один из таких возможных примеров: губы пользователя сомкнуты, и их положение в динамике не изменяется активно, в то же время имеются определенные звуковые колебания — следовательно, в таком случае устройство не производит запись аудиодорожки для задач последующего распознавания.
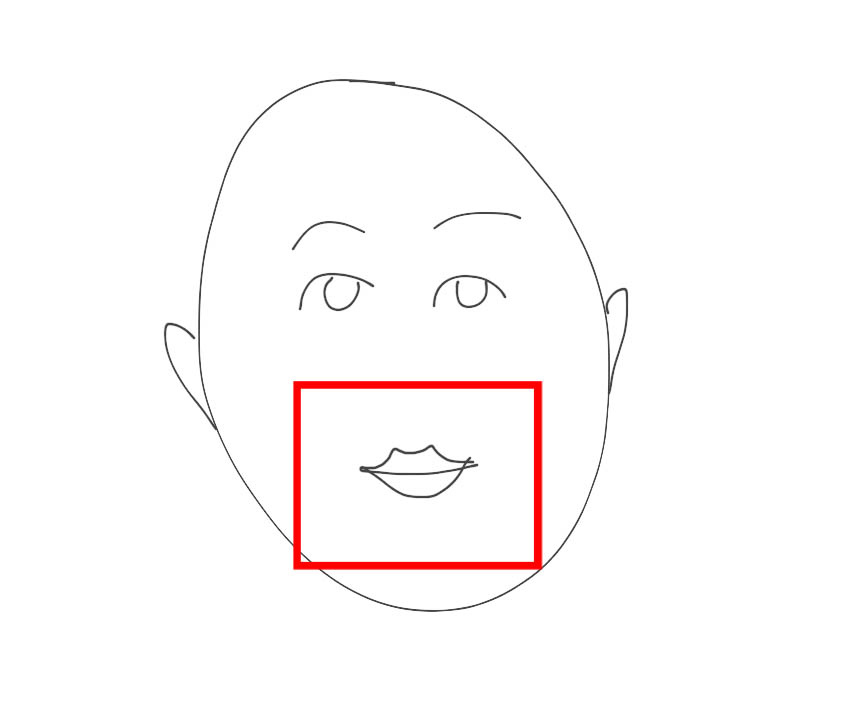
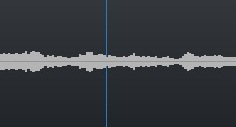
Рисунок 3. Пример работы системы, когда не зафиксировано активное движение губ пользователя во временной динамике, в то же время имеются некоторые активные колебания звуковой частоты (в представленном случае речь идет о включенной музыке) — соответственно, не производится запись речи для последующего распознавания.
• В случае если микрофон пользователя включен и должным образом настроен, также как включена камера устройства и должным образом настроена, то происходит включение работы устройства. Запись и последующая обработка звукового сигнала начинается только после того, как активные звуковые колебания начинают совпадать с активным движением губ пользователя. При этом необходимо иметь в виду следующее:
a) Активное движение губ пользователь, как правило, начинает произносить чуть раньше, нежели происходят активные звуковые колебания. В данном случае представленное решение просматривает движение губ пользователя и активные звуковые колебания во временной динамике. Если дальнейшее активное движение губ пользователя начинает совпадать с активным колебанием звуковой частоты, то в таком случае на месте, где начало активной фазы движения губ и звуковой частоты максимально совпадает, представленное решение начинает вести запись речи пользователя для дальнейшей ее последующей обработки и распознавания в базе данных систем распознавания речи. Пример начала активного движения губ пользователя и последующее за тем активное звуковое колебание представлено на рисунке 4.

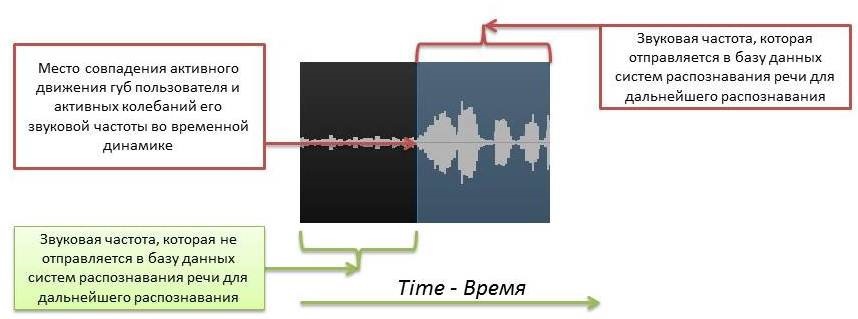
Рисунок 4. Пример места фиксации начала звуковой дорожки, которую необходимо записывать для того, чтобы затем отправить для последующего анализа в базу данных систем распознавания речи. Как можно заметить система зафиксировала активное движение губ пользователя, которое во временной динамике совпало с активными звуковыми колебаниями. На месте, где звуковые колебания и движения губ пользователя стали наиболее активными было определено начало речи для записи.
b) Однако же бывают моменты, когда в результате коартикуляции — наложение артикуляции, характерной для последующего звука, на весь предшествующий звук, движение губ пользователя по различным причинам не успевают в полной мере сомкнуться во время того момента, когда диктор сделал паузу в предыдущей своей части речи. Это обусловлено тем, что в открытом состоянии губам пользователя необходимо потратить меньше времени и усилий, чтобы создать движение совместно с аудио речевым потоком пользователя. В таком случае начало записи речи будет определенно в тот момент, когда наиболее активное движение губ пользователя максимально совпадает с активным колебанием звуковой частоты при анализе аудио-видео потока во временной динамике. Данный принцип также актуален для того момента, когда диктор прекращает свою речь, но только в этом случае речь идет о том, что активная фаза движения губ диктора и колебаний его частоты начинает прекращаться. На месте максимального одновременного прекращения активной фазы этих показателей речи пользователя представленное решение останавливает запись речи пользователя и отправляет зафиксированный фрагмент в базу данных систем распознавания речи для осуществления соответствующего распознавания. Пример работы системы для данной ситуации представлен на рисунке 5.

На рисунке 5 представлен пример, когда губы пользователя были в открытом состоянии, но активное звуковое колебание по времени начиналось чуть позже. В таком случае система начинает вести запись речи для задач последующего распознавания в тот момент, когда наблюдается наиболее активный период колебания движения губ и частоты голоса пользователя. Как можно увидеть из рисунка активная фаза звуковой волны, которая зафиксирована для последующего распознавания, была определена представленным изобретение чуть раньше, нежели начались активные звуковые колебания речи. Момент фиксации был определен как раз за счет параллельного анализа движения губ и частоты голоса пользователя во временной динамике исходя из среднего наиболее релевантного значения.
Прекращение записи речи для задач последующей обработки определяется в тот момент, когда пользователь прекращает проводить активное движение губ и колебания своей звуковой частоты. Данный момент рассматривается для анализа во временном пространстве. Система для удобства сама разбивает речь пользователя на паузы и микро паузы, руководствуясь принципом выбора наиболее верного речевого фрагмента, который необходимо отделить от того потока, который не следует записывать для задач дальнейшего распознавания, а также принципом быстрой и качественной обработки данных во временном пространстве.
Таким образом, система сама подстраивается под манеру речи конкретного пользователя. Если пользователь произносит свою речь быстро, то в таком случае представленная система начинает фиксировать паузы в речи для выделения отдельных речевых фрагментов, это могут быть как отдельные выражения, так и предложения. Если пользователь произносит свою речь четко и ясно, то в таком случае система начинает фиксировать более короткие речевые фрагменты в речи диктора, это могут быть как выражения, предложения, так и отдельные слова и так далее. При желании интенсивность анализа аудиовизуального потока во временном пространстве и способность системы автоматически определять паузы в речи конкретного пользователя можно отрегулировать.
Как и в случае с фиксированием начала речи пользователя для задач последующего распознавания, необходимо руководствоваться тем, что движение губ пользователя, как правило заканчивается чуть позже, чем колебание голоса. Поэтому для того, чтобы остановка речи была определена наиболее корректно, система фиксирует прекращение речи пользователя исходя из среднего значения того момента, когда прекращение активных звуковых колебаний максимально совпадают с активным прекращением движением губ пользователя. На рисунке 6 представлен момент, когда пользователь полностью сомкнул свои губы, и система остановила запись речи для задач последующего распознавания.
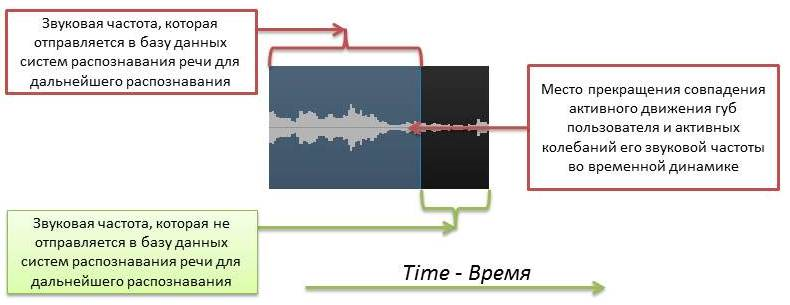
Рисунок 6. Пример возможного прекращения записи речи пользователя для задач дальнейшего распознавания.
Также необходимо иметь в виду, что разрабатываемая система основной акцент в своей работе для обработки аудио потока для задач последующего распознавания делает именно на основе параллельного анализа активного движения губ пользователя и активных звуковых колебаний пользователя во временной шкале. При этом разрабатываемая система фиксирует наиболее релевантный, максимально точный момент, когда происходит сочетание или прекращение сочетания активного движения губ пользователя совместно с колебанием звуковой волны.
Но в целом основной упор в своей работе разрабатываемая система делает именно на определение и анализ движения губ пользователя. Это обусловлено тем, что система видео-идентификации в качестве дополнения к средствам аудио-распознавания речи реального пользователя является более надежной системой (за счет дополнительного источника видео информации) по сравнению с другими системами, которые делают основной акцент исключительно на обработку аудио данных речи пользователя. Так в случае если разрабатываемая система начинает определять активное звуковое колебание речи, в то время как за этим процессом не следует каких-то активных движений губ пользователя во временном пространстве, то это значит, что речь идет о речевых частотах, которые не имеют никакого отношения к речи пользователя — следовательно, их не нужно обрабатывать. То же самое относится к моменту прекращения речи — если пользователь прекратил активную фазу движения своих губ и зафиксировал их в течение определенного временного промежутка в статическом положении, то, следовательно, разрабатываемая система за счет решения визуализации прекращает запись речи, несмотря на то, что могут наблюдаться какие-то активные звуковые колебания.
Видео испытания
Протоколы испытаний
Плюсы
Таким образом, за счет параллельной обработки движения губ пользователя совместно с анализом частоты его голоса во временной динамике, представленное видео расширение увеличивает точность систем распознавания речи за счет как раз предварительной визуальной обработки аудиоданных в режиме реального времени:
• Разрабатываемая система не обрабатывает звуковую частоту, которая не имеет никакого отношение к речи пользователя — следовательно, эти звуковые данные не попадают в базу данных систем распознавания речи для задач последующего распознавания;
• Разрабатываемая система за счет параллельной обработки аудио-видео потока речи пользователя способна в автоматическом режиме более точно определить начало и конец речи конкретного пользователя — после того как система зафиксировала данный звуковой файл, она отправляет его для задач последующего распознавания в базу данных систем распознавания речи;
• Разрабатываемая система адаптируется к манере речи пользователя. Для более надежного фиксирования пауз и микро пауз, разрабатываемая система выделяет промежутки, где можно начать или прекратить запись речи, для задач последующего распознавания, исходя из представленной речевой информации диктора во временной динамике. При желании данный процесс анализа можно отрегулировать для конкретного пользователя;
• Разрабатываемая система производит запись речи постоянно. То есть устройство, с которого производиться аудиовизуальная запись речи не останавливает свою работу во время всего процесса распознавания речи и пользователь представленного изобретения имеет возможность вести распознавание своей речи непрерывно, не отвлекаясь на само устройство;
• Результирующие данные после прохождения соответствующего процесса распознавания выводятся на устройство пользователя в автоматическом режиме;
• Основной акцент в своей работе представленная система придает движения губ пользователя во временной динамике и сочетанию активной фазы движения губ пользователя с активной фазой сочетания частоты его голоса. Это связано с тем, что движение губ дает более информативное представление о реальном пользователе данной системы и его речи, нежели использование исключительно аудиоинформации.
• За счет предварительной обработки аудио-потока на основе определения движения губ реального пользователя совместно с анализом частоты его голоса снижается общая скорость обработки данных. Так как, с одной стороны, в базу данных систем распознавания речи не попадает посторонний аудио-поток, который не имеет никакого отношения к речи диктора; с другой стороны, в базу данных систем распознавания речи, после предварительной аудиовизуальной обработки, речевая частота пользователя поступает отдельными небольшими структурированными фрагментами, а не общим речевым потоком.
• Действительно за счет использования дополнительного источника информации повышается качество распознавания речи.
Минусы
• Неестественность. Для фиксации движения губ программой испытуемый всегда должен находиться в кадре, что неестественно для большинства потенциальных пользователей и делает работу программы неудобной. Это противоречит основному достоинству систем распознавания речи = эффект свободы, отвязка от устройства и его клавиатуры;
• Чувствительность к качеству изображений. Для работы системы требуется как правило фон без артефактов. Любой внешний пестрый обзор за испытуемым или же темное-светлое, контрастное или иное помещение с обилием помех в фоне может негативно повлиять на качество работы системы;
• Чувствительность к камере. Для работы системы как правило требуется широкоформатная камера, которая должна максимально качественно считывать информацию с видео;
• Чувствительность к устройству. Для правильной работы системы требуется устройство, которое способно обсчитывать данные в режиме реального времени информацию с видео с частотой 25 кадров в секунду;
• Расстояние. Для правильной работы программы требуется соблюдать субординацию между камерой и устройством. Программа должна иметь возможность видеть все лицо человека в положении анфас перед камерой. При этом расстояние должно быть достаточно, чтобы можно было считывать информацию с губ максимально эффективно;
• Поведенческие особенности. Человек в кадре должен вести себя спокойно, при общении не использовать ненужную жестикуляцию и так далее, что может мешать работе системы
• Наличие помех на лице человека. Информация с изображений лица человека должна хорошо считываться — не должно быть бороды, посторонних предметов и так далее, которые будут прикрывать объект интереса работы системы
• При нарушении представленных условий качество распознавания речи может не только не улучшиться, но и даже ухудшиться.
Заключение
Таким образом, рассмотрев самые распространенные системы распознавания речи с закрытым исходным кодом мы решили использовать речевой инструментарий Google, который более встраиваемый точный и быстрый за счет больших вычислительных мощностей и отсутствие ограничений по количеству речевых запросов в сутки.
Учитывая данные обстоятельства в представленной исследовательской работе, нам удалось осуществить пробную интеграцию разрабатываемого видео-расширения в существующую систему распознавания речи на основе Google Speech Recognition API. Мы смогли экспериментальным образом доказать, что видео (а именно анализатор движения губ пользователя во время распознавания речи) может являться дополнительным источником информации. Однако, представленное решение далеко до пользовательского внедрения, так как оно на текущий момент исследования не естественно в работе и противоречит главному достоинству речевых технологий: «Эффект свободы от устройства». Далее мы планируем на основе накопленного опыта исправить архитектуру работы системы и сделать так, что видео являлось средством уточнения для улучшения точности систем распознавания речи и средством быстрой верификации речи диктора из общего потока, а также отличным решением для аудио-видео идентификации и авторизации пользователя без использования клавиатуры.
ссылка на оригинал статьи http://habrahabr.ru/post/231821/
Добавить комментарий